 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Dimensional Linguistic Properties of the Word Embedding Space
Oct 05, 2019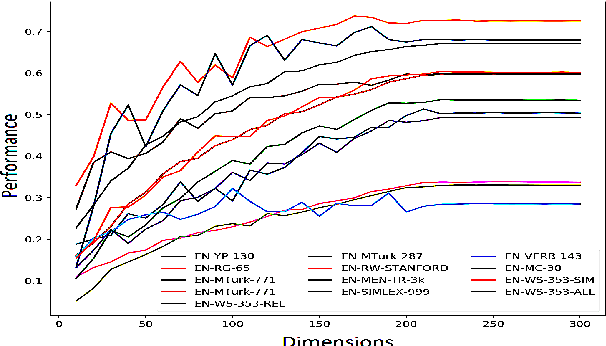
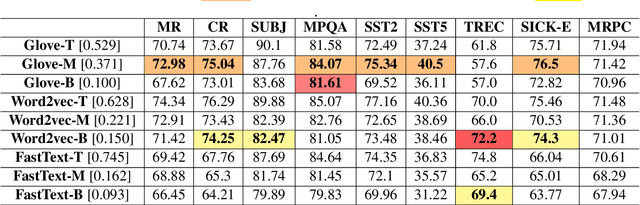
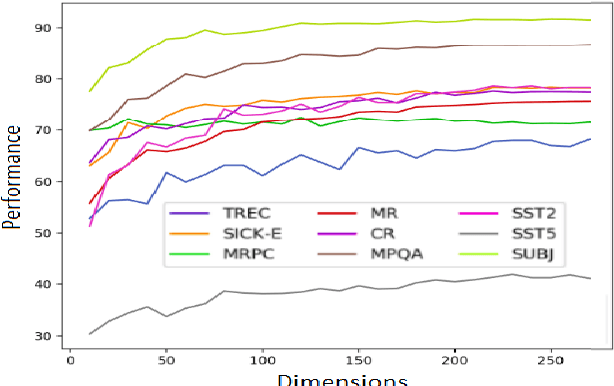
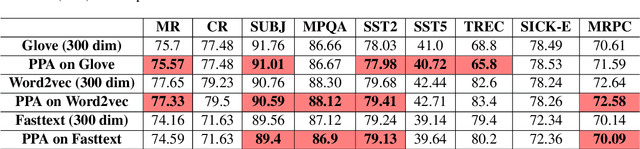
Word embeddings have become a staple of several natural language processing tasks, yet much remains to be understood about their properties. In this work, we analyze word embeddings in terms of their principal components and arrive at a number of novel conclusions. In particular, we characterize the utility of variance explained by the principal components (widely used as a fundamental tool to assess the quality of the resulting representations) as a proxy for downstream performance. Further, through dimensional linguistic probing of the embedding space, we show that the syntactic information captured by a principal component does not depend on the amount of variance it explains. Consequently, we investigate the limitations of variance based embedding post-processing techniques and demonstrate that such post-processing is counter-productive in a number of scenarios such as sentence classification and machine translation tasks. Finally, we offer a few guidelines on variance based embedding post-processing. We have released the source code along with the paper.
SANTLR: Speech Annotation Toolkit for Low Resource Languages
Aug 02, 2019
While low resource speech recognition has attracted a lot of attention from the speech community, there are a few tools available to facilitate low resource speech collection. In this work, we present SANTLR: Speech Annotation Toolkit for Low Resource Languages. It is a web-based toolkit which allows researchers to easily collect and annotate a corpus of speech in a low resource language. Annotators may use this toolkit for two purposes: transcription or recording. In transcription, annotators would transcribe audio files provided by the researchers; in recording, annotators would record their voice by reading provided texts. We highlight two properties of this toolkit. First, SANTLR has a very user-friendly User Interface (UI). Both researchers and annotators may use this simple web interface to interact. There is no requirement for the annotators to have any expertise in audio or text processing. The toolkit would handle all preprocessing and postprocessing steps. Second, we employ a multi-step ranking mechanism facilitate the annotation process. In particular, the toolkit would give higher priority to utterances which are easier to annotate and are more beneficial to achieving the goal of the annotation, e.g. quickly training an acoustic model.
Multilingual Speech Recognition with Corpus Relatedness Sampling
Aug 02, 2019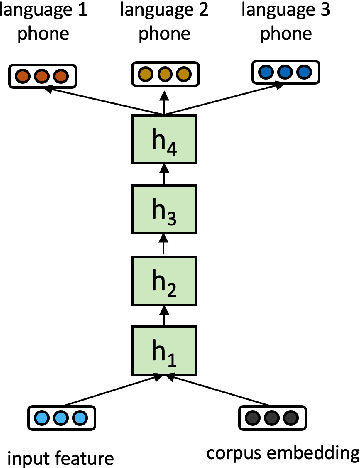
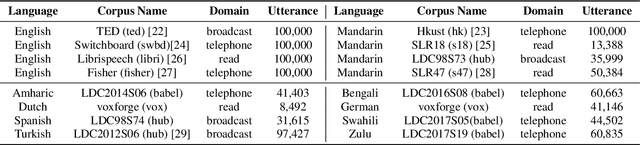
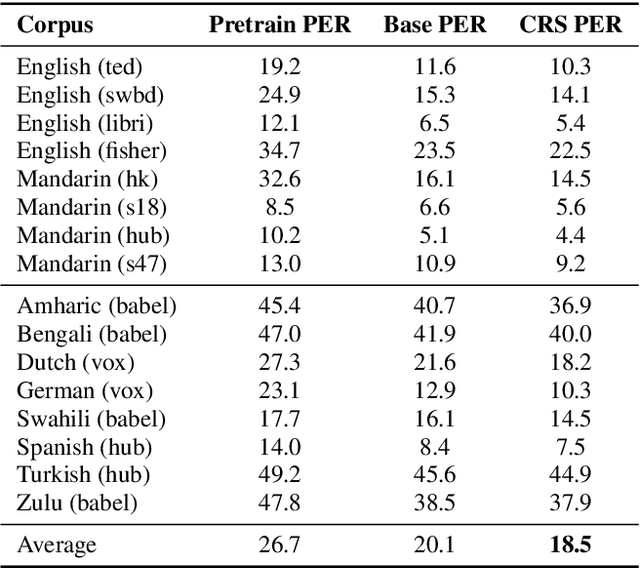
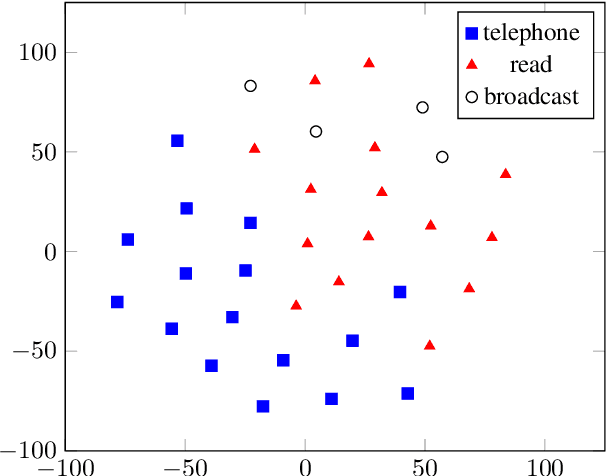
Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.
Cross-Attention End-to-End ASR for Two-Party Conversations
Jul 24, 2019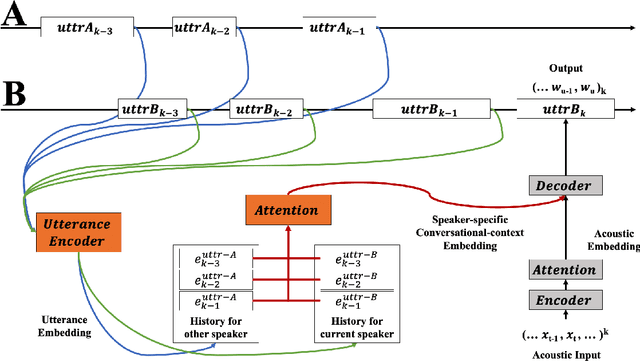
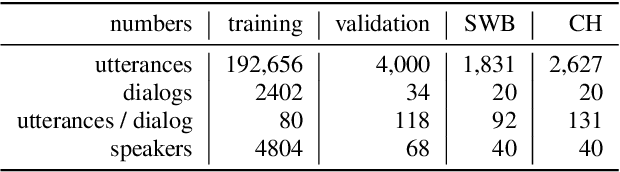
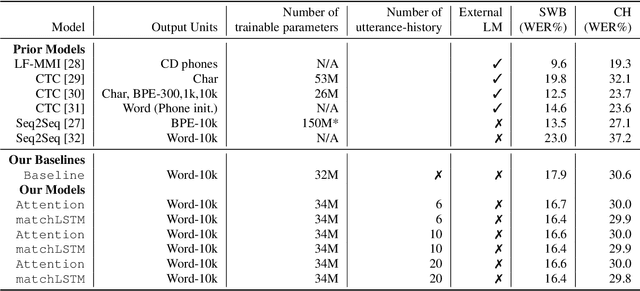
We present an end-to-end speech recognition model that learns interaction between two speakers based on the turn-changing information. Unlike conventional speech recognition models, our model exploits two speakers' history of conversational-context information that spans across multiple turns within an end-to-end framework. Specifically, we propose a speaker-specific cross-attention mechanism that can look at the output of the other speaker side as well as the one of the current speaker for better at recognizing long conversations. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Analyzing Utility of Visual Context in Multimodal Speech Recognition Under Noisy Conditions
Jun 30, 2019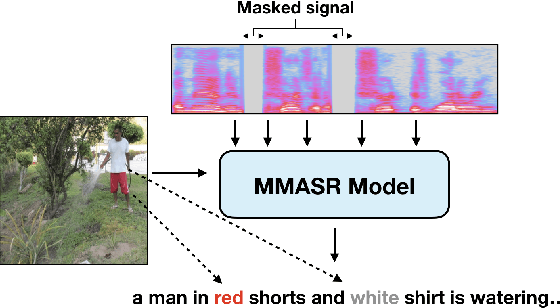

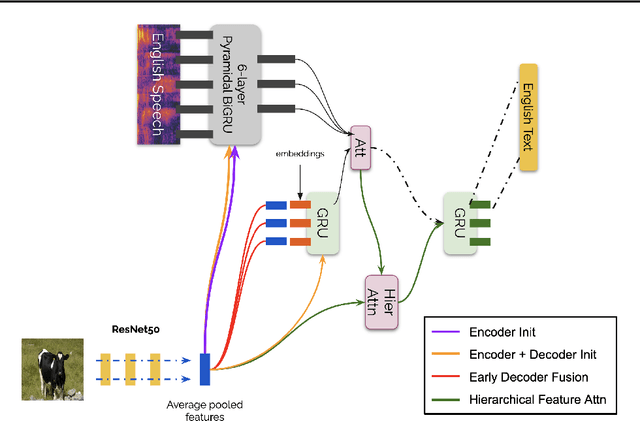
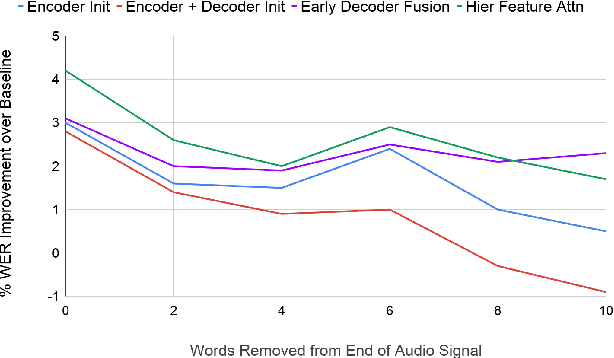
Multimodal learning allows us to leverage information from multiple sources (visual, acoustic and text), similar to our experience of the real world. However, it is currently unclear to what extent auxiliary modalities improve performance over unimodal models, and under what circumstances the auxiliary modalities are useful. We examine the utility of the auxiliary visual context in Multimodal Automatic Speech Recognition in adversarial settings, where we deprive the models from partial audio signal during inference time. Our experiments show that while MMASR models show significant gains over traditional speech-to-text architectures (upto 4.2% WER improvements), they do not incorporate visual information when the audio signal has been corrupted. This shows that current methods of integrating the visual modality do not improve model robustness to noise, and we need better visually grounded adaptation techniques.
Gated Embeddings in End-to-End Speech Recognition for Conversational-Context Fusion
Jun 27, 2019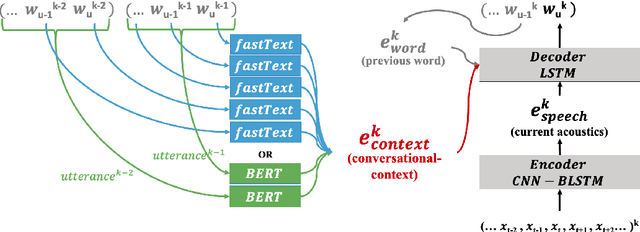
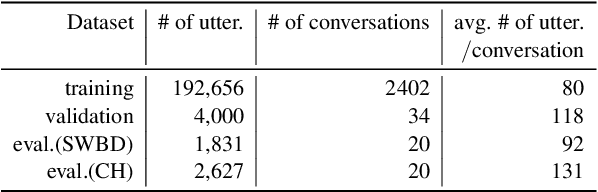
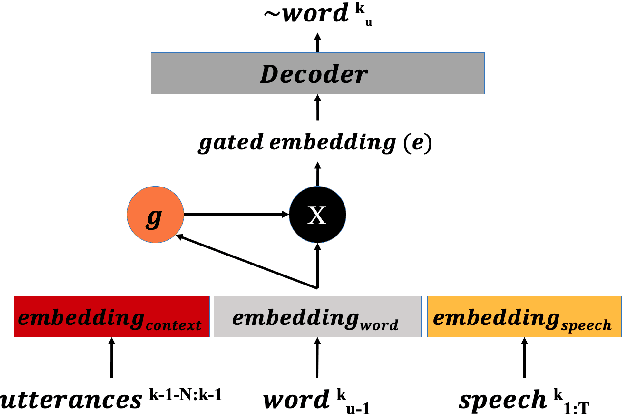
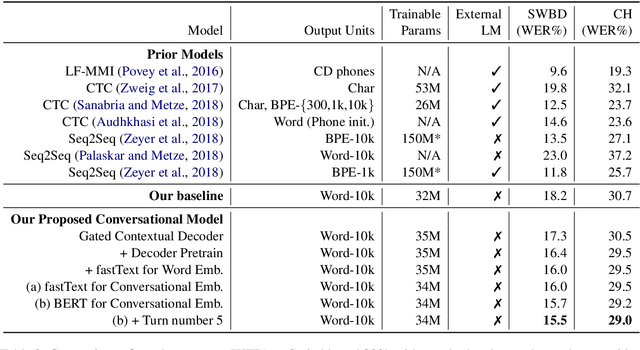
We present a novel conversational-context aware end-to-end speech recognizer based on a gated neural network that incorporates conversational-context/word/speech embeddings. Unlike conventional speech recognition models, our model learns longer conversational-context information that spans across sentences and is consequently better at recognizing long conversations. Specifically, we propose to use the text-based external word and/or sentence embeddings (i.e., fastText, BERT) within an end-to-end framework, yielding a significant improvement in word error rate with better conversational-context representation. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Multimodal Abstractive Summarization for How2 Videos
Jun 19, 2019
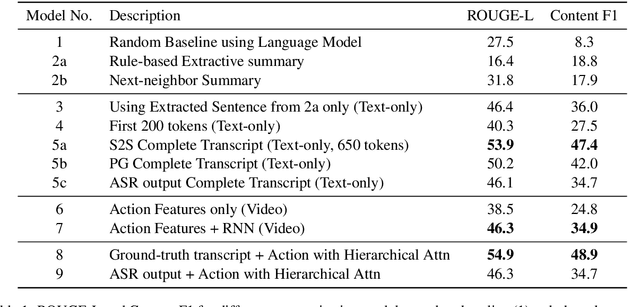
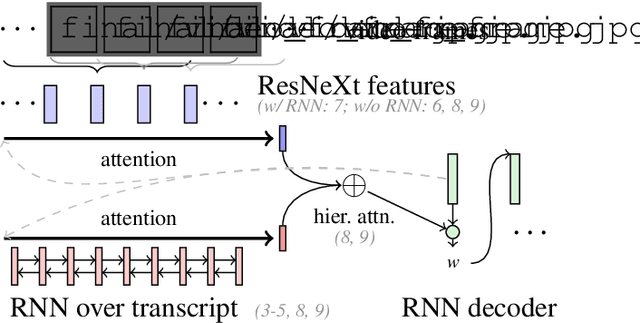
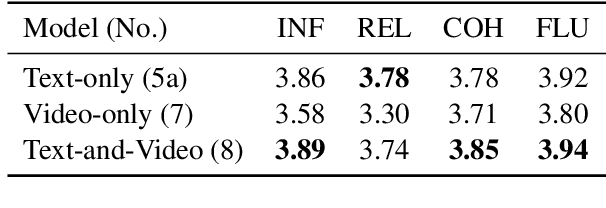
In this paper, we study abstractive summarization for open-domain videos. Unlike the traditional text news summarization, the goal is less to "compress" text information but rather to provide a fluent textual summary of information that has been collected and fused from different source modalities, in our case video and audio transcripts (or text). We show how a multi-source sequence-to-sequence model with hierarchical attention can integrate information from different modalities into a coherent output, compare various models trained with different modalities and present pilot experiments on the How2 corpus of instructional videos. We also propose a new evaluation metric (Content F1) for abstractive summarization task that measures semantic adequacy rather than fluency of the summaries, which is covered by metrics like ROUGE and BLEU.
Acoustic-to-Word Models with Conversational Context Information
May 21, 2019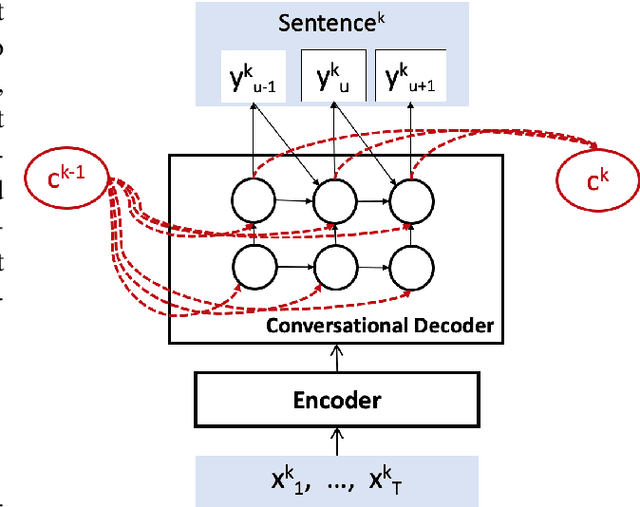
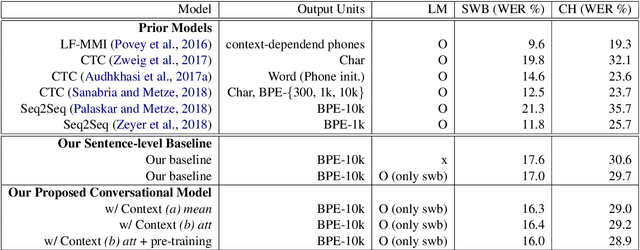
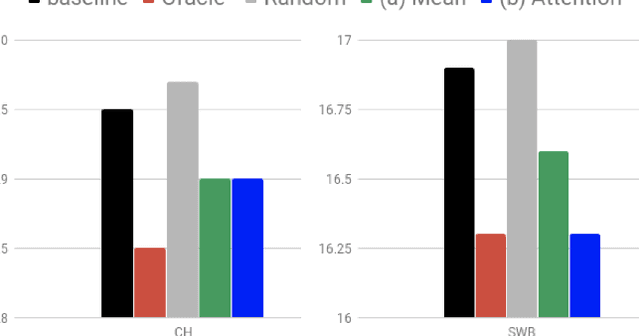
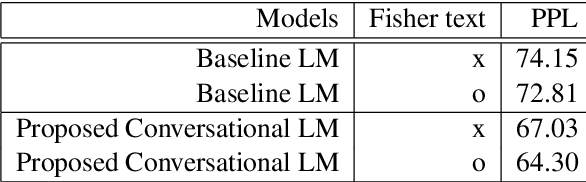
Conversational context information, higher-level knowledge that spans across sentences, can help to recognize a long conversation. However, existing speech recognition models are typically built at a sentence level, and thus it may not capture important conversational context information. The recent progress in end-to-end speech recognition enables integrating context with other available information (e.g., acoustic, linguistic resources) and directly recognizing words from speech. In this work, we present a direct acoustic-to-word, end-to-end speech recognition model capable of utilizing the conversational context to better process long conversations. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a standard end-to-end speech recognition system.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019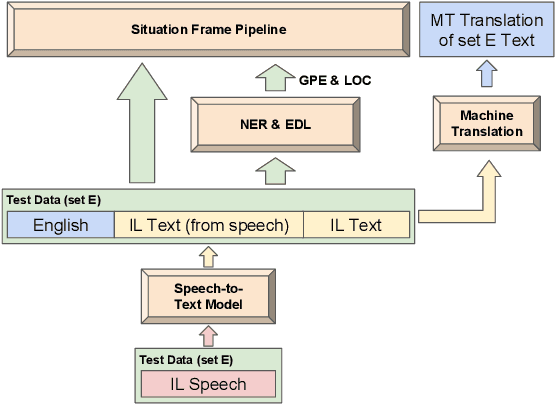
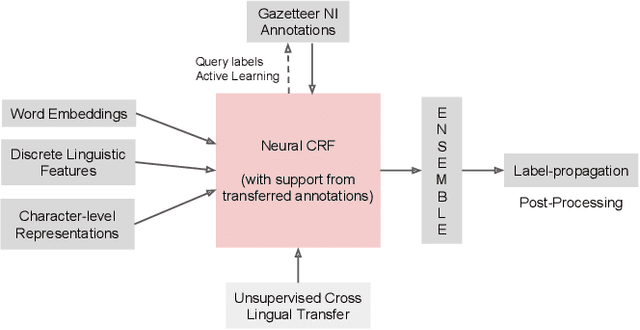
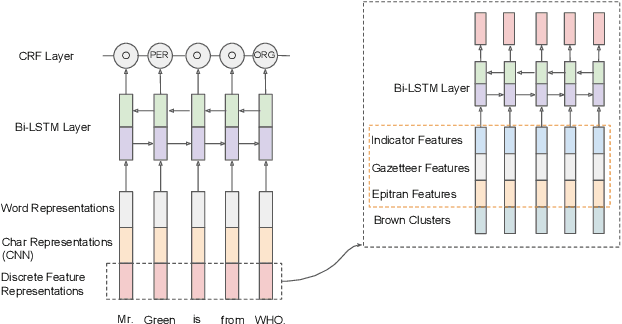
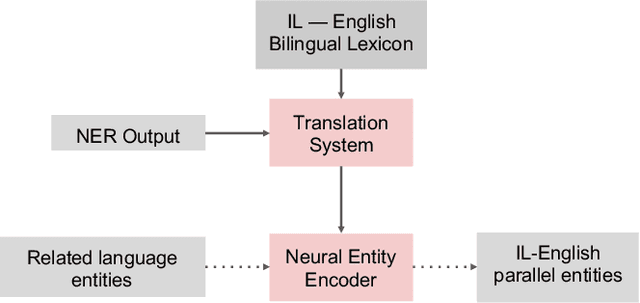
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Phoneme Level Language Models for Sequence Based Low Resource ASR
Feb 20, 2019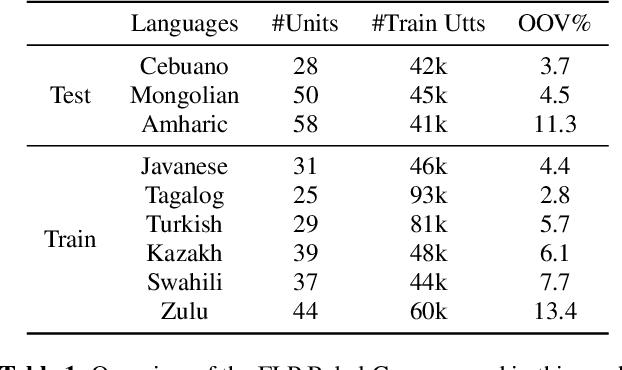
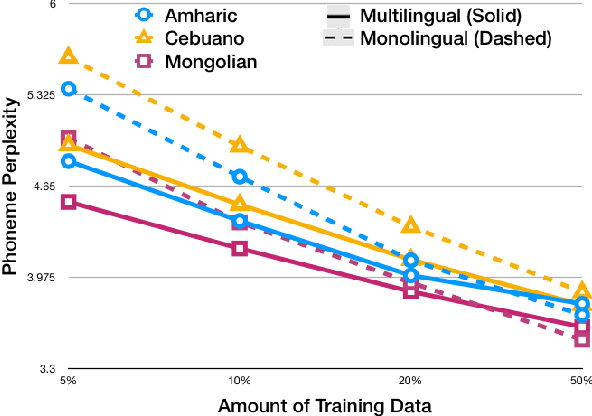
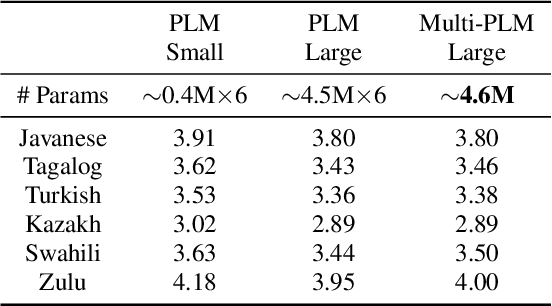
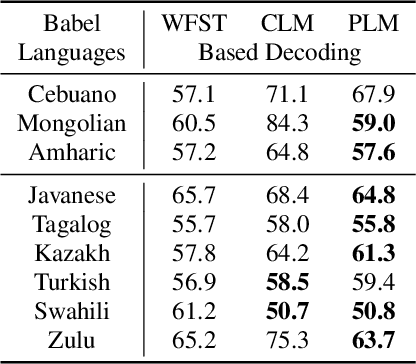
Building multilingual and crosslingual models help bring different languages together in a language universal space. It allows models to share parameters and transfer knowledge across languages, enabling faster and better adaptation to a new language. These approaches are particularly useful for low resource languages. In this paper, we propose a phoneme-level language model that can be used multilingually and for crosslingual adaptation to a target language. We show that our model performs almost as well as the monolingual models by using six times fewer parameters, and is capable of better adaptation to languages not seen during training in a low resource scenario. We show that these phoneme-level language models can be used to decode sequence based Connectionist Temporal Classification (CTC) acoustic model outputs to obtain comparable word error rates with Weighted Finite State Transducer (WFST) based decoding in Babel languages. We also show that these phoneme-level language models outperform WFST decoding in various low-resource conditions like adapting to a new language and domain mismatch between training and testing data.