 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMRF: View Matching Neural Radiance Fields
Jul 06, 2022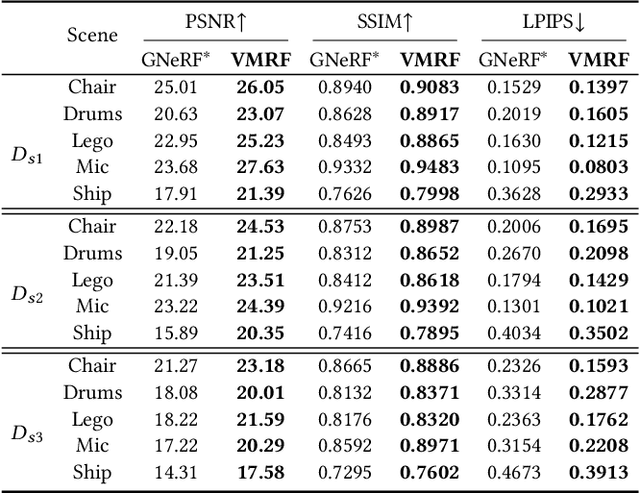
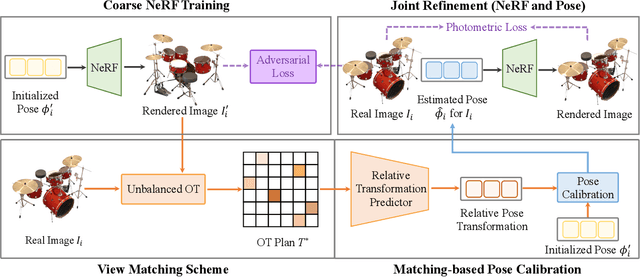
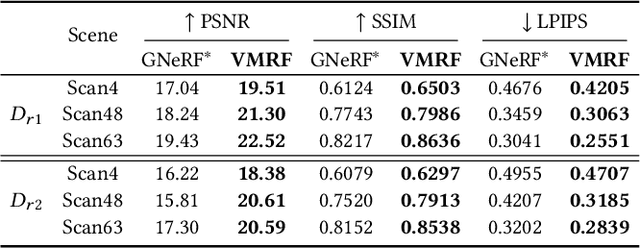
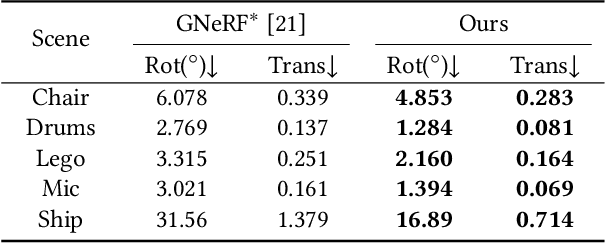
Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022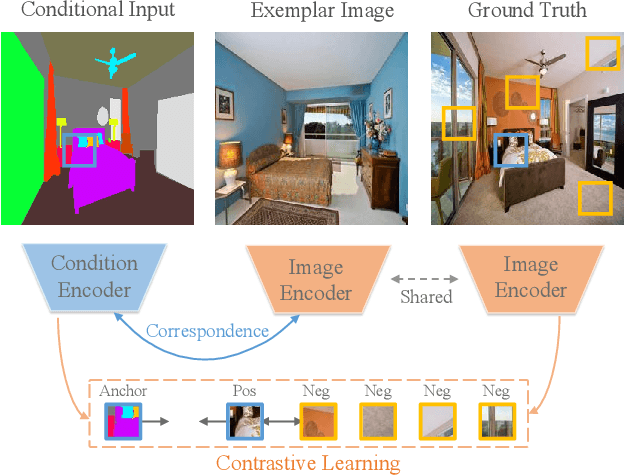
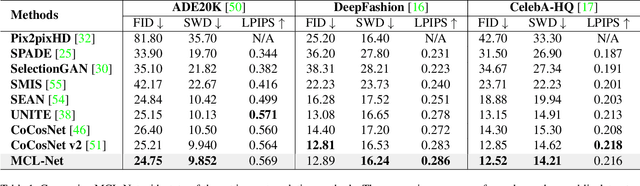
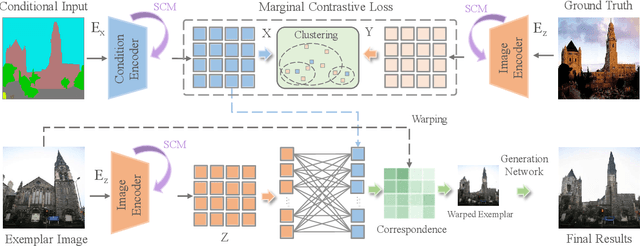
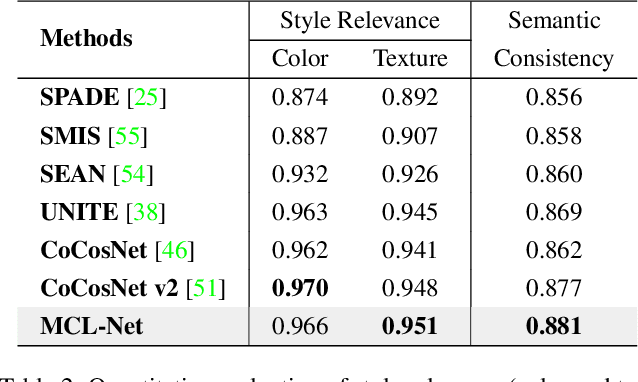
Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
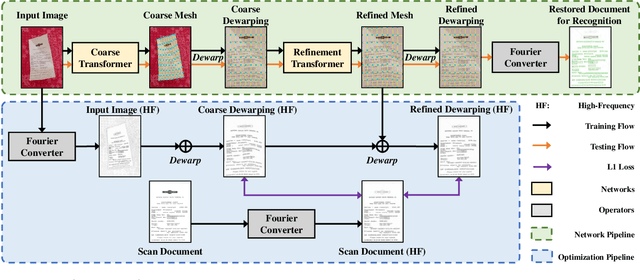
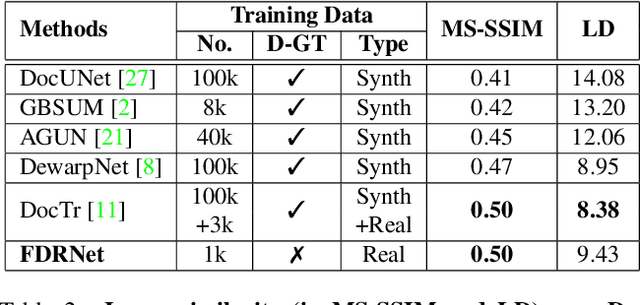
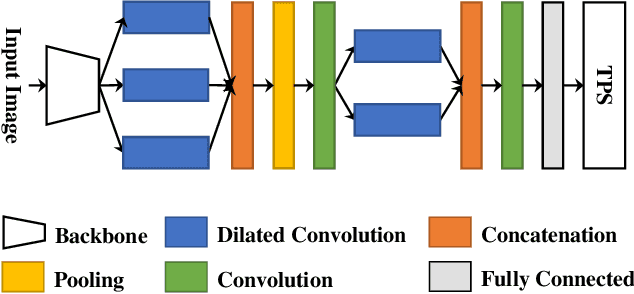
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Modulated Contrast for Versatile Image Synthesis
Mar 17, 2022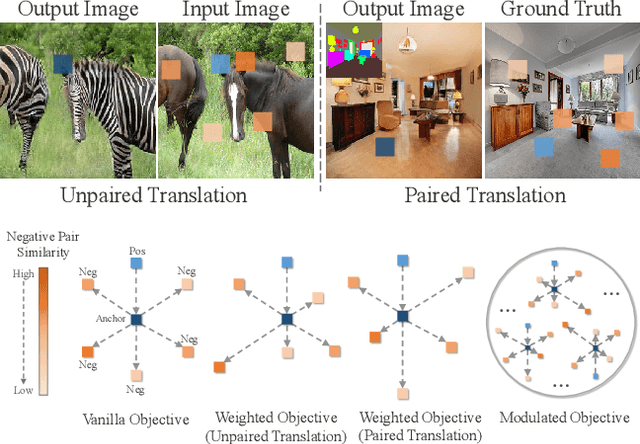
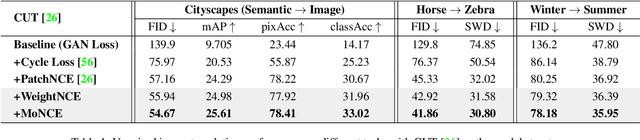

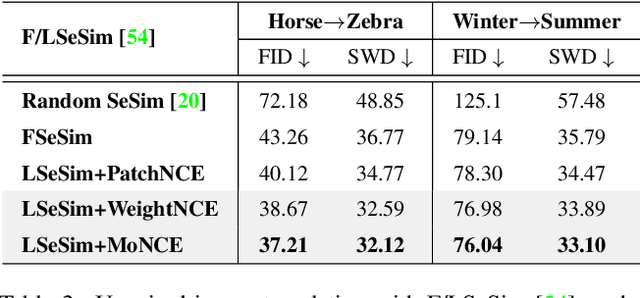
Perceiving the similarity between images has been a long-standing and fundamental problem underlying various visual generation tasks. Predominant approaches measure the inter-image distance by computing pointwise absolute deviations, which tends to estimate the median of instance distributions and leads to blurs and artifacts in the generated images. This paper presents MoNCE, a versatile metric that introduces image contrast to learn a calibrated metric for the perception of multifaceted inter-image distances. Unlike vanilla contrast which indiscriminately pushes negative samples from the anchor regardless of their similarity, we propose to re-weight the pushing force of negative samples adaptively according to their similarity to the anchor, which facilitates the contrastive learning from informative negative samples. Since multiple patch-level contrastive objectives are involved in image distance measurement, we introduce optimal transport in MoNCE to modulate the pushing force of negative samples collaboratively across multiple contrastive objectives. Extensive experiments over multiple image translation tasks show that the proposed MoNCE outperforms various prevailing metrics substantially. The code is available at https://github.com/fnzhan/MoNCE.
Multimodal Image Synthesis and Editing: A Survey
Dec 27, 2021

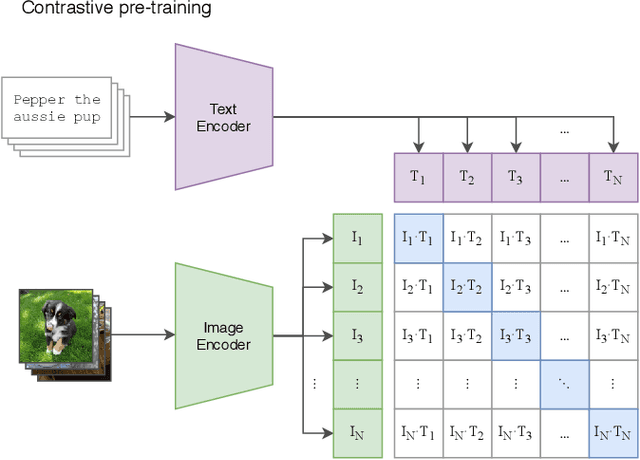
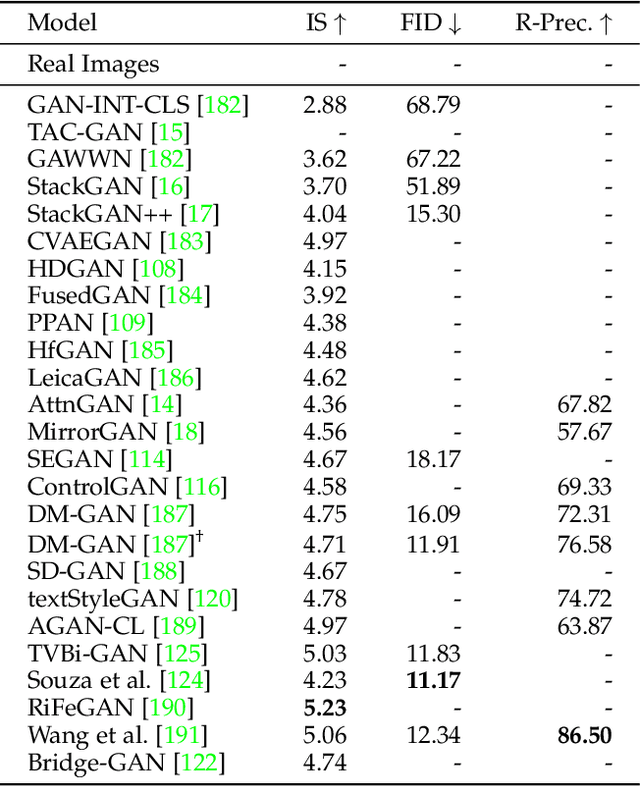
As information exists in various modalities in real world, effective interaction and fusion among multimodal information plays a key role for the creation and perception of multimodal data in computer vision and deep learning research. With superb power in modelling the interaction among multimodal information, multimodal image synthesis and editing have become a hot research topic in recent years. Different from traditional visual guidance which provides explicit clues, multimodal guidance offers intuitive and flexible means in image synthesis and editing. On the other hand, this field is also facing several challenges in alignment of features with inherent modality gaps, synthesis of high-resolution images, faithful evaluation metrics, etc. In this survey, we comprehensively contextualize the advance of the recent multimodal image synthesis \& editing and formulate taxonomies according to data modality and model architectures. We start with an introduction to different types of guidance modalities in image synthesis and editing. We then describe multimodal image synthesis and editing approaches extensively with detailed frameworks including Generative Adversarial Networks (GANs), GAN Inversion, Transformers, and other methods such as NeRF and Diffusion models. This is followed by a comprehensive description of benchmark datasets and corresponding evaluation metrics as widely adopted in multimodal image synthesis and editing, as well as detailed comparisons of different synthesis methods with analysis of respective advantages and limitations. Finally, we provide insights into the current research challenges and possible future research directions. A project associated with this survey is available at https://github.com/fnzhan/MISE
GenCo: Generative Co-training on Data-Limited Image Generation
Oct 04, 2021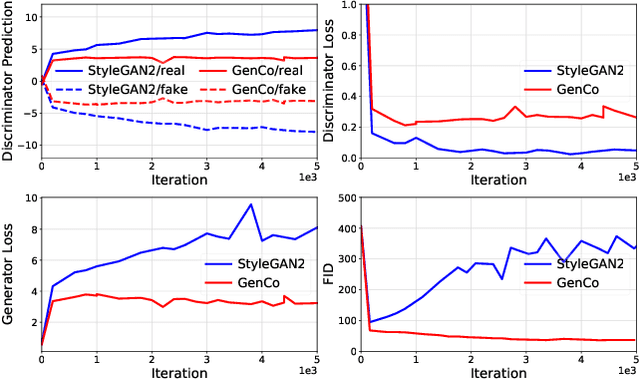
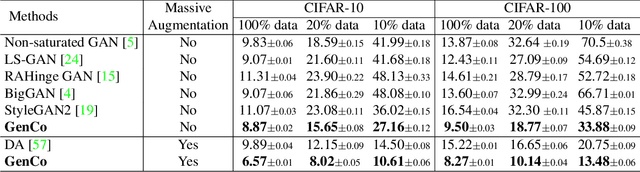
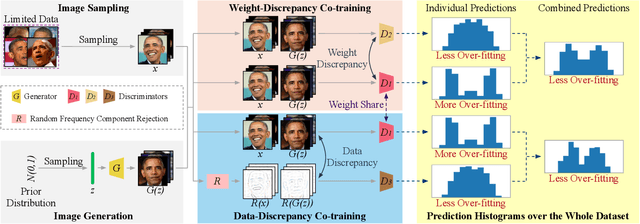
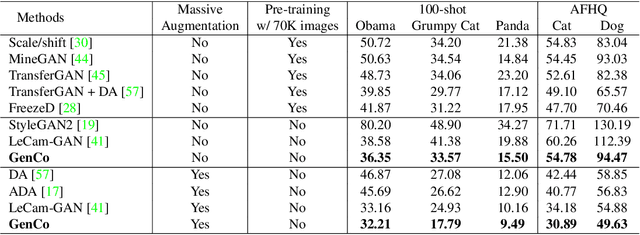
Training effective Generative Adversarial Networks (GANs) requires large amounts of training data, without which the trained models are usually sub-optimal with discriminator over-fitting. Several prior studies address this issue by expanding the distribution of the limited training data via massive and hand-crafted data augmentation. We handle data-limited image generation from a very different perspective. Specifically, we design GenCo, a Generative Co-training network that mitigates the discriminator over-fitting issue by introducing multiple complementary discriminators that provide diverse supervision from multiple distinctive views in training. We instantiate the idea of GenCo in two ways. The first way is Weight-Discrepancy Co-training (WeCo) which co-trains multiple distinctive discriminators by diversifying their parameters. The second way is Data-Discrepancy Co-training (DaCo) which achieves co-training by feeding discriminators with different views of the input images (e.g., different frequency components of the input images). Extensive experiments over multiple benchmarks show that GenCo achieves superior generation with limited training data. In addition, GenCo also complements the augmentation approach with consistent and clear performance gains when combined.
Conditional Directed Graph Convolution for 3D Human Pose Estimation
Aug 04, 2021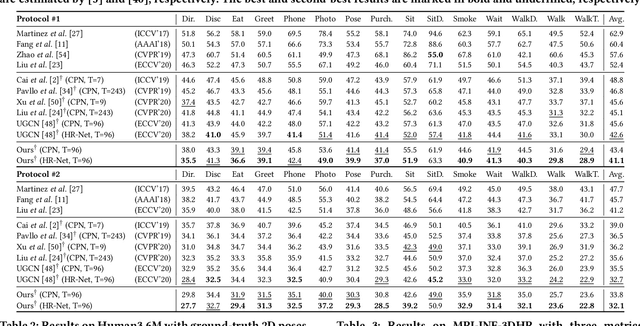
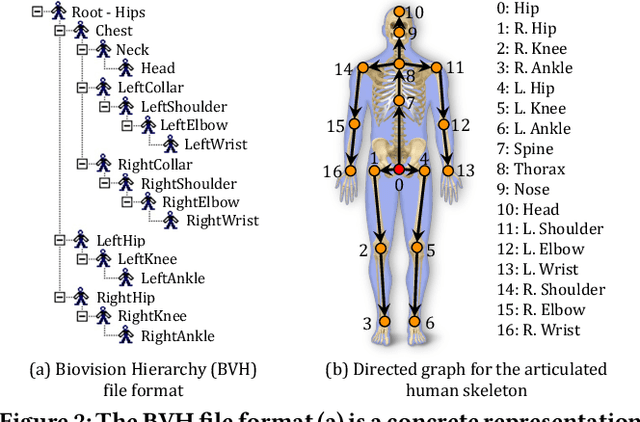
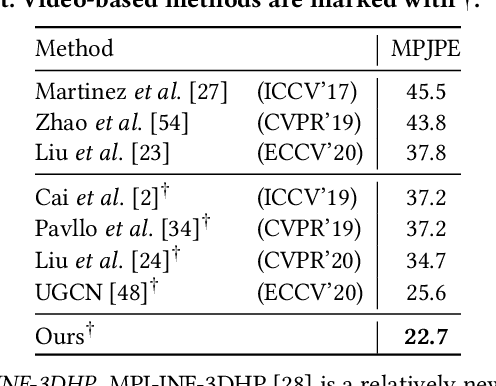

Graph convolutional networks have significantly improved 3D human pose estimation by representing the human skeleton as an undirected graph. However, this representation fails to reflect the articulated characteristic of human skeletons as the hierarchical orders among the joints are not explicitly presented. In this paper, we propose to represent the human skeleton as a directed graph with the joints as nodes and bones as edges that are directed from parent joints to child joints. By so doing, the directions of edges can explicitly reflect the hierarchical relationships among the nodes. Based on this representation, we further propose a spatial-temporal conditional directed graph convolution to leverage varying non-local dependence for different poses by conditioning the graph topology on input poses. Altogether, we form a U-shaped network, named U-shaped Conditional Directed Graph Convolutional Network, for 3D human pose estimation from monocular videos. To evaluate the effectiveness of our method, we conducted extensive experiments on two challenging large-scale benchmarks: Human3.6M and MPI-INF-3DHP. Both quantitative and qualitative results show that our method achieves top performance. Also, ablation studies show that directed graphs can better exploit the hierarchy of articulated human skeletons than undirected graphs, and the conditional connections can yield adaptive graph topologies for different poses.
WaveFill: A Wavelet-based Generation Network for Image Inpainting
Jul 23, 2021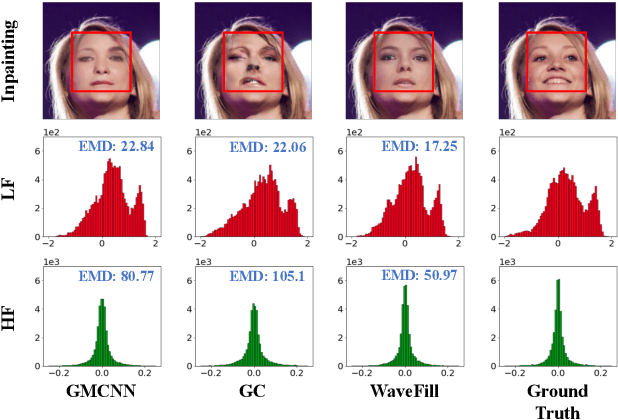
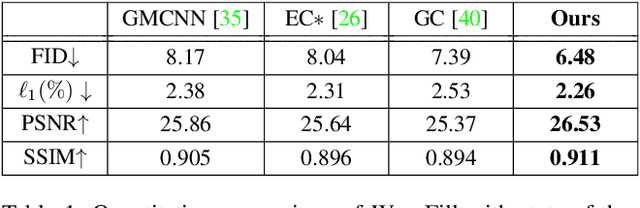
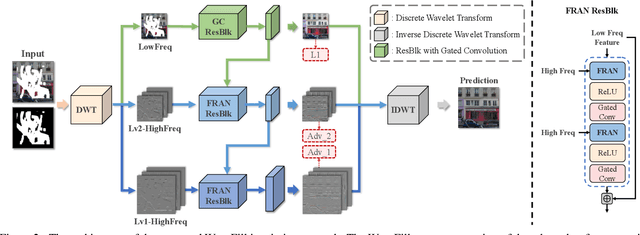
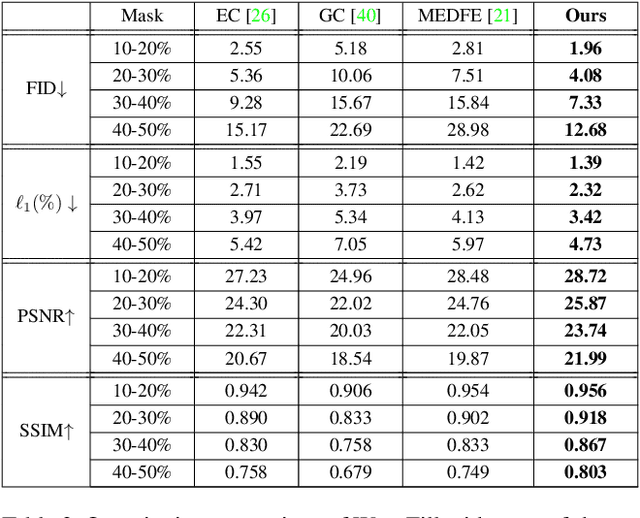
Image inpainting aims to complete the missing or corrupted regions of images with realistic contents. The prevalent approaches adopt a hybrid objective of reconstruction and perceptual quality by using generative adversarial networks. However, the reconstruction loss and adversarial loss focus on synthesizing contents of different frequencies and simply applying them together often leads to inter-frequency conflicts and compromised inpainting. This paper presents WaveFill, a wavelet-based inpainting network that decomposes images into multiple frequency bands and fills the missing regions in each frequency band separately and explicitly. WaveFill decomposes images by using discrete wavelet transform (DWT) that preserves spatial information naturally. It applies L1 reconstruction loss to the decomposed low-frequency bands and adversarial loss to high-frequency bands, hence effectively mitigate inter-frequency conflicts while completing images in spatial domain. To address the inpainting inconsistency in different frequency bands and fuse features with distinct statistics, we design a novel normalization scheme that aligns and fuses the multi-frequency features effectively. Extensive experiments over multiple datasets show that WaveFill achieves superior image inpainting qualitatively and quantitatively.
SynLiDAR: Learning From Synthetic LiDAR Sequential Point Cloud for Semantic Segmentation
Jul 12, 2021
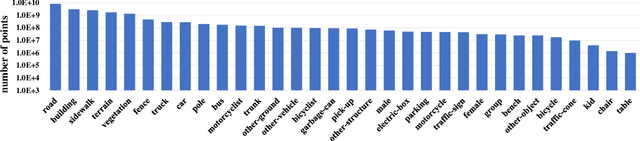
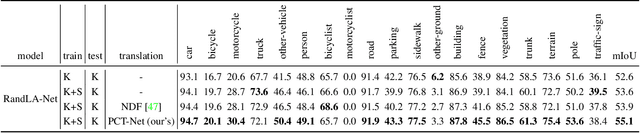
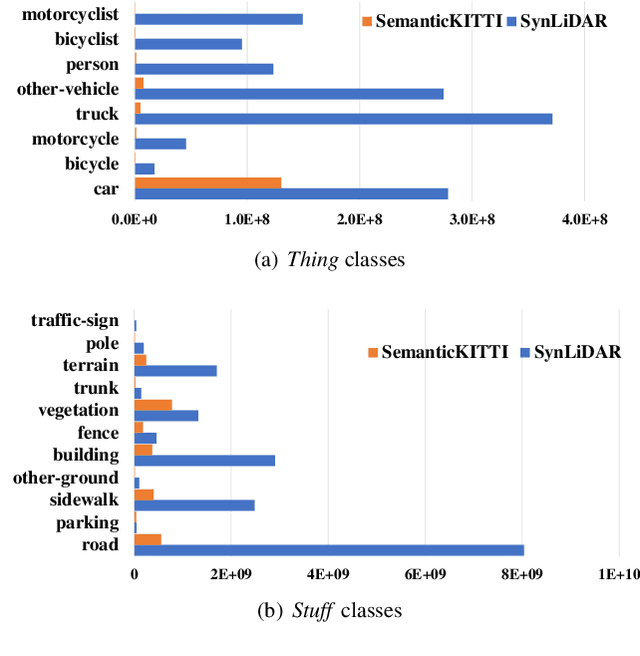
Transfer learning from synthetic to real data has been proved an effective way of mitigating data annotation constraints in various computer vision tasks. However, the developments focused on 2D images but lag far behind for 3D point clouds due to the lack of large-scale high-quality synthetic point cloud data and effective transfer methods. We address this issue by collecting SynLiDAR, a synthetic LiDAR point cloud dataset that contains large-scale point-wise annotated point cloud with accurate geometric shapes and comprehensive semantic classes, and designing PCT-Net, a point cloud translation network that aims to narrow down the gap with real-world point cloud data. For SynLiDAR, we leverage graphic tools and professionals who construct multiple realistic virtual environments with rich scene types and layouts where annotated LiDAR points can be generated automatically. On top of that, PCT-Net disentangles synthetic-to-real gaps into an appearance component and a sparsity component and translates SynLiDAR by aligning the two components with real-world data separately. Extensive experiments over multiple data augmentation and semi-supervised semantic segmentation tasks show very positive outcomes - including SynLiDAR can either train better models or reduce real-world annotated data without sacrificing performance, and PCT-Net translated data further improve model performance consistently.
FBC-GAN: Diverse and Flexible Image Synthesis via Foreground-Background Composition
Jul 07, 2021
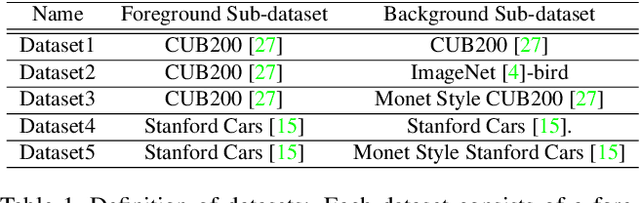
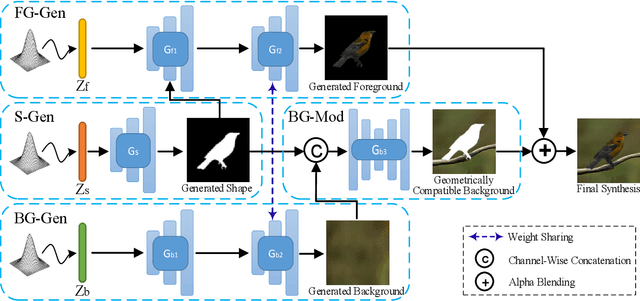
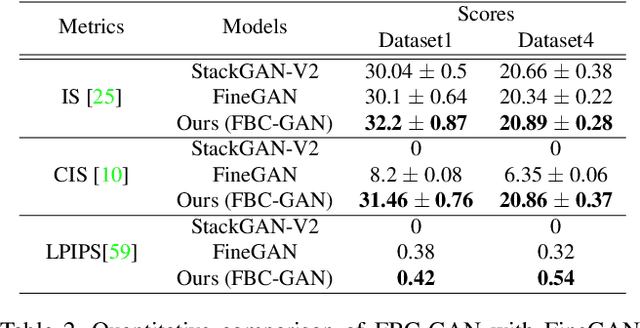
Generative Adversarial Networks (GANs) have become the de-facto standard in image synthesis. However, without considering the foreground-background decomposition, existing GANs tend to capture excessive content correlation between foreground and background, thus constraining the diversity in image generation. This paper presents a novel Foreground-Background Composition GAN (FBC-GAN) that performs image generation by generating foreground objects and background scenes concurrently and independently, followed by composing them with style and geometrical consistency. With this explicit design, FBC-GAN can generate images with foregrounds and backgrounds that are mutually independent in contents, thus lifting the undesirably learned content correlation constraint and achieving superior diversity. It also provides excellent flexibility by allowing the same foreground object with different background scenes, the same background scene with varying foreground objects, or the same foreground object and background scene with different object positions, sizes and poses. It can compose foreground objects and background scenes sampled from different datasets as well. Extensive experiments over multiple datasets show that FBC-GAN achieves competitive visual realism and superior diversity as compared with state-of-the-art methods.