 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring diversity of synthetic prompts and data generated with fine-grained persona prompting
May 23, 2025



Fine-grained personas have recently been used for generating 'diverse' synthetic data for pre-training and supervised fine-tuning of Large Language Models (LLMs). In this work, we measure the diversity of persona-driven synthetically generated prompts and responses with a suite of lexical diversity and redundancy metrics. Firstly, we find that synthetic prompts/instructions are significantly less diverse than human-written ones. Next, we sample responses from LLMs of different sizes with fine-grained and coarse persona descriptions to investigate how much fine-grained detail in persona descriptions contribute to generated text diversity. We find that while persona-prompting does improve lexical diversity (especially with larger models), fine-grained detail in personas doesn't increase diversity noticeably.
The Universal Decompositional Semantics Dataset and Decomp Toolkit
Sep 30, 2019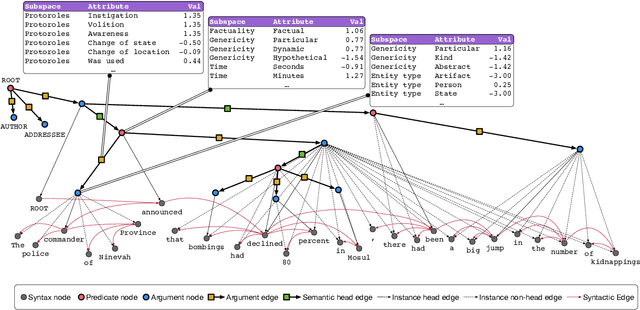
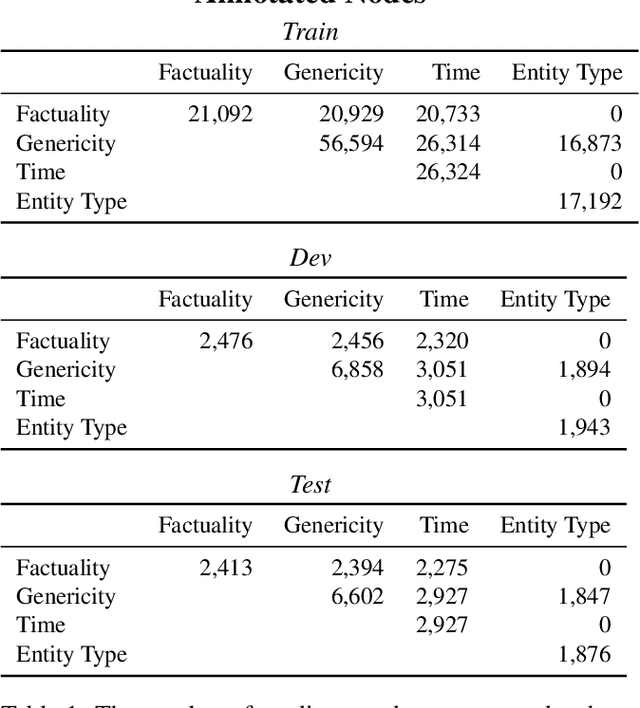
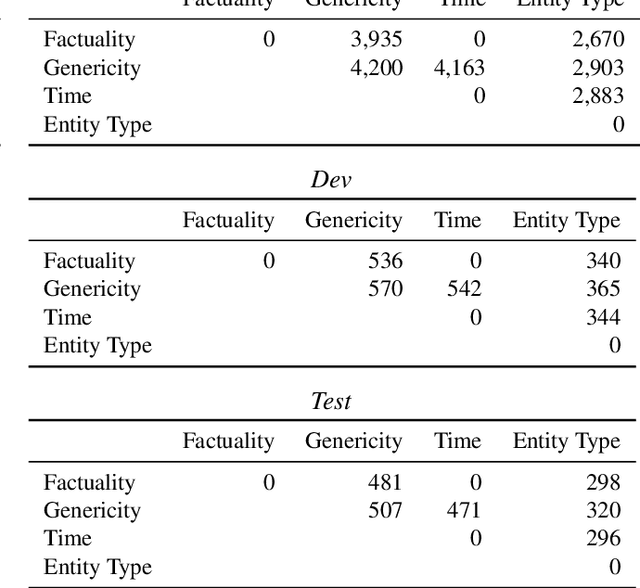

We present the Universal Decompositional Semantics (UDS) dataset (v1.0), which is bundled with the Decomp toolkit (v0.1). UDS1.0 unifies five high-quality, decompositional semantics-aligned annotation sets within a single semantic graph specification---with graph structures defined by the predicative patterns produced by the PredPatt tool and real-valued node and edge attributes constructed using sophisticated normalization procedures. The Decomp toolkit provides a suite of Python 3 tools for querying UDS graphs using SPARQL. Both UDS1.0 and Decomp0.1 are publicly available at http://decomp.io.