 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Language Learning in a Simulated 3D World
Jun 26, 2017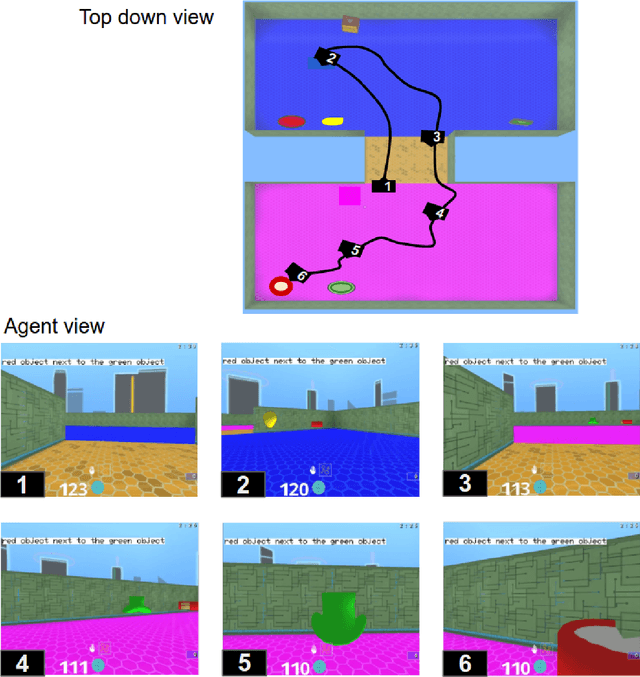

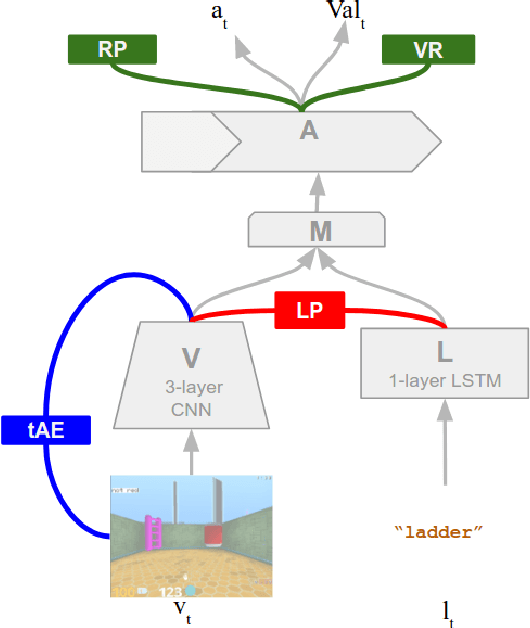
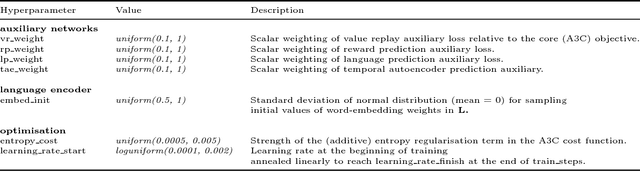
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
HyperLex: A Large-Scale Evaluation of Graded Lexical Entailment
May 10, 2017We introduce HyperLex - a dataset and evaluation resource that quantifies the extent of of the semantic category membership, that is, type-of relation also known as hyponymy-hypernymy or lexical entailment (LE) relation between 2,616 concept pairs. Cognitive psychology research has established that typicality and category/class membership are computed in human semantic memory as a gradual rather than binary relation. Nevertheless, most NLP research, and existing large-scale invetories of concept category membership (WordNet, DBPedia, etc.) treat category membership and LE as binary. To address this, we asked hundreds of native English speakers to indicate typicality and strength of category membership between a diverse range of concept pairs on a crowdsourcing platform. Our results confirm that category membership and LE are indeed more gradual than binary. We then compare these human judgements with the predictions of automatic systems, which reveals a huge gap between human performance and state-of-the-art LE, distributional and representation learning models, and substantial differences between the models themselves. We discuss a pathway for improving semantic models to overcome this discrepancy, and indicate future application areas for improved graded LE systems.
SimVerb-3500: A Large-Scale Evaluation Set of Verb Similarity
Sep 20, 2016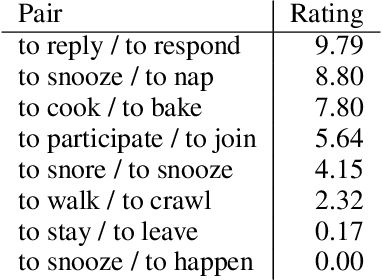
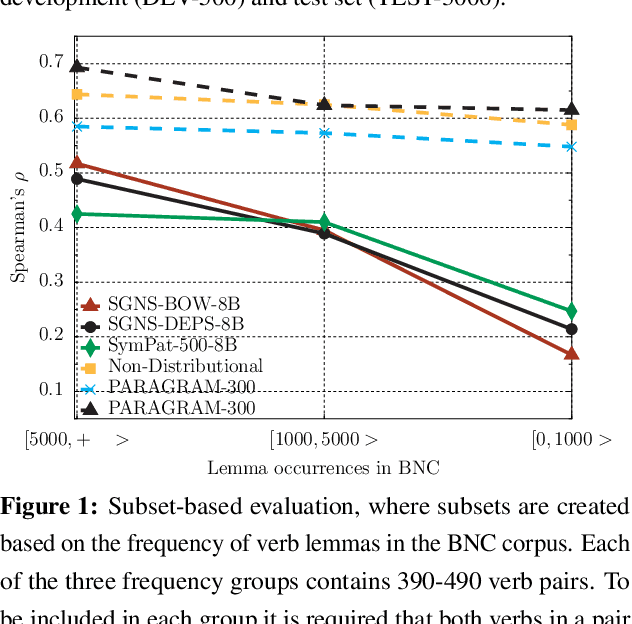
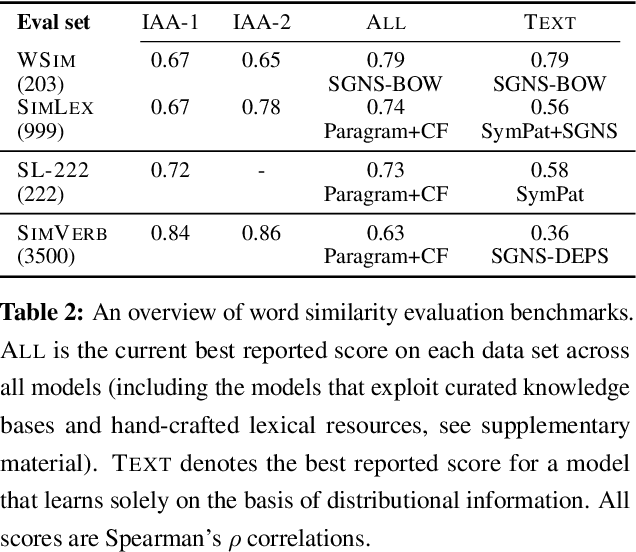
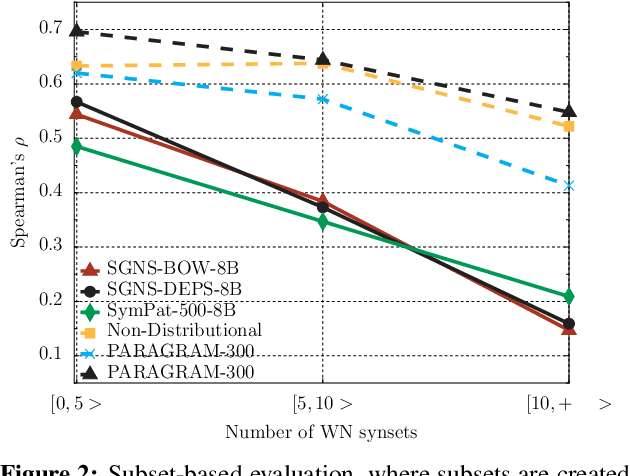
Verbs play a critical role in the meaning of sentences, but these ubiquitous words have received little attention in recent distributional semantics research. We introduce SimVerb-3500, an evaluation resource that provides human ratings for the similarity of 3,500 verb pairs. SimVerb-3500 covers all normed verb types from the USF free-association database, providing at least three examples for every VerbNet class. This broad coverage facilitates detailed analyses of how syntactic and semantic phenomena together influence human understanding of verb meaning. Further, with significantly larger development and test sets than existing benchmarks, SimVerb-3500 enables more robust evaluation of representation learning architectures and promotes the development of methods tailored to verbs. We hope that SimVerb-3500 will enable a richer understanding of the diversity and complexity of verb semantics and guide the development of systems that can effectively represent and interpret this meaning.
The Goldilocks Principle: Reading Children's Books with Explicit Memory Representations
Apr 01, 2016
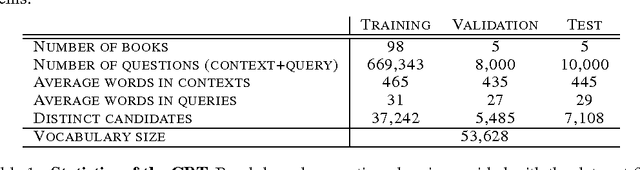
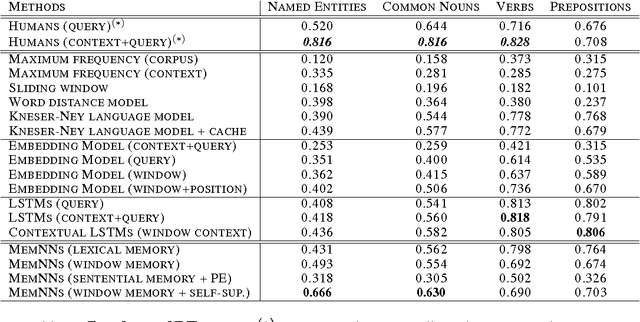

We introduce a new test of how well language models capture meaning in children's books. Unlike standard language modelling benchmarks, it distinguishes the task of predicting syntactic function words from that of predicting lower-frequency words, which carry greater semantic content. We compare a range of state-of-the-art models, each with a different way of encoding what has been previously read. We show that models which store explicit representations of long-term contexts outperform state-of-the-art neural language models at predicting semantic content words, although this advantage is not observed for syntactic function words. Interestingly, we find that the amount of text encoded in a single memory representation is highly influential to the performance: there is a sweet-spot, not too big and not too small, between single words and full sentences that allows the most meaningful information in a text to be effectively retained and recalled. Further, the attention over such window-based memories can be trained effectively through self-supervision. We then assess the generality of this principle by applying it to the CNN QA benchmark, which involves identifying named entities in paraphrased summaries of news articles, and achieve state-of-the-art performance.
Learning to Understand Phrases by Embedding the Dictionary
Mar 22, 2016Distributional models that learn rich semantic word representations are a success story of recent NLP research. However, developing models that learn useful representations of phrases and sentences has proved far harder. We propose using the definitions found in everyday dictionaries as a means of bridging this gap between lexical and phrasal semantics. Neural language embedding models can be effectively trained to map dictionary definitions (phrases) to (lexical) representations of the words defined by those definitions. We present two applications of these architectures: "reverse dictionaries" that return the name of a concept given a definition or description and general-knowledge crossword question answerers. On both tasks, neural language embedding models trained on definitions from a handful of freely-available lexical resources perform as well or better than existing commercial systems that rely on significant task-specific engineering. The results highlight the effectiveness of both neural embedding architectures and definition-based training for developing models that understand phrases and sentences.
Learning Distributed Representations of Sentences from Unlabelled Data
Feb 10, 2016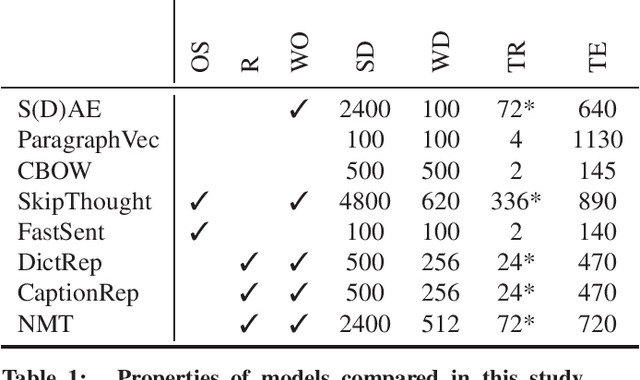
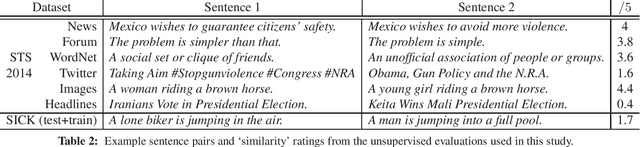
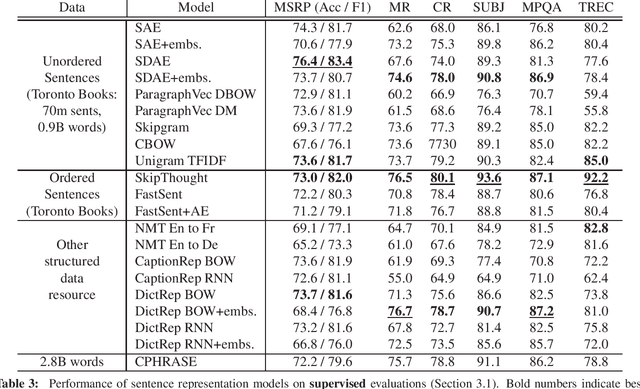
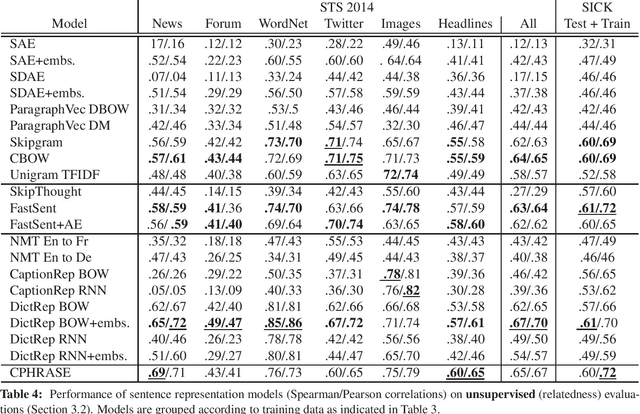
Unsupervised methods for learning distributed representations of words are ubiquitous in today's NLP research, but far less is known about the best ways to learn distributed phrase or sentence representations from unlabelled data. This paper is a systematic comparison of models that learn such representations. We find that the optimal approach depends critically on the intended application. Deeper, more complex models are preferable for representations to be used in supervised systems, but shallow log-linear models work best for building representation spaces that can be decoded with simple spatial distance metrics. We also propose two new unsupervised representation-learning objectives designed to optimise the trade-off between training time, domain portability and performance.
Embedding Word Similarity with Neural Machine Translation
Apr 03, 2015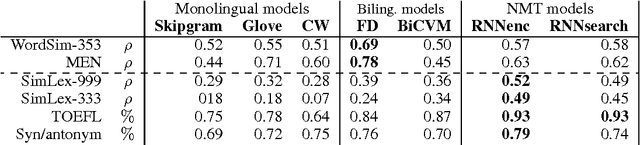
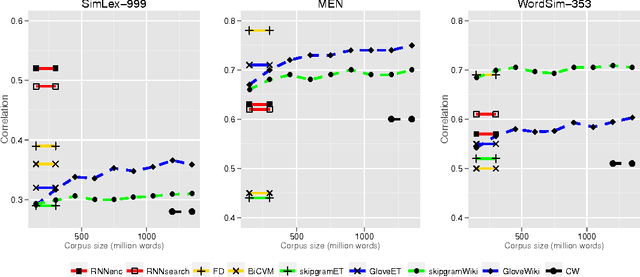
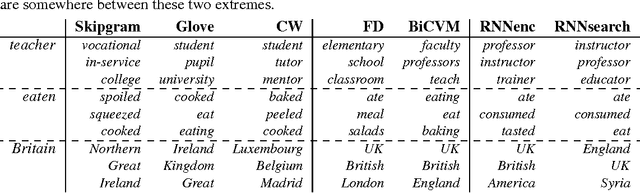
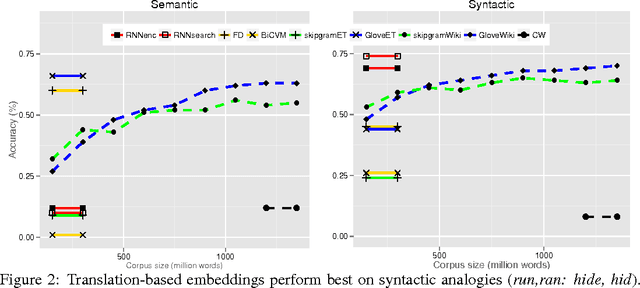
Neural language models learn word representations, or embeddings, that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models, a recently-developed class of neural language model. We show that embeddings from translation models outperform those learned by monolingual models at tasks that require knowledge of both conceptual similarity and lexical-syntactic role. We further show that these effects hold when translating from both English to French and English to German, and argue that the desirable properties of translation embeddings should emerge largely independently of the source and target languages. Finally, we apply a new method for training neural translation models with very large vocabularies, and show that this vocabulary expansion algorithm results in minimal degradation of embedding quality. Our embedding spaces can be queried in an online demo and downloaded from our web page. Overall, our analyses indicate that translation-based embeddings should be used in applications that require concepts to be organised according to similarity and/or lexical function, while monolingual embeddings are better suited to modelling (nonspecific) inter-word relatedness.
Not All Neural Embeddings are Born Equal
Nov 13, 2014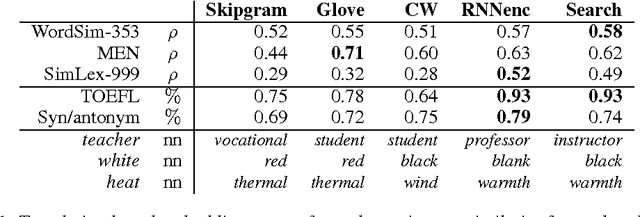
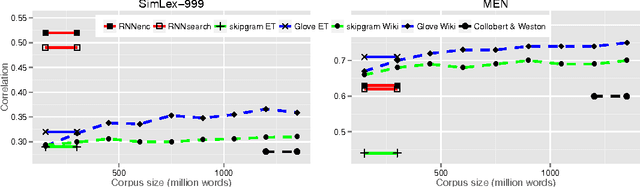
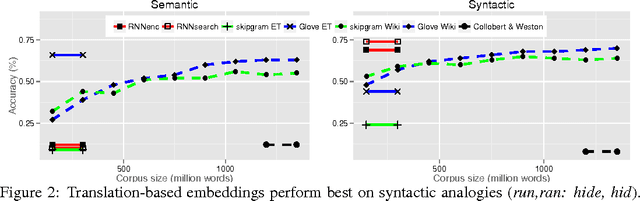
Neural language models learn word representations that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models. We show that translation-based embeddings outperform those learned by cutting-edge monolingual models at single-language tasks requiring knowledge of conceptual similarity and/or syntactic role. The findings suggest that, while monolingual models learn information about how concepts are related, neural-translation models better capture their true ontological status.
SimLex-999: Evaluating Semantic Models with (Genuine) Similarity Estimation
Aug 15, 2014We present SimLex-999, a gold standard resource for evaluating distributional semantic models that improves on existing resources in several important ways. First, in contrast to gold standards such as WordSim-353 and MEN, it explicitly quantifies similarity rather than association or relatedness, so that pairs of entities that are associated but not actually similar [Freud, psychology] have a low rating. We show that, via this focus on similarity, SimLex-999 incentivizes the development of models with a different, and arguably wider range of applications than those which reflect conceptual association. Second, SimLex-999 contains a range of concrete and abstract adjective, noun and verb pairs, together with an independent rating of concreteness and (free) association strength for each pair. This diversity enables fine-grained analyses of the performance of models on concepts of different types, and consequently greater insight into how architectures can be improved. Further, unlike existing gold standard evaluations, for which automatic approaches have reached or surpassed the inter-annotator agreement ceiling, state-of-the-art models perform well below this ceiling on SimLex-999. There is therefore plenty of scope for SimLex-999 to quantify future improvements to distributional semantic models, guiding the development of the next generation of representation-learning architectures.