 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-State Controllers for (Hidden-Model) POMDPs using Deep Reinforcement Learning
Feb 09, 2026Solving partially observable Markov decision processes (POMDPs) requires computing policies under imperfect state information. Despite recent advances, the scalability of existing POMDP solvers remains limited. Moreover, many settings require a policy that is robust across multiple POMDPs, further aggravating the scalability issue. We propose the Lexpop framework for POMDP solving. Lexpop (1) employs deep reinforcement learning to train a neural policy, represented by a recurrent neural network, and (2) constructs a finite-state controller mimicking the neural policy through efficient extraction methods. Crucially, unlike neural policies, such controllers can be formally evaluated, providing performance guarantees. We extend Lexpop to compute robust policies for hidden-model POMDPs (HM-POMDPs), which describe finite sets of POMDPs. We associate every extracted controller with its worst-case POMDP. Using a set of such POMDPs, we iteratively train a robust neural policy and consequently extract a robust controller. Our experiments show that on problems with large state spaces, Lexpop outperforms state-of-the-art solvers for POMDPs as well as HM-POMDPs.
Rule-Guided Reinforcement Learning Policy Evaluation and Improvement
Mar 12, 2025We consider the challenging problem of using domain knowledge to improve deep reinforcement learning policies. To this end, we propose LEGIBLE, a novel approach, following a multi-step process, which starts by mining rules from a deep RL policy, constituting a partially symbolic representation. These rules describe which decisions the RL policy makes and which it avoids making. In the second step, we generalize the mined rules using domain knowledge expressed as metamorphic relations. We adapt these relations from software testing to RL to specify expected changes of actions in response to changes in observations. The third step is evaluating generalized rules to determine which generalizations improve performance when enforced. These improvements show weaknesses in the policy, where it has not learned the general rules and thus can be improved by rule guidance. LEGIBLE supported by metamorphic relations provides a principled way of expressing and enforcing domain knowledge about RL environments. We show the efficacy of our approach by demonstrating that it effectively finds weaknesses, accompanied by explanations of these weaknesses, in eleven RL environments and by showcasing that guiding policy execution with rules improves performance w.r.t. gained reward.
Test Where Decisions Matter: Importance-driven Testing for Deep Reinforcement Learning
Nov 12, 2024



In many Deep Reinforcement Learning (RL) problems, decisions in a trained policy vary in significance for the expected safety and performance of the policy. Since RL policies are very complex, testing efforts should concentrate on states in which the agent's decisions have the highest impact on the expected outcome. In this paper, we propose a novel model-based method to rigorously compute a ranking of state importance across the entire state space. We then focus our testing efforts on the highest-ranked states. In this paper, we focus on testing for safety. However, the proposed methods can be easily adapted to test for performance. In each iteration, our testing framework computes optimistic and pessimistic safety estimates. These estimates provide lower and upper bounds on the expected outcomes of the policy execution across all modeled states in the state space. Our approach divides the state space into safe and unsafe regions upon convergence, providing clear insights into the policy's weaknesses. Two important properties characterize our approach. (1) Optimal Test-Case Selection: At any time in the testing process, our approach evaluates the policy in the states that are most critical for safety. (2) Guaranteed Safety: Our approach can provide formal verification guarantees over the entire state space by sampling only a fraction of the policy. Any safety properties assured by the pessimistic estimate are formally proven to hold for the policy. We provide a detailed evaluation of our framework on several examples, showing that our method discovers unsafe policy behavior with low testing effort.
Learning Environment Models with Continuous Stochastic Dynamics
Jun 29, 2023



Solving control tasks in complex environments automatically through learning offers great potential. While contemporary techniques from deep reinforcement learning (DRL) provide effective solutions, their decision-making is not transparent. We aim to provide insights into the decisions faced by the agent by learning an automaton model of environmental behavior under the control of an agent. However, for most control problems, automata learning is not scalable enough to learn a useful model. In this work, we raise the capabilities of automata learning such that it is possible to learn models for environments that have complex and continuous dynamics. The core of the scalability of our method lies in the computation of an abstract state-space representation, by applying dimensionality reduction and clustering on the observed environmental state space. The stochastic transitions are learned via passive automata learning from observed interactions of the agent and the environment. In an iterative model-based RL process, we sample additional trajectories to learn an accurate environment model in the form of a discrete-state Markov decision process (MDP). We apply our automata learning framework on popular RL benchmarking environments in the OpenAI Gym, including LunarLander, CartPole, Mountain Car, and Acrobot. Our results show that the learned models are so precise that they enable the computation of policies solving the respective control tasks. Yet the models are more concise and more general than neural-network-based policies and by using MDPs we benefit from a wealth of tools available for analyzing them. When solving the task of LunarLander, the learned model even achieved similar or higher rewards than deep RL policies learned with stable-baselines3.
On the Relationship Between RNN Hidden State Vectors and Semantic Ground Truth
Jun 29, 2023



We examine the assumption that the hidden-state vectors of recurrent neural networks (RNNs) tend to form clusters of semantically similar vectors, which we dub the clustering hypothesis. While this hypothesis has been assumed in the analysis of RNNs in recent years, its validity has not been studied thoroughly on modern neural network architectures. We examine the clustering hypothesis in the context of RNNs that were trained to recognize regular languages. This enables us to draw on perfect ground-truth automata in our evaluation, against which we can compare the RNN's accuracy and the distribution of the hidden-state vectors. We start with examining the (piecewise linear) separability of an RNN's hidden-state vectors into semantically different classes. We continue the analysis by computing clusters over the hidden-state vector space with multiple state-of-the-art unsupervised clustering approaches. We formally analyze the accuracy of computed clustering functions and the validity of the clustering hypothesis by determining whether clusters group semantically similar vectors to the same state in the ground-truth model. Our evaluation supports the validity of the clustering hypothesis in the majority of examined cases. We observed that the hidden-state vectors of well-trained RNNs are separable, and that the unsupervised clustering techniques succeed in finding clusters of similar state vectors.
Automata Learning meets Shielding
Dec 04, 2022Safety is still one of the major research challenges in reinforcement learning (RL). In this paper, we address the problem of how to avoid safety violations of RL agents during exploration in probabilistic and partially unknown environments. Our approach combines automata learning for Markov Decision Processes (MDPs) and shield synthesis in an iterative approach. Initially, the MDP representing the environment is unknown. The agent starts exploring the environment and collects traces. From the collected traces, we passively learn MDPs that abstractly represent the safety-relevant aspects of the environment. Given a learned MDP and a safety specification, we construct a shield. For each state-action pair within a learned MDP, the shield computes exact probabilities on how likely it is that executing the action results in violating the specification from the current state within the next $k$ steps. After the shield is constructed, the shield is used during runtime and blocks any actions that induce a too large risk from the agent. The shielded agent continues to explore the environment and collects new data on the environment. Iteratively, we use the collected data to learn new MDPs with higher accuracy, resulting in turn in shields able to prevent more safety violations. We implemented our approach and present a detailed case study of a Q-learning agent exploring slippery Gridworlds. In our experiments, we show that as the agent explores more and more of the environment during training, the improved learned models lead to shields that are able to prevent many safety violations.
Online Shielding for Reinforcement Learning
Dec 04, 2022Besides the recent impressive results on reinforcement learning (RL), safety is still one of the major research challenges in RL. RL is a machine-learning approach to determine near-optimal policies in Markov decision processes (MDPs). In this paper, we consider the setting where the safety-relevant fragment of the MDP together with a temporal logic safety specification is given and many safety violations can be avoided by planning ahead a short time into the future. We propose an approach for online safety shielding of RL agents. During runtime, the shield analyses the safety of each available action. For any action, the shield computes the maximal probability to not violate the safety specification within the next $k$ steps when executing this action. Based on this probability and a given threshold, the shield decides whether to block an action from the agent. Existing offline shielding approaches compute exhaustively the safety of all state-action combinations ahead of time, resulting in huge computation times and large memory consumption. The intuition behind online shielding is to compute at runtime the set of all states that could be reached in the near future. For each of these states, the safety of all available actions is analysed and used for shielding as soon as one of the considered states is reached. Our approach is well suited for high-level planning problems where the time between decisions can be used for safety computations and it is sustainable for the agent to wait until these computations are finished. For our evaluation, we selected a 2-player version of the classical computer game SNAKE. The game represents a high-level planning problem that requires fast decisions and the multiplayer setting induces a large state space, which is computationally expensive to analyse exhaustively.
Reinforcement Learning under Partial Observability Guided by Learned Environment Models
Jun 23, 2022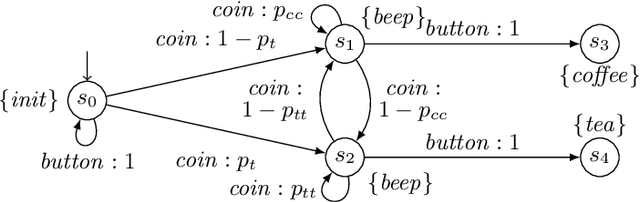
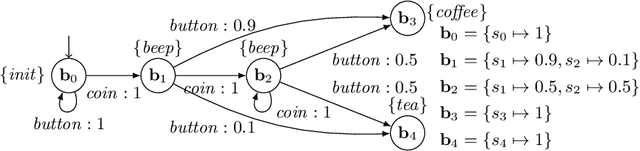
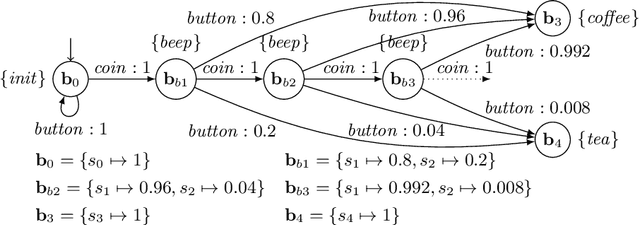
In practical applications, we can rarely assume full observability of a system's environment, despite such knowledge being important for determining a reactive control system's precise interaction with its environment. Therefore, we propose an approach for reinforcement learning (RL) in partially observable environments. While assuming that the environment behaves like a partially observable Markov decision process with known discrete actions, we assume no knowledge about its structure or transition probabilities. Our approach combines Q-learning with IoAlergia, a method for learning Markov decision processes (MDP). By learning MDP models of the environment from episodes of the RL agent, we enable RL in partially observable domains without explicit, additional memory to track previous interactions for dealing with ambiguities stemming from partial observability. We instead provide RL with additional observations in the form of abstract environment states by simulating new experiences on learned environment models to track the explored states. In our evaluation, we report on the validity of our approach and its promising performance in comparison to six state-of-the-art deep RL techniques with recurrent neural networks and fixed memory.
Search-Based Testing of Reinforcement Learning
May 14, 2022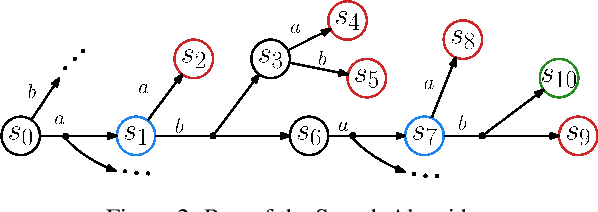
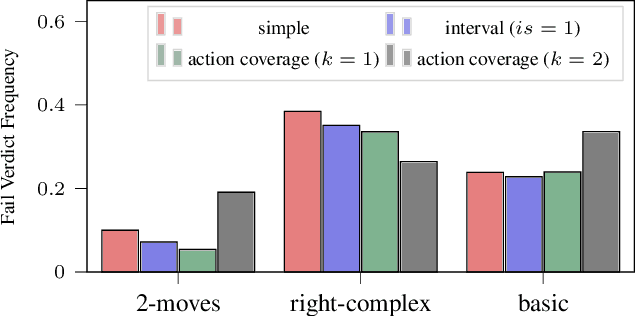
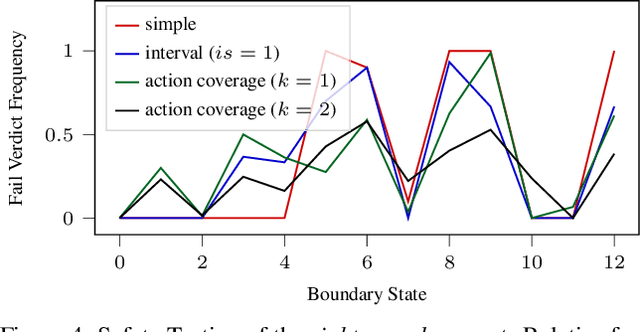
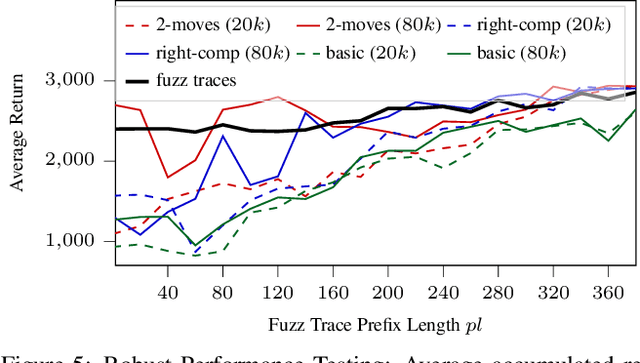
Evaluation of deep reinforcement learning (RL) is inherently challenging. Especially the opaqueness of learned policies and the stochastic nature of both agents and environments make testing the behavior of deep RL agents difficult. We present a search-based testing framework that enables a wide range of novel analysis capabilities for evaluating the safety and performance of deep RL agents. For safety testing, our framework utilizes a search algorithm that searches for a reference trace that solves the RL task. The backtracking states of the search, called boundary states, pose safety-critical situations. We create safety test-suites that evaluate how well the RL agent escapes safety-critical situations near these boundary states. For robust performance testing, we create a diverse set of traces via fuzz testing. These fuzz traces are used to bring the agent into a wide variety of potentially unknown states from which the average performance of the agent is compared to the average performance of the fuzz traces. We apply our search-based testing approach on RL for Nintendo's Super Mario Bros.
Learning a Behavior Model of Hybrid Systems Through Combining Model-Based Testing and Machine Learning
Jul 10, 2019
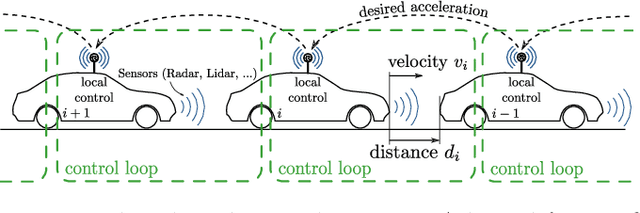
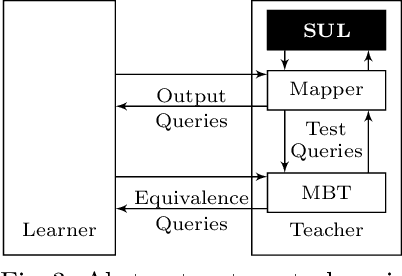
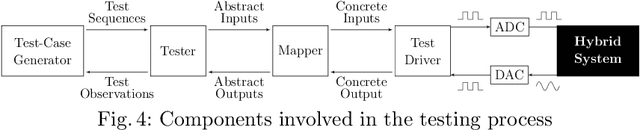
Models play an essential role in the design process of cyber-physical systems. They form the basis for simulation and analysis and help in identifying design problems as early as possible. However, the construction of models that comprise physical and digital behavior is challenging. Therefore, there is considerable interest in learning such hybrid behavior by means of machine learning which requires sufficient and representative training data covering the behavior of the physical system adequately. In this work, we exploit a combination of automata learning and model-based testing to generate sufficient training data fully automatically. Experimental results on a platooning scenario show that recurrent neural networks learned with this data achieved significantly better results compared to models learned from randomly generated data. In particular, the classification error for crash detection is reduced by a factor of five and a similar F1-score is obtained with up to three orders of magnitude fewer training samples.