 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple is not Enough: Document-level Text Simplification using Readability and Coherence
Dec 24, 2024



In this paper, we present the SimDoc system, a simplification model considering simplicity, readability, and discourse aspects, such as coherence. In the past decade, the progress of the Text Simplification (TS) field has been mostly shown at a sentence level, rather than considering paragraphs or documents, a setting from which most TS audiences would benefit. We propose a simplification system that is initially fine-tuned with professionally created corpora. Further, we include multiple objectives during training, considering simplicity, readability, and coherence altogether. Our contributions include the extension of professionally annotated simplification corpora by the association of existing annotations into (complex text, simple text, readability label) triples to benefit from readability during training. Also, we present a comparative analysis in which we evaluate our proposed models in a zero-shot, few-shot, and fine-tuning setting using document-level TS corpora, demonstrating novel methods for simplification. Finally, we show a detailed analysis of outputs, highlighting the difficulties of simplification at a document level.
BLESS: Benchmarking Large Language Models on Sentence Simplification
Oct 24, 2023



We present BLESS, a comprehensive performance benchmark of the most recent state-of-the-art large language models (LLMs) on the task of text simplification (TS). We examine how well off-the-shelf LLMs can solve this challenging task, assessing a total of 44 models, differing in size, architecture, pre-training methods, and accessibility, on three test sets from different domains (Wikipedia, news, and medical) under a few-shot setting. Our analysis considers a suite of automatic metrics as well as a large-scale quantitative investigation into the types of common edit operations performed by the different models. Furthermore, we perform a manual qualitative analysis on a subset of model outputs to better gauge the quality of the generated simplifications. Our evaluation indicates that the best LLMs, despite not being trained on TS, perform comparably with state-of-the-art TS baselines. Additionally, we find that certain LLMs demonstrate a greater range and diversity of edit operations. Our performance benchmark will be available as a resource for the development of future TS methods and evaluation metrics.
Investigating Text Simplification Evaluation
Jul 28, 2021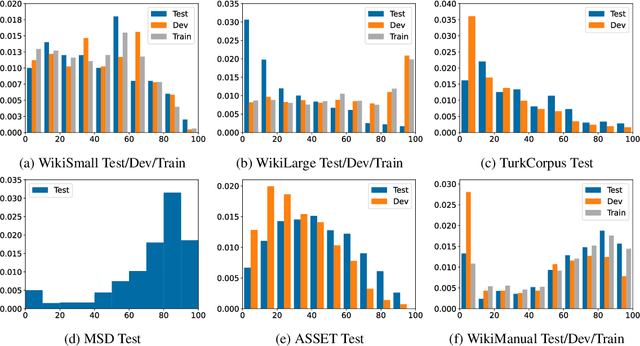
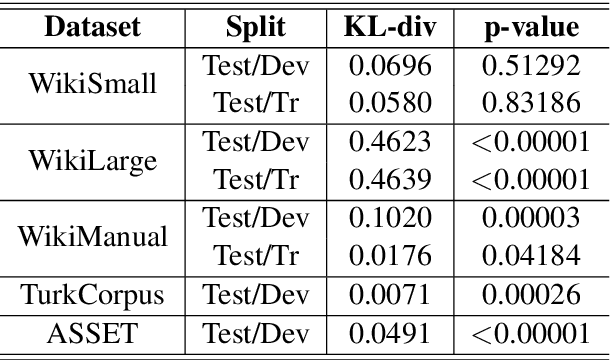
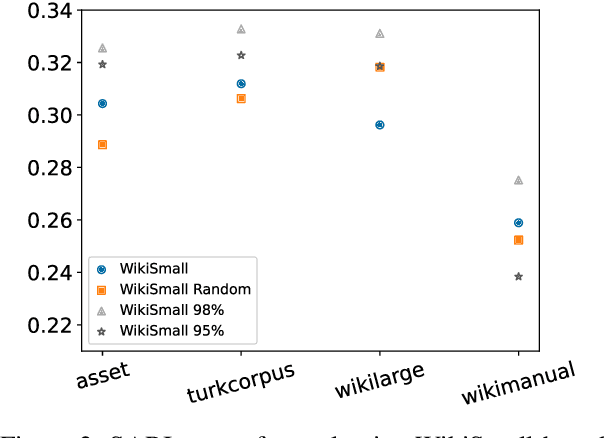
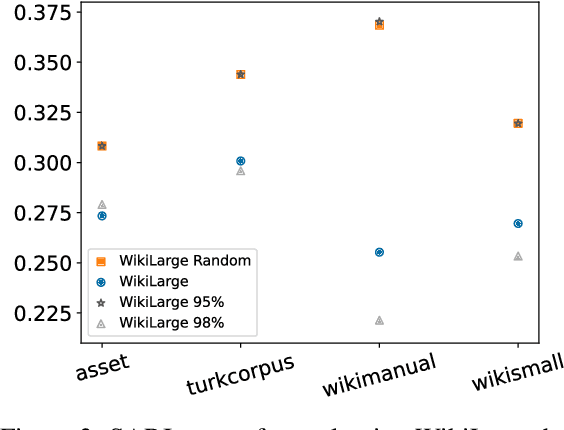
Modern text simplification (TS) heavily relies on the availability of gold standard data to build machine learning models. However, existing studies show that parallel TS corpora contain inaccurate simplifications and incorrect alignments. Additionally, evaluation is usually performed by using metrics such as BLEU or SARI to compare system output to the gold standard. A major limitation is that these metrics do not match human judgements and the performance on different datasets and linguistic phenomena vary greatly. Furthermore, our research shows that the test and training subsets of parallel datasets differ significantly. In this work, we investigate existing TS corpora, providing new insights that will motivate the improvement of existing state-of-the-art TS evaluation methods. Our contributions include the analysis of TS corpora based on existing modifications used for simplification and an empirical study on TS models performance by using better-distributed datasets. We demonstrate that by improving the distribution of TS datasets, we can build more robust TS models.
* 7 pages, 3 figures, 1 table