 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks and Adversarial Autoencoders: Tutorial and Survey
Nov 26, 2021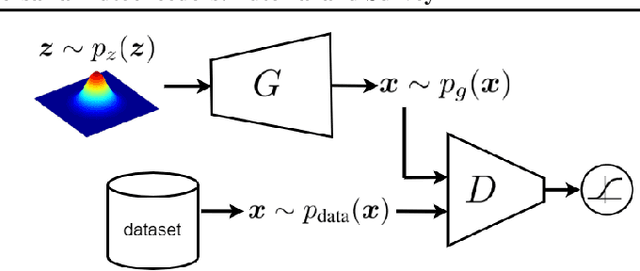


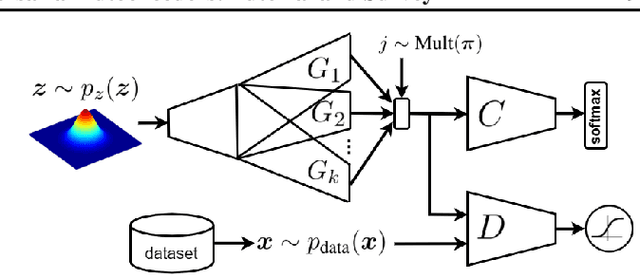
This is a tutorial and survey paper on Generative Adversarial Network (GAN), adversarial autoencoders, and their variants. We start with explaining adversarial learning and the vanilla GAN. Then, we explain the conditional GAN and DCGAN. The mode collapse problem is introduced and various methods, including minibatch GAN, unrolled GAN, BourGAN, mixture GAN, D2GAN, and Wasserstein GAN, are introduced for resolving this problem. Then, maximum likelihood estimation in GAN are explained along with f-GAN, adversarial variational Bayes, and Bayesian GAN. Then, we cover feature matching in GAN, InfoGAN, GRAN, LSGAN, energy-based GAN, CatGAN, MMD GAN, LapGAN, progressive GAN, triple GAN, LAG, GMAN, AdaGAN, CoGAN, inverse GAN, BiGAN, ALI, SAGAN, Few-shot GAN, SinGAN, and interpolation and evaluation of GAN. Then, we introduce some applications of GAN such as image-to-image translation (including PatchGAN, CycleGAN, DeepFaceDrawing, simulated GAN, interactive GAN), text-to-image translation (including StackGAN), and mixing image characteristics (including FineGAN and MixNMatch). Finally, we explain the autoencoders based on adversarial learning including adversarial autoencoder, PixelGAN, and implicit autoencoder.
Sufficient Dimension Reduction for High-Dimensional Regression and Low-Dimensional Embedding: Tutorial and Survey
Oct 18, 2021This is a tutorial and survey paper on various methods for Sufficient Dimension Reduction (SDR). We cover these methods with both statistical high-dimensional regression perspective and machine learning approach for dimensionality reduction. We start with introducing inverse regression methods including Sliced Inverse Regression (SIR), Sliced Average Variance Estimation (SAVE), contour regression, directional regression, Principal Fitted Components (PFC), Likelihood Acquired Direction (LAD), and graphical regression. Then, we introduce forward regression methods including Principal Hessian Directions (pHd), Minimum Average Variance Estimation (MAVE), Conditional Variance Estimation (CVE), and deep SDR methods. Finally, we explain Kernel Dimension Reduction (KDR) both for supervised and unsupervised learning. We also show that supervised KDR and supervised PCA are equivalent.
KKT Conditions, First-Order and Second-Order Optimization, and Distributed Optimization: Tutorial and Survey
Oct 05, 2021
This is a tutorial and survey paper on Karush-Kuhn-Tucker (KKT) conditions, first-order and second-order numerical optimization, and distributed optimization. After a brief review of history of optimization, we start with some preliminaries on properties of sets, norms, functions, and concepts of optimization. Then, we introduce the optimization problem, standard optimization problems (including linear programming, quadratic programming, and semidefinite programming), and convex problems. We also introduce some techniques such as eliminating inequality, equality, and set constraints, adding slack variables, and epigraph form. We introduce Lagrangian function, dual variables, KKT conditions (including primal feasibility, dual feasibility, weak and strong duality, complementary slackness, and stationarity condition), and solving optimization by method of Lagrange multipliers. Then, we cover first-order optimization including gradient descent, line-search, convergence of gradient methods, momentum, steepest descent, and backpropagation. Other first-order methods are explained, such as accelerated gradient method, stochastic gradient descent, mini-batch gradient descent, stochastic average gradient, stochastic variance reduced gradient, AdaGrad, RMSProp, and Adam optimizer, proximal methods (including proximal mapping, proximal point algorithm, and proximal gradient method), and constrained gradient methods (including projected gradient method, projection onto convex sets, and Frank-Wolfe method). We also cover non-smooth and $\ell_1$ optimization methods including lasso regularization, convex conjugate, Huber function, soft-thresholding, coordinate descent, and subgradient methods. Then, we explain second-order methods including Newton's method for unconstrained, equality constrained, and inequality constrained problems....
Vector Transport Free Riemannian LBFGS for Optimization on Symmetric Positive Definite Matrix Manifolds
Aug 25, 2021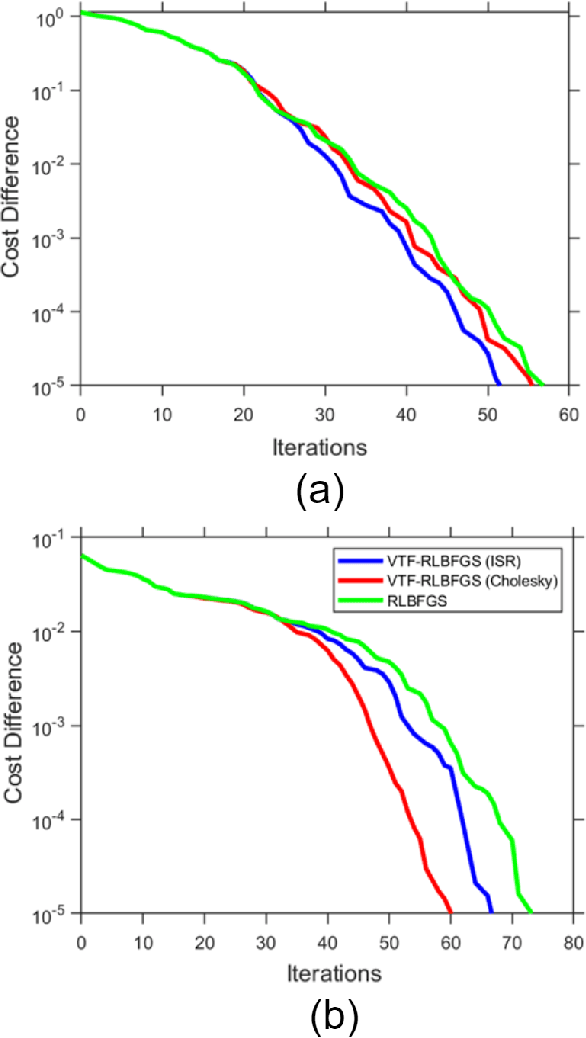
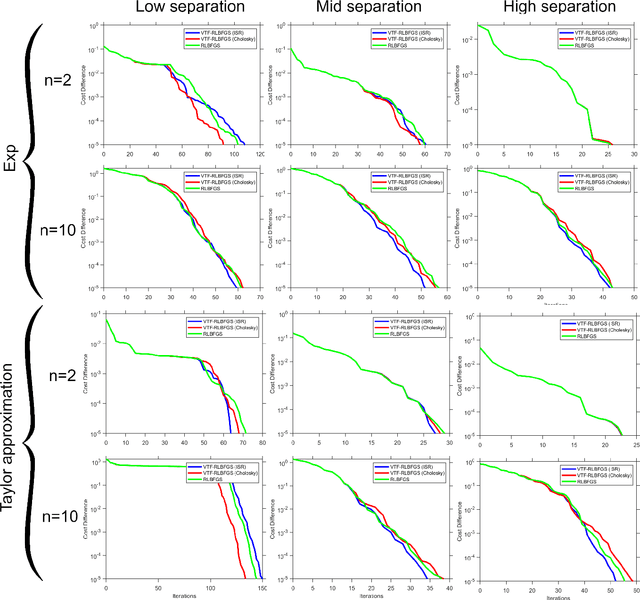
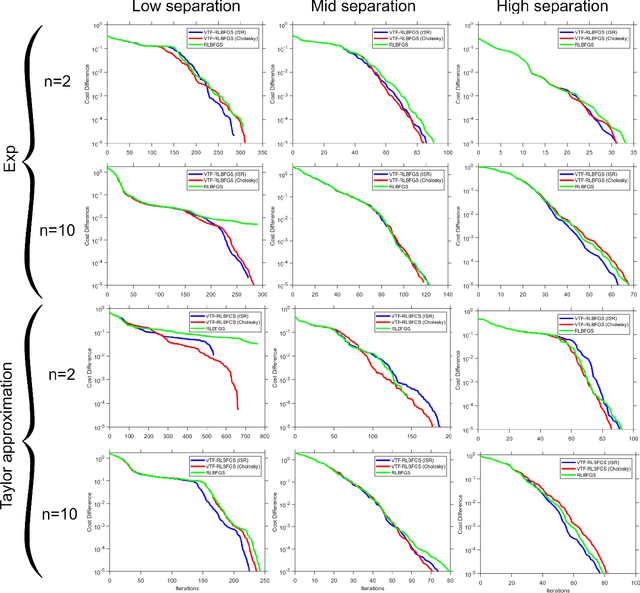
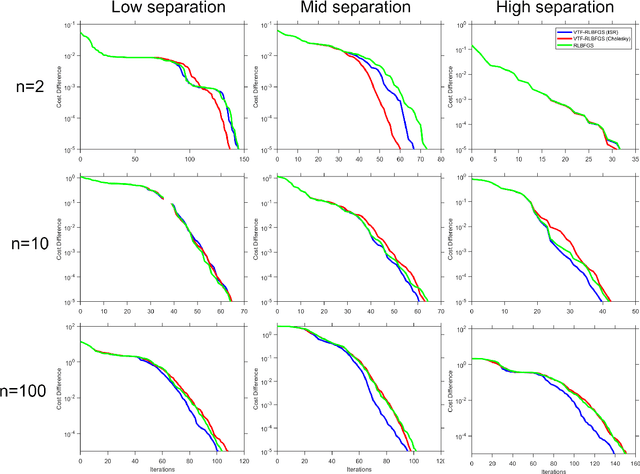
This work concentrates on optimization on Riemannian manifolds. The Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) algorithm is a commonly used quasi-Newton method for numerical optimization in Euclidean spaces. Riemannian LBFGS (RLBFGS) is an extension of this method to Riemannian manifolds. RLBFGS involves computationally expensive vector transports as well as unfolding recursions using adjoint vector transports. In this article, we propose two mappings in the tangent space using the inverse second root and Cholesky decomposition. These mappings make both vector transport and adjoint vector transport identity and therefore isometric. Identity vector transport makes RLBFGS less computationally expensive and its isometry is also very useful in convergence analysis of RLBFGS. Moreover, under the proposed mappings, the Riemannian metric reduces to Euclidean inner product, which is much less computationally expensive. We focus on the Symmetric Positive Definite (SPD) manifolds which are beneficial in various fields such as data science and statistics. This work opens a research opportunity for extension of the proposed mappings to other well-known manifolds.
Uniform Manifold Approximation and Projection (UMAP) and its Variants: Tutorial and Survey
Aug 25, 2021Uniform Manifold Approximation and Projection (UMAP) is one of the state-of-the-art methods for dimensionality reduction and data visualization. This is a tutorial and survey paper on UMAP and its variants. We start with UMAP algorithm where we explain probabilities of neighborhood in the input and embedding spaces, optimization of cost function, training algorithm, derivation of gradients, and supervised and semi-supervised embedding by UMAP. Then, we introduce the theory behind UMAP by algebraic topology and category theory. Then, we introduce UMAP as a neighbor embedding method and compare it with t-SNE and LargeVis algorithms. We discuss negative sampling and repulsive forces in UMAP's cost function. DensMAP is then explained for density-preserving embedding. We then introduce parametric UMAP for embedding by deep learning and progressive UMAP for streaming and out-of-sample data embedding.
Johnson-Lindenstrauss Lemma, Linear and Nonlinear Random Projections, Random Fourier Features, and Random Kitchen Sinks: Tutorial and Survey
Aug 09, 2021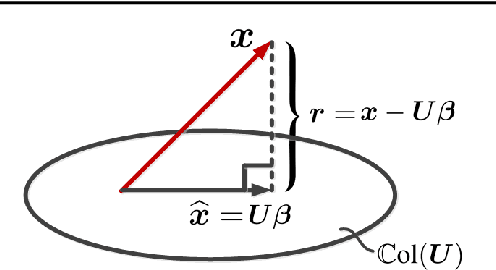
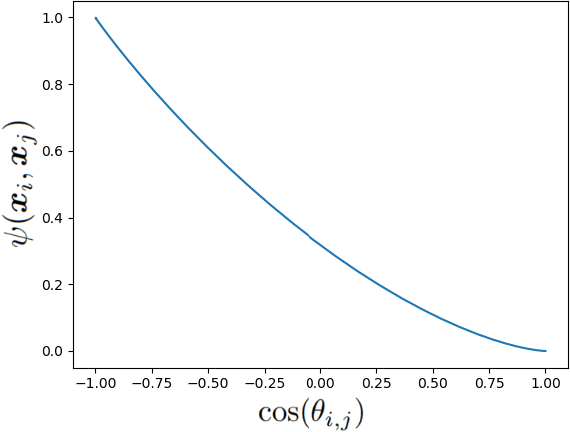
This is a tutorial and survey paper on the Johnson-Lindenstrauss (JL) lemma and linear and nonlinear random projections. We start with linear random projection and then justify its correctness by JL lemma and its proof. Then, sparse random projections with $\ell_1$ norm and interpolation norm are introduced. Two main applications of random projection, which are low-rank matrix approximation and approximate nearest neighbor search by random projection onto hypercube, are explained. Random Fourier Features (RFF) and Random Kitchen Sinks (RKS) are explained as methods for nonlinear random projection. Some other methods for nonlinear random projection, including extreme learning machine, randomly weighted neural networks, and ensemble of random projections, are also introduced.
Restricted Boltzmann Machine and Deep Belief Network: Tutorial and Survey
Jul 26, 2021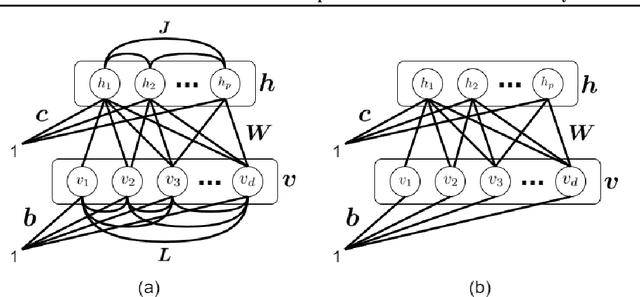
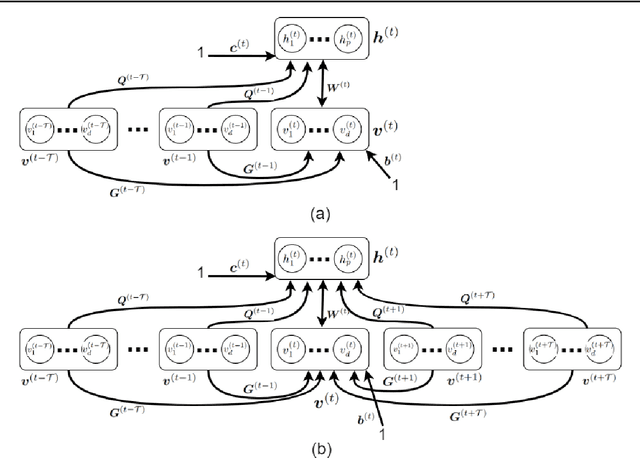
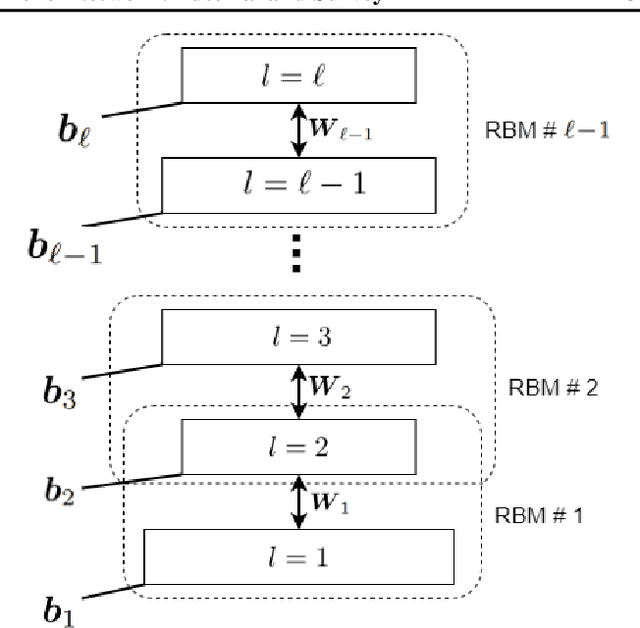
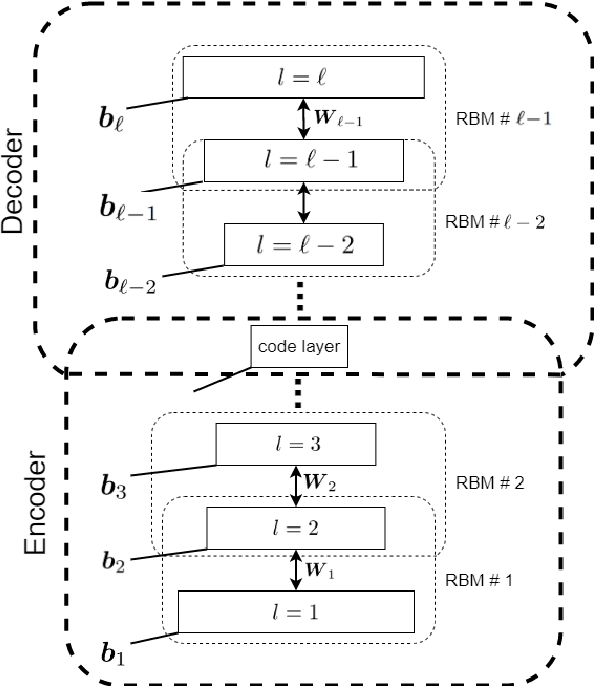
This is a tutorial and survey paper on Boltzmann Machine (BM), Restricted Boltzmann Machine (RBM), and Deep Belief Network (DBN). We start with the required background on probabilistic graphical models, Markov random field, Gibbs sampling, statistical physics, Ising model, and the Hopfield network. Then, we introduce the structures of BM and RBM. The conditional distributions of visible and hidden variables, Gibbs sampling in RBM for generating variables, training BM and RBM by maximum likelihood estimation, and contrastive divergence are explained. Then, we discuss different possible discrete and continuous distributions for the variables. We introduce conditional RBM and how it is trained. Finally, we explain deep belief network as a stack of RBM models. This paper on Boltzmann machines can be useful in various fields including data science, statistics, neural computation, and statistical physics.
Unified Framework for Spectral Dimensionality Reduction, Maximum Variance Unfolding, and Kernel Learning By Semidefinite Programming: Tutorial and Survey
Jun 29, 2021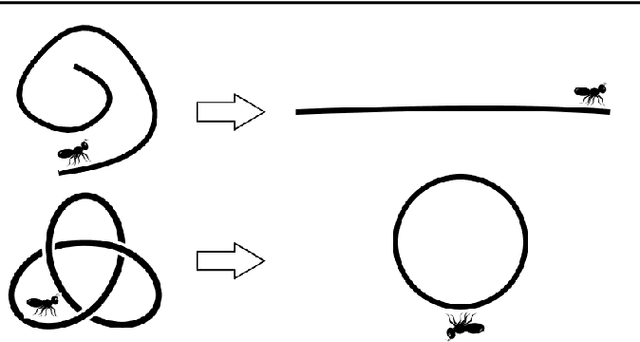
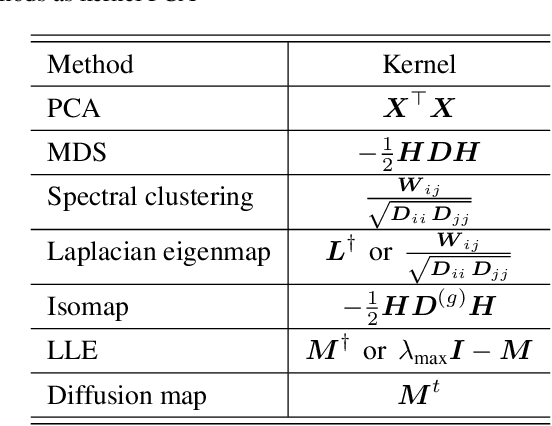

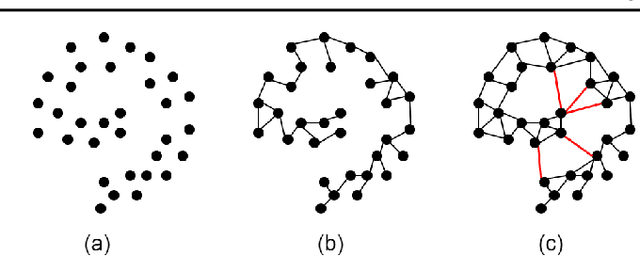
This is a tutorial and survey paper on unification of spectral dimensionality reduction methods, kernel learning by Semidefinite Programming (SDP), Maximum Variance Unfolding (MVU) or Semidefinite Embedding (SDE), and its variants. We first explain how the spectral dimensionality reduction methods can be unified as kernel Principal Component Analysis (PCA) with different kernels. This unification can be interpreted as eigenfunction learning or representation of kernel in terms of distance matrix. Then, since the spectral methods are unified as kernel PCA, we say let us learn the best kernel for unfolding the manifold of data to its maximum variance. We first briefly introduce kernel learning by SDP for the transduction task. Then, we explain MVU in detail. Various versions of supervised MVU using nearest neighbors graph, by class-wise unfolding, by Fisher criterion, and by colored MVU are explained. We also explain out-of-sample extension of MVU using eigenfunctions and kernel mapping. Finally, we introduce other variants of MVU including action respecting embedding, relaxed MVU, and landmark MVU for big data.
Smart Healthcare in the Age of AI: Recent Advances, Challenges, and Future Prospects
Jun 24, 2021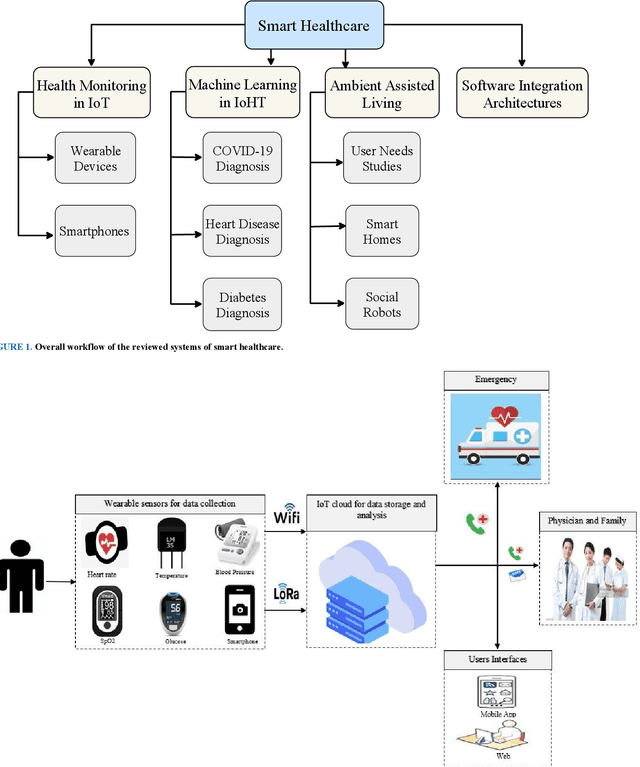
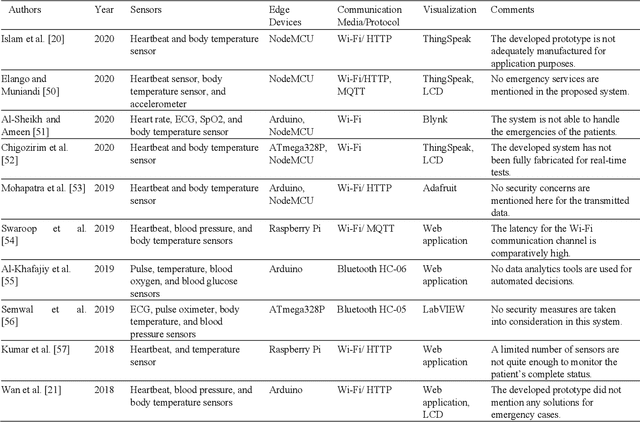
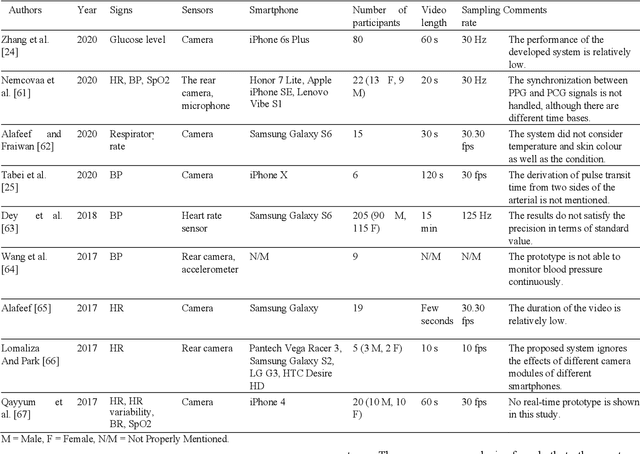
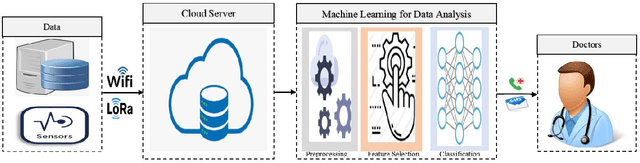
The significant increase in the number of individuals with chronic ailments (including the elderly and disabled) has dictated an urgent need for an innovative model for healthcare systems. The evolved model will be more personalized and less reliant on traditional brick-and-mortar healthcare institutions such as hospitals, nursing homes, and long-term healthcare centers. The smart healthcare system is a topic of recently growing interest and has become increasingly required due to major developments in modern technologies, especially in artificial intelligence (AI) and machine learning (ML). This paper is aimed to discuss the current state-of-the-art smart healthcare systems highlighting major areas like wearable and smartphone devices for health monitoring, machine learning for disease diagnosis, and the assistive frameworks, including social robots developed for the ambient assisted living environment. Additionally, the paper demonstrates software integration architectures that are very significant to create smart healthcare systems, integrating seamlessly the benefit of data analytics and other tools of AI. The explained developed systems focus on several facets: the contribution of each developed framework, the detailed working procedure, the performance as outcomes, and the comparative merits and limitations. The current research challenges with potential future directions are addressed to highlight the drawbacks of existing systems and the possible methods to introduce novel frameworks, respectively. This review aims at providing comprehensive insights into the recent developments of smart healthcare systems to equip experts to contribute to the field.
Reproducing Kernel Hilbert Space, Mercer's Theorem, Eigenfunctions, Nyström Method, and Use of Kernels in Machine Learning: Tutorial and Survey
Jun 15, 2021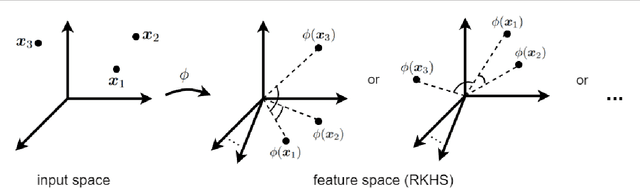
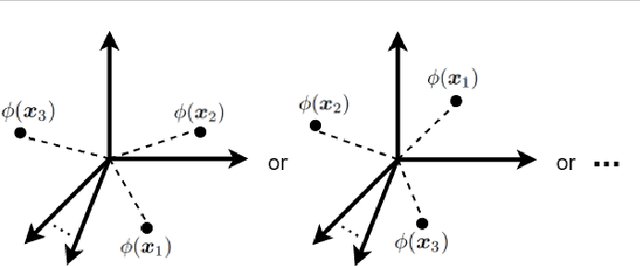
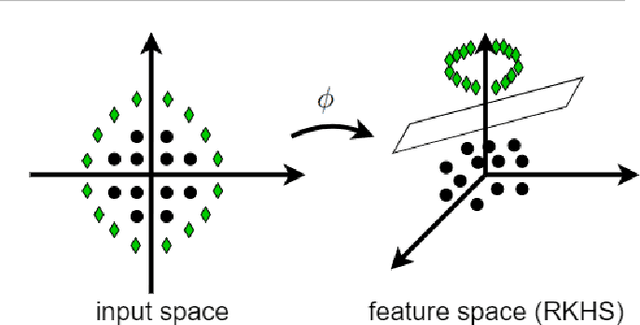
This is a tutorial and survey paper on kernels, kernel methods, and related fields. We start with reviewing the history of kernels in functional analysis and machine learning. Then, Mercer kernel, Hilbert and Banach spaces, Reproducing Kernel Hilbert Space (RKHS), Mercer's theorem and its proof, frequently used kernels, kernel construction from distance metric, important classes of kernels (including bounded, integrally positive definite, universal, stationary, and characteristic kernels), kernel centering and normalization, and eigenfunctions are explained in detail. Then, we introduce types of use of kernels in machine learning including kernel methods (such as kernel support vector machines), kernel learning by semi-definite programming, Hilbert-Schmidt independence criterion, maximum mean discrepancy, kernel mean embedding, and kernel dimensionality reduction. We also cover rank and factorization of kernel matrix as well as the approximation of eigenfunctions and kernels using the Nystr{\"o}m method. This paper can be useful for various fields of science including machine learning, dimensionality reduction, functional analysis in mathematics, and mathematical physics in quantum mechanics.