 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Monte Carlo Transformer: a stochastic self-attention model for sequence prediction
Jul 15, 2020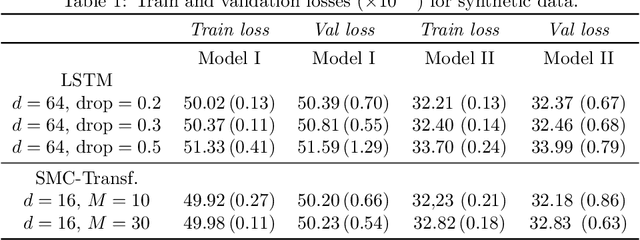
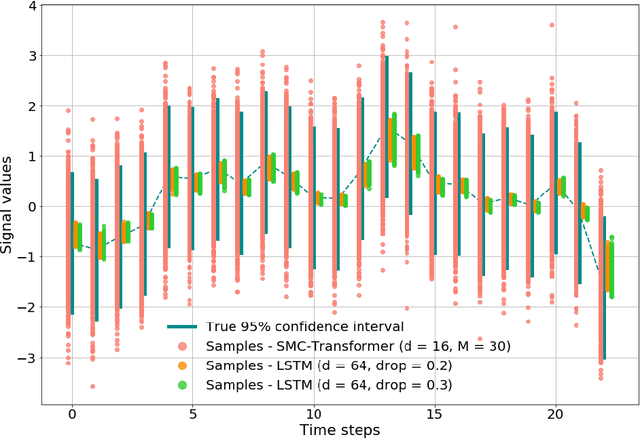
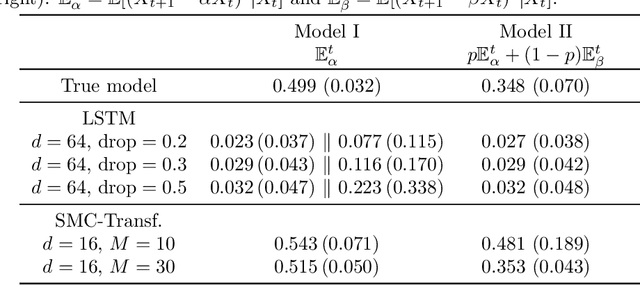
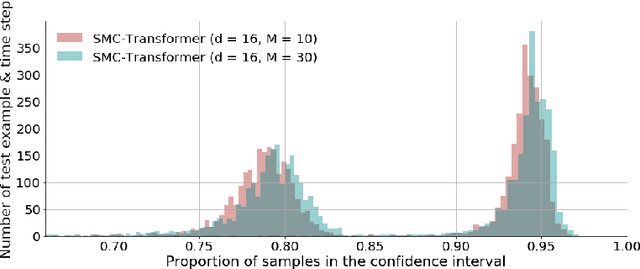
This paper introduces the Sequential Monte Carlo Transformer, an original approach that naturally captures the observations distribution in a recurrent architecture. The keys, queries, values and attention vectors of the network are considered as the unobserved stochastic states of its hidden structure. This generative model is such that at each time step the received observation is a random function of these past states in a given attention window. In this general state-space setting, we use Sequential Monte Carlo methods to approximate the posterior distributions of the states given the observations, and then to estimate the gradient of the log-likelihood. We thus propose a generative model providing a predictive distribution, instead of a single-point estimate.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020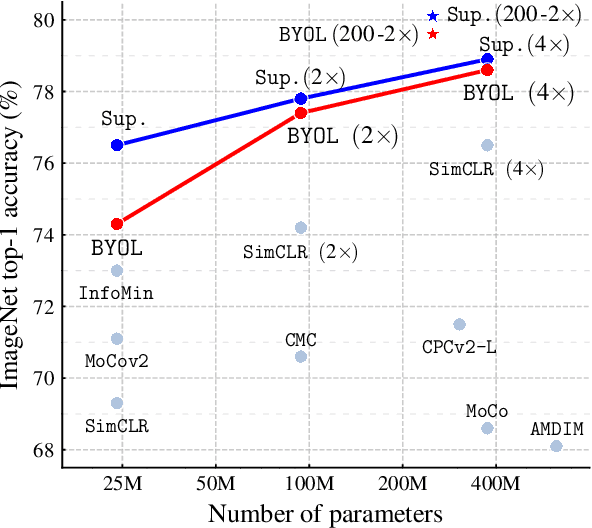

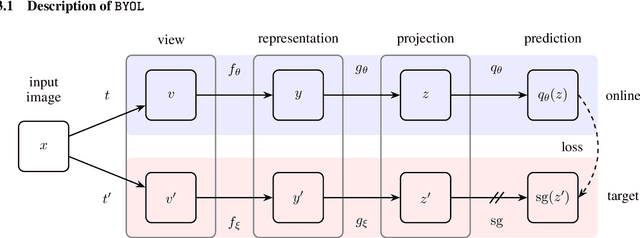
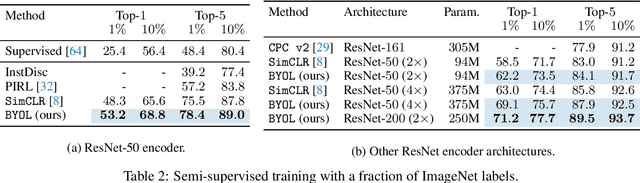
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
Countering Language Drift with Seeded Iterated Learning
Apr 06, 2020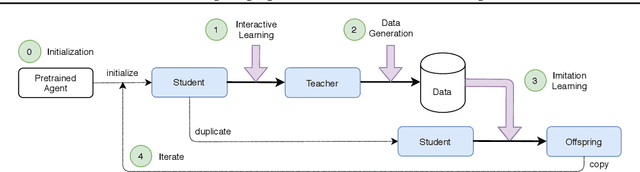

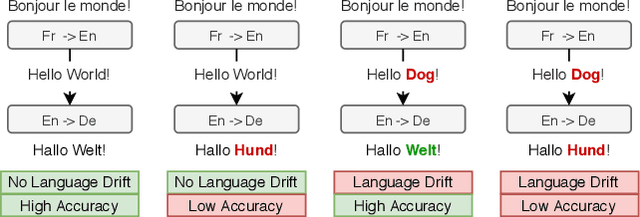
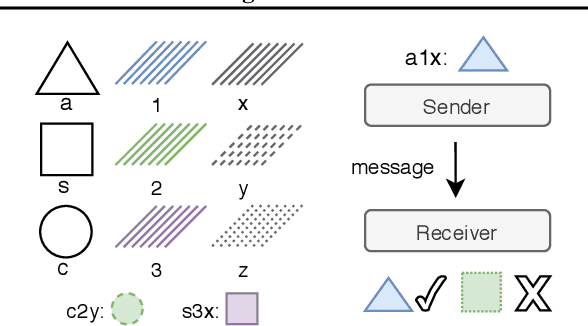
Supervised learning methods excel at capturing statistical properties of language when trained over large text corpora. Yet, these models often produce inconsistent outputs in goal-oriented language settings as they are not trained to complete the underlying task. Moreover, as soon as the agents are finetuned to maximize task completion, they suffer from the so-called language drift phenomenon: they slowly lose syntactic and semantic properties of language as they only focus on solving the task. In this paper, we propose a generic approach to counter language drift by using iterated learning. We iterate between fine-tuning agents with interactive training steps, and periodically replacing them with new agents that are seeded from last iteration and trained to imitate the latest finetuned models. Iterated learning does not require external syntactic constraint nor semantic knowledge, making it a valuable task-agnostic finetuning protocol. We first explore iterated learning in the Lewis Game. We then scale-up the approach in the translation game. In both settings, our results show that iterated learn-ing drastically counters language drift as well as it improves the task completion metric.
Self-Educated Language Agent With Hindsight Experience Replay For Instruction Following
Oct 21, 2019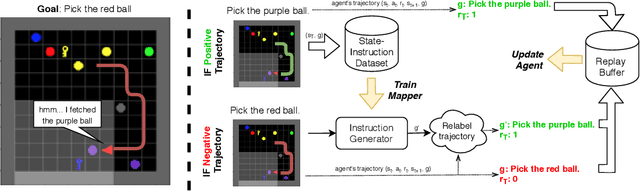

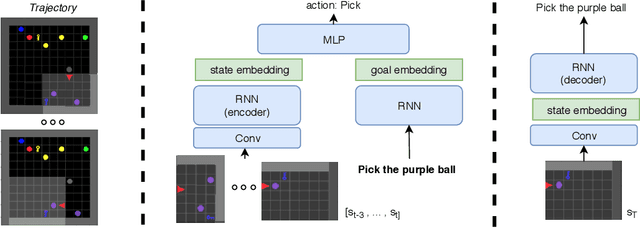
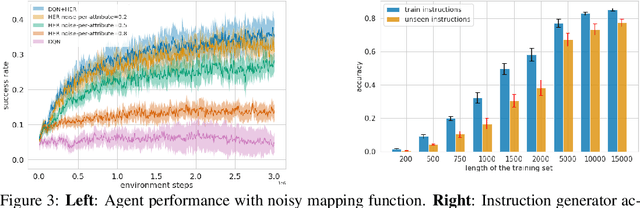
Language creates a compact representation of the world and allows the description of unlimited situations and objectives through compositionality. These properties make it a natural fit to guide the training of interactive agents as it could ease recurrent challenges in Reinforcement Learning such as sample complexity, generalization, or multi-tasking. Yet, it remains an open-problem to relate language and RL in even simple instruction following scenarios. Current methods rely on expert demonstrations, auxiliary losses, or inductive biases in neural architectures. In this paper, we propose an orthogonal approach called Textual Hindsight Experience Replay (THER) that extends the Hindsight Experience Replay approach to the language setting. Whenever the agent does not fulfill its instruction, THER learns to output a new directive that matches the agent trajectory, and it relabels the episode with a positive reward. To do so, THER learns to map a state into an instruction by using past successful trajectories, which removes the need to have external expert interventions to relabel episodes as in vanilla HER. We observe that this simple idea also initiates a learning synergy between language acquisition and policy learning on instruction following tasks in the BabyAI environment.
Accurate reconstruction of EBSD datasets by a multimodal data approach using an evolutionary algorithm
Mar 08, 2019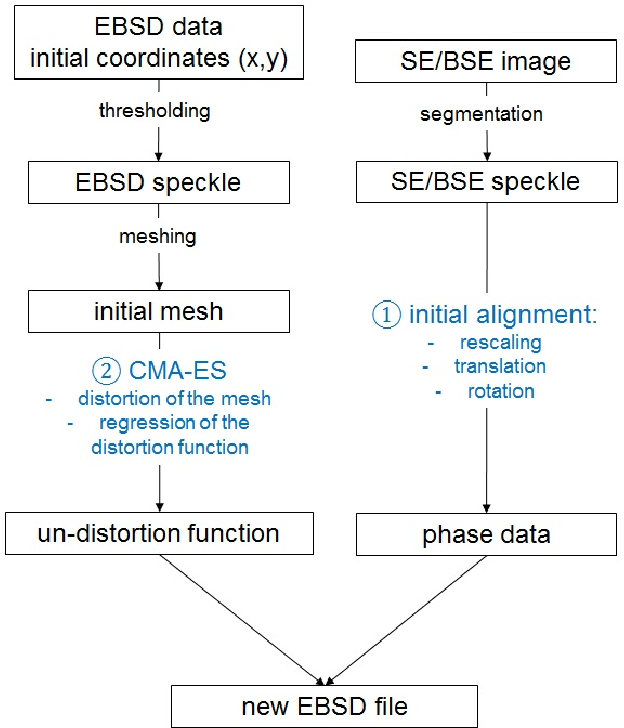

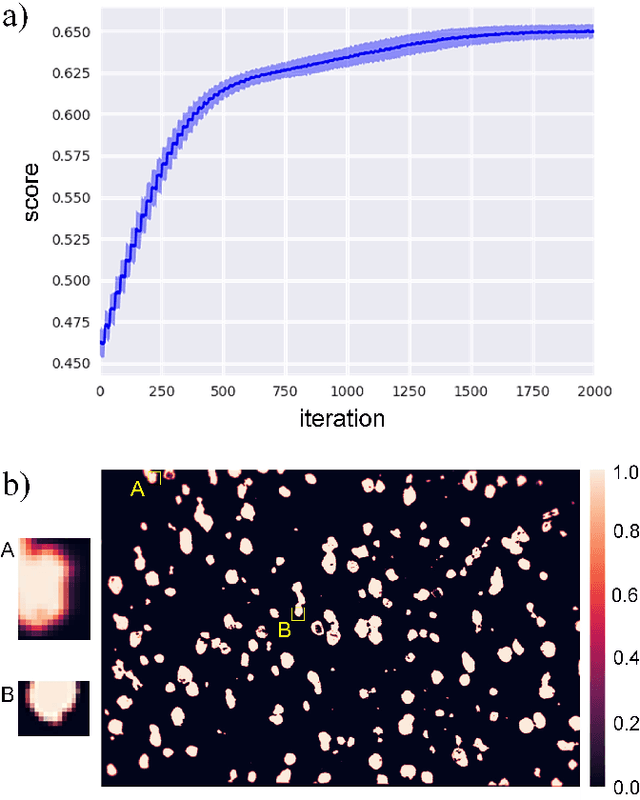
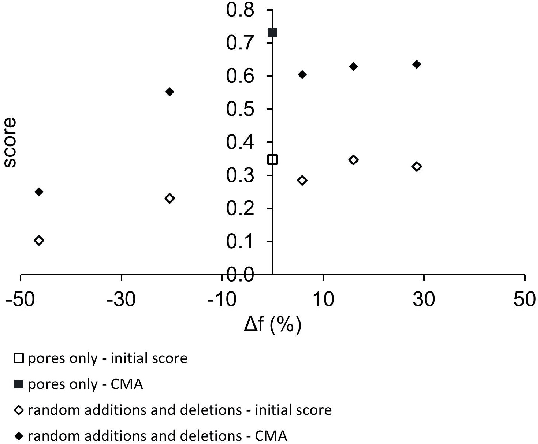
A new method has been developed for the correction of the distortions and/or enhanced phase differentiation in Electron Backscatter Diffraction (EBSD) data. Using a multi-modal data approach, the method uses segmented images of the phase of interest (laths, precipitates, voids, inclusions) on images gathered by backscattered or secondary electrons of the same area as the EBSD map. The proposed approach then search for the best transformation to correct their relative distortions and recombines the data in a new EBSD file. Speckles of the features of interest are first segmented in both the EBSD and image data modes. The speckle extracted from the EBSD data is then meshed, and the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) is implemented to distort the mesh until the speckles superimpose. The quality of the matching is quantified via a score that is linked to the number of overlapping pixels in the speckles. The locations of the points of the distorted mesh are compared to those of the initial positions to create pairs of matching points that are used to calculate the polynomial function that describes the distortion the best. This function is then applied to un-distort the EBSD data, and the phase information is inferred using the data of the segmented speckle. Fast and versatile, this method does not require any human annotation and can be applied to large datasets and wide areas. Besides, this method requires very few assumptions concerning the shape of the distortion function. It can be used for the single compensation of the distortions or combined with the phase differentiation. The accuracy of this method is of the order of the pixel size. Some application examples in multiphase materials with feature sizes down to 1 $\mu$m are presented, including Ti-6Al-4V Titanium alloy, Rene 65 and additive manufactured Inconel 718 Nickel-base superalloys.
* A short version of this paper exists towards people working in Machine Learning, namely arxiv:1903.02982
Correction of Electron Back-scattered Diffraction datasets using an evolutionary algorithm
Mar 07, 2019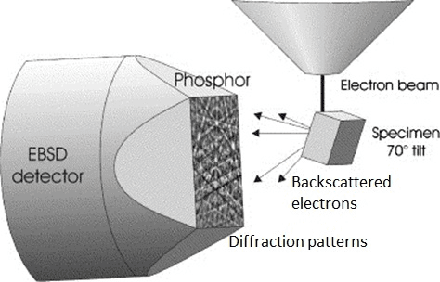



In materials science and particularly electron microscopy, Electron Back-scatter Diffraction (EBSD) is a common and powerful mapping technique for collecting local crystallographic data at the sub-micron scale. The quality of the reconstruction of the maps is critical to study the spatial distribution of phases and crystallographic orientation relationships between phases, a key interest in materials science. However, EBSD data is known to suffer from distortions that arise from several instrument and detector artifacts. In this paper, we present an unsupervised method that corrects those distortions, and enables or enhances phase differentiation in EBSD data. The method uses a segmented electron image of the phases of interest (laths, precipitates, voids, inclusions) gathered using detectors that generate less distorted data, of the same area than the EBSD map, and then searches for the best transformation to correct the distortions of the initial EBSD data. To do so, the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) is implemented to distort the EBSD until it matches the reference electron image. Fast and versatile, this method does not require any human annotation and can be applied to large datasets and wide areas, where the distortions are important. Besides, this method requires very little assumption concerning the shape of the distortion function. Some application examples in multiphase materials with feature sizes down to 1 $\mu$m are presented, including a Titanium alloy and a Nickel-base superalloy.
Deep Reinforcement Learning and the Deadly Triad
Dec 06, 2018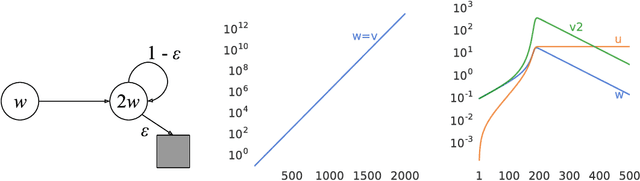
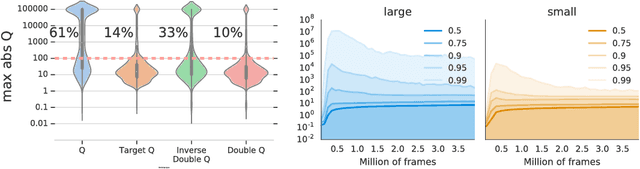
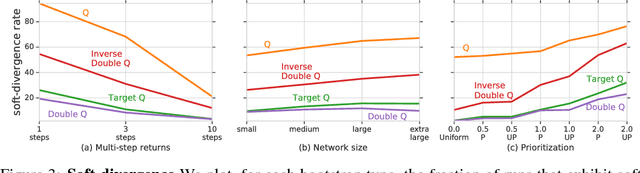
We know from reinforcement learning theory that temporal difference learning can fail in certain cases. Sutton and Barto (2018) identify a deadly triad of function approximation, bootstrapping, and off-policy learning. When these three properties are combined, learning can diverge with the value estimates becoming unbounded. However, several algorithms successfully combine these three properties, which indicates that there is at least a partial gap in our understanding. In this work, we investigate the impact of the deadly triad in practice, in the context of a family of popular deep reinforcement learning models - deep Q-networks trained with experience replay - analysing how the components of this system play a role in the emergence of the deadly triad, and in the agent's performance
Visual Reasoning with Multi-hop Feature Modulation
Oct 12, 2018
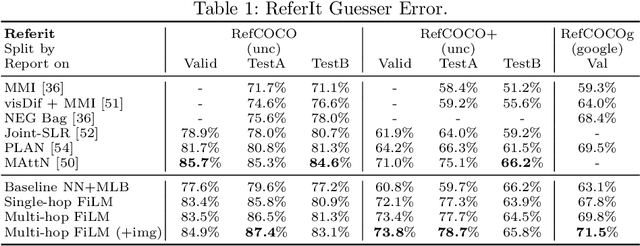
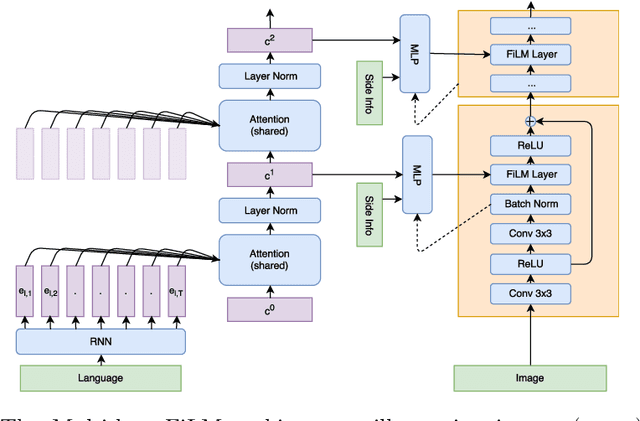
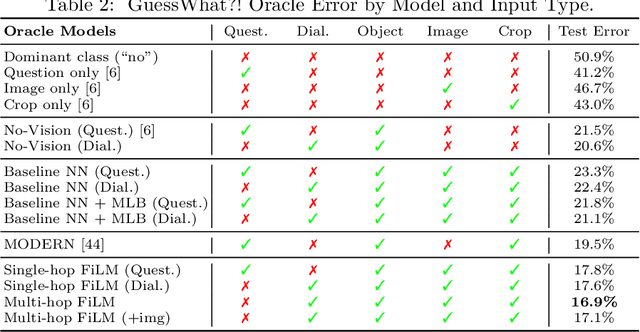
Recent breakthroughs in computer vision and natural language processing have spurred interest in challenging multi-modal tasks such as visual question-answering and visual dialogue. For such tasks, one successful approach is to condition image-based convolutional network computation on language via Feature-wise Linear Modulation (FiLM) layers, i.e., per-channel scaling and shifting. We propose to generate the parameters of FiLM layers going up the hierarchy of a convolutional network in a multi-hop fashion rather than all at once, as in prior work. By alternating between attending to the language input and generating FiLM layer parameters, this approach is better able to scale to settings with longer input sequences such as dialogue. We demonstrate that multi-hop FiLM generation achieves state-of-the-art for the short input sequence task ReferIt --- on-par with single-hop FiLM generation --- while also significantly outperforming prior state-of-the-art and single-hop FiLM generation on the GuessWhat?! visual dialogue task.
Hybrid Recommender System based on Autoencoders
Dec 29, 2017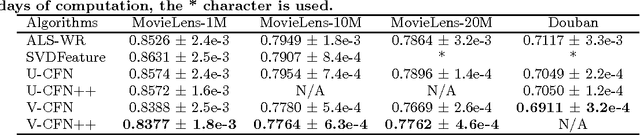
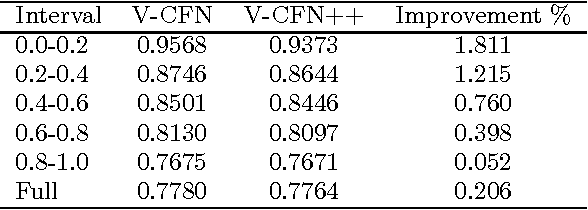
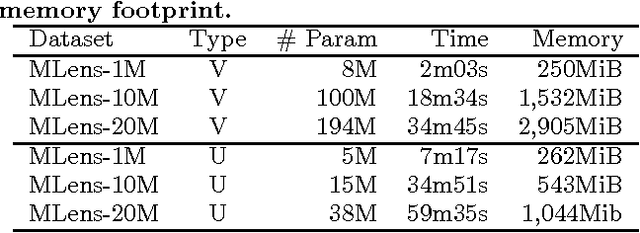
A standard model for Recommender Systems is the Matrix Completion setting: given partially known matrix of ratings given by users (rows) to items (columns), infer the unknown ratings. In the last decades, few attempts where done to handle that objective with Neural Networks, but recently an architecture based on Autoencoders proved to be a promising approach. In current paper, we enhanced that architecture (i) by using a loss function adapted to input data with missing values, and (ii) by incorporating side information. The experiments demonstrate that while side information only slightly improve the test error averaged on all users/items, it has more impact on cold users/items.
* arXiv admin note: substantial text overlap with arXiv:1603.00806
Learning Visual Reasoning Without Strong Priors
Dec 18, 2017
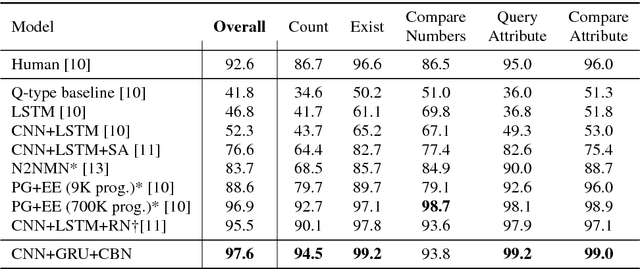
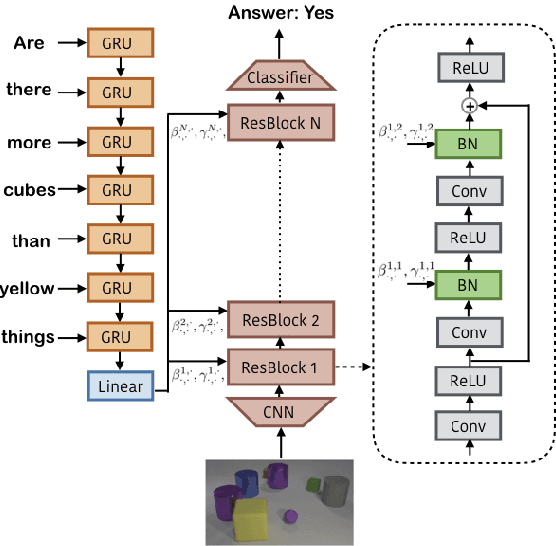
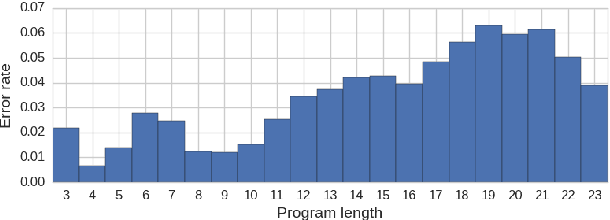
Achieving artificial visual reasoning - the ability to answer image-related questions which require a multi-step, high-level process - is an important step towards artificial general intelligence. This multi-modal task requires learning a question-dependent, structured reasoning process over images from language. Standard deep learning approaches tend to exploit biases in the data rather than learn this underlying structure, while leading methods learn to visually reason successfully but are hand-crafted for reasoning. We show that a general-purpose, Conditional Batch Normalization approach achieves state-of-the-art results on the CLEVR Visual Reasoning benchmark with a 2.4% error rate. We outperform the next best end-to-end method (4.5%) and even methods that use extra supervision (3.1%). We probe our model to shed light on how it reasons, showing it has learned a question-dependent, multi-step process. Previous work has operated under the assumption that visual reasoning calls for a specialized architecture, but we show that a general architecture with proper conditioning can learn to visually reason effectively.