 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021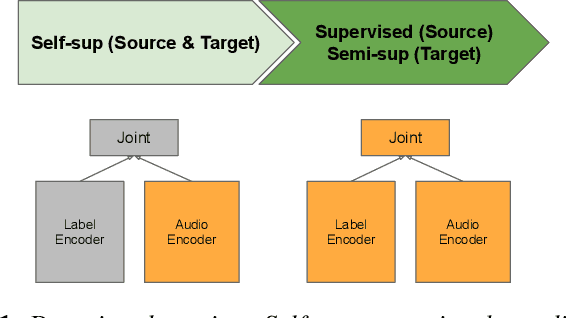

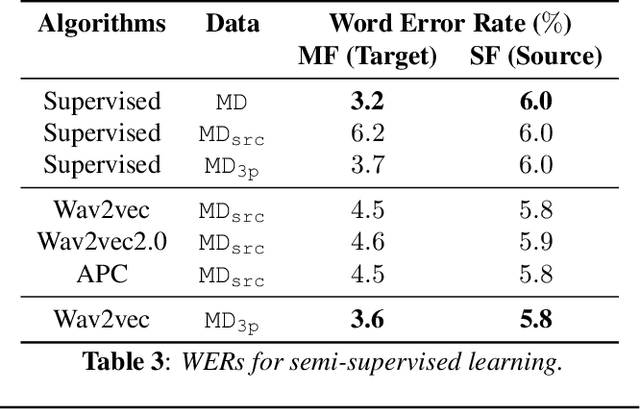
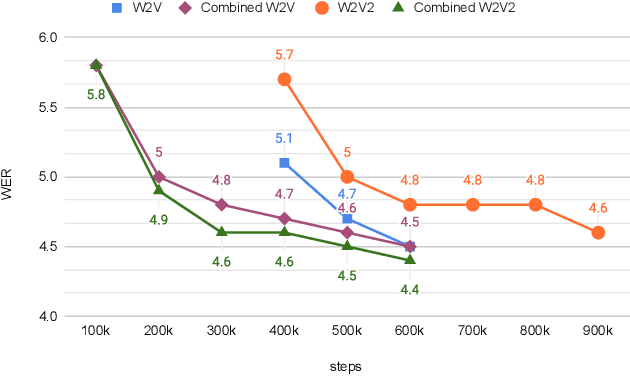
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Partial Variable Training for Efficient On-Device Federated Learning
Oct 11, 2021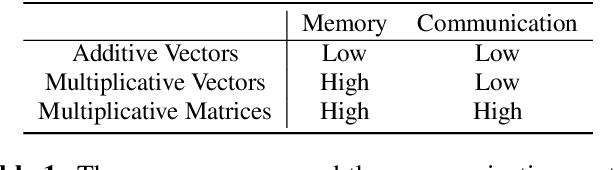
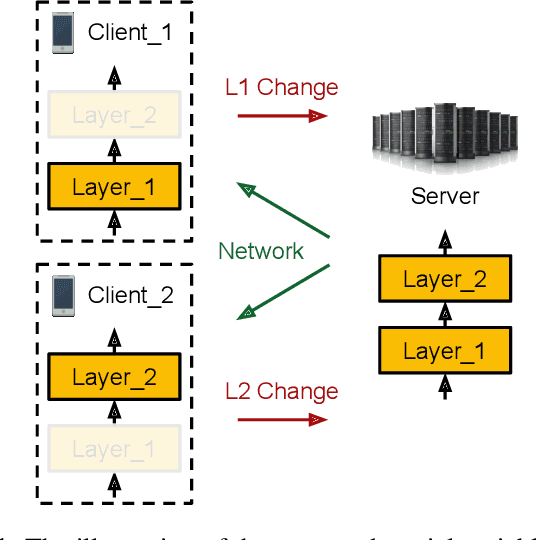
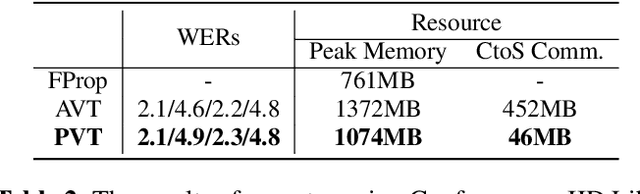
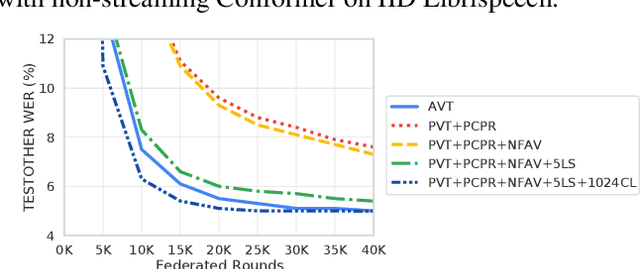
This paper aims to address the major challenges of Federated Learning (FL) on edge devices: limited memory and expensive communication. We propose a novel method, called Partial Variable Training (PVT), that only trains a small subset of variables on edge devices to reduce memory usage and communication cost. With PVT, we show that network accuracy can be maintained by utilizing more local training steps and devices, which is favorable for FL involving a large population of devices. According to our experiments on two state-of-the-art neural networks for speech recognition and two different datasets, PVT can reduce memory usage by up to 1.9$\times$ and communication cost by up to 593$\times$ while attaining comparable accuracy when compared with full network training.
Exploring Heterogeneous Characteristics of Layers in ASR Models for More Efficient Training
Oct 08, 2021

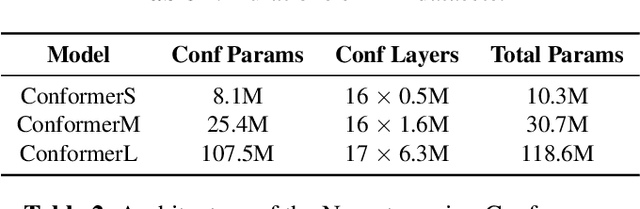
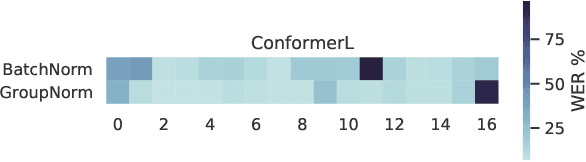
Transformer-based architectures have been the subject of research aimed at understanding their overparameterization and the non-uniform importance of their layers. Applying these approaches to Automatic Speech Recognition, we demonstrate that the state-of-the-art Conformer models generally have multiple ambient layers. We study the stability of these layers across runs and model sizes, propose that group normalization may be used without disrupting their formation, and examine their correlation with model weight updates in each layer. Finally, we apply these findings to Federated Learning in order to improve the training procedure, by targeting Federated Dropout to layers by importance. This allows us to reduce the model size optimized by clients without quality degradation, and shows potential for future exploration.
Fast Contextual Adaptation with Neural Associative Memory for On-Device Personalized Speech Recognition
Oct 07, 2021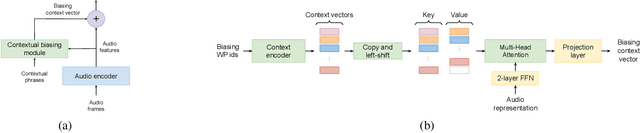
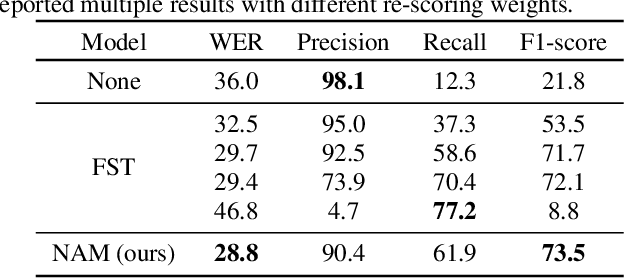
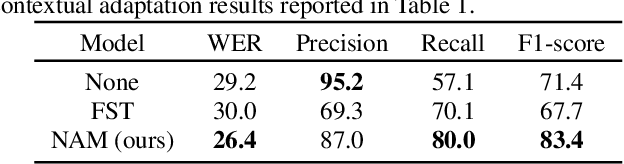

Fast contextual adaptation has shown to be effective in improving Automatic Speech Recognition (ASR) of rare words and when combined with an on-device personalized training, it can yield an even better recognition result. However, the traditional re-scoring approaches based on an external language model is prone to diverge during the personalized training. In this work, we introduce a model-based end-to-end contextual adaptation approach that is decoder-agnostic and amenable to on-device personalization. Our on-device simulation experiments demonstrate that the proposed approach outperforms the traditional re-scoring technique by 12% relative WER and 15.7% entity mention specific F1-score in a continues personalization scenario.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021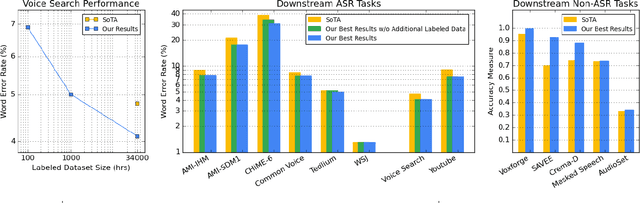
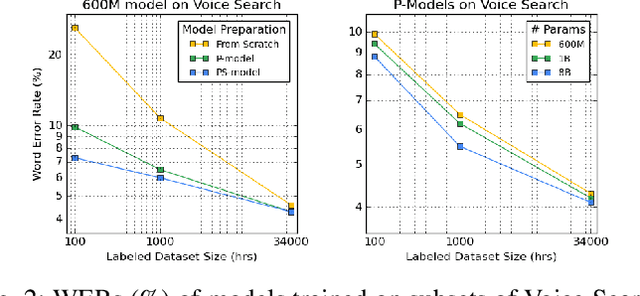
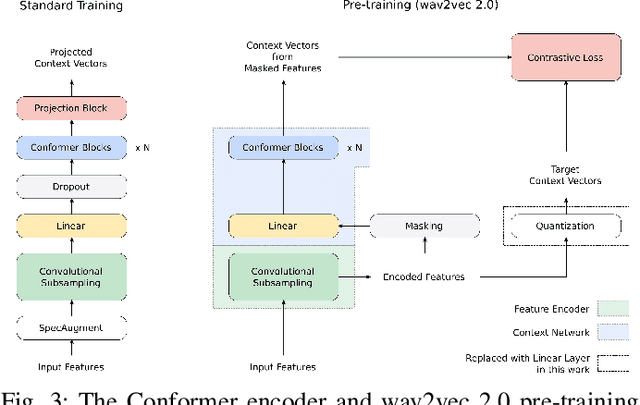
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Incremental Layer-wise Self-Supervised Learning for Efficient Speech Domain Adaptation On Device
Oct 01, 2021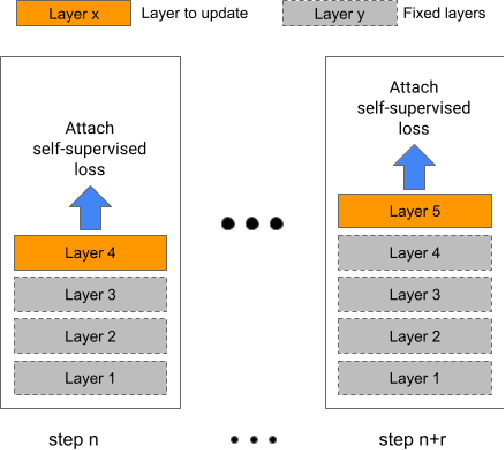
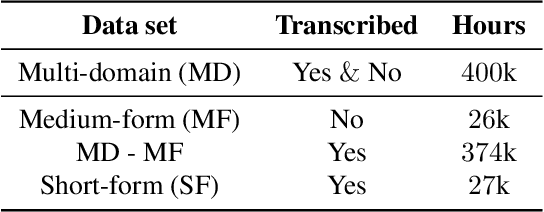
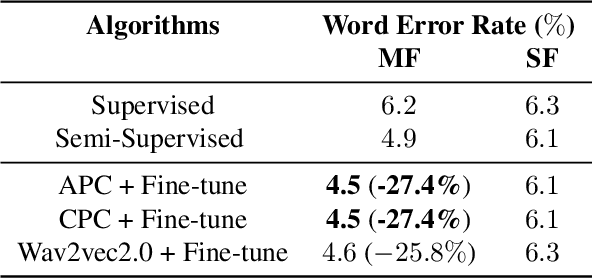
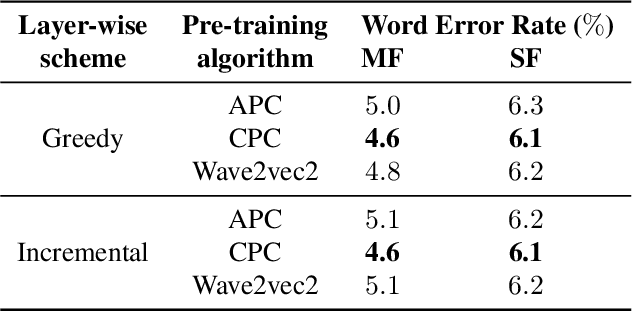
Streaming end-to-end speech recognition models have been widely applied to mobile devices and show significant improvement in efficiency. These models are typically trained on the server using transcribed speech data. However, the server data distribution can be very different from the data distribution on user devices, which could affect the model performance. There are two main challenges for on device training, limited reliable labels and limited training memory. While self-supervised learning algorithms can mitigate the mismatch between domains using unlabeled data, they are not applicable on mobile devices directly because of the memory constraint. In this paper, we propose an incremental layer-wise self-supervised learning algorithm for efficient speech domain adaptation on mobile devices, in which only one layer is updated at a time. Extensive experimental results demonstrate that the proposed algorithm obtains a Word Error Rate (WER) on the target domain $24.2\%$ better than supervised baseline and costs $89.7\%$ less training memory than the end-to-end self-supervised learning algorithm.
On-Device Personalization of Automatic Speech Recognition Models for Disordered Speech
Jun 18, 2021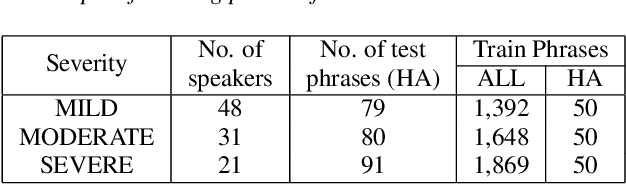
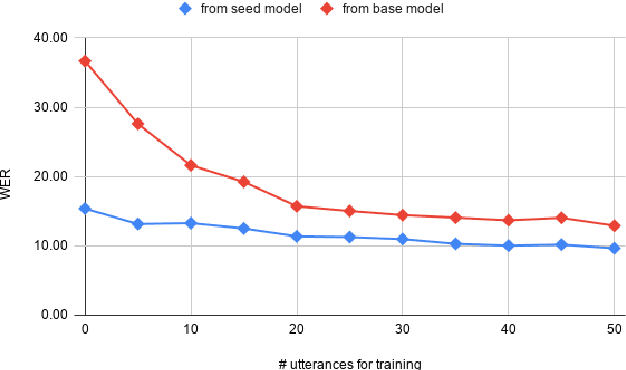
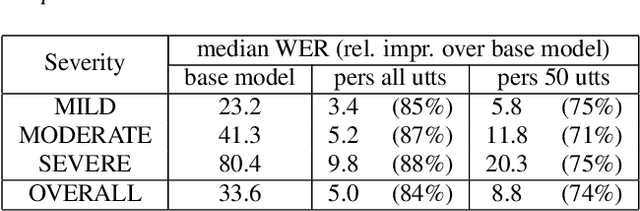
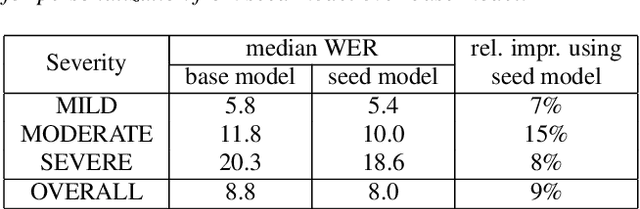
While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.
A Method to Reveal Speaker Identity in Distributed ASR Training, and How to Counter It
Apr 15, 2021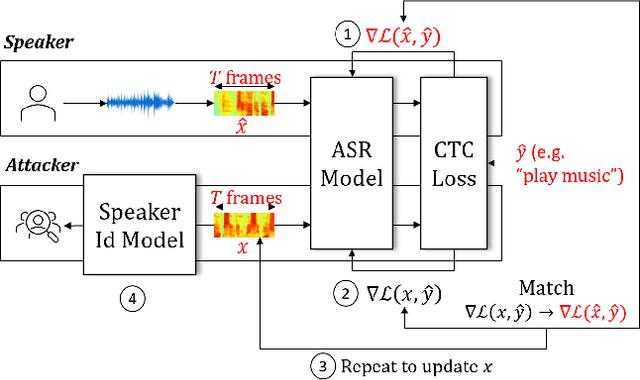

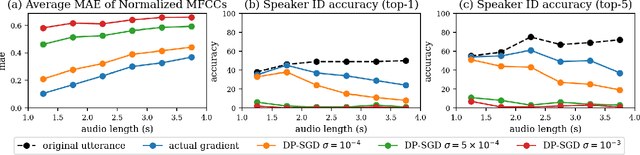
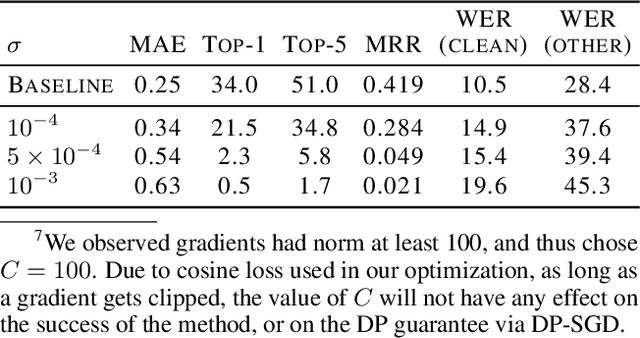
End-to-end Automatic Speech Recognition (ASR) models are commonly trained over spoken utterances using optimization methods like Stochastic Gradient Descent (SGD). In distributed settings like Federated Learning, model training requires transmission of gradients over a network. In this work, we design the first method for revealing the identity of the speaker of a training utterance with access only to a gradient. We propose Hessian-Free Gradients Matching, an input reconstruction technique that operates without second derivatives of the loss function (required in prior works), which can be expensive to compute. We show the effectiveness of our method using the DeepSpeech model architecture, demonstrating that it is possible to reveal the speaker's identity with 34% top-1 accuracy (51% top-5 accuracy) on the LibriSpeech dataset. Further, we study the effect of two well-known techniques, Differentially Private SGD and Dropout, on the success of our method. We show that a dropout rate of 0.2 can reduce the speaker identity accuracy to 0% top-1 (0.5% top-5).
Training Production Language Models without Memorizing User Data
Sep 21, 2020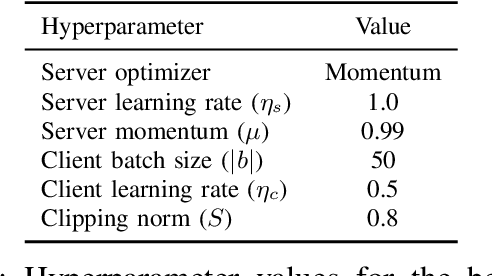
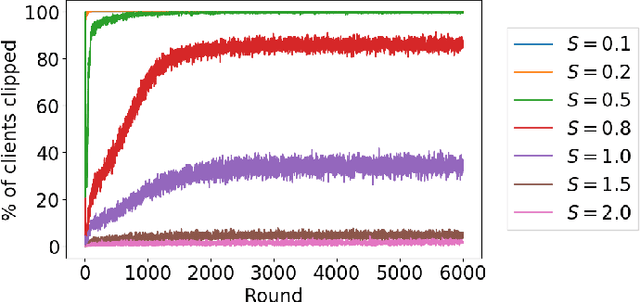
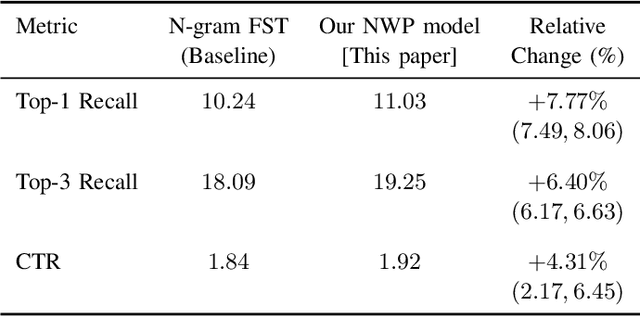
This paper presents the first consumer-scale next-word prediction (NWP) model trained with Federated Learning (FL) while leveraging the Differentially Private Federated Averaging (DP-FedAvg) technique. There has been prior work on building practical FL infrastructure, including work demonstrating the feasibility of training language models on mobile devices using such infrastructure. It has also been shown (in simulations on a public corpus) that it is possible to train NWP models with user-level differential privacy using the DP-FedAvg algorithm. Nevertheless, training production-quality NWP models with DP-FedAvg in a real-world production environment on a heterogeneous fleet of mobile phones requires addressing numerous challenges. For instance, the coordinating central server has to keep track of the devices available at the start of each round and sample devices uniformly at random from them, while ensuring \emph{secrecy of the sample}, etc. Unlike all prior privacy-focused FL work of which we are aware, for the first time we demonstrate the deployment of a differentially private mechanism for the training of a production neural network in FL, as well as the instrumentation of the production training infrastructure to perform an end-to-end empirical measurement of unintended memorization.
Understanding Unintended Memorization in Federated Learning
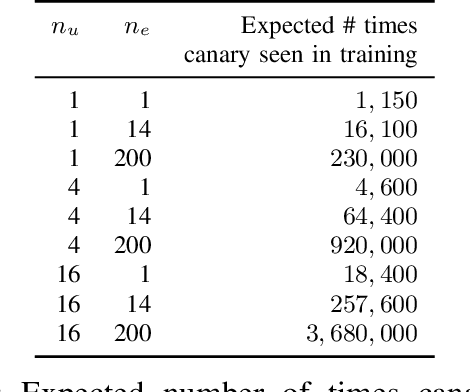
Jun 12, 2020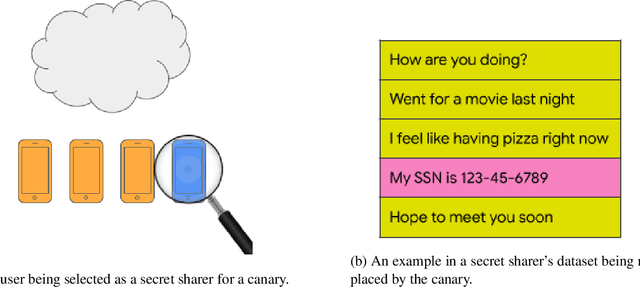
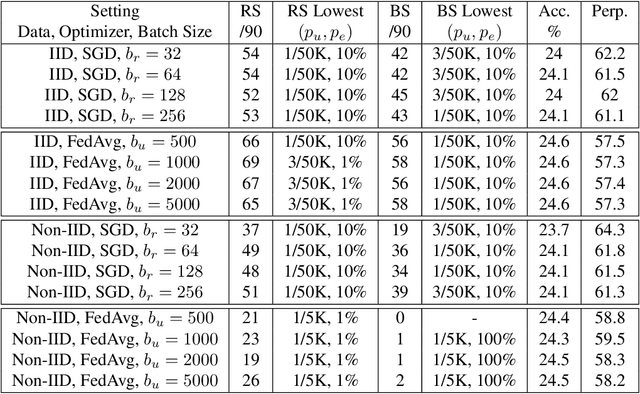
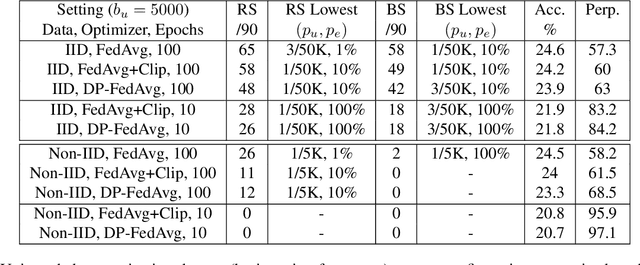
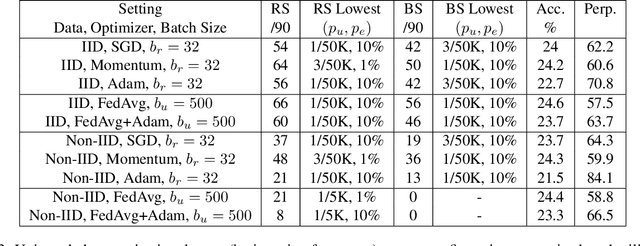
Recent works have shown that generative sequence models (e.g., language models) have a tendency to memorize rare or unique sequences in the training data. Since useful models are often trained on sensitive data, to ensure the privacy of the training data it is critical to identify and mitigate such unintended memorization. Federated Learning (FL) has emerged as a novel framework for large-scale distributed learning tasks. However, it differs in many aspects from the well-studied central learning setting where all the data is stored at the central server. In this paper, we initiate a formal study to understand the effect of different components of canonical FL on unintended memorization in trained models, comparing with the central learning setting. Our results show that several differing components of FL play an important role in reducing unintended memorization. Specifically, we observe that the clustering of data according to users---which happens by design in FL---has a significant effect in reducing such memorization, and using the method of Federated Averaging for training causes a further reduction. We also show that training with a strong user-level differential privacy guarantee results in models that exhibit the least amount of unintended memorization.