 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025



Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
TEn-CATS: Text-Enriched Audio-Visual Video Parsing with Multi-Scale Category-Aware Temporal Graph
Sep 04, 2025Audio-Visual Video Parsing (AVVP) task aims to identify event categories and their occurrence times in a given video with weakly supervised labels. Existing methods typically fall into two categories: (i) designing enhanced architectures based on attention mechanism for better temporal modeling, and (ii) generating richer pseudo-labels to compensate for the absence of frame-level annotations. However, the first type methods treat noisy segment-level pseudo labels as reliable supervision and the second type methods let indiscriminate attention spread them across all frames, the initial errors are repeatedly amplified during training. To address this issue, we propose a method that combines the Bi-Directional Text Fusion (BiT) module and Category-Aware Temporal Graph (CATS) module. Specifically, we integrate the strengths and complementarity of the two previous research directions. We first perform semantic injection and dynamic calibration on audio and visual modality features through the BiT module, to locate and purify cleaner and richer semantic cues. Then, we leverage the CATS module for semantic propagation and connection to enable precise semantic information dissemination across time. Experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance in multiple key indicators on two benchmark datasets, LLP and UnAV-100.
Deconstruct Complexity (DeComplex): A Novel Perspective on Tackling Dense Action Detection
Jan 30, 2025Dense action detection involves detecting multiple co-occurring actions in an untrimmed video while action classes are often ambiguous and represent overlapping concepts. To address this challenge task, we introduce a novel perspective inspired by how humans tackle complex tasks by breaking them into manageable sub-tasks. Instead of relying on a single network to address the entire problem, as in current approaches, we propose decomposing the problem into detecting key concepts present in action classes, specifically, detecting dense static concepts and detecting dense dynamic concepts, and assigning them to distinct, specialized networks. Furthermore, simultaneous actions in a video often exhibit interrelationships, and exploiting these relationships can improve performance. However, we argue that current networks fail to effectively learn these relationships due to their reliance on binary cross-entropy optimization, which treats each class independently. To address this limitation, we propose providing explicit supervision on co-occurring concepts during network optimization through a novel language-guided contrastive learning loss. Our extensive experiments demonstrate the superiority of our approach over state-of-the-art methods, achieving substantial relative improvements of 23.4% and 2.5% mAP on the challenging benchmark datasets, Charades and MultiTHUMOS.
An Effective-Efficient Approach for Dense Multi-Label Action Detection
Jun 10, 2024



Unlike the sparse label action detection task, where a single action occurs in each timestamp of a video, in a dense multi-label scenario, actions can overlap. To address this challenging task, it is necessary to simultaneously learn (i) temporal dependencies and (ii) co-occurrence action relationships. Recent approaches model temporal information by extracting multi-scale features through hierarchical transformer-based networks. However, the self-attention mechanism in transformers inherently loses temporal positional information. We argue that combining this with multiple sub-sampling processes in hierarchical designs can lead to further loss of positional information. Preserving this information is essential for accurate action detection. In this paper, we address this issue by proposing a novel transformer-based network that (a) employs a non-hierarchical structure when modelling different ranges of temporal dependencies and (b) embeds relative positional encoding in its transformer layers. Furthermore, to model co-occurrence action relationships, current methods explicitly embed class relations into the transformer network. However, these approaches are not computationally efficient, as the network needs to compute all possible pair action class relations. We also overcome this challenge by introducing a novel learning paradigm that allows the network to benefit from explicitly modelling temporal co-occurrence action dependencies without imposing their additional computational costs during inference. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets and show that our method improves the current state-of-the-art results.
NarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
Jun 10, 2024



Existing video captioning benchmarks and models lack coherent representations of causal-temporal narrative, which is sequences of events linked through cause and effect, unfolding over time and driven by characters or agents. This lack of narrative restricts models' ability to generate text descriptions that capture the causal and temporal dynamics inherent in video content. To address this gap, we propose NarrativeBridge, an approach comprising of: (1) a novel Causal-Temporal Narrative (CTN) captions benchmark generated using a large language model and few-shot prompting, explicitly encoding cause-effect temporal relationships in video descriptions, evaluated automatically to ensure caption quality and relevance; and (2) a dedicated Cause-Effect Network (CEN) architecture with separate encoders for capturing cause and effect dynamics independently, enabling effective learning and generation of captions with causal-temporal narrative. Extensive experiments demonstrate that CEN is more accurate in articulating the causal and temporal aspects of video content than the second best model (GIT): 17.88 and 17.44 CIDEr on the MSVD and MSR-VTT datasets, respectively. The proposed framework understands and generates nuanced text descriptions with intricate causal-temporal narrative structures present in videos, addressing a critical limitation in video captioning. For project details, visit https://narrativebridge.github.io/.
CoLeaF: A Contrastive-Collaborative Learning Framework for Weakly Supervised Audio-Visual Video Parsing
May 17, 2024



Weakly supervised audio-visual video parsing (AVVP) methods aim to detect audible-only, visible-only, and audible-visible events using only video-level labels. Existing approaches tackle this by leveraging unimodal and cross-modal contexts. However, we argue that while cross-modal learning is beneficial for detecting audible-visible events, in the weakly supervised scenario, it negatively impacts unaligned audible or visible events by introducing irrelevant modality information. In this paper, we propose CoLeaF, a novel learning framework that optimizes the integration of cross-modal context in the embedding space such that the network explicitly learns to combine cross-modal information for audible-visible events while filtering them out for unaligned events. Additionally, as videos often involve complex class relationships, modelling them improves performance. However, this introduces extra computational costs into the network. Our framework is designed to leverage cross-class relationships during training without incurring additional computations at inference. Furthermore, we propose new metrics to better evaluate a method's capabilities in performing AVVP. Our extensive experiments demonstrate that CoLeaF significantly improves the state-of-the-art results by an average of 1.9% and 2.4% F-score on the LLP and UnAV-100 datasets, respectively.
PAT: Position-Aware Transformer for Dense Multi-Label Action Detection
Aug 09, 2023



We present PAT, a transformer-based network that learns complex temporal co-occurrence action dependencies in a video by exploiting multi-scale temporal features. In existing methods, the self-attention mechanism in transformers loses the temporal positional information, which is essential for robust action detection. To address this issue, we (i) embed relative positional encoding in the self-attention mechanism and (ii) exploit multi-scale temporal relationships by designing a novel non hierarchical network, in contrast to the recent transformer-based approaches that use a hierarchical structure. We argue that joining the self-attention mechanism with multiple sub-sampling processes in the hierarchical approaches results in increased loss of positional information. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets, and show that PAT improves the current state-of-the-art result by 1.1% and 0.6% mAP on the Charades and MultiTHUMOS datasets, respectively, thereby achieving the new state-of-the-art mAP at 26.5% and 44.6%, respectively. We also perform extensive ablation studies to examine the impact of the different components of our proposed network.
Unsupervised View-Invariant Human Posture Representation
Sep 17, 2021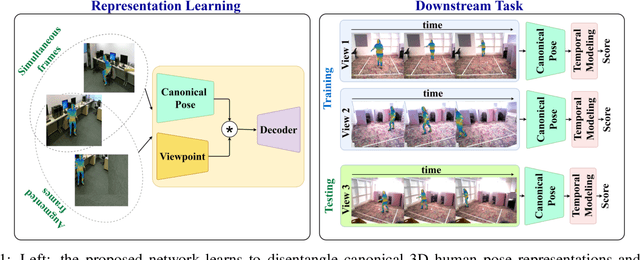

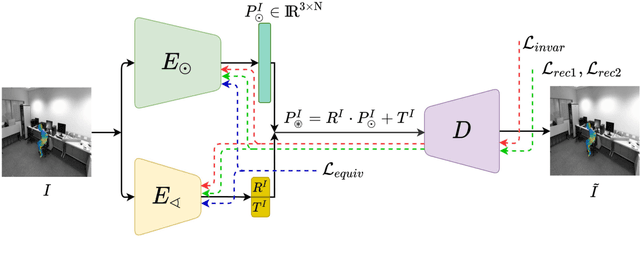
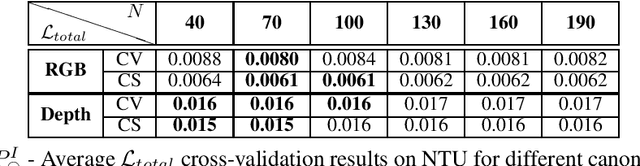
Most recent view-invariant action recognition and performance assessment approaches rely on a large amount of annotated 3D skeleton data to extract view-invariant features. However, acquiring 3D skeleton data can be cumbersome, if not impractical, in in-the-wild scenarios. To overcome this problem, we present a novel unsupervised approach that learns to extract view-invariant 3D human pose representation from a 2D image without using 3D joint data. Our model is trained by exploiting the intrinsic view-invariant properties of human pose between simultaneous frames from different viewpoints and their equivariant properties between augmented frames from the same viewpoint. We evaluate the learned view-invariant pose representations for two downstream tasks. We perform comparative experiments that show improvements on the state-of-the-art unsupervised cross-view action classification accuracy on NTU RGB+D by a significant margin, on both RGB and depth images. We also show the efficiency of transferring the learned representations from NTU RGB+D to obtain the first ever unsupervised cross-view and cross-subject rank correlation results on the multi-view human movement quality dataset, QMAR, and marginally improve on the-state-of-the-art supervised results for this dataset. We also carry out ablation studies to examine the contributions of the different components of our proposed network.
VI-Net: View-Invariant Quality of Human Movement Assessment
Aug 11, 2020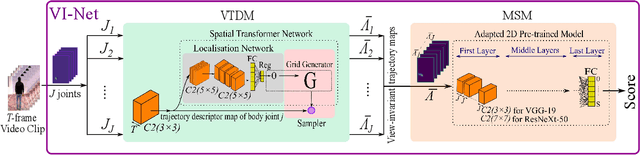
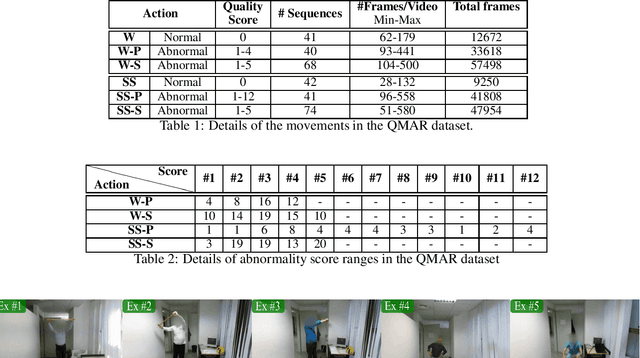
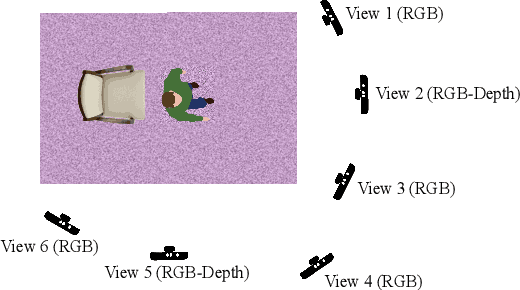

We propose a view-invariant method towards the assessment of the quality of human movements which does not rely on skeleton data. Our end-to-end convolutional neural network consists of two stages, where at first a view-invariant trajectory descriptor for each body joint is generated from RGB images, and then the collection of trajectories for all joints are processed by an adapted, pre-trained 2D CNN (e.g. VGG-19 or ResNeXt-50) to learn the relationship amongst the different body parts and deliver a score for the movement quality. We release the only publicly-available, multi-view, non-skeleton, non-mocap, rehabilitation movement dataset (QMAR), and provide results for both cross-subject and cross-view scenarios on this dataset. We show that VI-Net achieves average rank correlation of 0.66 on cross-subject and 0.65 on unseen views when trained on only two views. We also evaluate the proposed method on the single-view rehabilitation dataset KIMORE and obtain 0.66 rank correlation against a baseline of 0.62.