 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relation of State Space Models and Hidden Markov Models
Jan 19, 2026State Space Models (SSMs) and Hidden Markov Models (HMMs) are foundational frameworks for modeling sequential data with latent variables and are widely used in signal processing, control theory, and machine learning. Despite their shared temporal structure, they differ fundamentally in the nature of their latent states, probabilistic assumptions, inference procedures, and training paradigms. Recently, deterministic state space models have re-emerged in natural language processing through architectures such as S4 and Mamba, raising new questions about the relationship between classical probabilistic SSMs, HMMs, and modern neural sequence models. In this paper, we present a unified and systematic comparison of HMMs, linear Gaussian state space models, Kalman filtering, and contemporary NLP state space models. We analyze their formulations through the lens of probabilistic graphical models, examine their inference algorithms -- including forward-backward inference and Kalman filtering -- and contrast their learning procedures via Expectation-Maximization and gradient-based optimization. By highlighting both structural similarities and semantic differences, we clarify when these models are equivalent, when they fundamentally diverge, and how modern NLP SSMs relate to classical probabilistic models. Our analysis bridges perspectives from control theory, probabilistic modeling, and modern deep learning.
Sampling Algorithms, from Survey Sampling to Monte Carlo Methods: Tutorial and Literature Review
Nov 02, 2020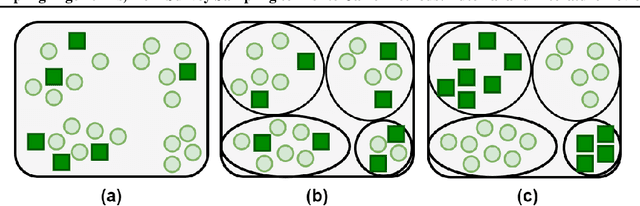
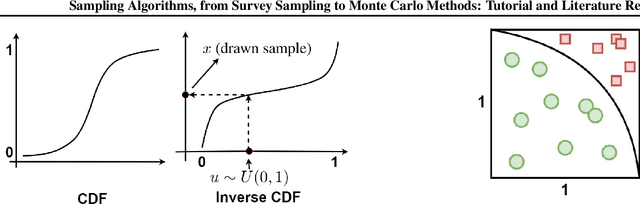
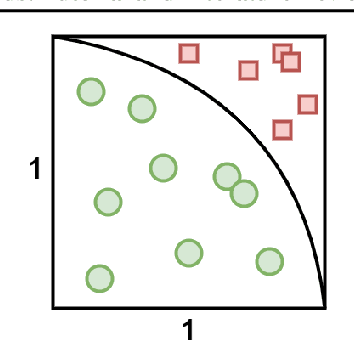
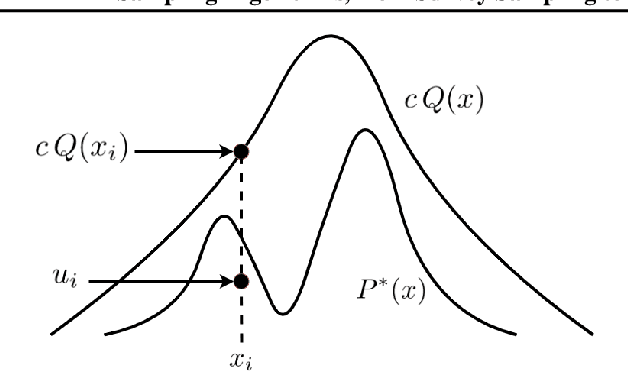
This paper is a tutorial and literature review on sampling algorithms. We have two main types of sampling in statistics. The first type is survey sampling which draws samples from a set or population. The second type is sampling from probability distribution where we have a probability density or mass function. In this paper, we cover both types of sampling. First, we review some required background on mean squared error, variance, bias, maximum likelihood estimation, Bernoulli, Binomial, and Hypergeometric distributions, the Horvitz-Thompson estimator, and the Markov property. Then, we explain the theory of simple random sampling, bootstrapping, stratified sampling, and cluster sampling. We also briefly introduce multistage sampling, network sampling, and snowball sampling. Afterwards, we switch to sampling from distribution. We explain sampling from cumulative distribution function, Monte Carlo approximation, simple Monte Carlo methods, and Markov Chain Monte Carlo (MCMC) methods. For simple Monte Carlo methods, whose iterations are independent, we cover importance sampling and rejection sampling. For MCMC methods, we cover Metropolis algorithm, Metropolis-Hastings algorithm, Gibbs sampling, and slice sampling. Then, we explain the random walk behaviour of Monte Carlo methods and more efficient Monte Carlo methods, including Hamiltonian (or hybrid) Monte Carlo, Adler's overrelaxation, and ordered overrelaxation. Finally, we summarize the characteristics, pros, and cons of sampling methods compared to each other. This paper can be useful for different fields of statistics, machine learning, reinforcement learning, and computational physics.
Fitting A Mixture Distribution to Data: Tutorial
Jan 20, 2019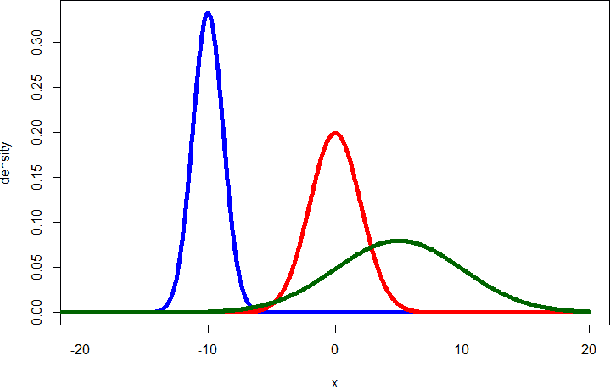
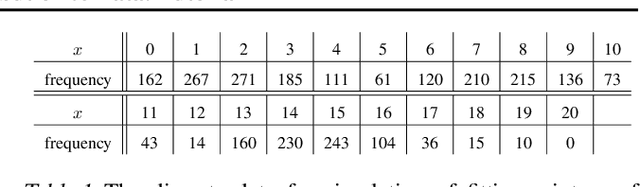
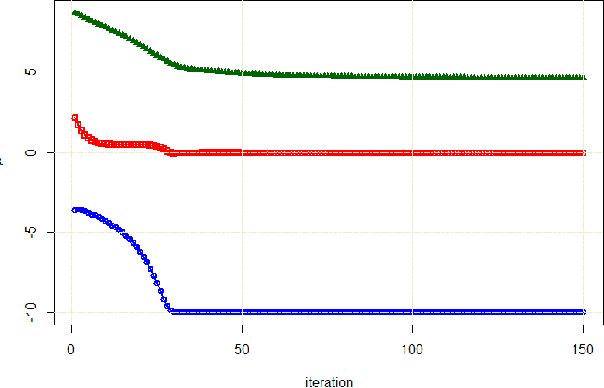
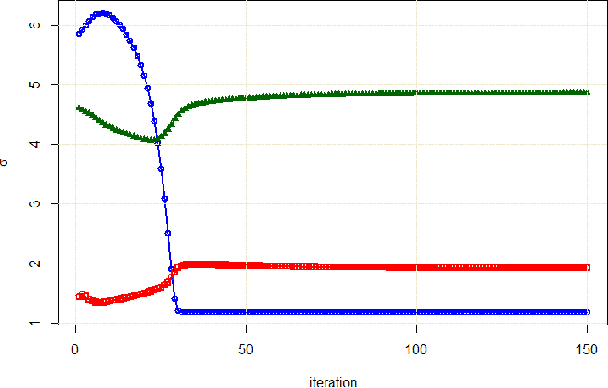
This paper is a step-by-step tutorial for fitting a mixture distribution to data. It merely assumes the reader has the background of calculus and linear algebra. Other required background is briefly reviewed before explaining the main algorithm. In explaining the main algorithm, first, fitting a mixture of two distributions is detailed and examples of fitting two Gaussians and Poissons, respectively for continuous and discrete cases, are introduced. Thereafter, fitting several distributions in general case is explained and examples of several Gaussians (Gaussian Mixture Model) and Poissons are again provided. Model-based clustering, as one of the applications of mixture distributions, is also introduced. Numerical simulations are also provided for both Gaussian and Poisson examples for the sake of better clarification.