 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation
Dec 22, 2025Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the π_{0}, π_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs. Project page: https://martin-sedlacek.com/realm
Large-scale Pre-training for Grounded Video Caption Generation
Mar 13, 2025We propose a novel approach for captioning and object grounding in video, where the objects in the caption are grounded in the video via temporally dense bounding boxes. We introduce the following contributions. First, we present a large-scale automatic annotation method that aggregates captions grounded with bounding boxes across individual frames into temporally dense and consistent bounding box annotations. We apply this approach on the HowTo100M dataset to construct a large-scale pre-training dataset, named HowToGround1M. We also introduce a Grounded Video Caption Generation model, dubbed GROVE, and pre-train the model on HowToGround1M. Second, we introduce a new dataset, called iGround, of 3500 videos with manually annotated captions and dense spatio-temporally grounded bounding boxes. This allows us to measure progress on this challenging problem, as well as to fine-tune our model on this small-scale but high-quality data. Third, we demonstrate that our approach achieves state-of-the-art results on the proposed iGround dataset compared to a number of baselines, as well as on the VidSTG and ActivityNet-Entities datasets. We perform extensive ablations that demonstrate the importance of pre-training using our automatically annotated HowToGround1M dataset followed by fine-tuning on the manually annotated iGround dataset and validate the key technical contributions of our model.
Grounded Video Caption Generation
Nov 12, 2024We propose a new task, dataset and model for grounded video caption generation. This task unifies captioning and object grounding in video, where the objects in the caption are grounded in the video via temporally consistent bounding boxes. We introduce the following contributions. First, we present a task definition and a manually annotated test dataset for this task, referred to as GROunded Video Caption Generation (GROC). Second, we introduce a large-scale automatic annotation method leveraging an existing model for grounded still image captioning together with an LLM for summarising frame-level captions into temporally consistent captions in video. Furthermore, we prompt the LLM to track by language -- classifying noun phrases from the frame-level captions into noun phrases of the video-level generated caption. We apply this approach to videos from the HowTo100M dataset, which results in a new large-scale training dataset, called HowToGround, with automatically annotated captions and spatio-temporally consistent bounding boxes with coherent natural language labels. Third, we introduce a new grounded video caption generation model, called VideoGround, and train the model on the new automatically annotated HowToGround dataset. Finally, results of our VideoGround model set the state of the art for the new task of grounded video caption generation. We perform extensive ablations and demonstrate the importance of key technical contributions of our model.
TIM: A Time Interval Machine for Audio-Visual Action Recognition
Apr 09, 2024



Diverse actions give rise to rich audio-visual signals in long videos. Recent works showcase that the two modalities of audio and video exhibit different temporal extents of events and distinct labels. We address the interplay between the two modalities in long videos by explicitly modelling the temporal extents of audio and visual events. We propose the Time Interval Machine (TIM) where a modality-specific time interval poses as a query to a transformer encoder that ingests a long video input. The encoder then attends to the specified interval, as well as the surrounding context in both modalities, in order to recognise the ongoing action. We test TIM on three long audio-visual video datasets: EPIC-KITCHENS, Perception Test, and AVE, reporting state-of-the-art (SOTA) for recognition. On EPIC-KITCHENS, we beat previous SOTA that utilises LLMs and significantly larger pre-training by 2.9% top-1 action recognition accuracy. Additionally, we show that TIM can be adapted for action detection, using dense multi-scale interval queries, outperforming SOTA on EPIC-KITCHENS-100 for most metrics, and showing strong performance on the Perception Test. Our ablations show the critical role of integrating the two modalities and modelling their time intervals in achieving this performance. Code and models at: https://github.com/JacobChalk/TIM
Graph Guided Question Answer Generation for Procedural Question-Answering
Jan 24, 2024



In this paper, we focus on task-specific question answering (QA). To this end, we introduce a method for generating exhaustive and high-quality training data, which allows us to train compact (e.g., run on a mobile device), task-specific QA models that are competitive against GPT variants. The key technological enabler is a novel mechanism for automatic question-answer generation from procedural text which can ingest large amounts of textual instructions and produce exhaustive in-domain QA training data. While current QA data generation methods can produce well-formed and varied data, their non-exhaustive nature is sub-optimal for training a QA model. In contrast, we leverage the highly structured aspect of procedural text and represent each step and the overall flow of the procedure as graphs. We then condition on graph nodes to automatically generate QA pairs in an exhaustive and controllable manner. Comprehensive evaluations of our method show that: 1) small models trained with our data achieve excellent performance on the target QA task, even exceeding that of GPT3 and ChatGPT despite being several orders of magnitude smaller. 2) semantic coverage is the key indicator for downstream QA performance. Crucially, while large language models excel at syntactic diversity, this does not necessarily result in improvements on the end QA model. In contrast, the higher semantic coverage provided by our method is critical for QA performance.
Epic-Sounds: A Large-scale Dataset of Actions That Sound
Feb 01, 2023



We introduce EPIC-SOUNDS, a large-scale dataset of audio annotations capturing temporal extents and class labels within the audio stream of the egocentric videos. We propose an annotation pipeline where annotators temporally label distinguishable audio segments and describe the action that could have caused this sound. We identify actions that can be discriminated purely from audio, through grouping these free-form descriptions of audio into classes. For actions that involve objects colliding, we collect human annotations of the materials of these objects (e.g. a glass object being placed on a wooden surface), which we verify from visual labels, discarding ambiguities. Overall, EPIC-SOUNDS includes 78.4k categorised segments of audible events and actions, distributed across 44 classes as well as 39.2k non-categorised segments. We train and evaluate two state-of-the-art audio recognition models on our dataset, highlighting the importance of audio-only labels and the limitations of current models to recognise actions that sound.
With a Little Help from my Temporal Context: Multimodal Egocentric Action Recognition
Nov 01, 2021
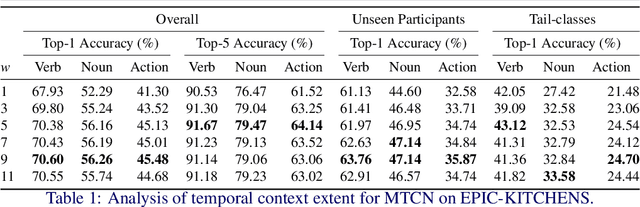

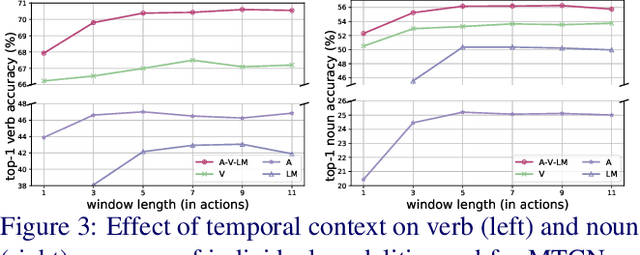
In egocentric videos, actions occur in quick succession. We capitalise on the action's temporal context and propose a method that learns to attend to surrounding actions in order to improve recognition performance. To incorporate the temporal context, we propose a transformer-based multimodal model that ingests video and audio as input modalities, with an explicit language model providing action sequence context to enhance the predictions. We test our approach on EPIC-KITCHENS and EGTEA datasets reporting state-of-the-art performance. Our ablations showcase the advantage of utilising temporal context as well as incorporating audio input modality and language model to rescore predictions. Code and models at: https://github.com/ekazakos/MTCN.
Slow-Fast Auditory Streams For Audio Recognition
Mar 05, 2021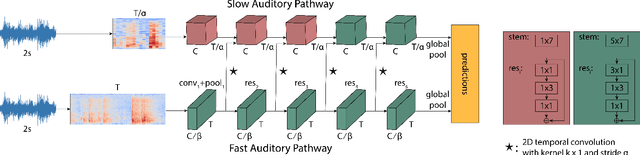
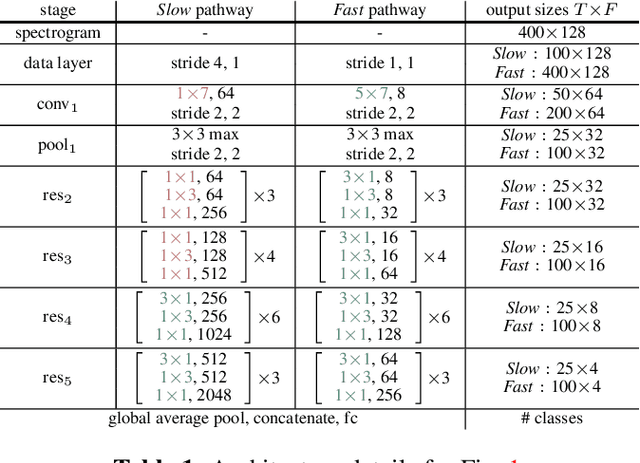

We propose a two-stream convolutional network for audio recognition, that operates on time-frequency spectrogram inputs. Following similar success in visual recognition, we learn Slow-Fast auditory streams with separable convolutions and multi-level lateral connections. The Slow pathway has high channel capacity while the Fast pathway operates at a fine-grained temporal resolution. We showcase the importance of our two-stream proposal on two diverse datasets: VGG-Sound and EPIC-KITCHENS-100, and achieve state-of-the-art results on both.
Rescaling Egocentric Vision
Jun 23, 2020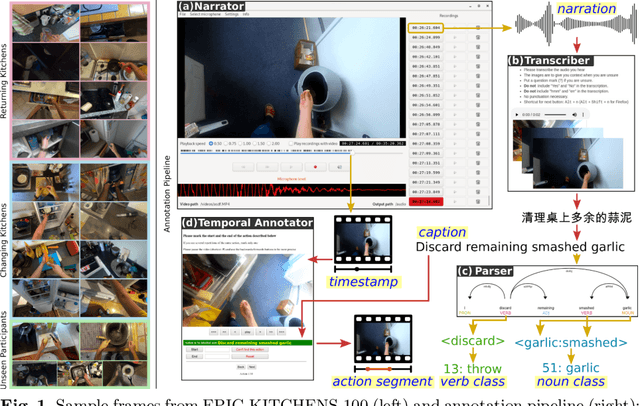
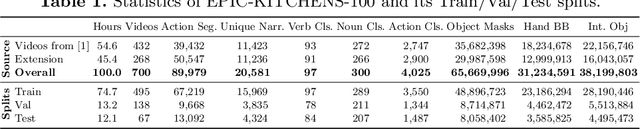
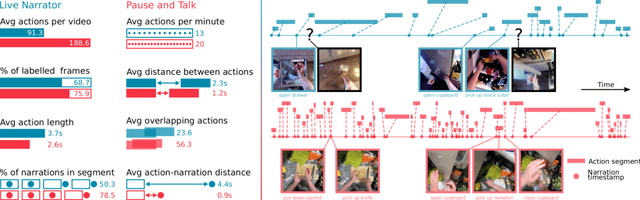
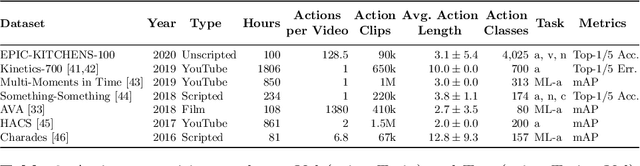
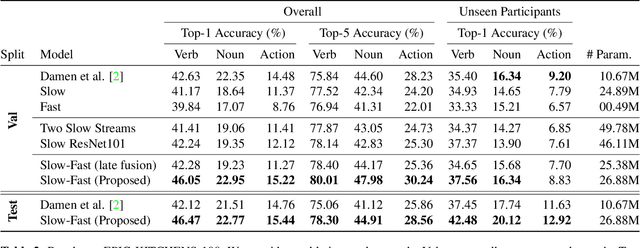
This paper introduces EPIC-KITCHENS-100, the largest annotated egocentric dataset - 100 hrs, 20M frames, 90K actions - of wearable videos capturing long-term unscripted activities in 45 environments. This extends our previous dataset (EPIC-KITCHENS-55), released in 2018, resulting in more action segments (+128%), environments (+41%) and hours (+84%), using a novel annotation pipeline that allows denser and more complete annotations of fine-grained actions (54% more actions per minute). We evaluate the "test of time" - i.e. whether models trained on data collected in 2018 can generalise to new footage collected under the same hypotheses albeit "two years on". The dataset is aligned with 6 challenges: action recognition (full and weak supervision), detection, anticipation, retrieval (from captions), as well as unsupervised domain adaptation for action recognition. For each challenge, we define the task, provide baselines and evaluation metrics. Our dataset and challenge leaderboards will be made publicly available.
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Apr 29, 2020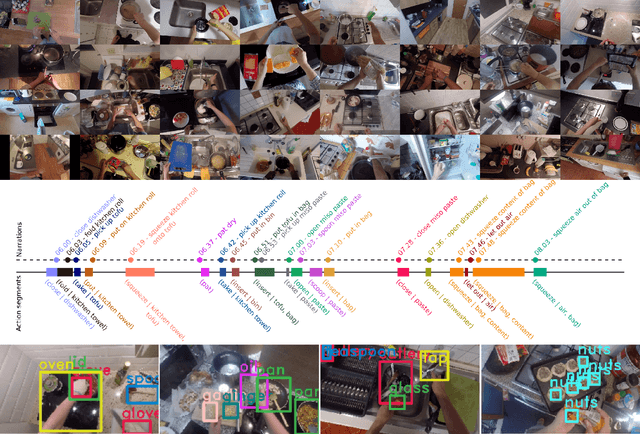
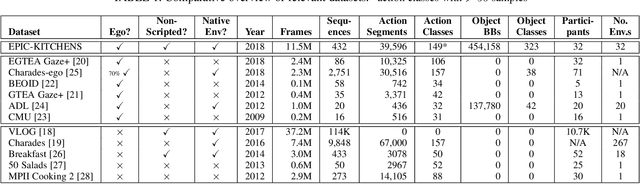

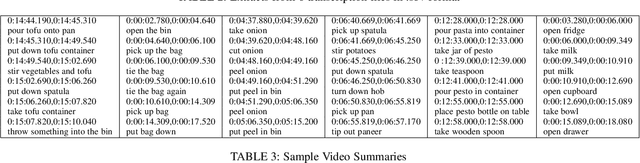
Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.