 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Semantic Knowledge Into Language Encoders
Oct 14, 2021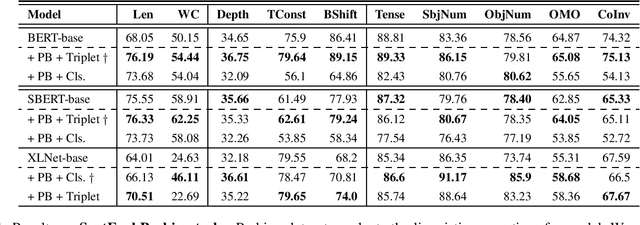
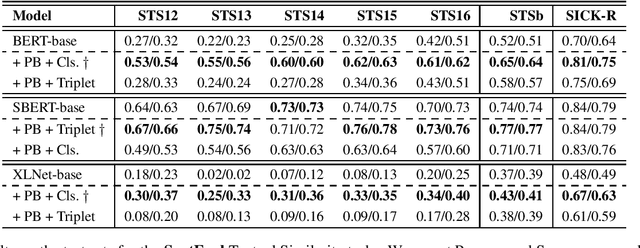
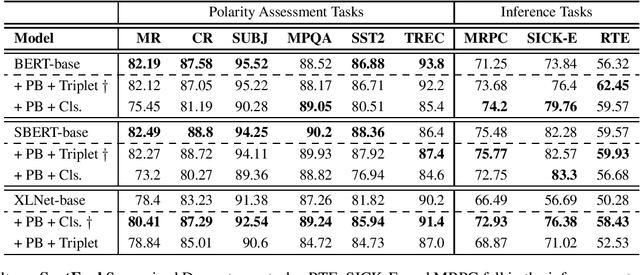
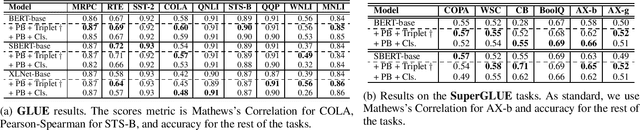
We introduce semantic form mid-tuning, an approach for transferring semantic knowledge from semantic meaning representations into transformer-based language encoders. In mid-tuning, we learn to align the text of general sentences -- not tied to any particular inference task -- and structured semantic representations of those sentences. Our approach does not require gold annotated semantic representations. Instead, it makes use of automatically generated semantic representations, such as from off-the-shelf PropBank and FrameNet semantic parsers. We show that this alignment can be learned implicitly via classification or directly via triplet loss. Our method yields language encoders that demonstrate improved predictive performance across inference, reading comprehension, textual similarity, and other semantic tasks drawn from the GLUE, SuperGLUE, and SentEval benchmarks. We evaluate our approach on three popular baseline models, where our experimental results and analysis concludes that current pre-trained language models can further benefit from structured semantic frames with the proposed mid-tuning method, as they inject additional task-agnostic knowledge to the encoder, improving the generated embeddings as well as the linguistic properties of the given model, as evident from improvements on a popular sentence embedding toolkit and a variety of probing tasks.
Discriminative and Generative Transformer-based Models For Situation Entity Classification
Sep 15, 2021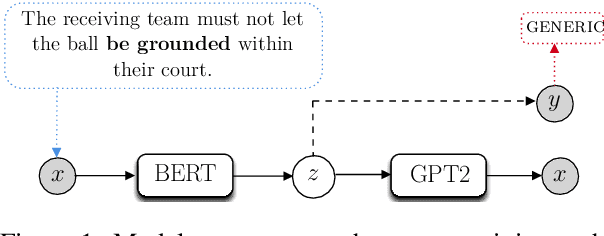
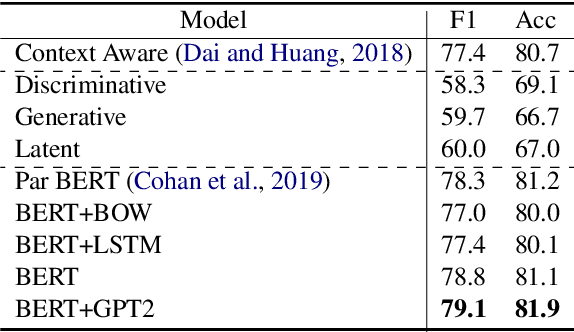
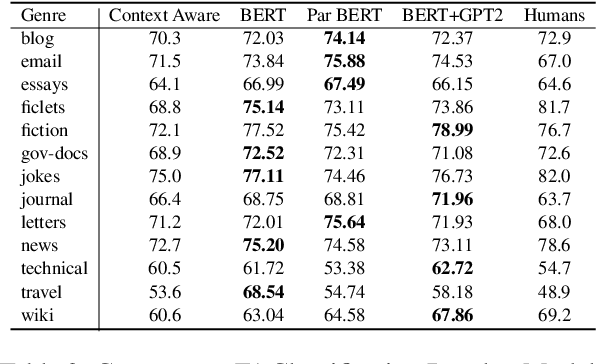
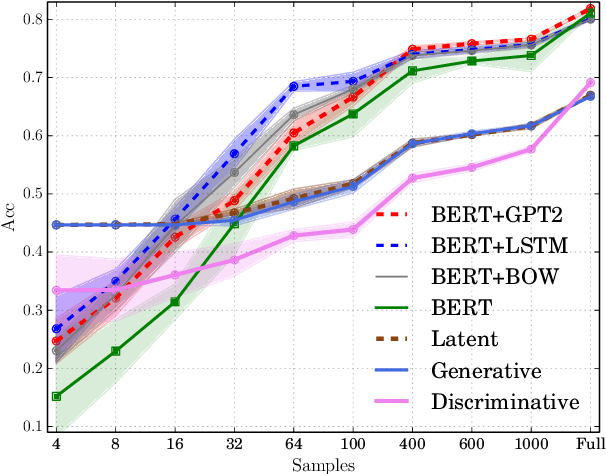
We re-examine the situation entity (SE) classification task with varying amounts of available training data. We exploit a Transformer-based variational autoencoder to encode sentences into a lower dimensional latent space, which is used to generate the text and learn a SE classifier. Test set and cross-genre evaluations show that when training data is plentiful, the proposed model can improve over the previous discriminative state-of-the-art models. Our approach performs disproportionately better with smaller amounts of training data, but when faced with extremely small sets (4 instances per label), generative RNN methods outperform transformers. Our work provides guidance for future efforts on SE and semantic prediction tasks, and low-label training regimes.
Neural Variational Learning for Grounded Language Acquisition
Jul 20, 2021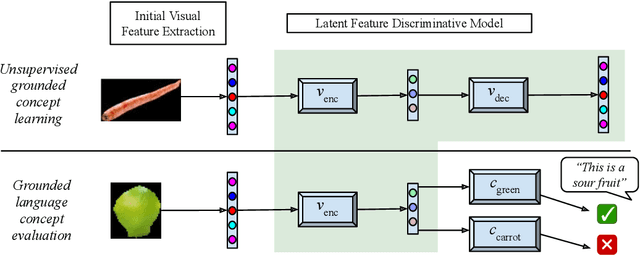

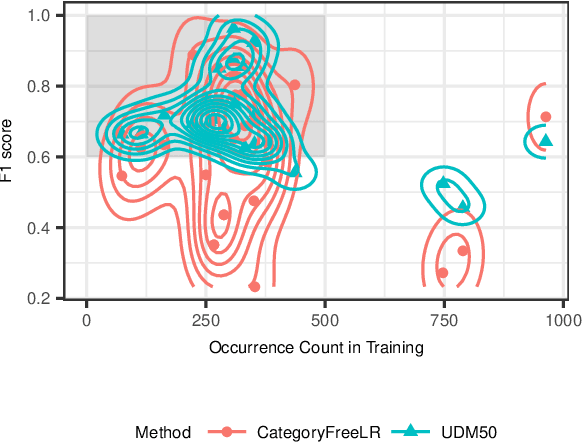
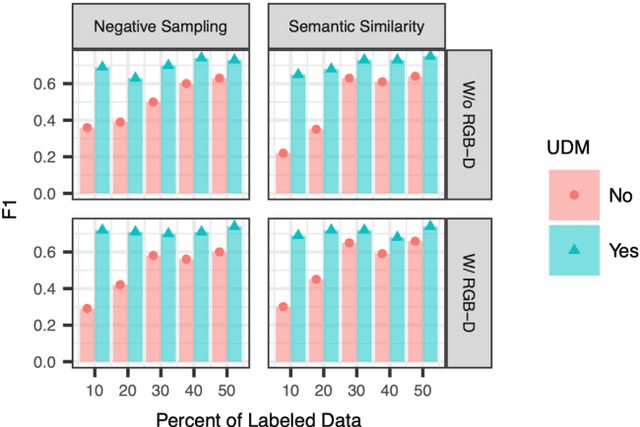
We propose a learning system in which language is grounded in visual percepts without specific pre-defined categories of terms. We present a unified generative method to acquire a shared semantic/visual embedding that enables the learning of language about a wide range of real-world objects. We evaluate the efficacy of this learning by predicting the semantics of objects and comparing the performance with neural and non-neural inputs. We show that this generative approach exhibits promising results in language grounding without pre-specifying visual categories under low resource settings. Our experiments demonstrate that this approach is generalizable to multilingual, highly varied datasets.
Learning a Reversible Embedding Mapping using Bi-Directional Manifold Alignment
Jun 30, 2021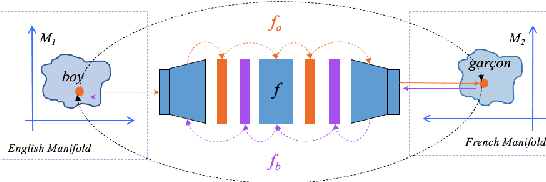
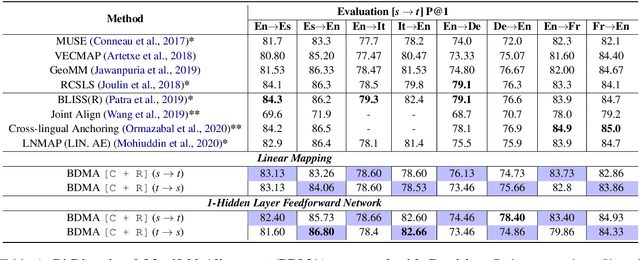
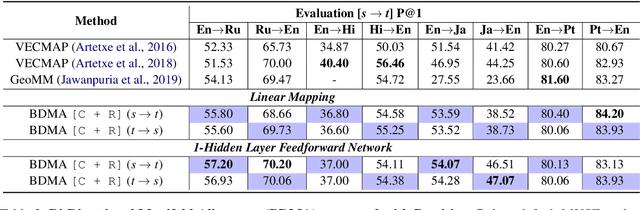
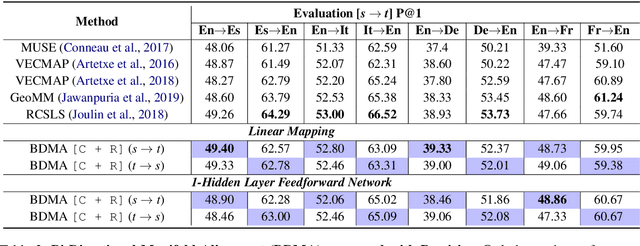
We propose a Bi-Directional Manifold Alignment (BDMA) that learns a non-linear mapping between two manifolds by explicitly training it to be bijective. We demonstrate BDMA by training a model for a pair of languages rather than individual, directed source and target combinations, reducing the number of models by 50%. We show that models trained with BDMA in the "forward" (source to target) direction can successfully map words in the "reverse" (target to source) direction, yielding equivalent (or better) performance to standard unidirectional translation models where the source and target language is flipped. We also show how BDMA reduces the overall size of the model.
Sampling Approach Matters: Active Learning for Robotic Language Acquisition
Nov 16, 2020
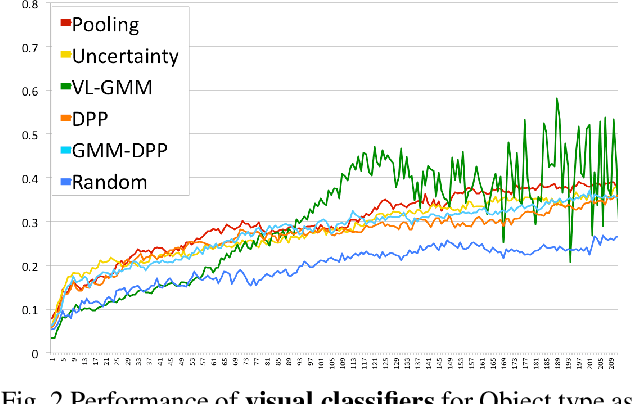


Ordering the selection of training data using active learning can lead to improvements in learning efficiently from smaller corpora. We present an exploration of active learning approaches applied to three grounded language problems of varying complexity in order to analyze what methods are suitable for improving data efficiency in learning. We present a method for analyzing the complexity of data in this joint problem space, and report on how characteristics of the underlying task, along with design decisions such as feature selection and classification model, drive the results. We observe that representativeness, along with diversity, is crucial in selecting data samples.
A Discrete Variational Recurrent Topic Model without the Reparametrization Trick
Oct 22, 2020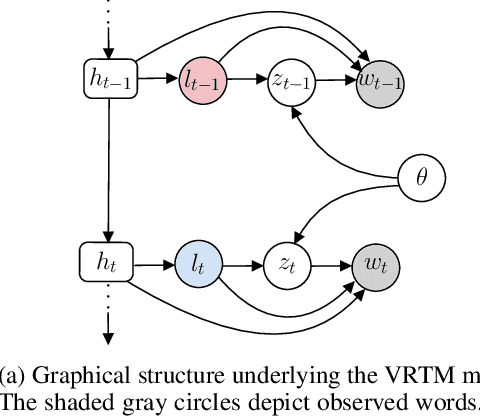
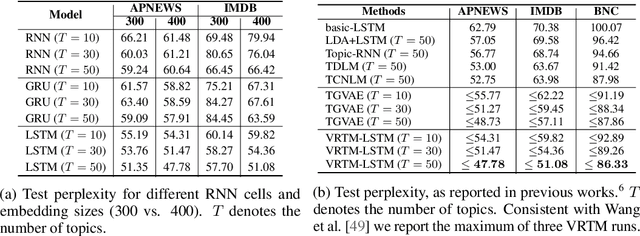
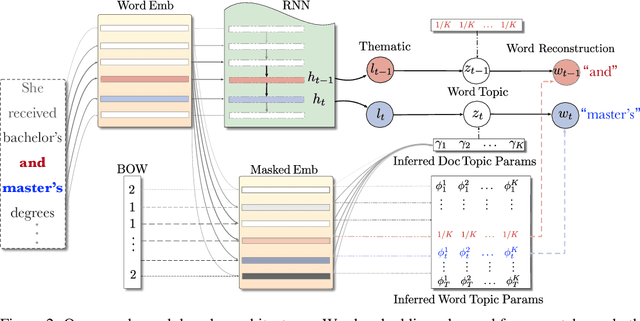
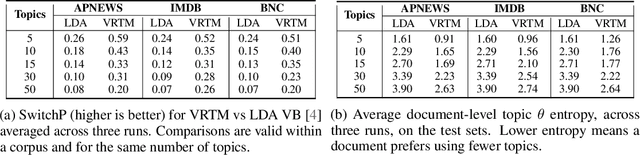
We show how to learn a neural topic model with discrete random variables---one that explicitly models each word's assigned topic---using neural variational inference that does not rely on stochastic backpropagation to handle the discrete variables. The model we utilize combines the expressive power of neural methods for representing sequences of text with the topic model's ability to capture global, thematic coherence. Using neural variational inference, we show improved perplexity and document understanding across multiple corpora. We examine the effect of prior parameters both on the model and variational parameters and demonstrate how our approach can compete and surpass a popular topic model implementation on an automatic measure of topic quality.
Event Representation with Sequential, Semi-Supervised Discrete Variables
Oct 16, 2020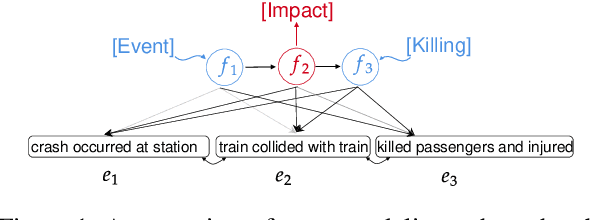
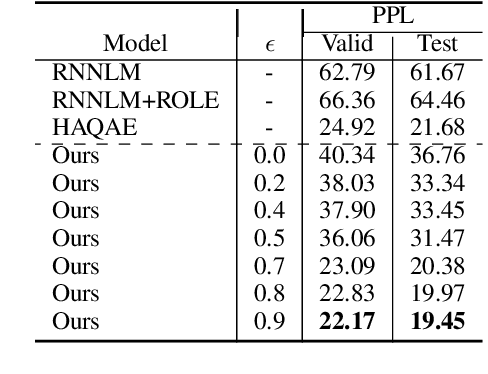
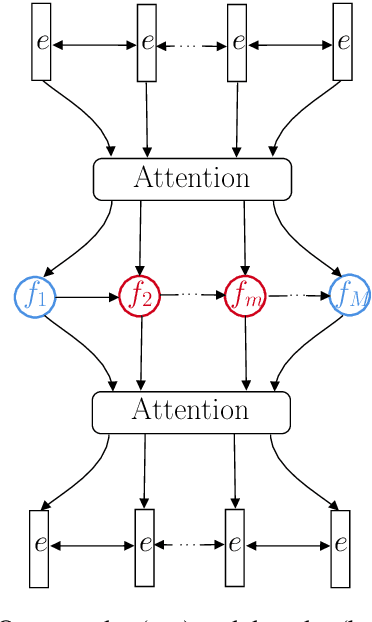
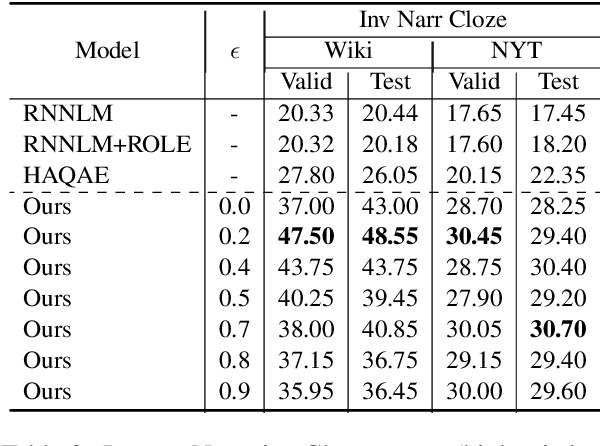
Within the context of event modeling and understanding, we propose a new method for neural sequence modeling that takes partially-observed sequences of discrete, external knowledge into account. We construct a sequential, neural variational autoencoder that uses a carefully defined encoder, and Gumbel-Softmax reparametrization, to allow for successful backpropagation during training. We show that our approach outperforms multiple baselines and the state-of-the-art in narrative script induction on multiple event modeling tasks. We demonstrate that our approach converges more quickly.
On the Complementary Nature of Knowledge Graph Embedding, Fine Grain Entity Types, and Language Modeling
Oct 12, 2020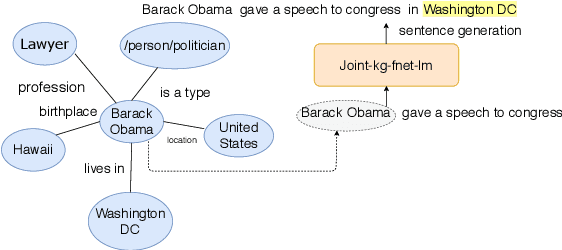
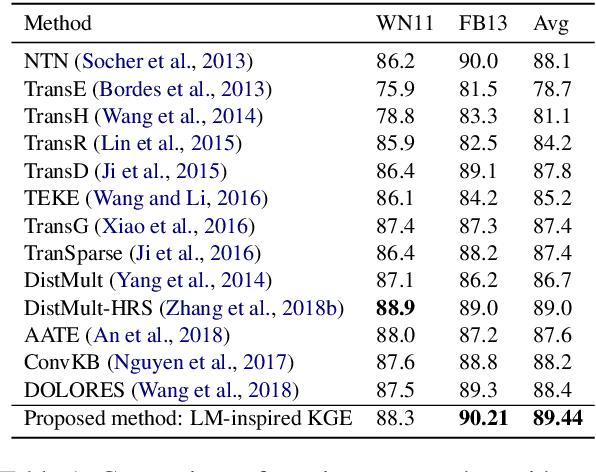
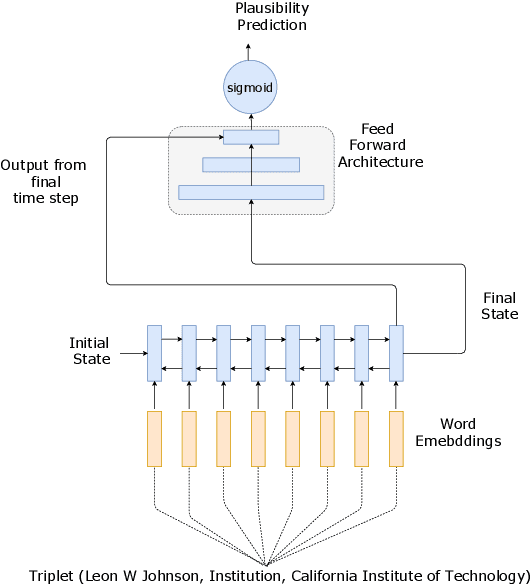
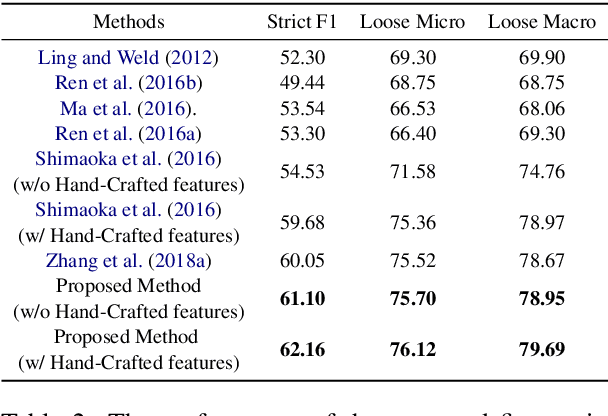
We demonstrate the complementary natures of neural knowledge graph embedding, fine-grain entity type prediction, and neural language modeling. We show that a language model-inspired knowledge graph embedding approach yields both improved knowledge graph embeddings and fine-grain entity type representations. Our work also shows that jointly modeling both structured knowledge tuples and language improves both.
The Universal Decompositional Semantics Dataset and Decomp Toolkit
Sep 30, 2019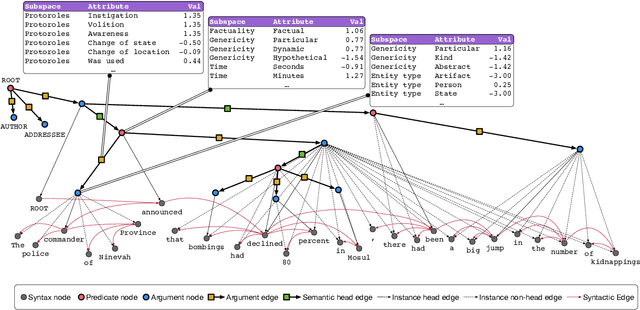
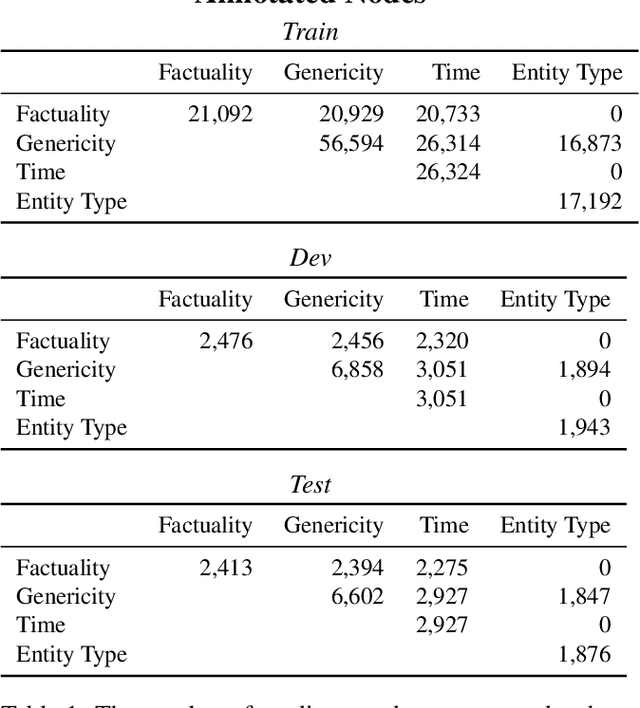
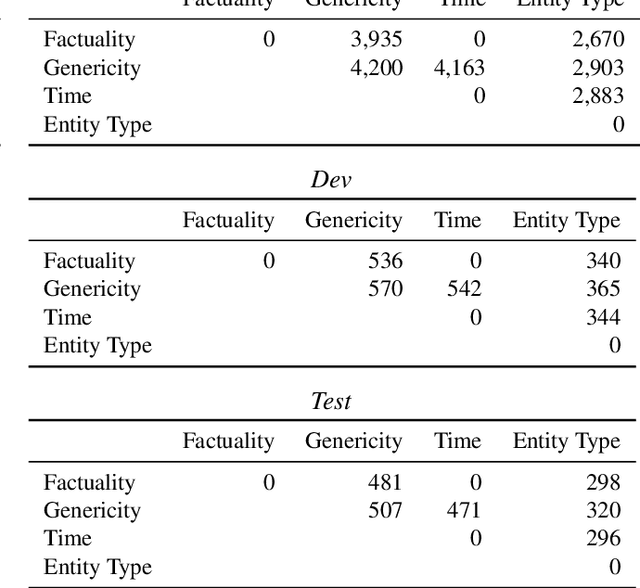

We present the Universal Decompositional Semantics (UDS) dataset (v1.0), which is bundled with the Decomp toolkit (v0.1). UDS1.0 unifies five high-quality, decompositional semantics-aligned annotation sets within a single semantic graph specification---with graph structures defined by the predicative patterns produced by the PredPatt tool and real-valued node and edge attributes constructed using sophisticated normalization procedures. The Decomp toolkit provides a suite of Python 3 tools for querying UDS graphs using SPARQL. Both UDS1.0 and Decomp0.1 are publicly available at http://decomp.io.
Knowledge Graph Fact Prediction via Knowledge-Enriched Tensor Factorization
Feb 08, 2019
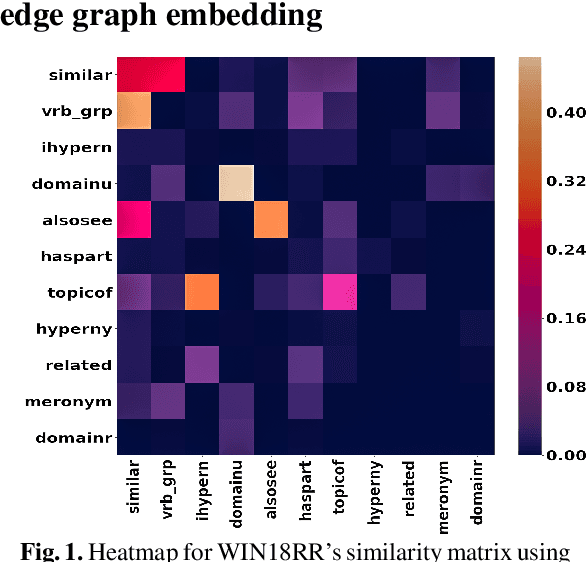
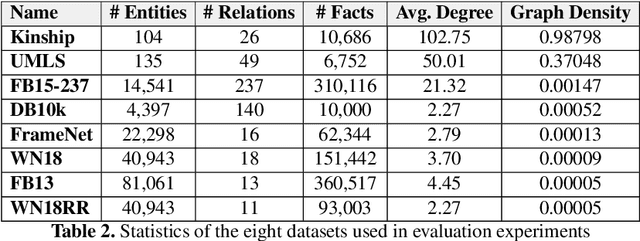
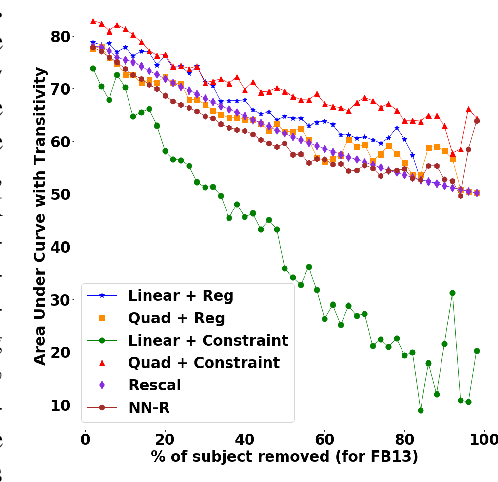
We present a family of novel methods for embedding knowledge graphs into real-valued tensors. These tensor-based embeddings capture the ordered relations that are typical in the knowledge graphs represented by semantic web languages like RDF. Unlike many previous models, our methods can easily use prior background knowledge provided by users or extracted automatically from existing knowledge graphs. In addition to providing more robust methods for knowledge graph embedding, we provide a provably-convergent, linear tensor factorization algorithm. We demonstrate the efficacy of our models for the task of predicting new facts across eight different knowledge graphs, achieving between 5% and 50% relative improvement over existing state-of-the-art knowledge graph embedding techniques. Our empirical evaluation shows that all of the tensor decomposition models perform well when the average degree of an entity in a graph is high, with constraint-based models doing better on graphs with a small number of highly similar relations and regularization-based models dominating for graphs with relations of varying degrees of similarity.