 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025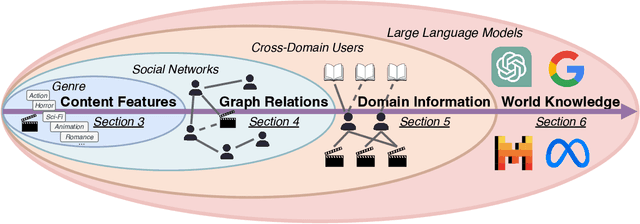
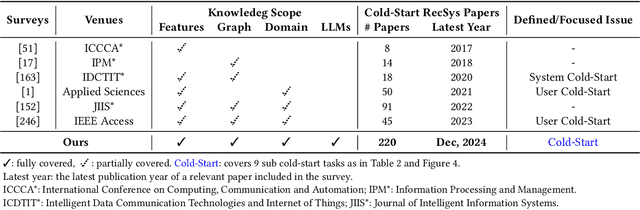
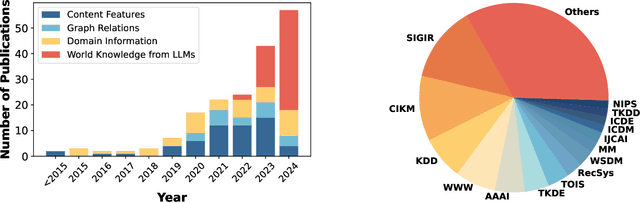
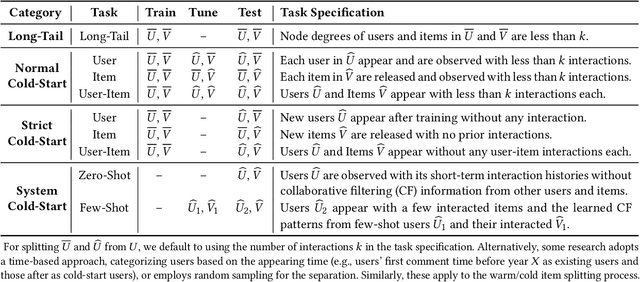
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
Urban4D: Semantic-Guided 4D Gaussian Splatting for Urban Scene Reconstruction
Dec 04, 2024



Reconstructing dynamic urban scenes presents significant challenges due to their intrinsic geometric structures and spatiotemporal dynamics. Existing methods that attempt to model dynamic urban scenes without leveraging priors on potentially moving regions often produce suboptimal results. Meanwhile, approaches based on manual 3D annotations yield improved reconstruction quality but are impractical due to labor-intensive labeling. In this paper, we revisit the potential of 2D semantic maps for classifying dynamic and static Gaussians and integrating spatial and temporal dimensions for urban scene representation. We introduce Urban4D, a novel framework that employs a semantic-guided decomposition strategy inspired by advances in deep 2D semantic map generation. Our approach distinguishes potentially dynamic objects through reliable semantic Gaussians. To explicitly model dynamic objects, we propose an intuitive and effective 4D Gaussian splatting (4DGS) representation that aggregates temporal information through learnable time embeddings for each Gaussian, predicting their deformations at desired timestamps using a multilayer perceptron (MLP). For more accurate static reconstruction, we also design a k-nearest neighbor (KNN)-based consistency regularization to handle the ground surface due to its low-texture characteristic. Extensive experiments on real-world datasets demonstrate that Urban4D not only achieves comparable or better quality than previous state-of-the-art methods but also effectively captures dynamic objects while maintaining high visual fidelity for static elements.
Enhance Hyperbolic Representation Learning via Second-order Pooling
Oct 29, 2024



Hyperbolic representation learning is well known for its ability to capture hierarchical information. However, the distance between samples from different levels of hierarchical classes can be required large. We reveal that the hyperbolic discriminant objective forces the backbone to capture this hierarchical information, which may inevitably increase the Lipschitz constant of the backbone. This can hinder the full utilization of the backbone's generalization ability. To address this issue, we introduce second-order pooling into hyperbolic representation learning, as it naturally increases the distance between samples without compromising the generalization ability of the input features. In this way, the Lipschitz constant of the backbone does not necessarily need to be large. However, current off-the-shelf low-dimensional bilinear pooling methods cannot be directly employed in hyperbolic representation learning because they inevitably reduce the distance expansion capability. To solve this problem, we propose a kernel approximation regularization, which enables the low-dimensional bilinear features to approximate the kernel function well in low-dimensional space. Finally, we conduct extensive experiments on graph-structured datasets to demonstrate the effectiveness of the proposed method.
Advances in Preference-based Reinforcement Learning: A Review
Aug 21, 2024
Reinforcement Learning (RL) algorithms suffer from the dependency on accurately engineered reward functions to properly guide the learning agents to do the required tasks. Preference-based reinforcement learning (PbRL) addresses that by utilizing human preferences as feedback from the experts instead of numeric rewards. Due to its promising advantage over traditional RL, PbRL has gained more focus in recent years with many significant advances. In this survey, we present a unified PbRL framework to include the newly emerging approaches that improve the scalability and efficiency of PbRL. In addition, we give a detailed overview of the theoretical guarantees and benchmarking work done in the field, while presenting its recent applications in complex real-world tasks. Lastly, we go over the limitations of the current approaches and the proposed future research directions.
Reference-free Hallucination Detection for Large Vision-Language Models
Aug 11, 2024



Large vision-language models (LVLMs) have made significant progress in recent years. While LVLMs exhibit excellent ability in language understanding, question answering, and conversations of visual inputs, they are prone to producing hallucinations. While several methods are proposed to evaluate the hallucinations in LVLMs, most are reference-based and depend on external tools, which complicates their practical application. To assess the viability of alternative methods, it is critical to understand whether the reference-free approaches, which do not rely on any external tools, can efficiently detect hallucinations. Therefore, we initiate an exploratory study to demonstrate the effectiveness of different reference-free solutions in detecting hallucinations in LVLMs. In particular, we conduct an extensive study on three kinds of techniques: uncertainty-based, consistency-based, and supervised uncertainty quantification methods on four representative LVLMs across two different tasks. The empirical results show that the reference-free approaches are capable of effectively detecting non-factual responses in LVLMs, with the supervised uncertainty quantification method outperforming the others, achieving the best performance across different settings.
CosmoCLIP: Generalizing Large Vision-Language Models for Astronomical Imaging
Jul 10, 2024



Existing vision-text contrastive learning models enhance representation transferability and support zero-shot prediction by matching paired image and caption embeddings while pushing unrelated pairs apart. However, astronomical image-label datasets are significantly smaller compared to general image and label datasets available from the internet. We introduce CosmoCLIP, an astronomical image-text contrastive learning framework precisely fine-tuned on the pre-trained CLIP model using SpaceNet and BLIP-based captions. SpaceNet, attained via FLARE, constitutes ~13k optimally distributed images, while BLIP acts as a rich knowledge extractor. The rich semantics derived from this SpaceNet and BLIP descriptions, when learned contrastively, enable CosmoCLIP to achieve superior generalization across various in-domain and out-of-domain tasks. Our results demonstrate that CosmoCLIP is a straightforward yet powerful framework, significantly outperforming CLIP in zero-shot classification and image-text retrieval tasks.
AstroSpy: On detecting Fake Images in Astronomy via Joint Image-Spectral Representations
Jul 09, 2024



The prevalence of AI-generated imagery has raised concerns about the authenticity of astronomical images, especially with advanced text-to-image models like Stable Diffusion producing highly realistic synthetic samples. Existing detection methods, primarily based on convolutional neural networks (CNNs) or spectral analysis, have limitations when used independently. We present AstroSpy, a hybrid model that integrates both spectral and image features to distinguish real from synthetic astronomical images. Trained on a unique dataset of real NASA images and AI-generated fakes (approximately 18k samples), AstroSpy utilizes a dual-pathway architecture to fuse spatial and spectral information. This approach enables AstroSpy to achieve superior performance in identifying authentic astronomical images. Extensive evaluations demonstrate AstroSpy's effectiveness and robustness, significantly outperforming baseline models in both in-domain and cross-domain tasks, highlighting its potential to combat misinformation in astronomy.
FLARE up your data: Diffusion-based Augmentation Method in Astronomical Imaging
May 22, 2024The intersection of Astronomy and AI encounters significant challenges related to issues such as noisy backgrounds, lower resolution (LR), and the intricate process of filtering and archiving images from advanced telescopes like the James Webb. Given the dispersion of raw images in feature space, we have proposed a \textit{two-stage augmentation framework} entitled as \textbf{FLARE} based on \underline{f}eature \underline{l}earning and \underline{a}ugmented \underline{r}esolution \underline{e}nhancement. We first apply lower (LR) to higher resolution (HR) conversion followed by standard augmentations. Secondly, we integrate a diffusion approach to synthetically generate samples using class-concatenated prompts. By merging these two stages using weighted percentiles, we realign the feature space distribution, enabling a classification model to establish a distinct decision boundary and achieve superior generalization on various in-domain and out-of-domain tasks. We conducted experiments on several downstream cosmos datasets and on our optimally distributed \textbf{SpaceNet} dataset across 8-class fine-grained and 4-class macro classification tasks. FLARE attains the highest performance gain of 20.78\% for fine-grained tasks compared to similar baselines, while across different classification models, FLARE shows a consistent increment of an average of +15\%. This outcome underscores the effectiveness of the FLARE method in enhancing the precision of image classification, ultimately bolstering the reliability of astronomical research outcomes. % Our code and SpaceNet dataset will be released to the public soon. Our code and SpaceNet dataset is available at \href{https://github.com/Razaimam45/PlanetX_Dxb}{\textit{https://github.com/Razaimam45/PlanetX\_Dxb}}.
GenLayNeRF: Generalizable Layered Representations with 3D Model Alignment for Multi-Human View Synthesis
Sep 20, 2023



Novel view synthesis (NVS) of multi-human scenes imposes challenges due to the complex inter-human occlusions. Layered representations handle the complexities by dividing the scene into multi-layered radiance fields, however, they are mainly constrained to per-scene optimization making them inefficient. Generalizable human view synthesis methods combine the pre-fitted 3D human meshes with image features to reach generalization, yet they are mainly designed to operate on single-human scenes. Another drawback is the reliance on multi-step optimization techniques for parametric pre-fitting of the 3D body models that suffer from misalignment with the images in sparse view settings causing hallucinations in synthesized views. In this work, we propose, GenLayNeRF, a generalizable layered scene representation for free-viewpoint rendering of multiple human subjects which requires no per-scene optimization and very sparse views as input. We divide the scene into multi-human layers anchored by the 3D body meshes. We then ensure pixel-level alignment of the body models with the input views through a novel end-to-end trainable module that carries out iterative parametric correction coupled with multi-view feature fusion to produce aligned 3D models. For NVS, we extract point-wise image-aligned and human-anchored features which are correlated and fused using self-attention and cross-attention modules. We augment low-level RGB values into the features with an attention-based RGB fusion module. To evaluate our approach, we construct two multi-human view synthesis datasets; DeepMultiSyn and ZJU-MultiHuman. The results indicate that our proposed approach outperforms generalizable and non-human per-scene NeRF methods while performing at par with layered per-scene methods without test time optimization.