 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Memorization Across Neural Language Models
Feb 24, 2022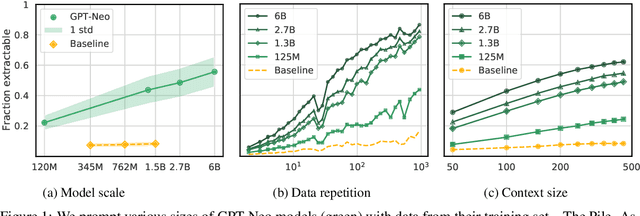
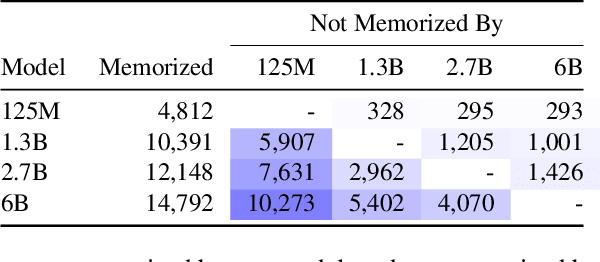
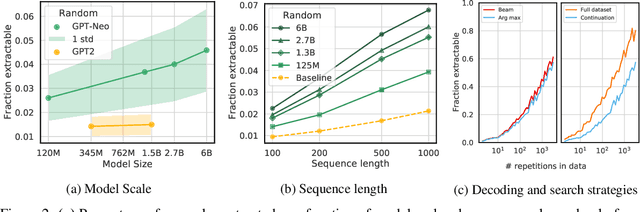
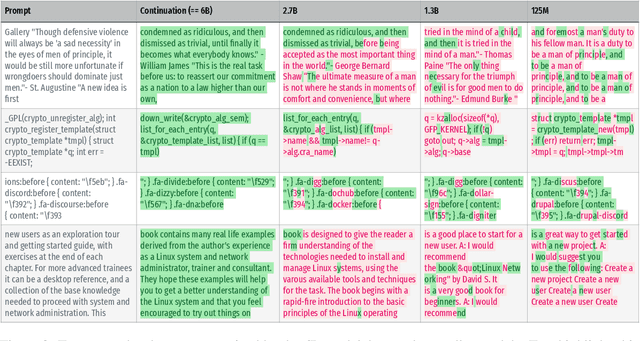
Large language models (LMs) have been shown to memorize parts of their training data, and when prompted appropriately, they will emit the memorized training data verbatim. This is undesirable because memorization violates privacy (exposing user data), degrades utility (repeated easy-to-memorize text is often low quality), and hurts fairness (some texts are memorized over others). We describe three log-linear relationships that quantify the degree to which LMs emit memorized training data. Memorization significantly grows as we increase (1) the capacity of a model, (2) the number of times an example has been duplicated, and (3) the number of tokens of context used to prompt the model. Surprisingly, we find the situation becomes complicated when generalizing these results across model families. On the whole, we find that memorization in LMs is more prevalent than previously believed and will likely get worse as models continues to scale, at least without active mitigations.
Membership Inference Attacks From First Principles
Dec 07, 2021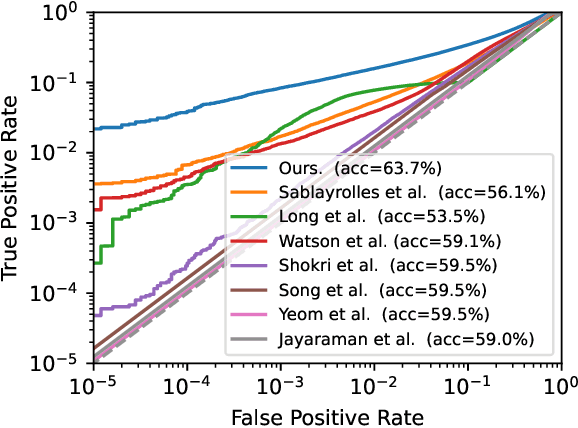
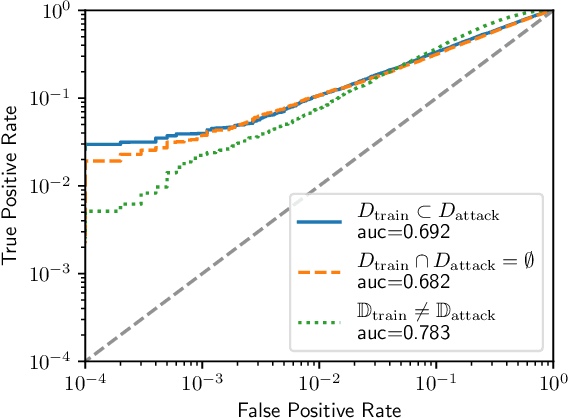
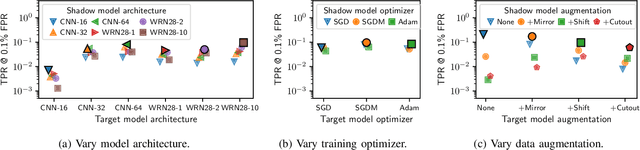
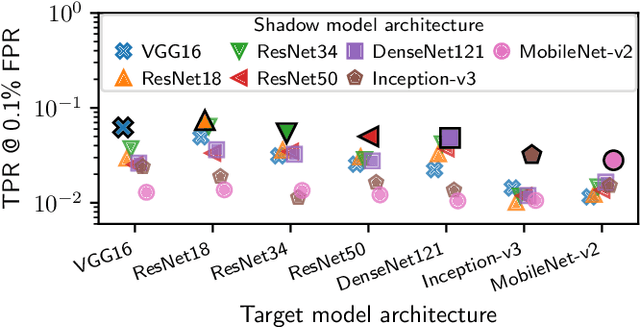
A membership inference attack allows an adversary to query a trained machine learning model to predict whether or not a particular example was contained in the model's training dataset. These attacks are currently evaluated using average-case "accuracy" metrics that fail to characterize whether the attack can confidently identify any members of the training set. We argue that attacks should instead be evaluated by computing their true-positive rate at low (e.g., <0.1%) false-positive rates, and find most prior attacks perform poorly when evaluated in this way. To address this we develop a Likelihood Ratio Attack (LiRA) that carefully combines multiple ideas from the literature. Our attack is 10x more powerful at low false-positive rates, and also strictly dominates prior attacks on existing metrics.
Extracting Training Data from Large Language Models
Dec 14, 2020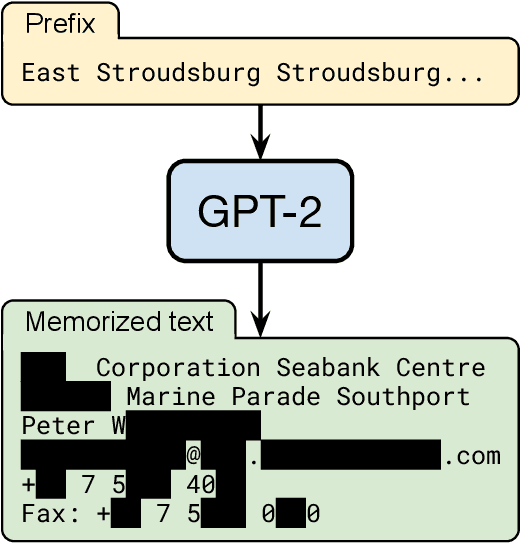
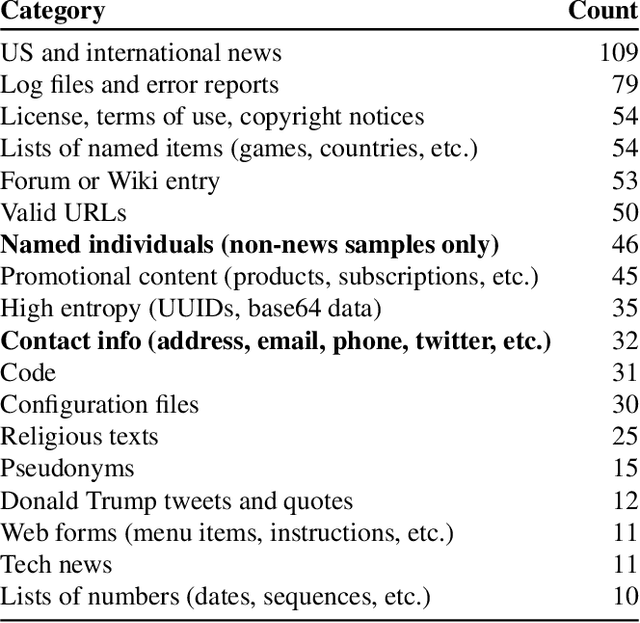
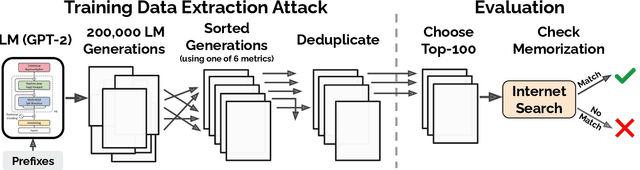
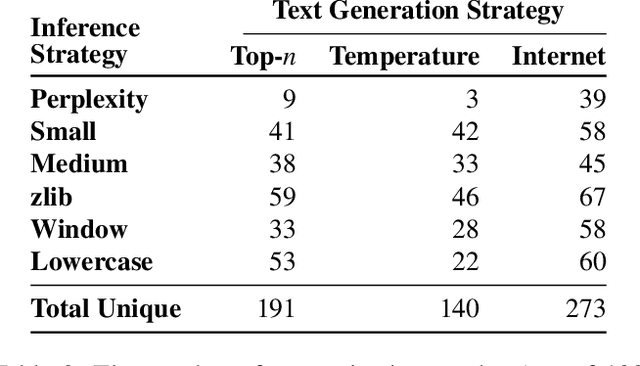
It has become common to publish large (billion parameter) language models that have been trained on private datasets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model. We demonstrate our attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model's training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data. We comprehensively evaluate our extraction attack to understand the factors that contribute to its success. For example, we find that larger models are more vulnerable than smaller models. We conclude by drawing lessons and discussing possible safeguards for training large language models.
An Attack on InstaHide: Is Private Learning Possible with Instance Encoding?
Nov 10, 2020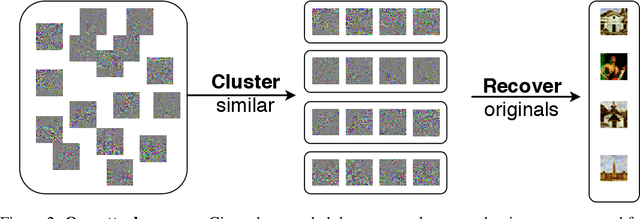



A learning algorithm is private if the produced model does not reveal (too much) about its training set. InstaHide [Huang, Song, Li, Arora, ICML'20] is a recent proposal that claims to preserve privacy by an encoding mechanism that modifies the inputs before being processed by the normal learner. We present a reconstruction attack on InstaHide that is able to use the encoded images to recover visually recognizable versions of the original images. Our attack is effective and efficient, and empirically breaks InstaHide on CIFAR-10, CIFAR-100, and the recently released InstaHide Challenge. We further formalize various privacy notions of learning through instance encoding and investigate the possibility of achieving these notions. We prove barriers against achieving (indistinguishability based notions of) privacy through any learning protocol that uses instance encoding.
Label-Only Membership Inference Attacks
Jul 28, 2020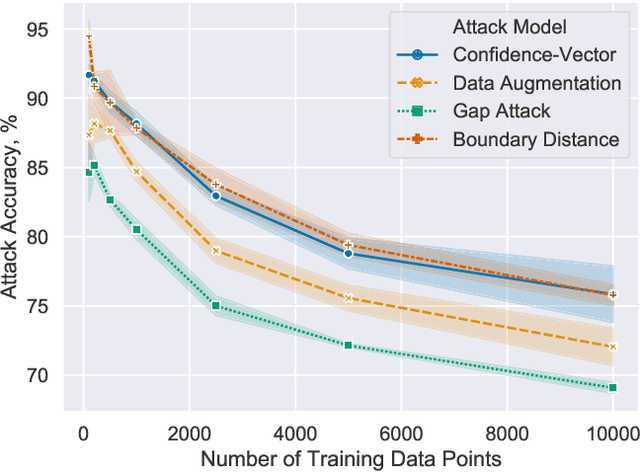
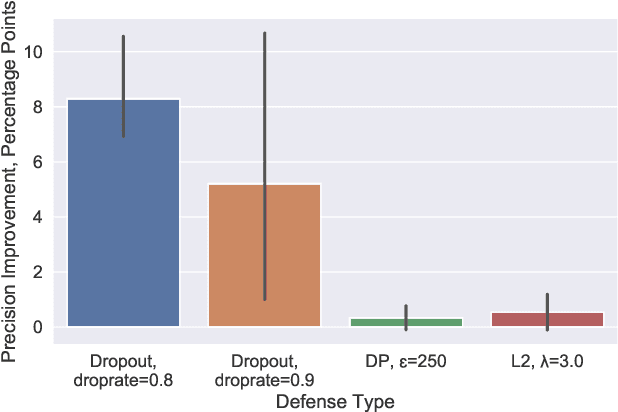
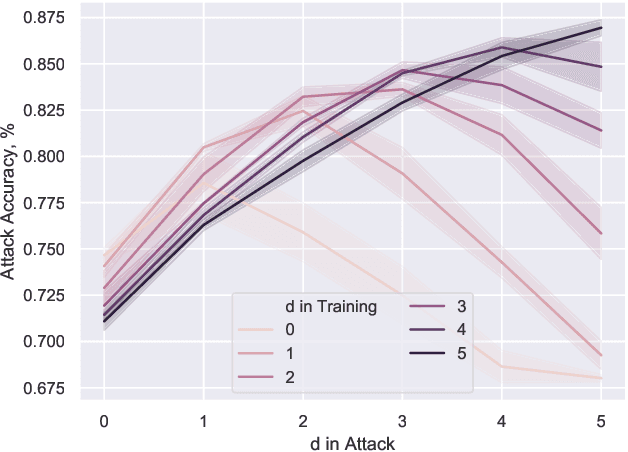
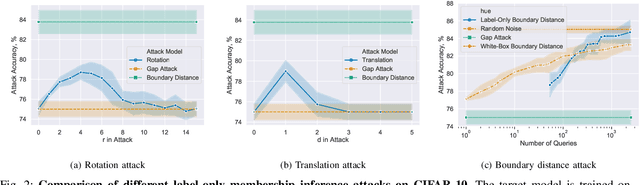
Membership inference attacks are one of the simplest forms of privacy leakage for machine learning models: given a data point and model, determine whether the point was used to train the model. Existing membership inference attacks exploit models' abnormal confidence when queried on their training data. These attacks do not apply if the adversary only gets access to models' predicted labels, without a confidence measure. In this paper, we introduce label-only membership inference attacks. Instead of relying on confidence scores, our attacks evaluate the robustness of a model's predicted labels under perturbations to obtain a fine-grained membership signal. These perturbations include common data augmentations or adversarial examples. We empirically show that our label-only membership inference attacks perform on par with prior attacks that required access to model confidences. We further demonstrate that label-only attacks break multiple defenses against membership inference attacks that (implicitly or explicitly) rely on a phenomenon we call confidence masking. These defenses modify a model's confidence scores in order to thwart attacks, but leave the model's predicted labels unchanged. Our label-only attacks demonstrate that confidence-masking is not a viable defense strategy against membership inference. Finally, we investigate worst-case label-only attacks, that infer membership for a small number of outlier data points. We show that label-only attacks also match confidence-based attacks in this setting. We find that training models with differential privacy and (strong) L2 regularization are the only known defense strategies that successfully prevents all attacks. This remains true even when the differential privacy budget is too high to offer meaningful provable guarantees.
On Adaptive Attacks to Adversarial Example Defenses
Feb 19, 2020
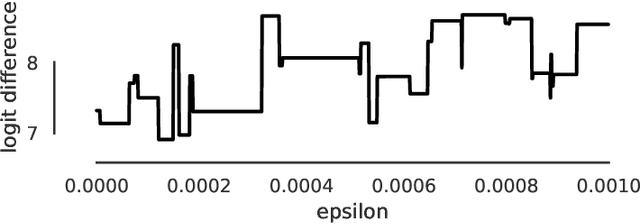
Adaptive attacks have (rightfully) become the de facto standard for evaluating defenses to adversarial examples. We find, however, that typical adaptive evaluations are incomplete. We demonstrate that thirteen defenses recently published at ICLR, ICML and NeurIPS---and chosen for illustrative and pedagogical purposes---can be circumvented despite attempting to perform evaluations using adaptive attacks. While prior evaluation papers focused mainly on the end result---showing that a defense was ineffective---this paper focuses on laying out the methodology and the approach necessary to perform an adaptive attack. We hope that these analyses will serve as guidance on how to properly perform adaptive attacks against defenses to adversarial examples, and thus will allow the community to make further progress in building more robust models.
Physical Adversarial Examples for Object Detectors
Oct 05, 2018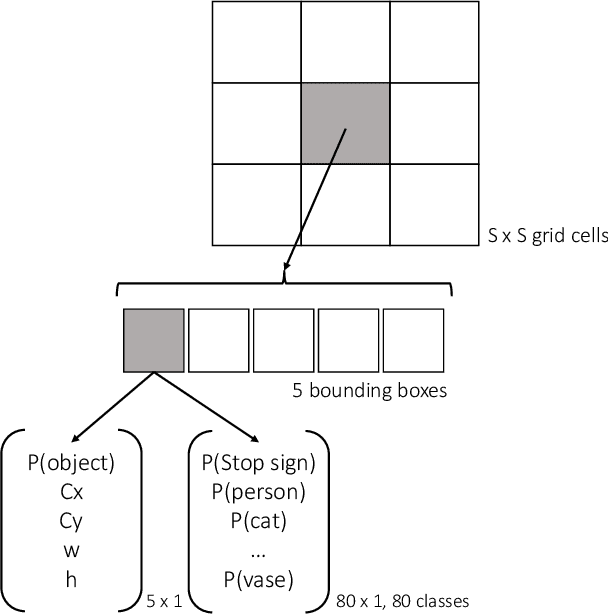
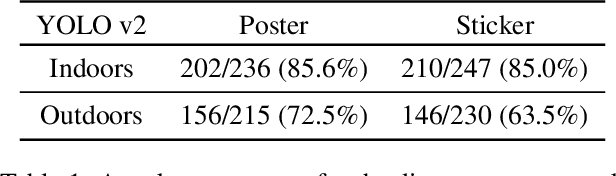

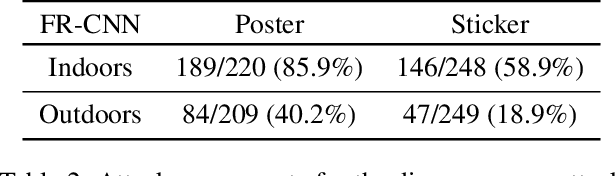
Deep neural networks (DNNs) are vulnerable to adversarial examples-maliciously crafted inputs that cause DNNs to make incorrect predictions. Recent work has shown that these attacks generalize to the physical domain, to create perturbations on physical objects that fool image classifiers under a variety of real-world conditions. Such attacks pose a risk to deep learning models used in safety-critical cyber-physical systems. In this work, we extend physical attacks to more challenging object detection models, a broader class of deep learning algorithms widely used to detect and label multiple objects within a scene. Improving upon a previous physical attack on image classifiers, we create perturbed physical objects that are either ignored or mislabeled by object detection models. We implement a Disappearance Attack, in which we cause a Stop sign to "disappear" according to the detector-either by covering thesign with an adversarial Stop sign poster, or by adding adversarial stickers onto the sign. In a video recorded in a controlled lab environment, the state-of-the-art YOLOv2 detector failed to recognize these adversarial Stop signs in over 85% of the video frames. In an outdoor experiment, YOLO was fooled by the poster and sticker attacks in 72.5% and 63.5% of the video frames respectively. We also use Faster R-CNN, a different object detection model, to demonstrate the transferability of our adversarial perturbations. The created poster perturbation is able to fool Faster R-CNN in 85.9% of the video frames in a controlled lab environment, and 40.2% of the video frames in an outdoor environment. Finally, we present preliminary results with a new Creation Attack, where in innocuous physical stickers fool a model into detecting nonexistent objects.
Note on Attacking Object Detectors with Adversarial Stickers
Jul 23, 2018


Deep learning has proven to be a powerful tool for computer vision and has seen widespread adoption for numerous tasks. However, deep learning algorithms are known to be vulnerable to adversarial examples. These adversarial inputs are created such that, when provided to a deep learning algorithm, they are very likely to be mislabeled. This can be problematic when deep learning is used to assist in safety critical decisions. Recent research has shown that classifiers can be attacked by physical adversarial examples under various physical conditions. Given the fact that state-of-the-art objection detection algorithms are harder to be fooled by the same set of adversarial examples, here we show that these detectors can also be attacked by physical adversarial examples. In this note, we briefly show both static and dynamic test results. We design an algorithm that produces physical adversarial inputs, which can fool the YOLO object detector and can also attack Faster-RCNN with relatively high success rate based on transferability. Furthermore, our algorithm can compress the size of the adversarial inputs to stickers that, when attached to the targeted object, result in the detector either mislabeling or not detecting the object a high percentage of the time. This note provides a small set of results. Our upcoming paper will contain a thorough evaluation on other object detectors, and will present the algorithm.
Slalom: Fast, Verifiable and Private Execution of Neural Networks in Trusted Hardware
Jun 08, 2018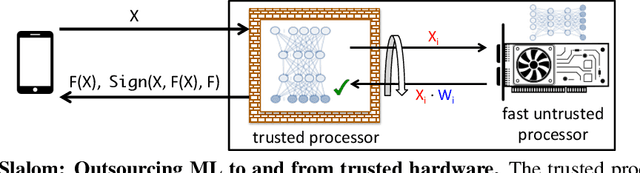


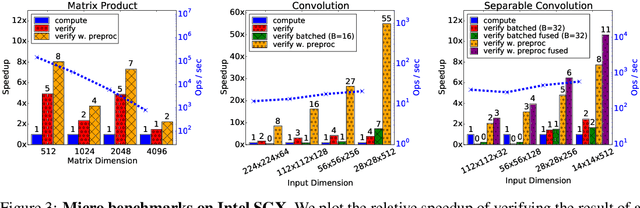
As Machine Learning (ML) gets applied to security-critical or sensitive domains, there is a growing need for integrity and privacy guarantees for ML computations running in untrusted environments. A pragmatic solution comes from Trusted Execution Environments, which use hardware and software protections to isolate sensitive computations from the untrusted software stack. However, these isolation guarantees come at a price in performance, compared to untrusted alternatives. This paper initiates the study of high performance execution of Deep Neural Networks (DNNs) in trusted environments by efficiently partitioning computations between trusted and untrusted devices. Building upon a simple secure outsourcing scheme for matrix multiplication, we propose Slalom, a framework that outsources execution of all linear layers in a DNN from any trusted environment (e.g., SGX, TrustZone or Sanctum) to a faster co-located device. We evaluate Slalom by executing DNNs in an Intel SGX enclave, which selectively outsources work to an untrusted GPU. For two canonical DNNs, VGG16 and MobileNet, we obtain 20x and 6x increases in throughput for verifiable inference, and 10x and 3.5x for verifiable and private inference.