 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFelix Hill
Language models show human-like content effects on reasoning
Jul 14, 2022




Abstract reasoning is a key ability for an intelligent system. Large language models achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human abstract reasoning is also imperfect, and depends on our knowledge and beliefs about the content of the reasoning problem. For example, humans reason much more reliably about logical rules that are grounded in everyday situations than arbitrary rules about abstract attributes. The training experiences of language models similarly endow them with prior expectations that reflect human knowledge and beliefs. We therefore hypothesized that language models would show human-like content effects on abstract reasoning problems. We explored this hypothesis across three logical reasoning tasks: natural language inference, judging the logical validity of syllogisms, and the Wason selection task (Wason, 1968). We find that state of the art large language models (with 7 or 70 billion parameters; Hoffman et al., 2022) reflect many of the same patterns observed in humans across these tasks -- like humans, models reason more effectively about believable situations than unrealistic or abstract ones. Our findings have implications for understanding both these cognitive effects, and the factors that contribute to language model performance.
Know your audience: specializing grounded language models with the game of Dixit
Jun 16, 2022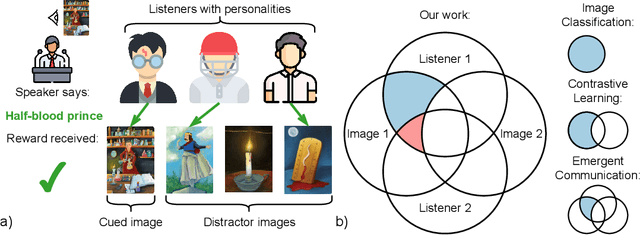
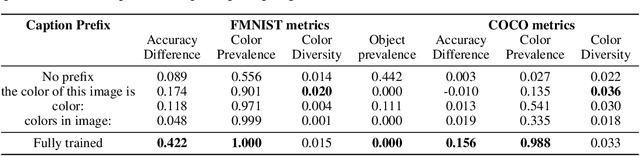
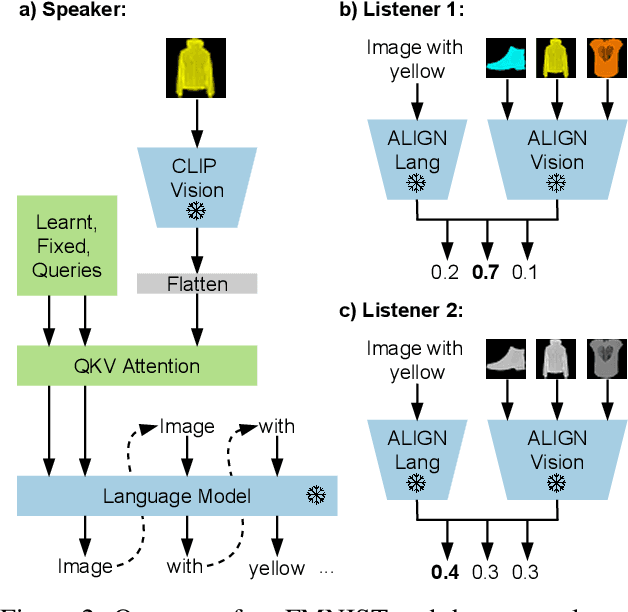
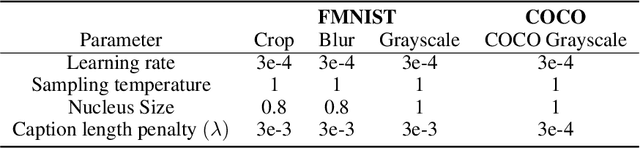
Effective communication requires adapting to the idiosyncratic common ground shared with each communicative partner. We study a particularly challenging instantiation of this problem: the popular game Dixit. We formulate a round of Dixit as a multi-agent image reference game where a (trained) speaker model is rewarded for describing a target image such that one (pretrained) listener model can correctly identify it from a pool of distractors, but another listener cannot. To adapt to this setting, the speaker must exploit differences in the common ground it shares with the different listeners. We show that finetuning an attention-based adapter between a CLIP vision encoder and a large language model in this contrastive, multi-agent setting gives rise to context-dependent natural language specialization from rewards only, without direct supervision. In a series of controlled experiments, we show that the speaker can adapt according to the idiosyncratic strengths and weaknesses of various pairs of different listeners. Furthermore, we show zero-shot transfer of the speaker's specialization to unseen real-world data. Our experiments offer a step towards adaptive communication in complex multi-partner settings and highlight the interesting research challenges posed by games like Dixit. We hope that our work will inspire creative new approaches to adapting pretrained models.
Semantic Exploration from Language Abstractions and Pretrained Representations
Apr 08, 2022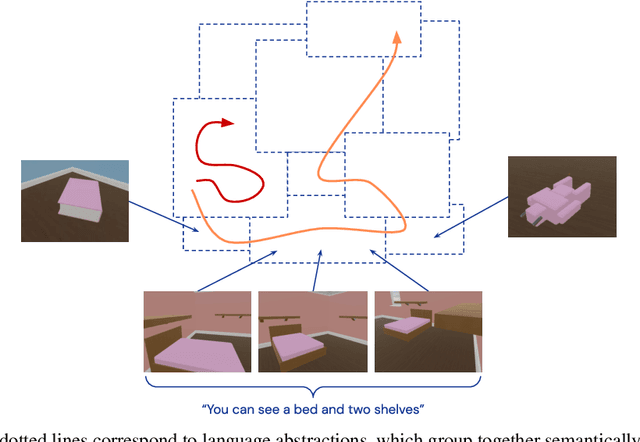


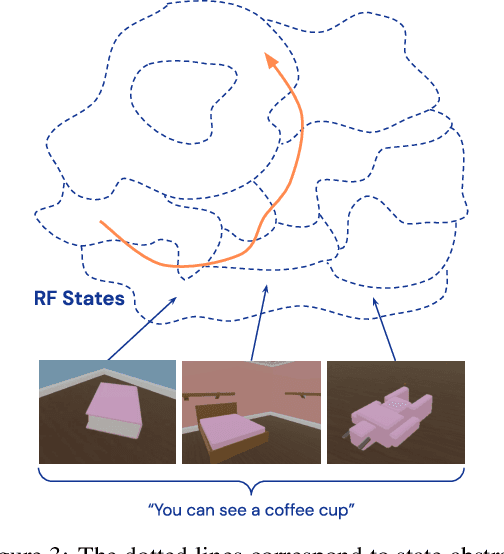
Continuous first-person 3D environments pose unique exploration challenges to reinforcement learning (RL) agents because of their high-dimensional state and action spaces. These challenges can be ameliorated by using semantically meaningful state abstractions to define novelty for exploration. We propose that learned representations shaped by natural language provide exactly this form of abstraction. In particular, we show that vision-language representations, when pretrained on image captioning datasets sampled from the internet, can drive meaningful, task-relevant exploration and improve performance on 3D simulated environments. We also characterize why and how language provides useful abstractions for exploration by comparing the impacts of using representations from a pretrained model, a language oracle, and several ablations. We demonstrate the benefits of our approach in two very different task domains -- one that stresses the identification and manipulation of everyday objects, and one that requires navigational exploration in an expansive world -- as well as two popular deep RL algorithms: Impala and R2D2. Our results suggest that using language-shaped representations could improve exploration for various algorithms and agents in challenging environments.
Can language models learn from explanations in context?
Apr 05, 2022
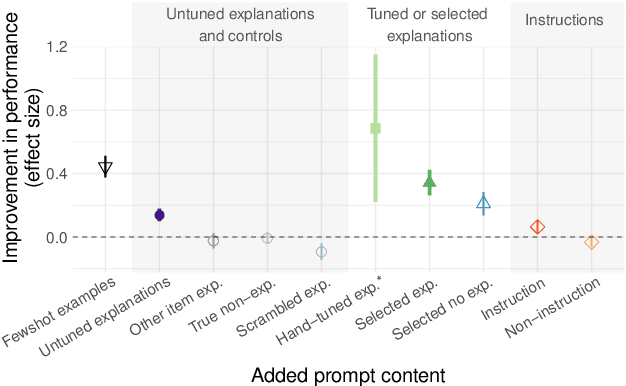
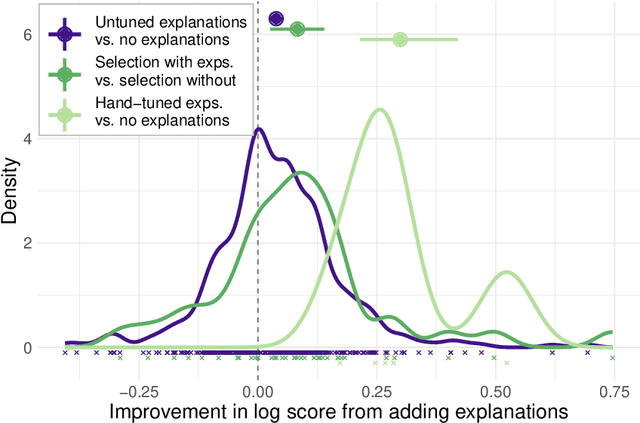

Large language models can perform new tasks by adapting to a few in-context examples. For humans, rapid learning from examples can benefit from explanations that connect examples to task principles. We therefore investigate whether explanations of few-shot examples can allow language models to adapt more effectively. We annotate a set of 40 challenging tasks from BIG-Bench with explanations of answers to a small subset of questions, as well as a variety of matched control explanations. We evaluate the effects of various zero-shot and few-shot prompts that include different types of explanations, instructions, and controls on the performance of a range of large language models. We analyze these results using statistical multilevel modeling techniques that account for the nested dependencies among conditions, tasks, prompts, and models. We find that explanations of examples can improve performance. Adding untuned explanations to a few-shot prompt offers a modest improvement in performance; about 1/3 the effect size of adding few-shot examples, but twice the effect size of task instructions. We then show that explanations tuned for performance on a small validation set offer substantially larger benefits; building a prompt by selecting examples and explanations together substantially improves performance over selecting examples alone. Hand-tuning explanations can substantially improve performance on challenging tasks. Furthermore, even untuned explanations outperform carefully matched controls, suggesting that the benefits are due to the link between an example and its explanation, rather than lower-level features of the language used. However, only large models can benefit from explanations. In summary, explanations can support the in-context learning abilities of large language models on
Zipfian environments for Reinforcement Learning
Mar 15, 2022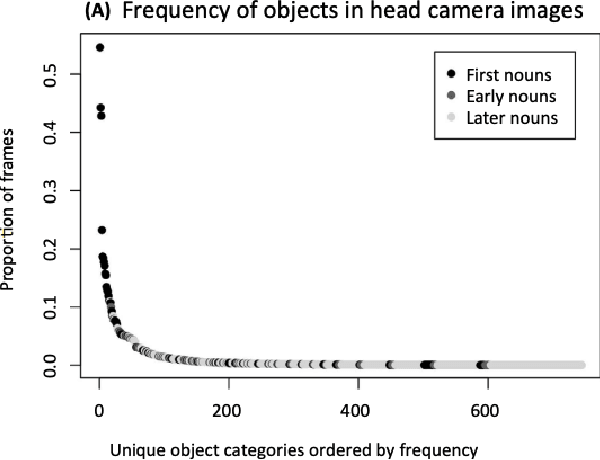
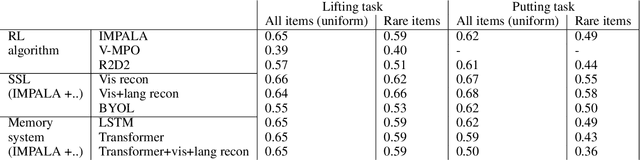
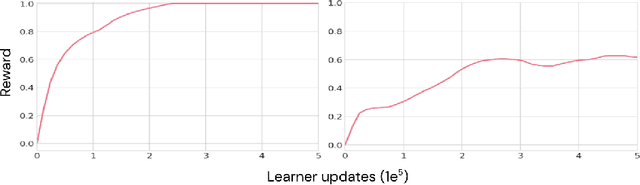
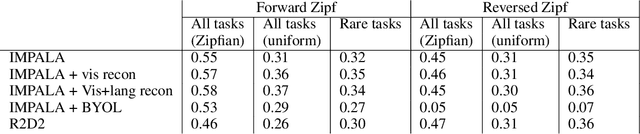
As humans and animals learn in the natural world, they encounter distributions of entities, situations and events that are far from uniform. Typically, a relatively small set of experiences are encountered frequently, while many important experiences occur only rarely. The highly-skewed, heavy-tailed nature of reality poses particular learning challenges that humans and animals have met by evolving specialised memory systems. By contrast, most popular RL environments and benchmarks involve approximately uniform variation of properties, objects, situations or tasks. How will RL algorithms perform in worlds (like ours) where the distribution of environment features is far less uniform? To explore this question, we develop three complementary RL environments where the agent's experience varies according to a Zipfian (discrete power law) distribution. On these benchmarks, we find that standard Deep RL architectures and algorithms acquire useful knowledge of common situations and tasks, but fail to adequately learn about rarer ones. To understand this failure better, we explore how different aspects of current approaches may be adjusted to help improve performance on rare events, and show that the RL objective function, the agent's memory system and self-supervised learning objectives can all influence an agent's ability to learn from uncommon experiences. Together, these results show that learning robustly from skewed experience is a critical challenge for applying Deep RL methods beyond simulations or laboratories, and our Zipfian environments provide a basis for measuring future progress towards this goal.
Feature-Attending Recurrent Modules for Generalization in Reinforcement Learning
Dec 15, 2021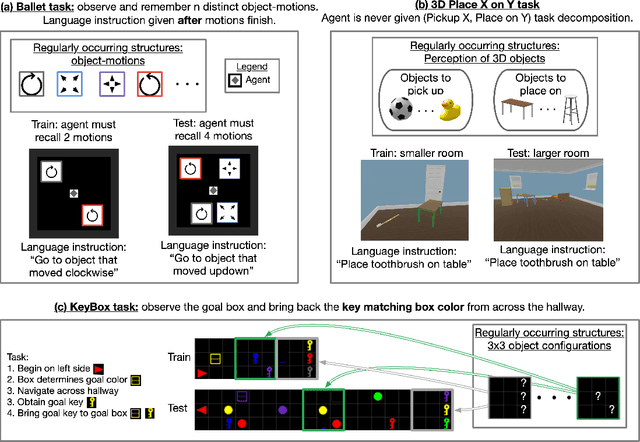
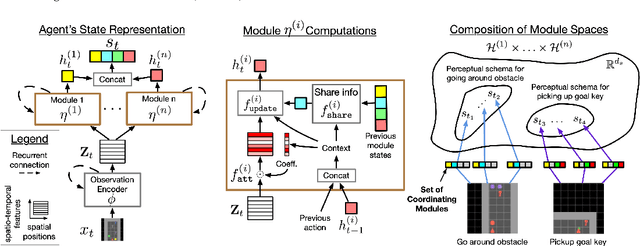
Deep reinforcement learning (Deep RL) has recently seen significant progress in developing algorithms for generalization. However, most algorithms target a single type of generalization setting. In this work, we study generalization across three disparate task structures: (a) tasks composed of spatial and temporal compositions of regularly occurring object motions; (b) tasks composed of active perception of and navigation towards regularly occurring 3D objects; and (c) tasks composed of remembering goal-information over sequences of regularly occurring object-configurations. These diverse task structures all share an underlying idea of compositionality: task completion always involves combining recurring segments of task-oriented perception and behavior. We hypothesize that an agent can generalize within a task structure if it can discover representations that capture these recurring task-segments. For our tasks, this corresponds to representations for recognizing individual object motions, for navigation towards 3D objects, and for navigating through object-configurations. Taking inspiration from cognitive science, we term representations for recurring segments of an agent's experience, "perceptual schemas". We propose Feature Attending Recurrent Modules (FARM), which learns a state representation where perceptual schemas are distributed across multiple, relatively small recurrent modules. We compare FARM to recurrent architectures that leverage spatial attention, which reduces observation features to a weighted average over spatial positions. Our experiments indicate that our feature-attention mechanism better enables FARM to generalize across the diverse object-centric domains we study.
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021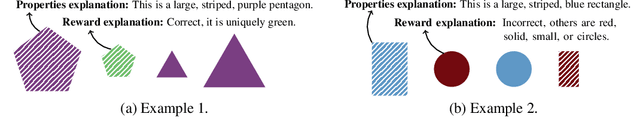
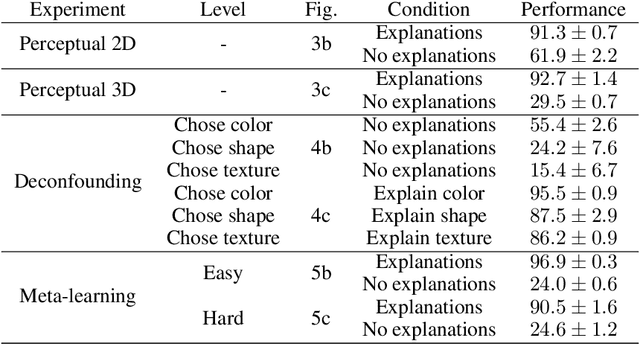
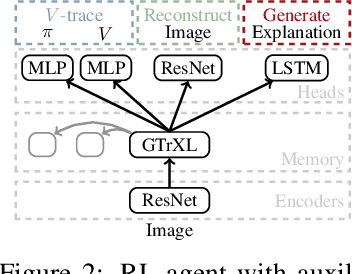
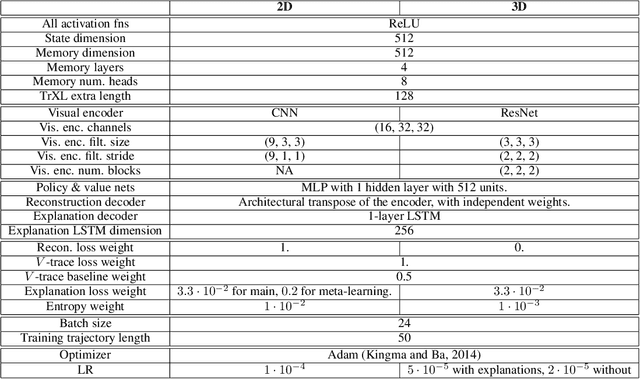
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
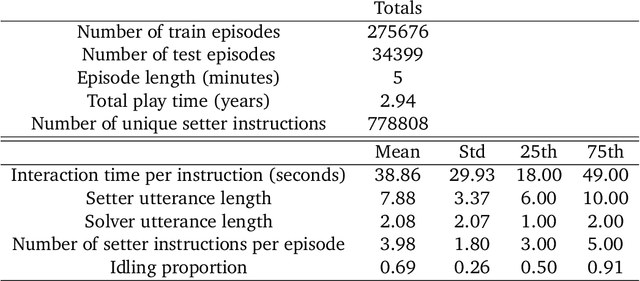
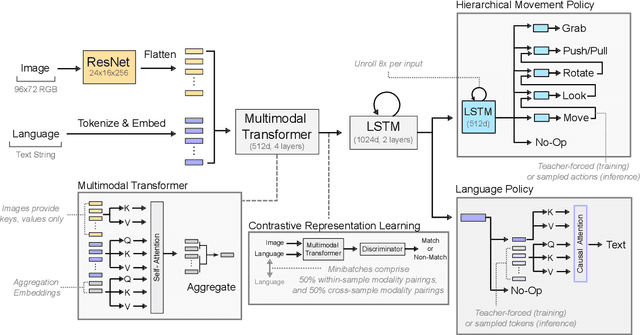
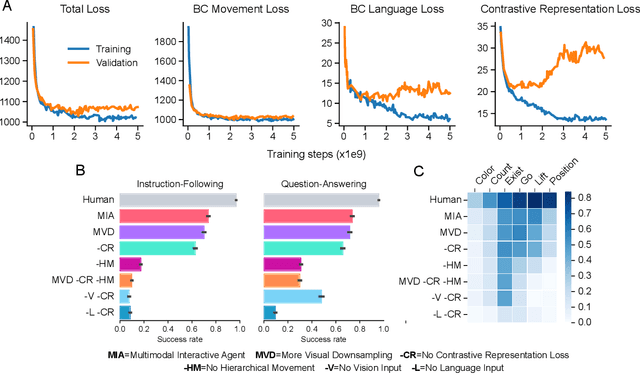
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY
BEAMetrics: A Benchmark for Language Generation Evaluation Evaluation
Oct 18, 2021
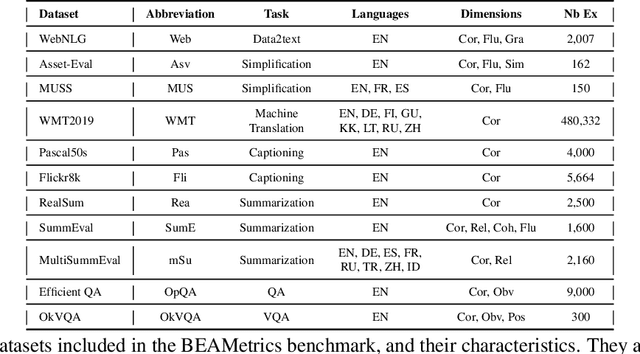
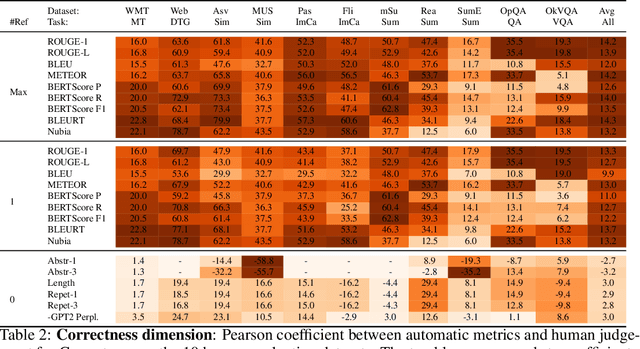
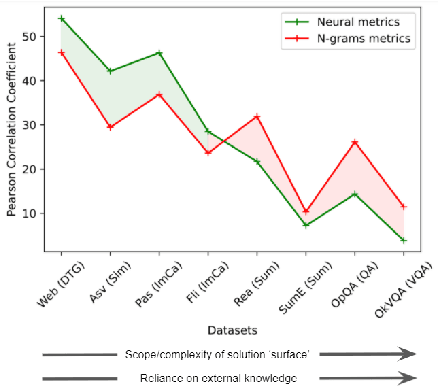
Natural language processing (NLP) systems are increasingly trained to generate open-ended text rather than classifying between responses. This makes research on evaluation metrics for generated language -- functions that score system output given the context and/or human reference responses -- of critical importance. However, different metrics have different strengths and biases, and reflect human intuitions better on some tasks than others. There is currently no simple, unified way to compare, analyse or evaluate metrics across a representative set of tasks. Here, we describe the Benchmark to Evaluate Automatic Metrics (BEAMetrics), a resource to make research into new metrics itself easier to evaluate. BEAMetrics users can quickly compare existing and new metrics with human judgements across a diverse set of tasks, quality dimensions (fluency vs. coherence vs. informativeness etc), and languages. As generation experts might predict, BEAMetrics reveals stark task-dependent differences between existing metrics, and consistently poor performance on tasks with complex answer spaces or high reliance on general knowledge. While this analysis highlights a critical issue facing current research practice, BEAMetrics also contribute to its resolution by facilitating research into better metrics -- particularly those that can account for the complex interaction between context and general knowledge inherent to many modern NLP applications. BEAMetrics is available under the MIT License: https://github.com/ThomasScialom/BEAMetrics
Multimodal Few-Shot Learning with Frozen Language Models
Jul 03, 2021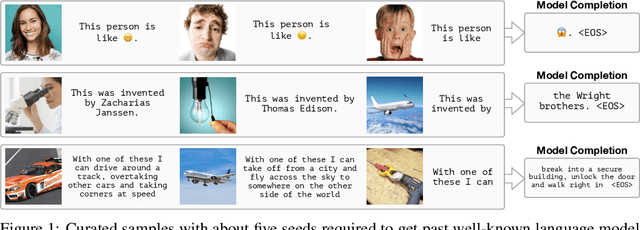
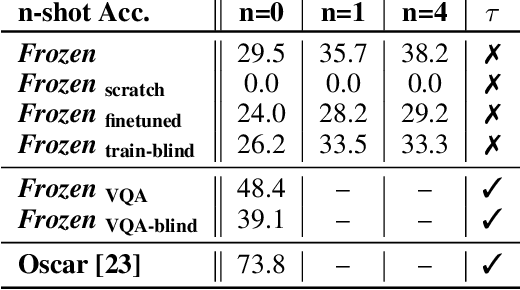
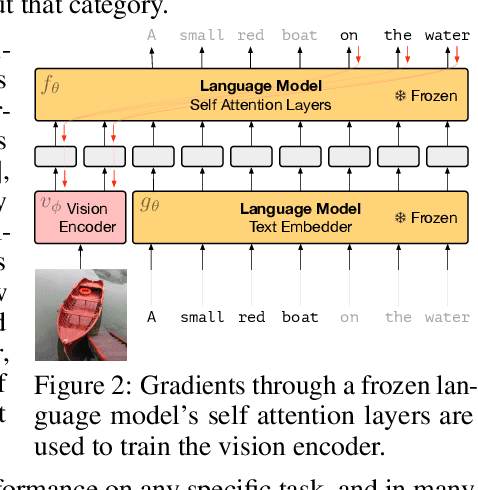
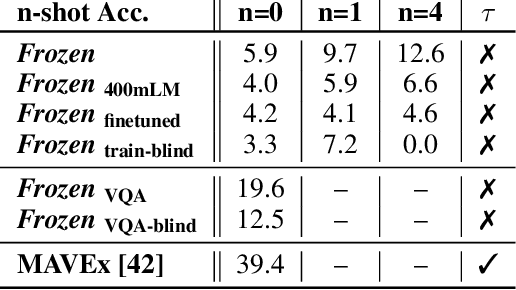
When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples. Here, we present a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language). Using aligned image and caption data, we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption. The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings. We demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.