 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeOnce: Real-Time Multi-Person Gaze Estimation
Apr 20, 2022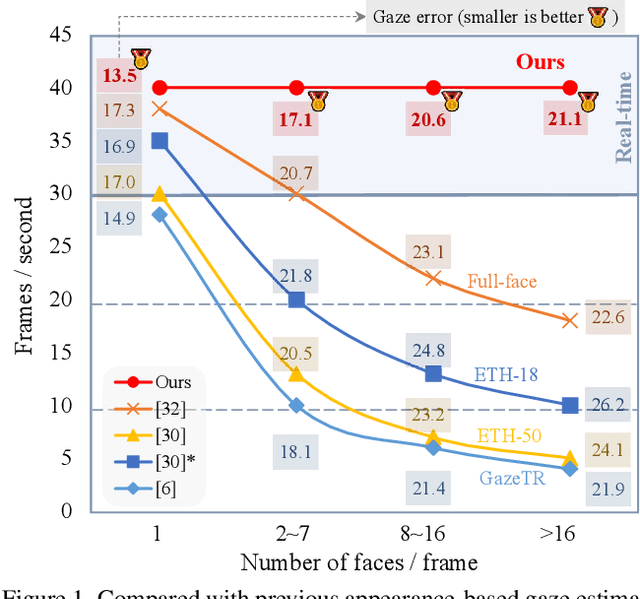


Appearance-based gaze estimation aims to predict the 3D eye gaze direction from a single image. While recent deep learning-based approaches have demonstrated excellent performance, they usually assume one calibrated face in each input image and cannot output multi-person gaze in real time. However, simultaneous gaze estimation for multiple people in the wild is necessary for real-world applications. In this paper, we propose the first one-stage end-to-end gaze estimation method, GazeOnce, which is capable of simultaneously predicting gaze directions for multiple faces (>10) in an image. In addition, we design a sophisticated data generation pipeline and propose a new dataset, MPSGaze, which contains full images of multiple people with 3D gaze ground truth. Experimental results demonstrate that our unified framework not only offers a faster speed, but also provides a lower gaze estimation error compared with state-of-the-art methods. This technique can be useful in real-time applications with multiple users.
Cloud Sphere: A 3D Shape Representation via Progressive Deformation
Dec 21, 2021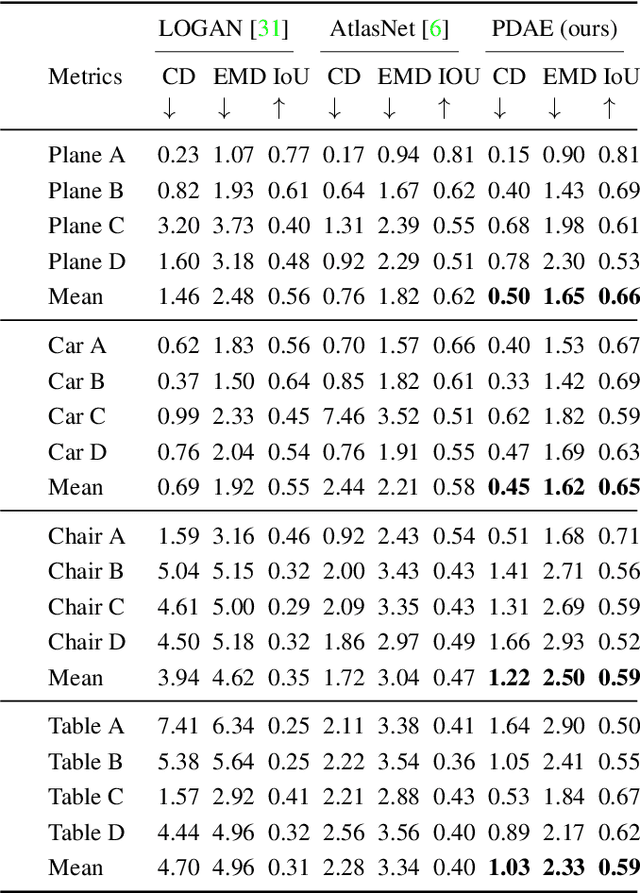
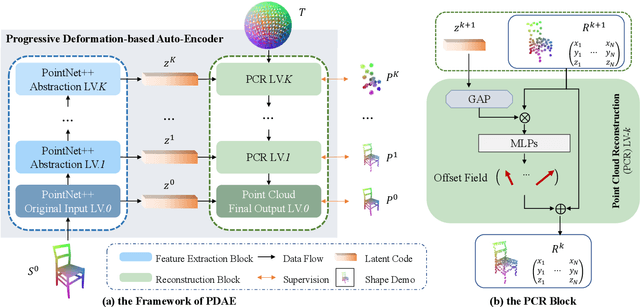
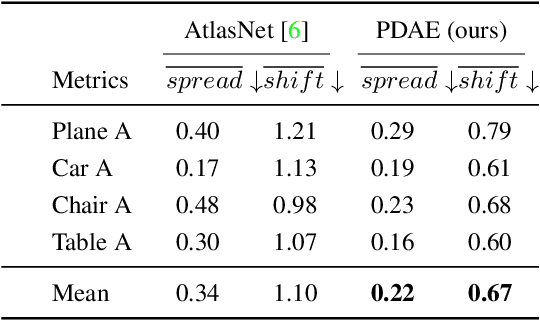
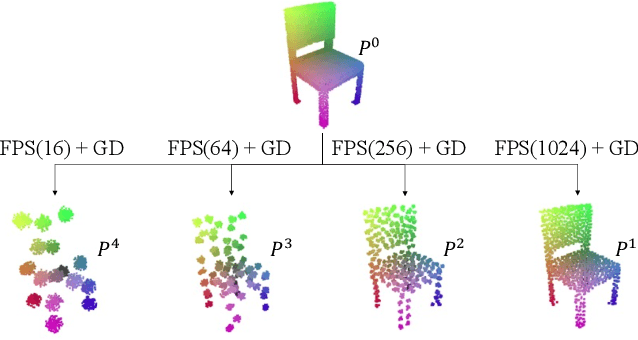
In the area of 3D shape analysis, the geometric properties of a shape have long been studied. Instead of directly extracting representative features using expert-designed descriptors or end-to-end deep neural networks, this paper is dedicated to discovering distinctive information from the shape formation process. Concretely, a spherical point cloud served as the template is progressively deformed to fit the target shape in a coarse-to-fine manner. During the shape formation process, several checkpoints are inserted to facilitate recording and investigating the intermediate stages. For each stage, the offset field is evaluated as a stage-aware description. The summation of the offsets throughout the shape formation process can completely define the target shape in terms of geometry. In this perspective, one can derive the point-wise shape correspondence from the template inexpensively, which benefits various graphic applications. In this paper, the Progressive Deformation-based Auto-Encoder (PDAE) is proposed to learn the stage-aware description through a coarse-to-fine shape fitting task. Experimental results show that the proposed PDAE has the ability to reconstruct 3D shapes with high fidelity, and consistent topology is preserved in the multi-stage deformation process. Additional applications based on the stage-aware description are performed, demonstrating its universality.
Separating Content and Style for Unsupervised Image-to-Image Translation
Oct 27, 2021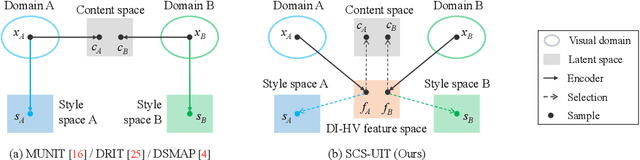
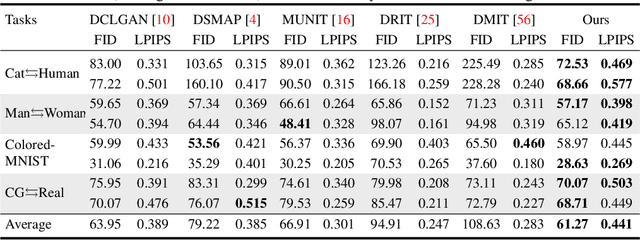
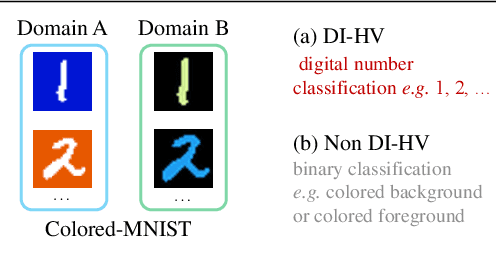
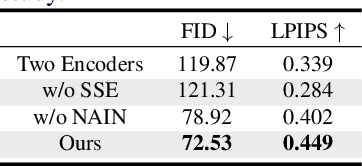
Unsupervised image-to-image translation aims to learn the mapping between two visual domains with unpaired samples. Existing works focus on disentangling domain-invariant content code and domain-specific style code individually for multimodal purposes. However, less attention has been paid to interpreting and manipulating the translated image. In this paper, we propose to separate the content code and style code simultaneously in a unified framework. Based on the correlation between the latent features and the high-level domain-invariant tasks, the proposed framework demonstrates superior performance in multimodal translation, interpretability and manipulation of the translated image. Experimental results show that the proposed approach outperforms the existing unsupervised image translation methods in terms of visual quality and diversity.
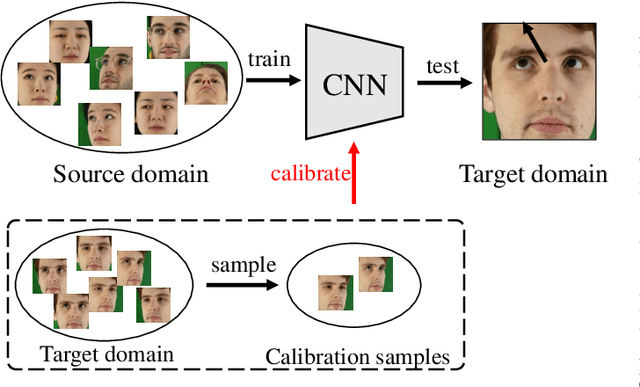
Generalizing Gaze Estimation with Outlier-guided Collaborative Adaptation
Jul 30, 2021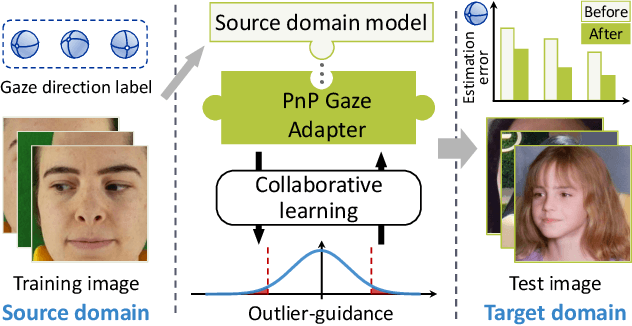

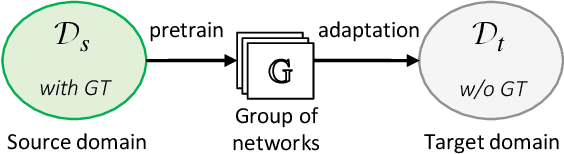
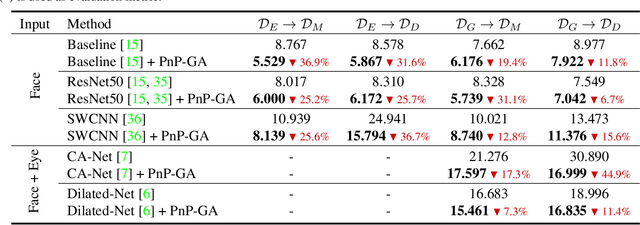
Deep neural networks have significantly improved appearance-based gaze estimation accuracy. However, it still suffers from unsatisfactory performance when generalizing the trained model to new domains, e.g., unseen environments or persons. In this paper, we propose a plug-and-play gaze adaptation framework (PnP-GA), which is an ensemble of networks that learn collaboratively with the guidance of outliers. Since our proposed framework does not require ground-truth labels in the target domain, the existing gaze estimation networks can be directly plugged into PnP-GA and generalize the algorithms to new domains. We test PnP-GA on four gaze domain adaptation tasks, ETH-to-MPII, ETH-to-EyeDiap, Gaze360-to-MPII, and Gaze360-to-EyeDiap. The experimental results demonstrate that the PnP-GA framework achieves considerable performance improvements of 36.9%, 31.6%, 19.4%, and 11.8% over the baseline system. The proposed framework also outperforms the state-of-the-art domain adaptation approaches on gaze domain adaptation tasks.
Assessment of Deep Learning-based Heart Rate Estimation using Remote Photoplethysmography under Different Illuminations
Jul 28, 2021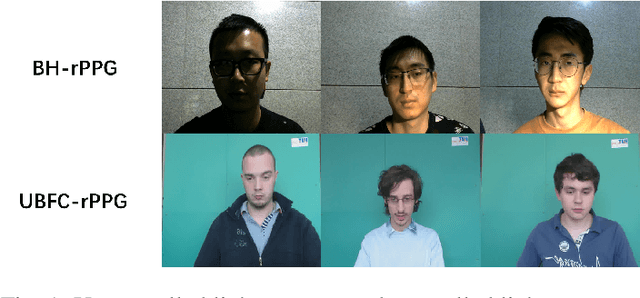
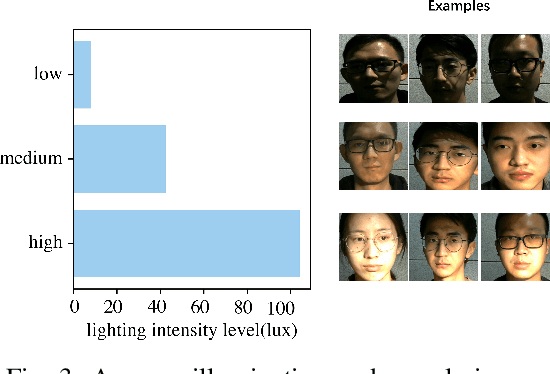
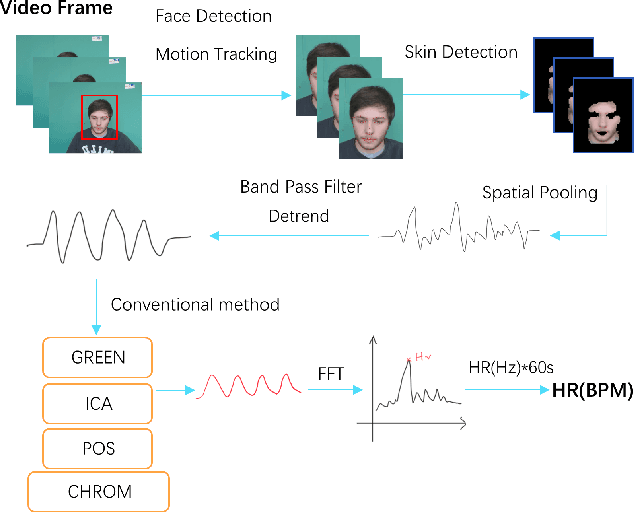
Remote photoplethysmography (rPPG) monitors heart rate without requiring physical contact, which allows for a wide variety of applications. Deep learning-based rPPG have demonstrated superior performance over the traditional approaches in controlled context. However, the lighting situation in indoor space is typically complex, with uneven light distribution and frequent variations in illumination. It lacks a fair comparison of different methods under different illuminations using the same dataset. In this paper, we present a public dataset, namely the BH-rPPG dataset, which contains data from twelve subjects under three illuminations: low, medium, and high illumination. We also provide the ground truth heart rate measured by an oximeter. We evaluate the performance of three deep learning-based methods to that of four traditional methods using two public datasets: the UBFC-rPPG dataset and the BH-rPPG dataset. The experimental results demonstrate that traditional methods are generally more resistant to fluctuating illuminations. We found that the rPPGNet achieves lowest MAE among deep learning-based method under medium illumination, whereas the CHROM achieves 1.5 beats per minute (BPM), outperforming the rPPGNet by 60%. These findings suggest that while developing deep learning-based heart rate estimation algorithms, illumination variation should be taken into account. This work serves as a benchmark for rPPG performance evaluation and it opens a pathway for future investigation into deep learning-based rPPG under illumination variations.
Explainable Diabetic Retinopathy Detection and Retinal Image Generation
Jul 01, 2021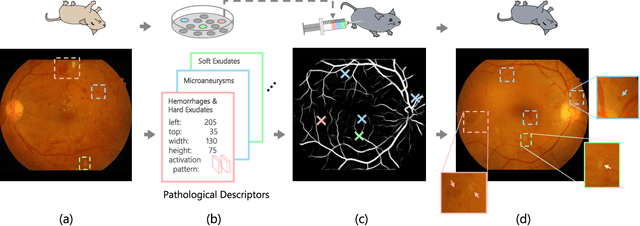
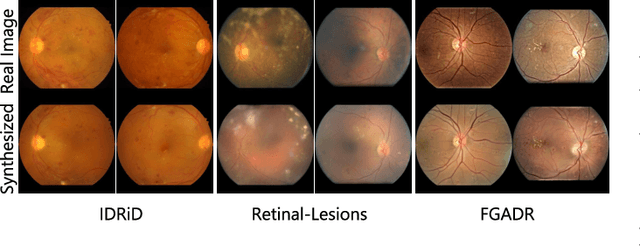
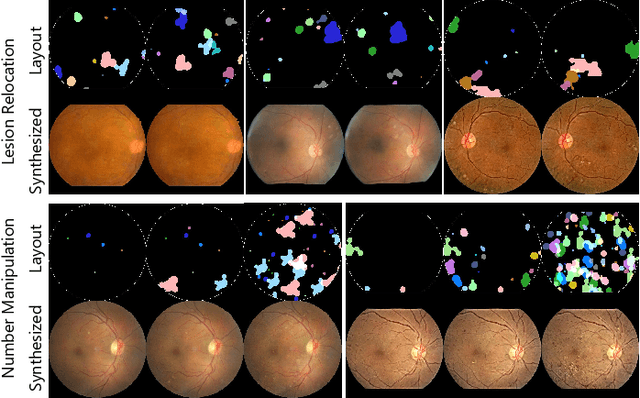
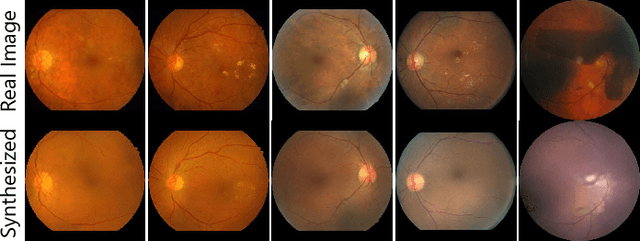
Though deep learning has shown successful performance in classifying the label and severity stage of certain diseases, most of them give few explanations on how to make predictions. Inspired by Koch's Postulates, the foundation in evidence-based medicine (EBM) to identify the pathogen, we propose to exploit the interpretability of deep learning application in medical diagnosis. By determining and isolating the neuron activation patterns on which diabetic retinopathy (DR) detector relies to make decisions, we demonstrate the direct relation between the isolated neuron activation and lesions for a pathological explanation. To be specific, we first define novel pathological descriptors using activated neurons of the DR detector to encode both spatial and appearance information of lesions. Then, to visualize the symptom encoded in the descriptor, we propose Patho-GAN, a new network to synthesize medically plausible retinal images. By manipulating these descriptors, we could even arbitrarily control the position, quantity, and categories of generated lesions. We also show that our synthesized images carry the symptoms directly related to diabetic retinopathy diagnosis. Our generated images are both qualitatively and quantitatively superior to the ones by previous methods. Besides, compared to existing methods that take hours to generate an image, our second level speed endows the potential to be an effective solution for data augmentation.
Gaze Estimation using Transformer
May 30, 2021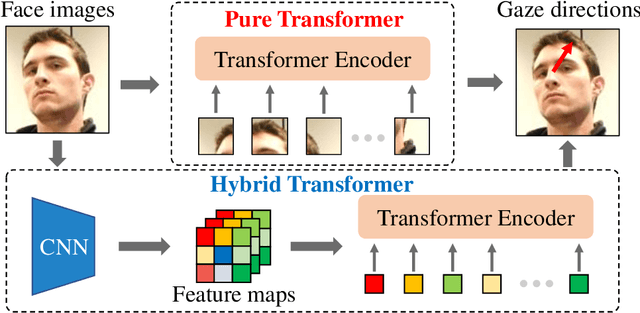
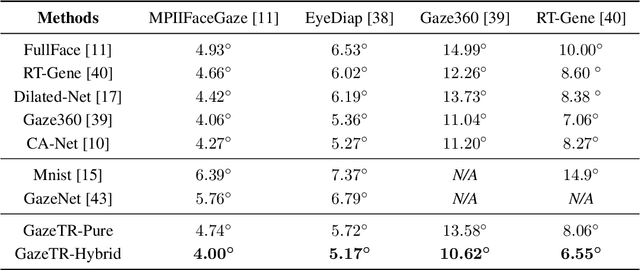

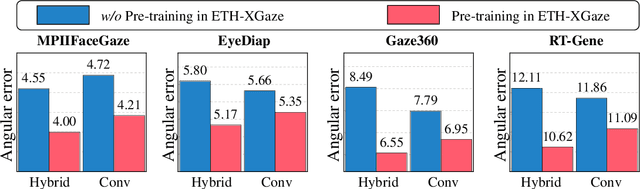
Recent work has proven the effectiveness of transformers in many computer vision tasks. However, the performance of transformers in gaze estimation is still unexplored. In this paper, we employ transformers and assess their effectiveness for gaze estimation. We consider two forms of vision transformer which are pure transformers and hybrid transformers. We first follow the popular ViT and employ a pure transformer to estimate gaze from images. On the other hand, we preserve the convolutional layers and integrate CNNs as well as transformers. The transformer serves as a component to complement CNNs. We compare the performance of the two transformers in gaze estimation. The Hybrid transformer significantly outperforms the pure transformer in all evaluation datasets with less parameters. We further conduct experiments to assess the effectiveness of the hybrid transformer and explore the advantage of self-attention mechanism. Experiments show the hybrid transformer can achieve state-of-the-art performance in all benchmarks with pre-training.To facilitate further research, we release codes and models in https://github.com/yihuacheng/GazeTR.
Appearance-based Gaze Estimation With Deep Learning: A Review and Benchmark
Apr 26, 2021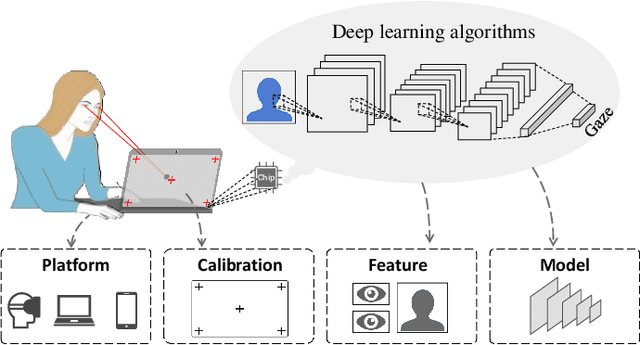


Gaze estimation reveals where a person is looking. It is an important clue for understanding human intention. The recent development of deep learning has revolutionized many computer vision tasks, the appearance-based gaze estimation is no exception. However, it lacks a guideline for designing deep learning algorithms for gaze estimation tasks. In this paper, we present a comprehensive review of the appearance-based gaze estimation methods with deep learning. We summarize the processing pipeline and discuss these methods from four perspectives: deep feature extraction, deep neural network architecture design, personal calibration as well as device and platform. Since the data pre-processing and post-processing methods are crucial for gaze estimation, we also survey face/eye detection method, data rectification method, 2D/3D gaze conversion method, and gaze origin conversion method. To fairly compare the performance of various gaze estimation approaches, we characterize all the publicly available gaze estimation datasets and collect the code of typical gaze estimation algorithms. We implement these codes and set up a benchmark of converting the results of different methods into the same evaluation metrics. This paper not only serves as a reference to develop deep learning-based gaze estimation methods but also a guideline for future gaze estimation research. Implemented methods and data processing codes are available at http://phi-ai.org/GazeHub.
STA-VPR: Spatio-temporal Alignment for Visual Place Recognition
Apr 09, 2021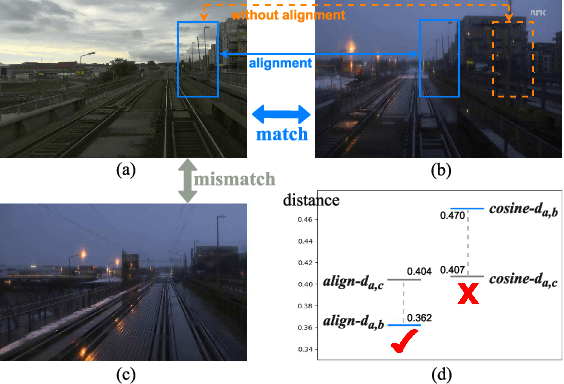
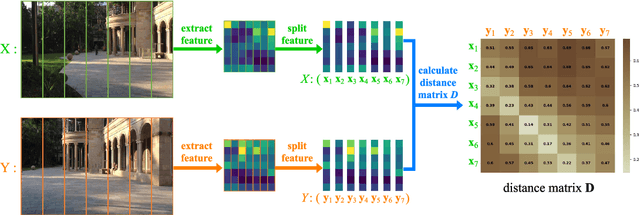
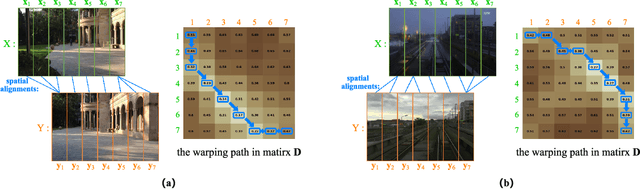
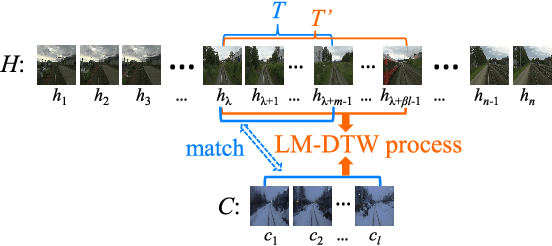
Recently, the methods based on Convolutional Neural Networks (CNNs) have gained popularity in the field of visual place recognition (VPR). In particular, the features from the middle layers of CNNs are more robust to drastic appearance changes than handcrafted features and high-layer features. Unfortunately, the holistic mid-layer features lack robustness to large viewpoint changes. Here we split the holistic mid-layer features into local features, and propose an adaptive dynamic time warping (DTW) algorithm to align local features from the spatial domain while measuring the distance between two images. This realizes viewpoint-invariant and condition-invariant place recognition. Meanwhile, a local matching DTW (LM-DTW) algorithm is applied to perform image sequence matching based on temporal alignment, which achieves further improvements and ensures linear time complexity. We perform extensive experiments on five representative VPR datasets. The results show that the proposed method significantly improves the CNN-based methods. Moreover, our method outperforms several state-of-the-art methods while maintaining good run-time performance. This work provides a novel way to boost the performance of CNN methods without any re-training for VPR. The code is available at https://github.com/Lu-Feng/STA-VPR.
* Accepted for publication in IEEE RA-L 2021
PureGaze: Purifying Gaze Feature for Generalizable Gaze Estimation
Mar 24, 2021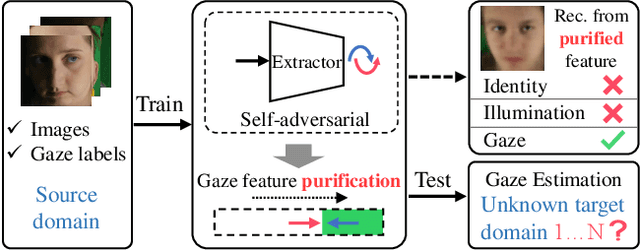
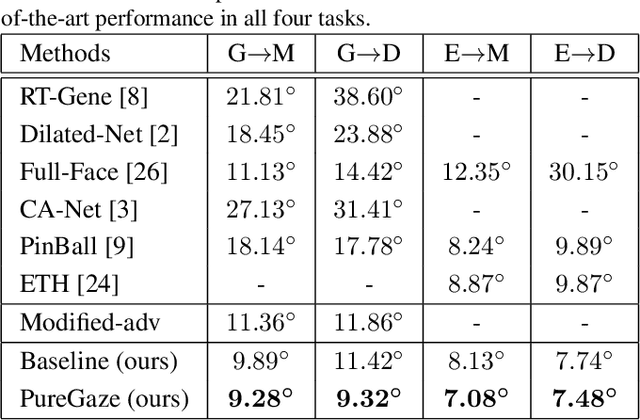
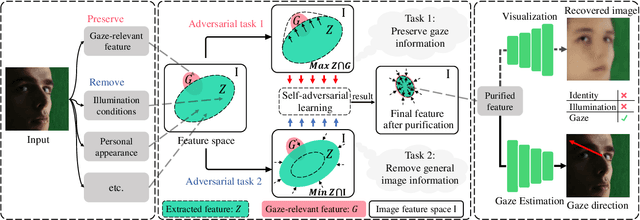
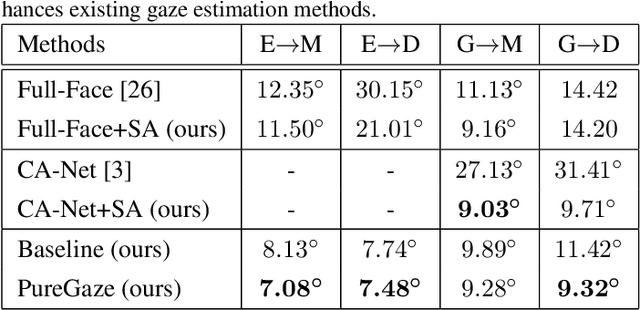
Gaze estimation methods learn eye gaze from facial features. However, among rich information in the facial image, real gaze-relevant features only correspond to subtle changes in eye region, while other gaze-irrelevant features like illumination, personal appearance and even facial expression may affect the learning in an unexpected way. This is a major reason why existing methods show significant performance degradation in cross-domain/dataset evaluation. In this paper, we tackle the domain generalization problem in cross-domain gaze estimation for unknown target domains. To be specific, we realize the domain generalization by gaze feature purification. We eliminate gaze-irrelevant factors such as illumination and identity to improve the cross-dataset performance without knowing the target dataset. We design a plug-and-play self-adversarial framework for the gaze feature purification. The framework enhances not only our baseline but also existing gaze estimation methods directly and significantly. Our method achieves the state-of-the-art performance in different benchmarks. Meanwhile, the purification is easily explainable via visualization.