 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Relatedness Based Re-ranker for Text Spotting
Sep 19, 2019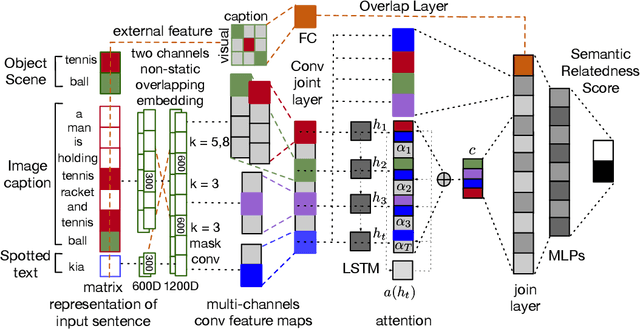
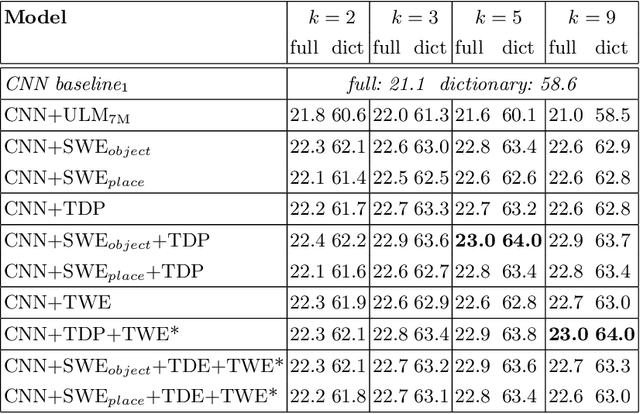
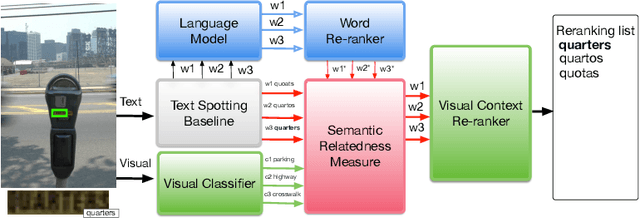
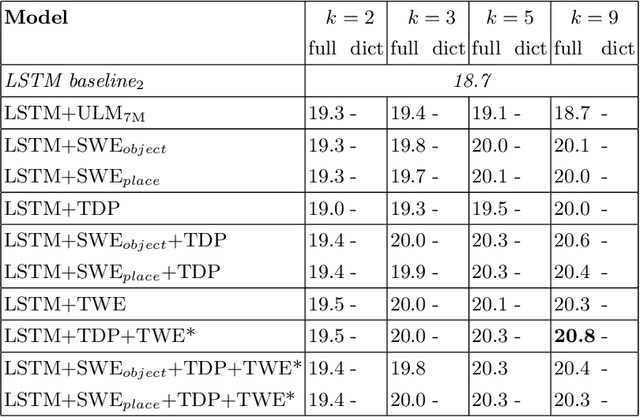
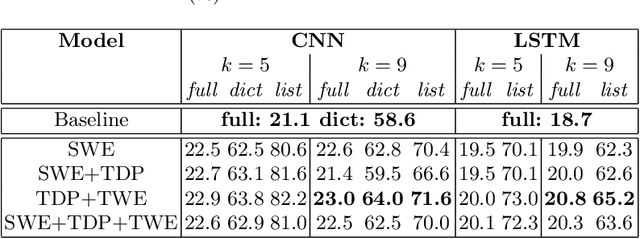
Applications such as textual entailment, plagiarism detection or document clustering rely on the notion of semantic similarity, and are usually approached with dimension reduction techniques like LDA or with embedding-based neural approaches. We present a scenario where semantic similarity is not enough, and we devise a neural approach to learn semantic relatedness. The scenario is text spotting in the wild, where a text in an image (e.g. street sign, advertisement or bus destination) must be identified and recognized. Our goal is to improve the performance of vision systems by leveraging semantic information. Our rationale is that the text to be spotted is often related to the image context in which it appears (word pairs such as Delta-airplane, or quarters-parking are not similar, but are clearly related). We show how learning a word-to-word or word-to-sentence relatedness score can improve the performance of text spotting systems up to 2.9 points, outperforming other measures in a benchmark dataset.
Context-aware Human Motion Prediction
Apr 12, 2019
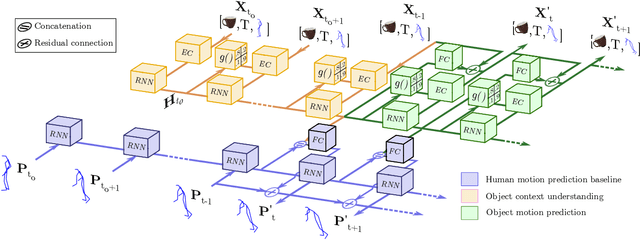
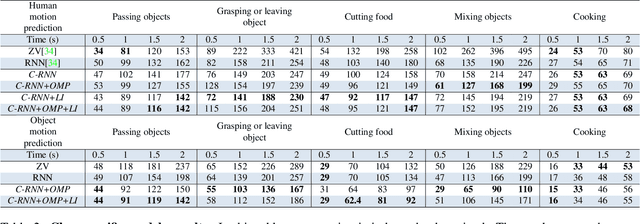
The problem of predicting human motion given a sequence of past observations is at the core of many applications in robotics and computer vision. Current state-of-the-art formulate this problem as a sequence-to-sequence task, in which a historical of 3D skeletons feeds a Recurrent Neural Network (RNN) that predicts future movements, typically in the order of 1 to 2 seconds. However, one aspect that has been obviated so far, is the fact that human motion is inherently driven by interactions with objects and/or other humans in the environment. In this paper, we explore this scenario using a novel context-aware motion prediction architecture. We use a semantic-graph model where the nodes parameterize the human and objects in the scene and the edges their mutual interactions. These interactions are iteratively learned through a graph attention layer, fed with the past observations, which now include both object and human body motions. Once this semantic graph is learned, we inject it to a standard RNN to predict future movements of the human/s and object/s. We consider two variants of our architecture, either freezing the contextual interactions in the future of updating them. A thorough evaluation in the "Whole-Body Human Motion Database" shows that in both cases, our context-aware networks clearly outperform baselines in which the context information is not considered.
3DPeople: Modeling the Geometry of Dressed Humans
Apr 09, 2019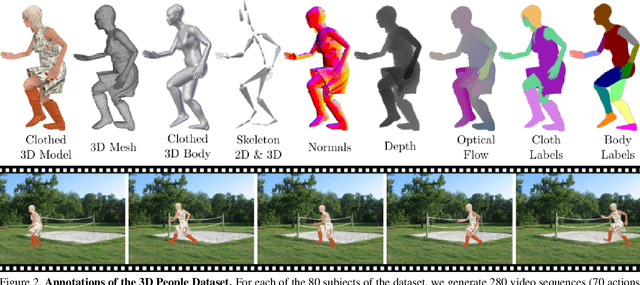
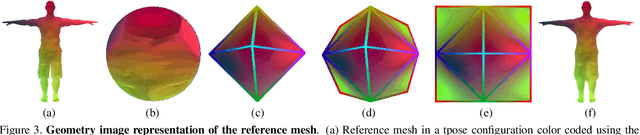
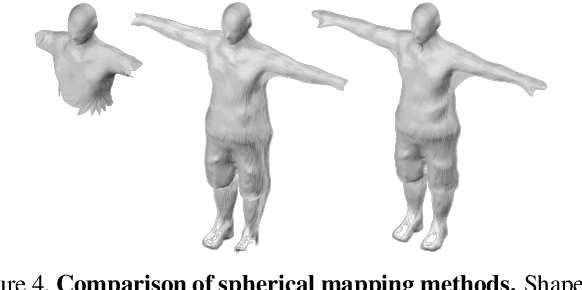
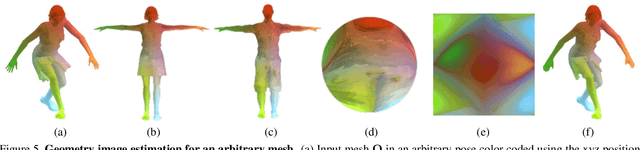
Recent advances in 3D human shape estimation build upon parametric representations that model very well the shape of the naked body, but are not appropriate to represent the clothing geometry. In this paper, we present an approach to model dressed humans and predict their geometry from single images. We contribute in three fundamental aspects of the problem, namely, a new dataset, a novel shape parameterization algorithm and an end-to-end deep generative network for predicting shape. First, we present 3DPeople, a large-scale synthetic dataset with 2.5 Million photo-realistic images of 80 subjects performing 70 activities and wearing diverse outfits. Besides providing textured 3D meshes for clothes and body, we annotate the dataset with segmentation masks, skeletons, depth, normal maps and optical flow. All this together makes 3DPeople suitable for a plethora of tasks. We then represent the 3D shapes using 2D geometry images. To build these images we propose a novel spherical area-preserving parameterization algorithm based on the optimal mass transportation method. We show this approach to improve existing spherical maps which tend to shrink the elongated parts of the full body models such as the arms and legs, making the geometry images incomplete. Finally, we design a multi-resolution deep generative network that, given an input image of a dressed human, predicts his/her geometry image (and thus the clothed body shape) in an end-to-end manner. We obtain very promising results in jointly capturing body pose and clothing shape, both for synthetic validation and on the wild images.
Fast video object segmentation with Spatio-Temporal GANs
Mar 28, 2019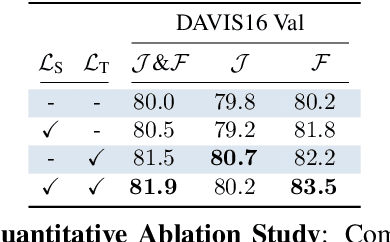
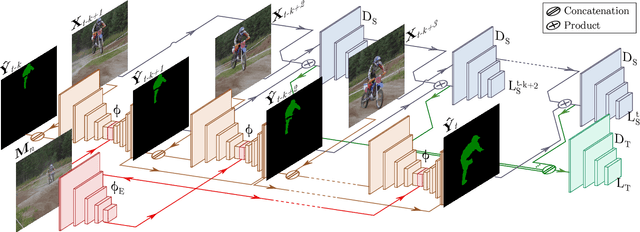

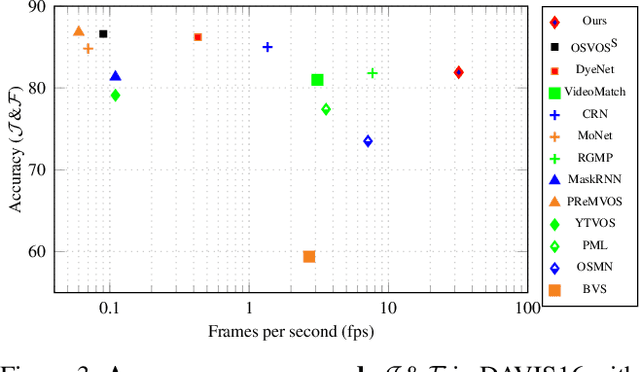
Learning descriptive spatio-temporal object models from data is paramount for the task of semi-supervised video object segmentation. Most existing approaches mainly rely on models that estimate the segmentation mask based on a reference mask at the first frame (aided sometimes by optical flow or the previous mask). These models, however, are prone to fail under rapid appearance changes or occlusions due to their limitations in modelling the temporal component. On the other hand, very recently, other approaches learned long-term features using a convolutional LSTM to leverage the information from all previous video frames. Even though these models achieve better temporal representations, they still have to be fine-tuned for every new video sequence. In this paper, we present an intermediate solution and devise a novel GAN architecture, FaSTGAN, to learn spatio-temporal object models over finite temporal windows. To achieve this, we concentrate all the heavy computational load to the training phase with two critics that enforce spatial and temporal mask consistency over the last K frames. Then at test time, we only use a relatively light regressor, which reduces the inference time considerably. As a result, our approach combines a high resiliency to sudden geometric and photometric object changes with efficiency at test time (no need for fine-tuning nor post-processing). We demonstrate that the accuracy of our method is on par with state-of-the-art techniques on the challenging YouTube-VOS and DAVIS datasets, while running at 32 fps, about 4x faster than the closest competitor.
Human Motion Prediction via Spatio-Temporal Inpainting
Dec 13, 2018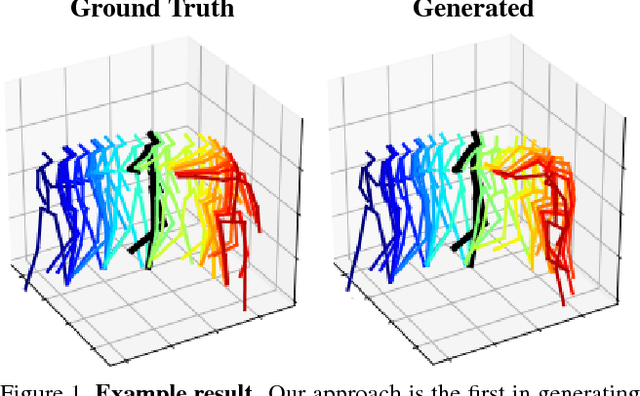
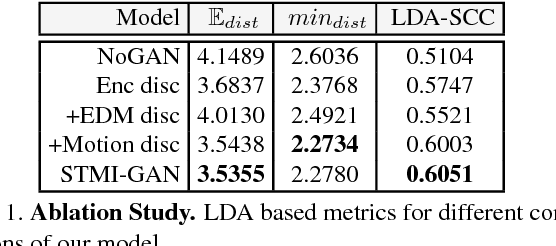
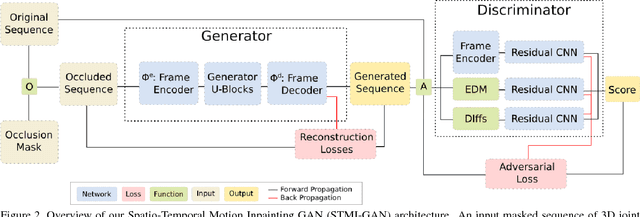

We propose a Generative Adversarial Network (GAN) to forecast 3D human motion given a sequence of observed 3D skeleton poses. While recent GANs have shown promising results, they can only forecast plausible human-like motion over relatively short periods of time, i.e. a few hundred milliseconds, and typically ignore the absolute position of the skeleton w.r.t. the camera. The GAN scheme we propose can reliably provide long term predictions of two seconds or more for both the non-rigid body pose and its absolute position, and can be trained in an self-supervised manner. Our approach builds upon three main contributions. First, we consider a data representation based on a spatio-temporal tensor of 3D skeleton coordinates which allows us to formulate the prediction problem as an inpainting one, for which GANs work particularly well. Secondly, we design a GAN architecture to learn the joint distribution of body poses and global motion, allowing us to hypothesize large chunks of the input 3D tensor with missing data. And finally, we argue that the L2 metric, which is considered so far by most approaches, fails to capture the actual distribution of long-term human motion. We therefore propose an alternative metric that is more correlated with human perception. Our experiments demonstrate that our approach achieves significant improvements over the state of the art for human motion forecasting and that it also handles situations in which past observations are corrupted by severe occlusions, noise and consecutive missing frames.
Visual Re-ranking with Natural Language Understanding for Text Spotting
Oct 29, 2018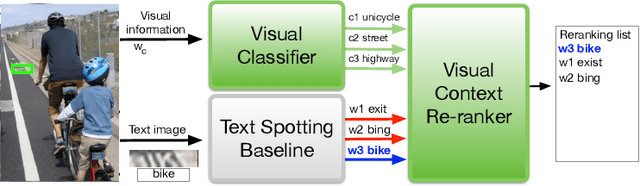
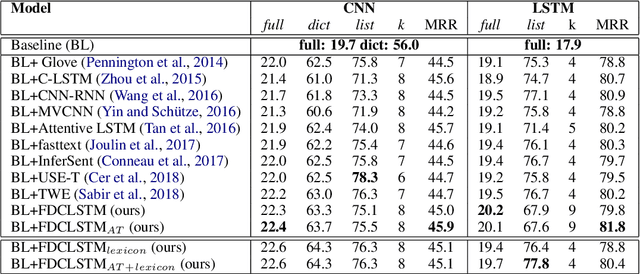
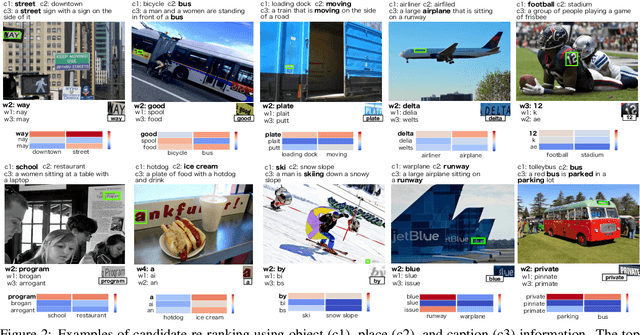
Many scene text recognition approaches are based on purely visual information and ignore the semantic relation between scene and text. In this paper, we tackle this problem from natural language processing perspective to fill the gap between language and vision. We propose a post-processing approach to improve scene text recognition accuracy by using occurrence probabilities of words (unigram language model), and the semantic correlation between scene and text. For this, we initially rely on an off-the-shelf deep neural network, already trained with a large amount of data, which provides a series of text hypotheses per input image. These hypotheses are then re-ranked using word frequencies and semantic relatedness with objects or scenes in the image. As a result of this combination, the performance of the original network is boosted with almost no additional cost. We validate our approach on ICDAR'17 dataset.
Visual Semantic Re-ranker for Text Spotting
Oct 27, 2018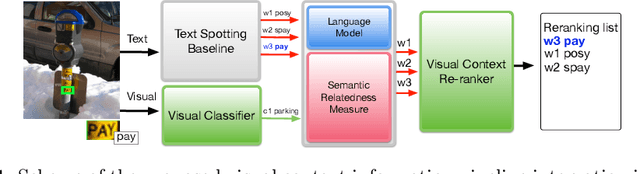
Many current state-of-the-art methods for text recognition are based on purely local information and ignore the semantic correlation between text and its surrounding visual context. In this paper, we propose a post-processing approach to improve the accuracy of text spotting by using the semantic relation between the text and the scene. We initially rely on an off-the-shelf deep neural network that provides a series of text hypotheses for each input image. These text hypotheses are then re-ranked using the semantic relatedness with the object in the image. As a result of this combination, the performance of the original network is boosted with a very low computational cost. The proposed framework can be used as a drop-in complement for any text-spotting algorithm that outputs a ranking of word hypotheses. We validate our approach on ICDAR'17 shared task dataset.
Geometry-Aware Network for Non-Rigid Shape Prediction from a Single View
Sep 27, 2018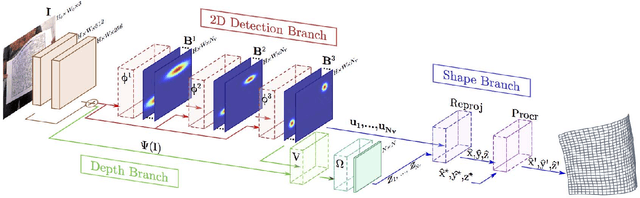
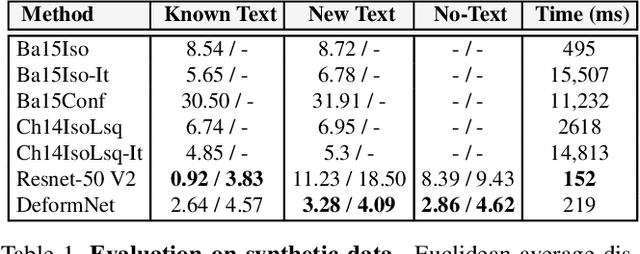


We propose a method for predicting the 3D shape of a deformable surface from a single view. By contrast with previous approaches, we do not need a pre-registered template of the surface, and our method is robust to the lack of texture and partial occlusions. At the core of our approach is a {\it geometry-aware} deep architecture that tackles the problem as usually done in analytic solutions: first perform 2D detection of the mesh and then estimate a 3D shape that is geometrically consistent with the image. We train this architecture in an end-to-end manner using a large dataset of synthetic renderings of shapes under different levels of deformation, material properties, textures and lighting conditions. We evaluate our approach on a test split of this dataset and available real benchmarks, consistently improving state-of-the-art solutions with a significantly lower computational time.
Unsupervised Person Image Synthesis in Arbitrary Poses
Sep 27, 2018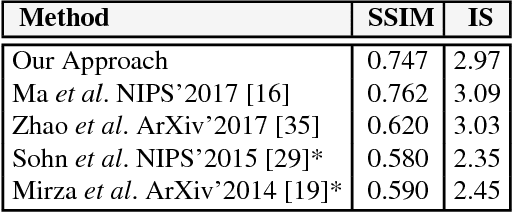
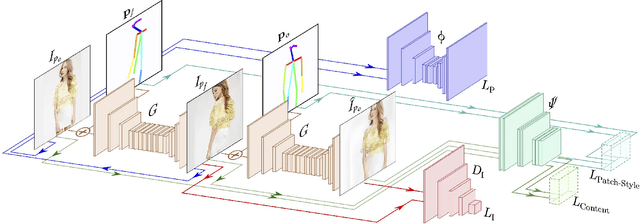
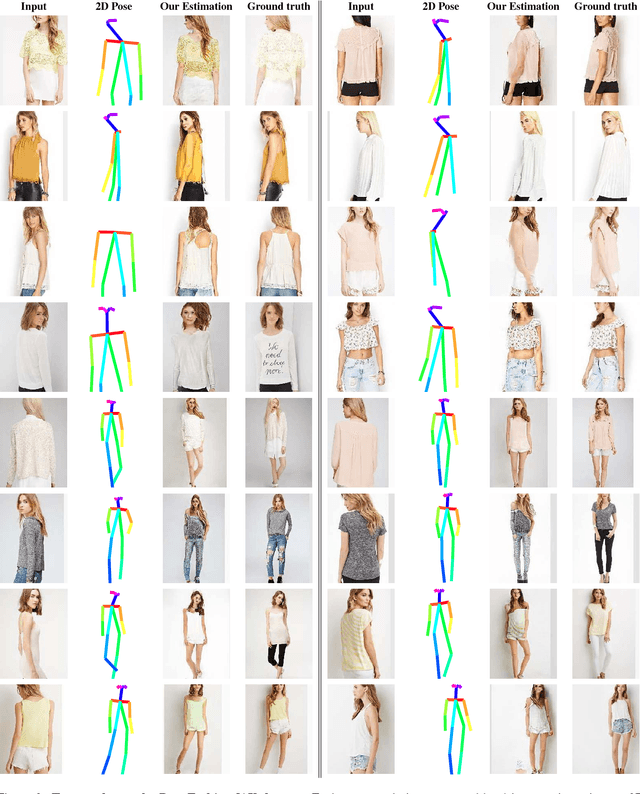

We present a novel approach for synthesizing photo-realistic images of people in arbitrary poses using generative adversarial learning. Given an input image of a person and a desired pose represented by a 2D skeleton, our model renders the image of the same person under the new pose, synthesizing novel views of the parts visible in the input image and hallucinating those that are not seen. This problem has recently been addressed in a supervised manner, i.e., during training the ground truth images under the new poses are given to the network. We go beyond these approaches by proposing a fully unsupervised strategy. We tackle this challenging scenario by splitting the problem into two principal subtasks. First, we consider a pose conditioned bidirectional generator that maps back the initially rendered image to the original pose, hence being directly comparable to the input image without the need to resort to any training image. Second, we devise a novel loss function that incorporates content and style terms, and aims at producing images of high perceptual quality. Extensive experiments conducted on the DeepFashion dataset demonstrate that the images rendered by our model are very close in appearance to those obtained by fully supervised approaches.
Hallucinating Dense Optical Flow from Sparse Lidar for Autonomous Vehicles
Aug 30, 2018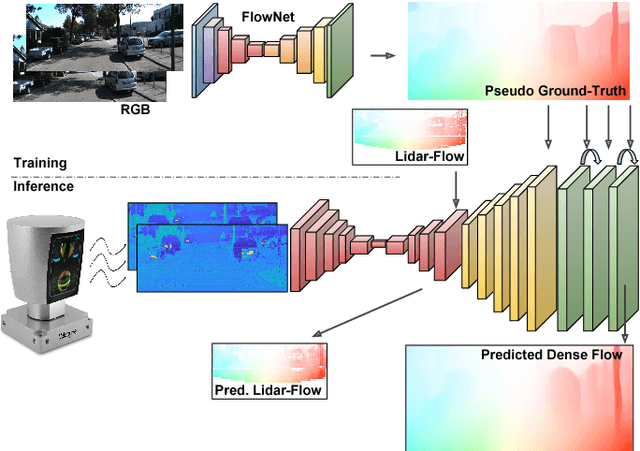
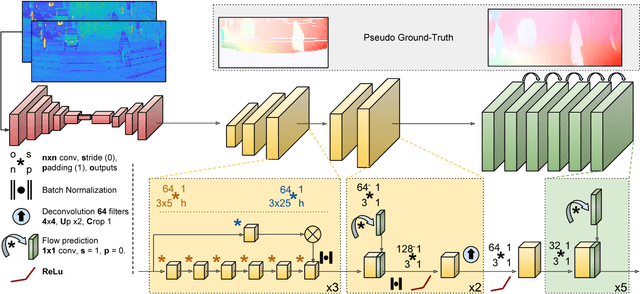
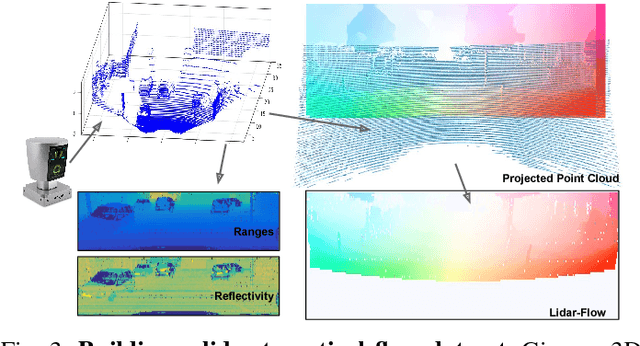

In this paper we propose a novel approach to estimate dense optical flow from sparse lidar data acquired on an autonomous vehicle. This is intended to be used as a drop-in replacement of any image-based optical flow system when images are not reliable due to e.g. adverse weather conditions or at night. In order to infer high resolution 2D flows from discrete range data we devise a three-block architecture of multiscale filters that combines multiple intermediate objectives, both in the lidar and image domain. To train this network we introduce a dataset with approximately 20K lidar samples of the Kitti dataset which we have augmented with a pseudo ground-truth image-based optical flow computed using FlowNet2. We demonstrate the effectiveness of our approach on Kitti, and show that despite using the low-resolution and sparse measurements of the lidar, we can regress dense optical flow maps which are at par with those estimated with image-based methods.