 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Hidden Vulnerabilities in Digital Human Generation via Adversarial Attacks
Apr 24, 2025



Expressive human pose and shape estimation (EHPS) is crucial for digital human generation, especially in applications like live streaming. While existing research primarily focuses on reducing estimation errors, it largely neglects robustness and security aspects, leaving these systems vulnerable to adversarial attacks. To address this significant challenge, we propose the \textbf{Tangible Attack (TBA)}, a novel framework designed to generate adversarial examples capable of effectively compromising any digital human generation model. Our approach introduces a \textbf{Dual Heterogeneous Noise Generator (DHNG)}, which leverages Variational Autoencoders (VAE) and ControlNet to produce diverse, targeted noise tailored to the original image features. Additionally, we design a custom \textbf{adversarial loss function} to optimize the noise, ensuring both high controllability and potent disruption. By iteratively refining the adversarial sample through multi-gradient signals from both the noise and the state-of-the-art EHPS model, TBA substantially improves the effectiveness of adversarial attacks. Extensive experiments demonstrate TBA's superiority, achieving a remarkable 41.0\% increase in estimation error, with an average improvement of approximately 17.0\%. These findings expose significant security vulnerabilities in current EHPS models and highlight the need for stronger defenses in digital human generation systems.
PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
Mar 20, 2025Recent advancements in audio-driven talking face generation have made great progress in lip synchronization. However, current methods often lack sufficient control over facial animation such as speaking style and emotional expression, resulting in uniform outputs. In this paper, we focus on improving two key factors: lip-audio alignment and emotion control, to enhance the diversity and user-friendliness of talking videos. Lip-audio alignment control focuses on elements like speaking style and the scale of lip movements, whereas emotion control is centered on generating realistic emotional expressions, allowing for modifications in multiple attributes such as intensity. To achieve precise control of facial animation, we propose a novel framework, PC-Talk, which enables lip-audio alignment and emotion control through implicit keypoint deformations. First, our lip-audio alignment control module facilitates precise editing of speaking styles at the word level and adjusts lip movement scales to simulate varying vocal loudness levels, maintaining lip synchronization with the audio. Second, our emotion control module generates vivid emotional facial features with pure emotional deformation. This module also enables the fine modification of intensity and the combination of multiple emotions across different facial regions. Our method demonstrates outstanding control capabilities and achieves state-of-the-art performance on both HDTF and MEAD datasets in extensive experiments.
Incentivized Exploration for Multi-Armed Bandits under Reward Drift
Dec 16, 2019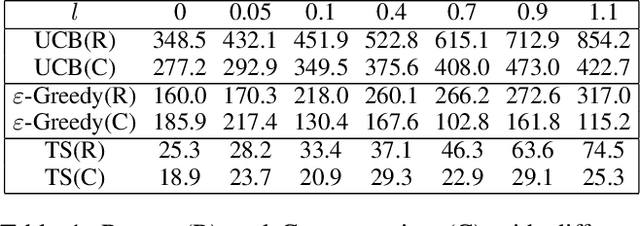
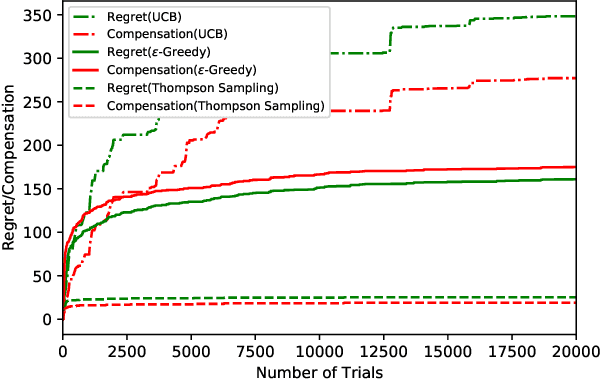
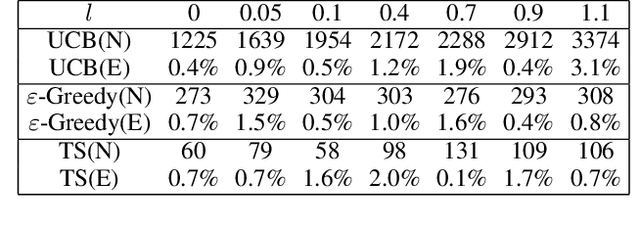
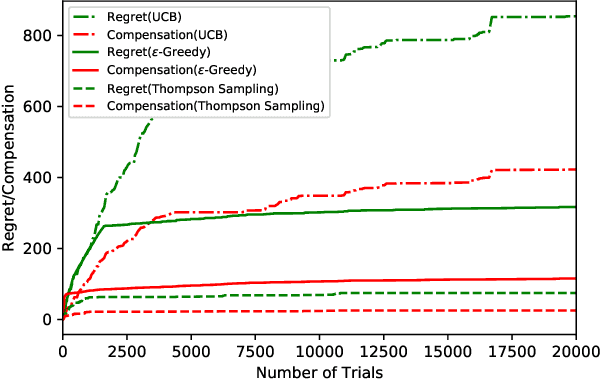
We study incentivized exploration for the multi-armed bandit (MAB) problem where the players receive compensation for exploring arms other than the greedy choice and may provide biased feedback on reward. We seek to understand the impact of this drifted reward feedback by analyzing the performance of three instantiations of the incentivized MAB algorithm: UCB, $\varepsilon$-Greedy, and Thompson Sampling. Our results show that they all achieve $\mathcal{O}(\log T)$ regret and compensation under the drifted reward, and are therefore effective in incentivizing exploration. Numerical examples are provided to complement the theoretical analysis.