 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGAI: A Vision-Based Decentralized Controller Learning Framework for Robot Swarms
Feb 06, 2020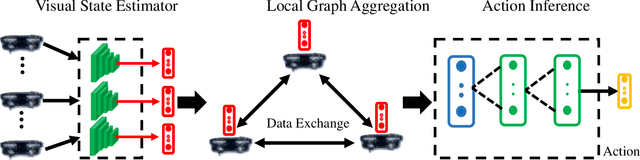
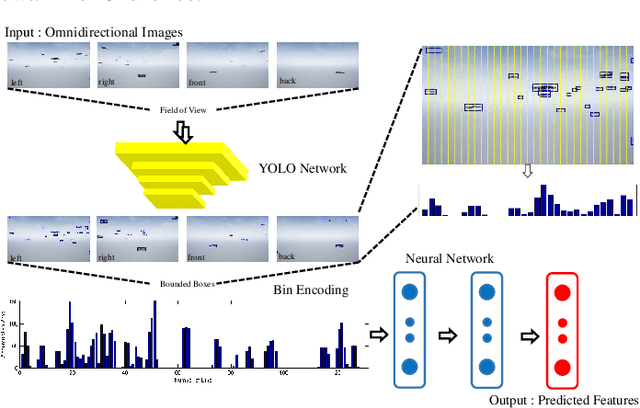
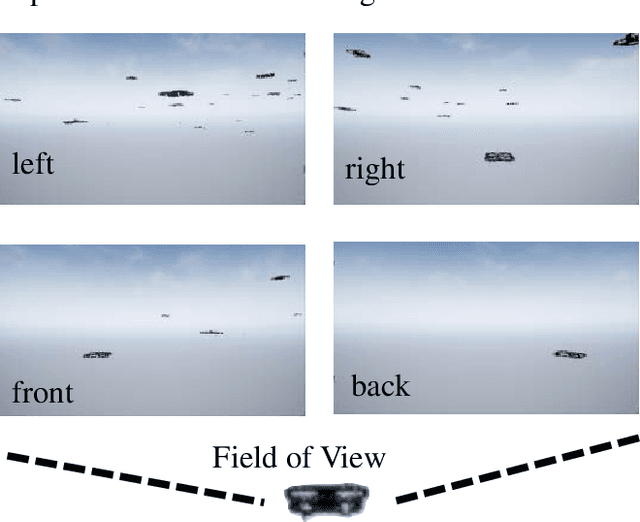
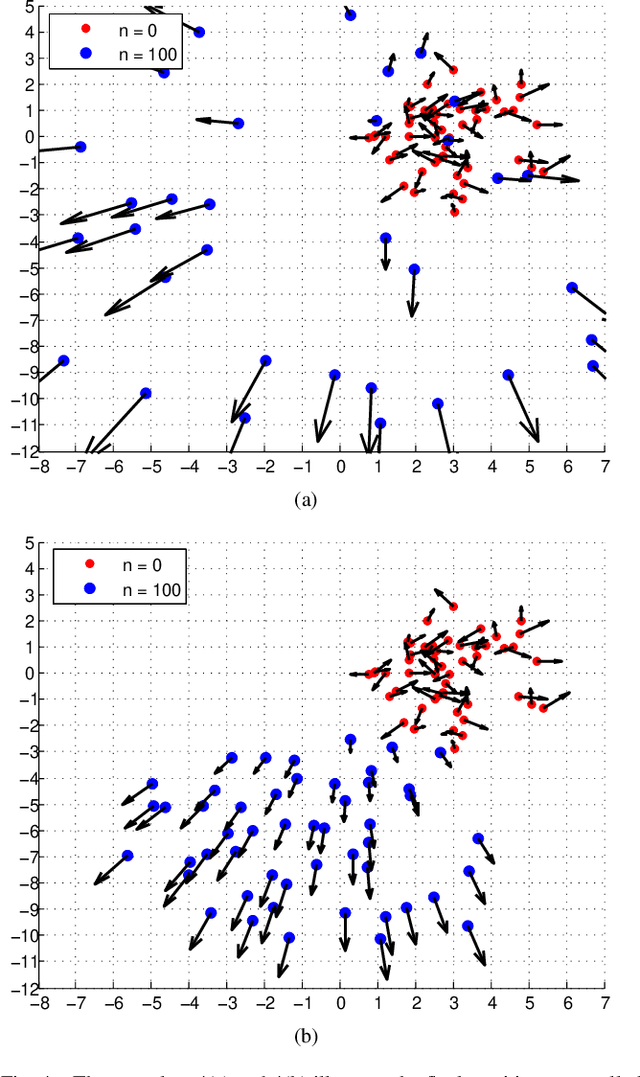
Despite the popularity of decentralized controller learning, very few successes have been demonstrated on learning to control large robot swarms using raw visual observations. To fill in this gap, we present Vision-based Graph Aggregation and Inference (VGAI), a decentralized learning-to-control framework that directly maps raw visual observations to agent actions, aided by sparse local communication among only neighboring agents. Our framework is implemented by an innovative cascade of convolutional neural networks (CNNs) and one graph neural network (GNN), addressing agent-level visual perception and feature learning, as well as swarm-level local information aggregation and agent action inference, respectively. Using the application example of drone flocking, we show that VGAI yields comparable or more competitive performance with other decentralized controllers, and even the centralized controller that learns from global information. Especially, it shows substantial scalability to learn over large swarms (e.g., 50 agents), thanks to the integration between visual perception and local communication.
Gated Graph Recurrent Neural Networks
Feb 03, 2020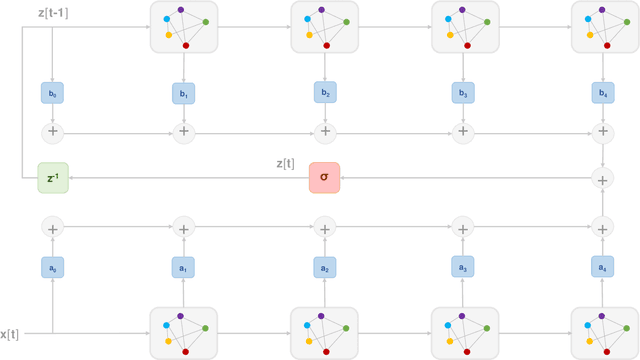
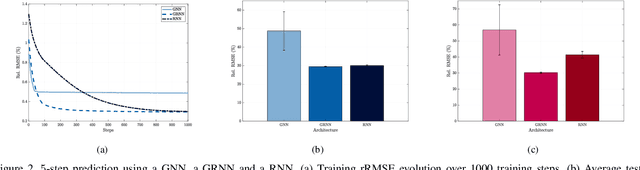
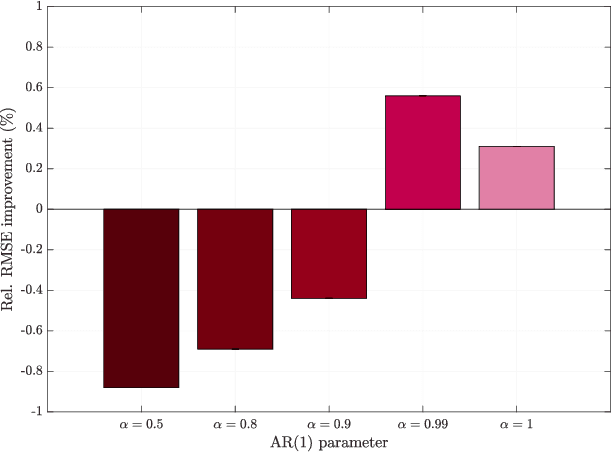
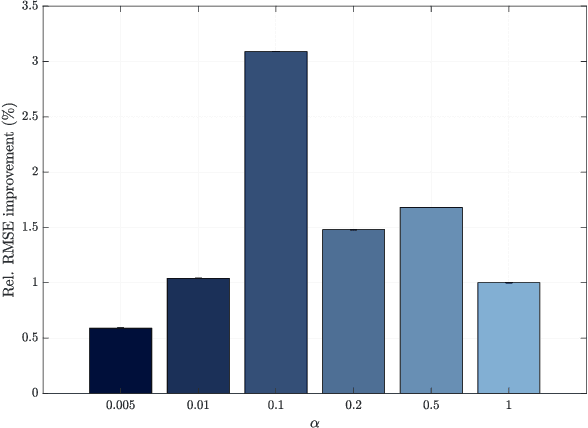
Graph processes exhibit a temporal structure determined by the sequence index and and a spatial structure determined by the graph support. To learn from graph processes, an information processing architecture must then be able to exploit both underlying structures. We introduce Graph Recurrent Neural Networks (GRNNs), which achieve this goal by leveraging the hidden Markov model (HMM) together with graph signal processing (GSP). In the GRNN, the number of learnable parameters is independent of the length of the sequence and of the size of the graph, guaranteeing scalability. We also prove that GRNNs are permutation equivariant and that they are stable to perturbations of the underlying graph support. Following the observation that stability decreases with longer sequences, we propose a time-gated extension of GRNNs. We also put forward node- and edge-gated variants of the GRNN to address the problem of vanishing gradients arising from long range graph dependencies. The advantages of GRNNs over GNNs and RNNs are demonstrated in a synthetic regression experiment and in a classification problem where seismic wave readings from a network of seismographs are used to predict the region of an earthquake. Finally, the benefits of time, node and edge gating are experimentally validated in multiple time and spatial correlation scenarios.
EdgeNets:Edge Varying Graph Neural Networks
Jan 21, 2020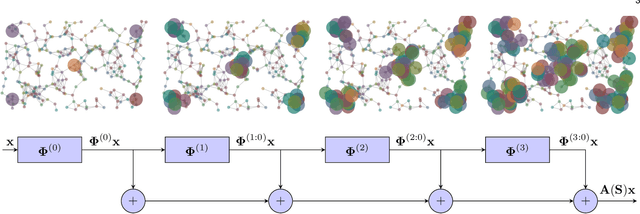
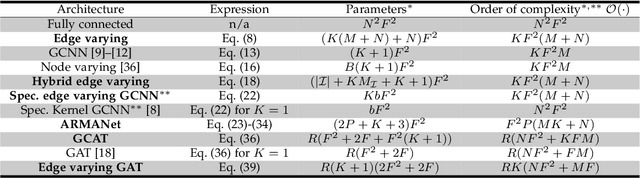
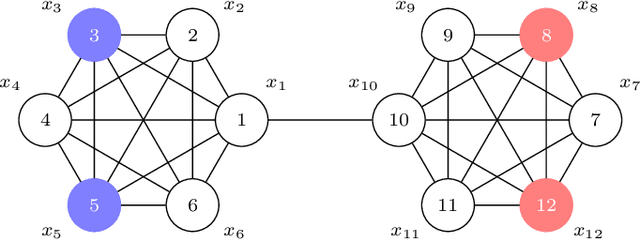
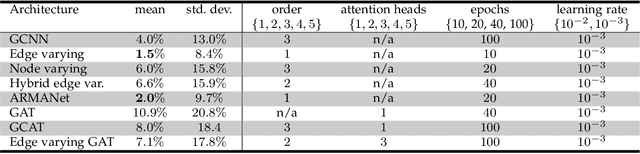
Driven by the outstanding performance of neural networks in the structured Euclidean domain, recent years have seen a surge of interest in developing neural networks for graphs and data supported on graphs. The graph is leveraged as a parameterization to capture detail at the node level with a reduced number of parameters and complexity. Following this rationale, this paper puts forth a general framework that unifies state-of-the-art graph neural networks (GNNs) through the concept of EdgeNet. An EdgeNet is a GNN architecture that allows different nodes to use different parameters to weigh the information of different neighbors. By extrapolating this strategy to more iterations between neighboring nodes, the EdgeNet learns edge- and neighbor-dependent weights to capture local detail. This is the most general local operation that a node can do and encompasses under one formulation all graph convolutional neural networks (GCNNs) as well as graph attention networks (GATs). In writing different GNN architectures with a common language, EdgeNets highlight specific architecture advantages and limitations, while providing guidelines to improve their capacity without compromising their local implementation. For instance, we show that GCNNs have a parameter sharing structure that induces permutation equivariance. This can be an advantage or a limitation, depending on the application. When it is a limitation, we propose hybrid approaches and provide insights to develop several other solutions that promote parameter sharing without enforcing permutation equivariance. Another interesting conclusion is the unification of GCNNs and GATs -approaches that have been so far perceived as separate. In particular, we show that GATs are GCNNs on a graph that is learned from the features. This particularization opens the doors to develop alternative attention mechanisms for improving discriminatory power.
Graph Neural Networks for Decentralized Multi-Robot Path Planning
Dec 12, 2019
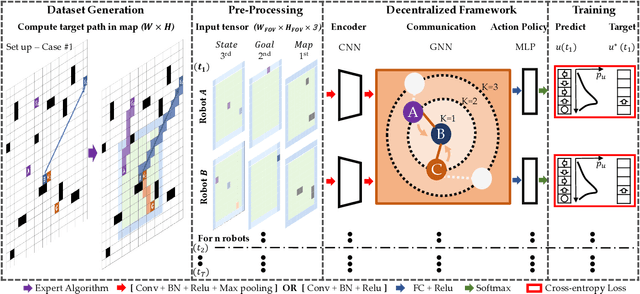
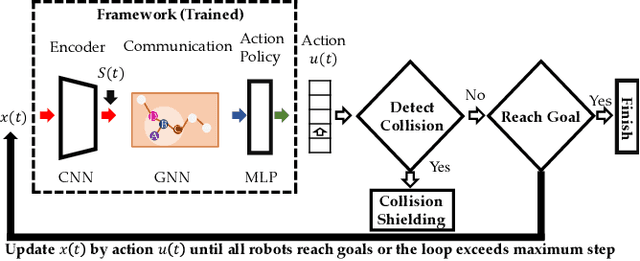
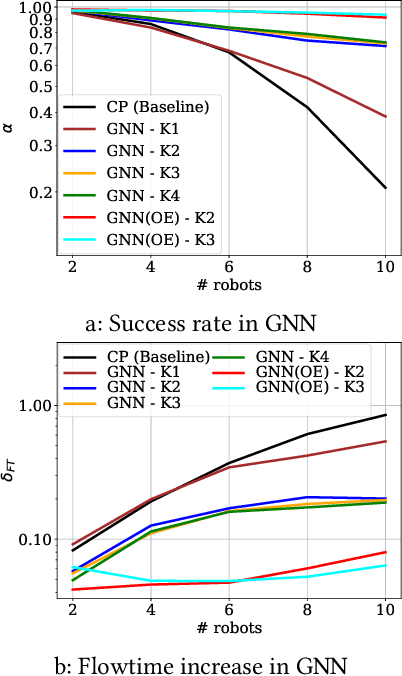
Efficient and collision-free navigation in multi-robot systems is fundamental to advancing mobility. Scenarios where the robots are restricted in observation and communication range call for decentralized solutions, whereby robots execute localized planning policies. From the point of view of an individual robot, however, its local decision-making system is incomplete, since other agents' unobservable states affect future values. The manner in which information is shared is crucial to the system's performance, yet is not well addressed by current approaches. To address these challenges, we propose a combined architecture, with the goal of learning a decentralized sequential action policy that yields efficient path plans for all robots. Our framework is composed of a convolutional neural network (CNN) that extracts adequate features from local observations, and a graph neural network (GNN) that communicates these features among robots. We train the model to imitate an expert algorithm, and use the resulting model online in decentralized planning involving only local communication. We evaluate our method in simulations involving teams of robots in cluttered workspaces. We measure the success rates and sum of costs over the planned paths. The results show a performance close to that of our expert algorithm, demonstrating the validity of our approach. In particular, we show our model's capability to generalize to previously unseen cases (involving larger environments and larger robot teams).
Stability of Graph Neural Networks to Relative Perturbations
Oct 21, 2019
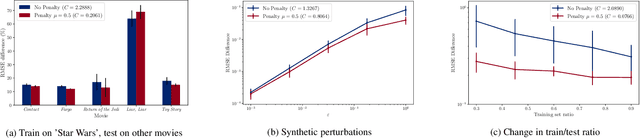
Graph neural networks (GNNs), consisting of a cascade of layers applying a graph convolution followed by a pointwise nonlinearity, have become a powerful architecture to process signals supported on graphs. Graph convolutions (and thus, GNNs), rely heavily on knowledge of the graph for operation. However, in many practical cases the GSO is not known and needs to be estimated, or might change from training time to testing time. In this paper, we are set to study the effect that a change in the underlying graph topology that supports the signal has on the output of a GNN. We prove that graph convolutions with integral Lipschitz filters lead to GNNs whose output change is bounded by the size of the relative change in the topology. Furthermore, we leverage this result to show that the main reason for the success of GNNs is that they are stable architectures capable of discriminating features on high eigenvalues, which is a feat that cannot be achieved by linear graph filters (which are either stable or discriminative, but cannot be both). Finally, we comment on the use of this result to train GNNs with increased stability and run experiments on movie recommendation systems.
Stability of Graph Scattering Transforms
Jun 11, 2019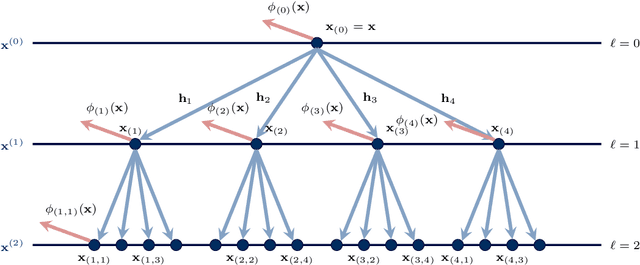
Scattering transforms are non-trainable deep convolutional architectures that exploit the multi-scale resolution of a wavelet filter bank to obtain an appropriate representation of data. More importantly, they are proven invariant to translations, and stable to perturbations that are close to translations. This stability property dons the scattering transform with a robustness to small changes in the metric domain of the data. When considering network data, regular convolutions do not hold since the data domain presents an irregular structure given by the network topology. In this work, we extend scattering transforms to network data by using multiresolution graph wavelets, whose computation can be obtained by means of graph convolutions. Furthermore, we prove that the resulting graph scattering transforms are stable to metric perturbations of the underlying network. This renders graph scattering transforms robust to changes on the network topology, making it particularly useful for cases of transfer learning, topology estimation or time-varying graphs.
Stability Properties of Graph Neural Networks
May 11, 2019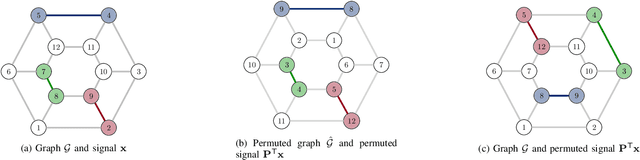
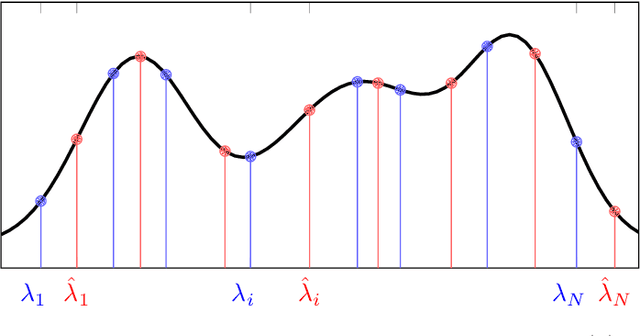
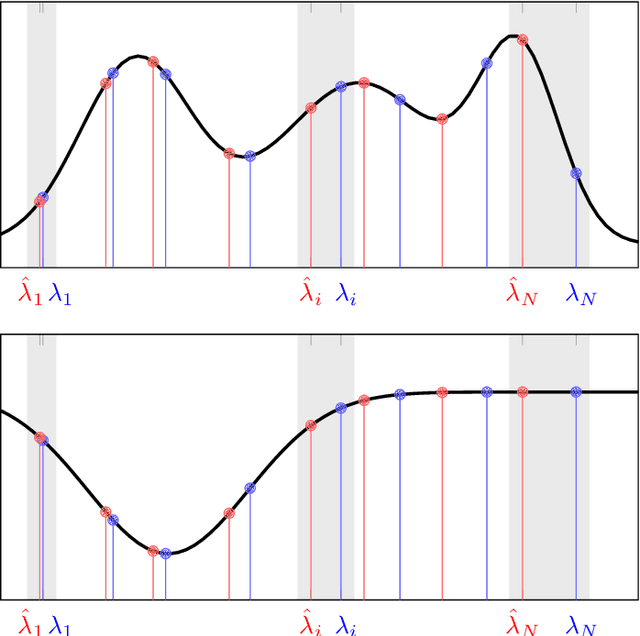
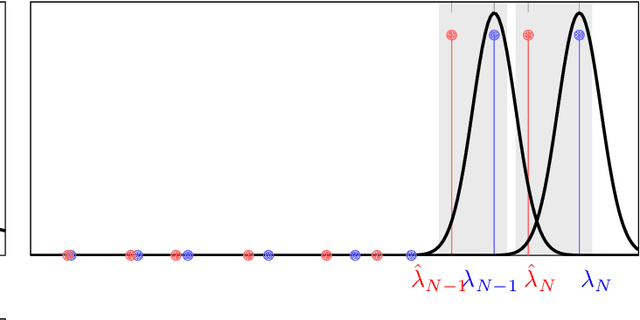
Data stemming from networks exhibit an irregular support, whereby each data element is related by arbitrary pairwise relationships determined by the network. Graph neural networks (GNNs) have emerged as information processing architectures that exploit the particularities of this underlying support. The use of nonlinearities in GNNs, coupled with the fact that filters are learned from data, raises mathematical challenges that have precluded the development of theoretical results that would give insight in the reasons for the remarkable performance of GNNs. In this work, we prove the property of stability, that states that a small change in the support of the data leads to a small (bounded) change in the output of the GNN. More specifically, we prove that the bound on the output difference of the GNN computed on one graph or another, is proportional to the difference between the graphs and the design parameters of the GNN, as long as the trained filters are integral Lipschitz. We exploit this result to provide some insights in the crucial effect that nonlinearities have in obtaining an architecture that is both stable and selective, a feat that is impossible to achieve if using only linear filters.
Invariance-Preserving Localized Activation Functions for Graph Neural Networks
Mar 29, 2019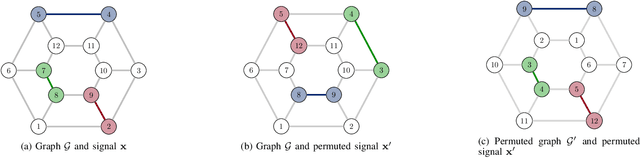
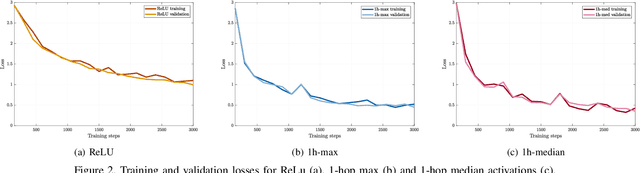

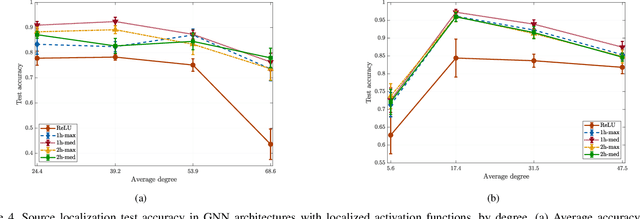
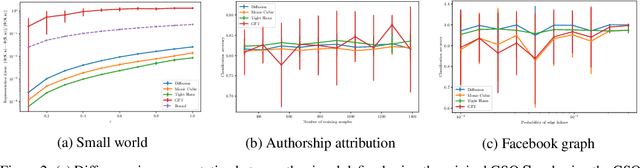
Graph signals are signals with an irregular structure that can be described by a graph. Graph neural networks (GNNs) are information processing architectures tailored to these graph signals and made of stacked layers that compose graph convolutional filters with nonlinear activation functions. Graph convolutions endow GNNs with invariance to permutations of the graph nodes' labels. In this paper, we consider the design of trainable nonlinear activation functions that take into consideration the structure of the graph. This is accomplished by using graph median filters and graph max filters, which mimic linear graph convolutions and are shown to retain the permutation invariance of GNNs. We also discuss modifications to the backpropagation algorithm necessary to train local activation functions. The advantages of localized activation function architectures are demonstrated in three numerical experiments: source localization on synthetic graphs, authorship attribution of 19th century novels and prediction of movie ratings. In all cases, localized activation functions are shown to improve model capacity.
Learning Decentralized Controllers for Robot Swarms with Graph Neural Networks
Mar 25, 2019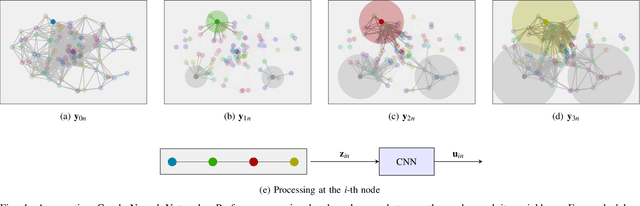
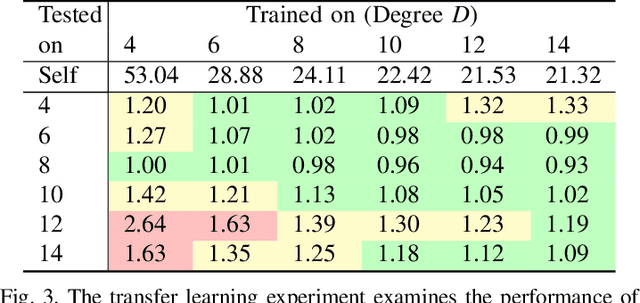
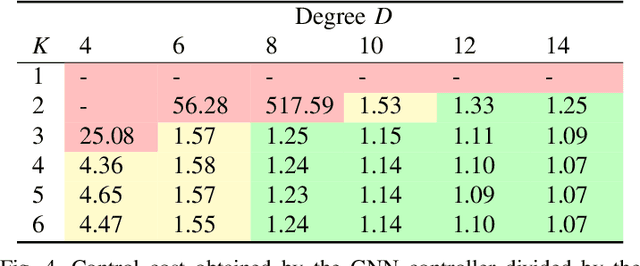
We consider the problem of finding distributed controllers for large networks of mobile robots with interacting dynamics and sparsely available communications. Our approach is to learn local controllers which require only local information and local communications at test time by imitating the policy of centralized controllers using global information at training time. By extending aggregation graph neural networks to time varying signals and time varying network support, we learn a single common local controller which exploits information from distant teammates using only local communication interchanges. We apply this approach to a decentralized linear quadratic regulator problem and observe how faster communication rates and smaller network degree increase the value of multi-hop information. Separate experiments learning a decentralized flocking controller demonstrate performance on communication graphs that change as the robots move.
Gated Graph Convolutional Recurrent Neural Networks
Mar 05, 2019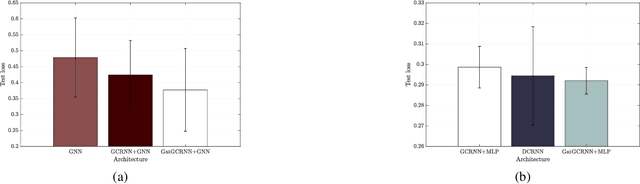

Graph processes model a number of important problems such as identifying the epicenter of an earthquake or predicting weather. In this paper, we propose a Graph Convolutional Recurrent Neural Network (GCRNN) architecture specifically tailored to deal with these problems. GCRNNs use convolutional filter banks to keep the number of trainable parameters independent of the size of the graph and of the time sequences considered. We also put forward Gated GCRNNs, a time-gated variation of GCRNNs akin to LSTMs. When compared with GNNs and another graph recurrent architecture in experiments using both synthetic and real-word data, GCRNNs significantly improve performance while using considerably less parameters.