 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Pass Filtering Improves Behavioral Alignment of Vision Models
Feb 14, 2026Despite their impressive performance on computer vision benchmarks, Deep Neural Networks (DNNs) still fall short of adequately modeling human visual behavior, as measured by error consistency and shape bias. Recent work hypothesized that behavioral alignment can be drastically improved through \emph{generative} -- rather than \emph{discriminative} -- classifiers, with far-reaching implications for models of human vision. Here, we instead show that the increased alignment of generative models can be largely explained by a seemingly innocuous resizing operation in the generative model which effectively acts as a low-pass filter. In a series of controlled experiments, we show that removing high-frequency spatial information from discriminative models like CLIP drastically increases their behavioral alignment. Simply blurring images at test-time -- rather than training on blurred images -- achieves a new state-of-the-art score on the model-vs-human benchmark, halving the current alignment gap between DNNs and human observers. Furthermore, low-pass filters are likely optimal, which we demonstrate by directly optimizing filters for alignment. To contextualize the performance of optimal filters, we compute the frontier of all possible pareto-optimal solutions to the benchmark, which was formerly unknown. We explain our findings by observing that the frequency spectrum of optimal Gaussian filters roughly matches the spectrum of band-pass filters implemented by the human visual system. We show that the contrast sensitivity function, describing the inverse of the contrast threshold required for humans to detect a sinusoidal grating as a function of spatiotemporal frequency, is approximated well by Gaussian filters of the specific width that also maximizes error consistency.
Signal Strength and Noise Drive Feature Preference in CNN Image Classifiers
Jan 19, 2022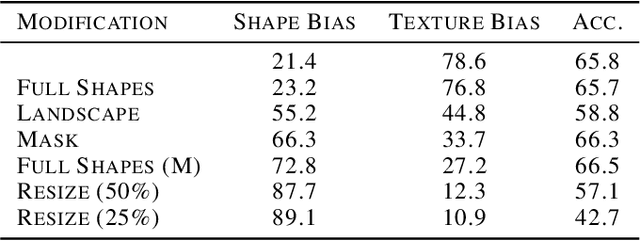
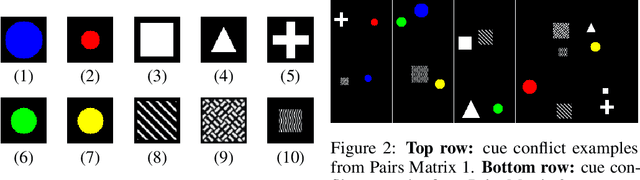
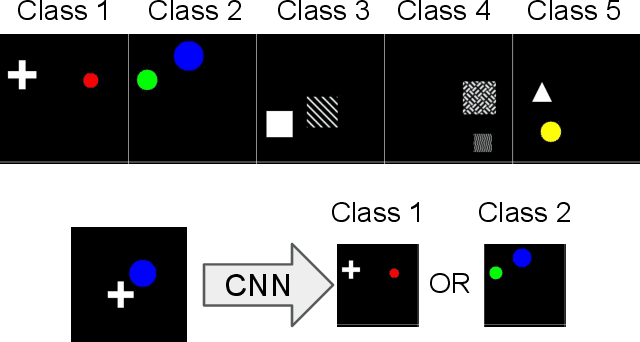
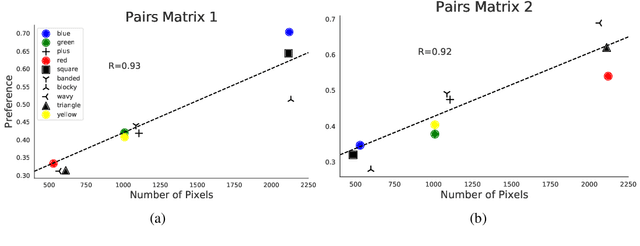
Feature preference in Convolutional Neural Network (CNN) image classifiers is integral to their decision making process, and while the topic has been well studied, it is still not understood at a fundamental level. We test a range of task relevant feature attributes (including shape, texture, and color) with varying degrees of signal and noise in highly controlled CNN image classification experiments using synthetic datasets to determine feature preferences. We find that CNNs will prefer features with stronger signal strength and lower noise irrespective of whether the feature is texture, shape, or color. This provides guidance for a predictive model for task relevant feature preferences, demonstrates pathways for bias in machine models that can be avoided with careful controls on experimental setup, and suggests that comparisons between how humans and machines prefer task relevant features in vision classification tasks should be revisited. Code to reproduce experiments in this paper can be found at \url{https://github.com/mwolff31/signal_preference}.
Attacking Neural Text Detectors
Feb 19, 2020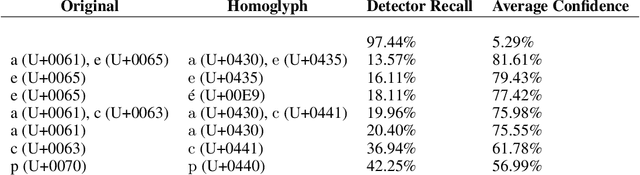
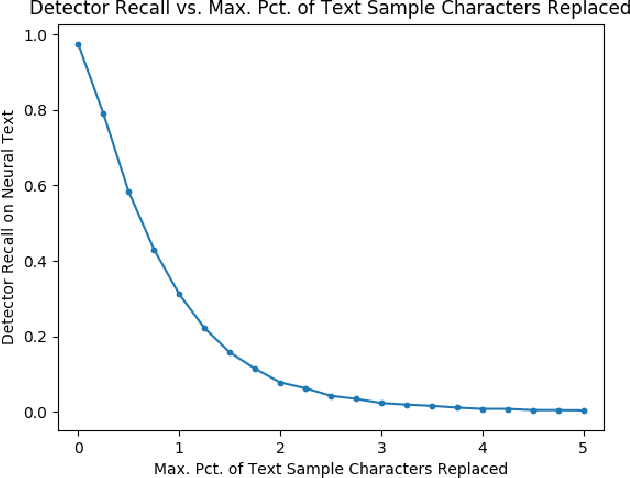

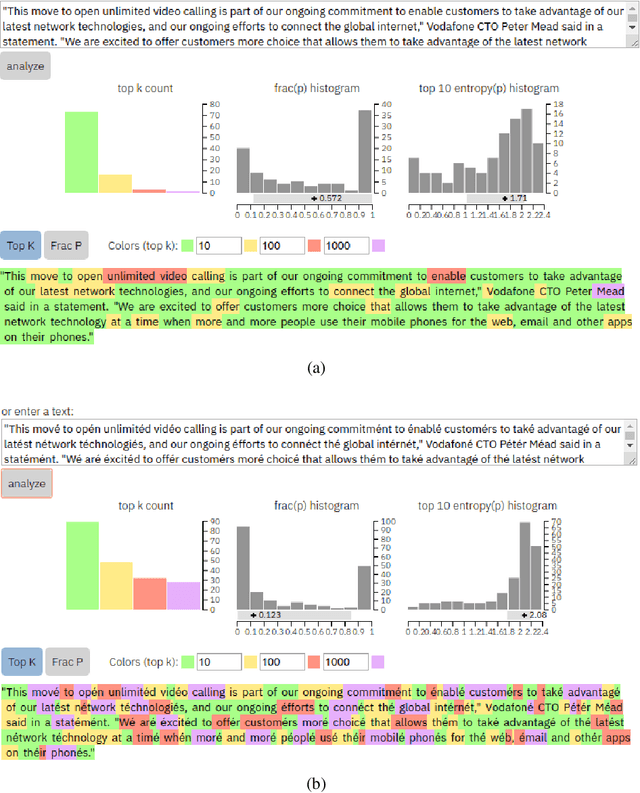
Machine learning based language models have recently made significant progress, which introduces a danger to spread misinformation. To combat this potential danger, several methods have been proposed for detecting text written by these language models. This paper presents two classes of black-box attacks on these detectors, one which randomly replaces characters with homoglyphs, and the other a simple scheme to purposefully misspell words. The homoglyph and misspelling attacks decrease a popular neural text detector's recall on neural text from 97.44% to 0.26% and 22.68%, respectively. Results also indicate that the attacks are transferable to other neural text detectors.