 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight-centric Visualization Recommendation
Mar 21, 2021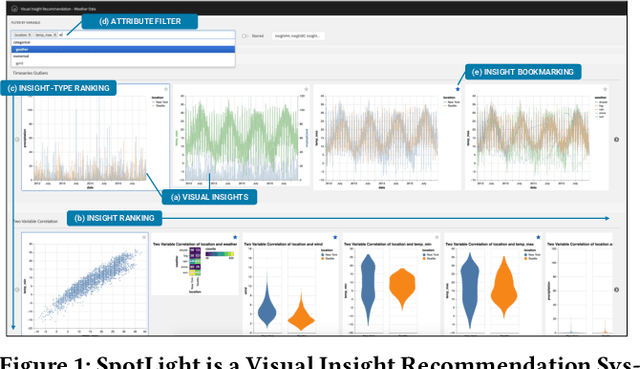
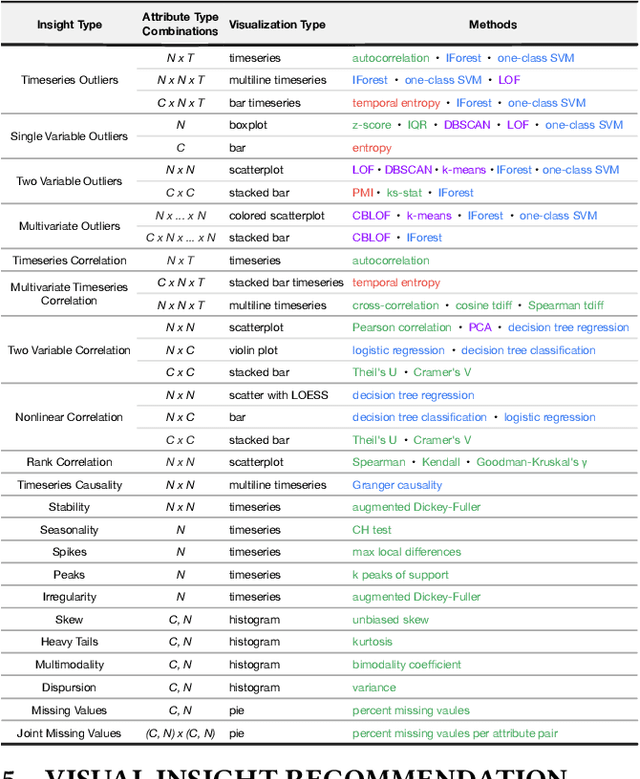
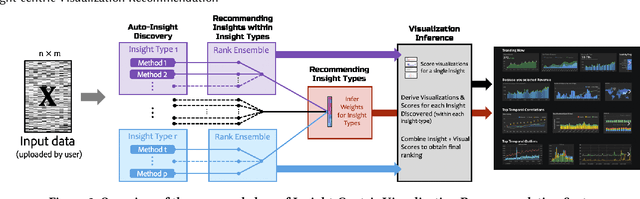
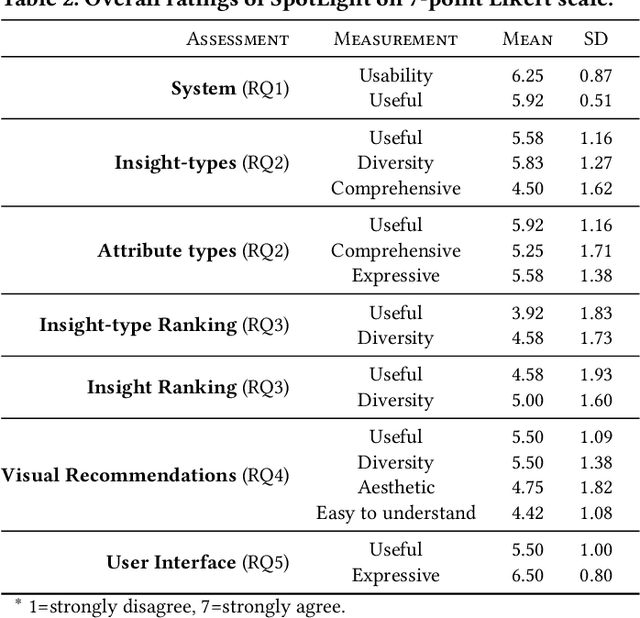
Visualization recommendation systems simplify exploratory data analysis (EDA) and make understanding data more accessible to users of all skill levels by automatically generating visualizations for users to explore. However, most existing visualization recommendation systems focus on ranking all visualizations into a single list or set of groups based on particular attributes or encodings. This global ranking makes it difficult and time-consuming for users to find the most interesting or relevant insights. To address these limitations, we introduce a novel class of visualization recommendation systems that automatically rank and recommend both groups of related insights as well as the most important insights within each group. Our proposed approach combines results from many different learning-based methods to discover insights automatically. A key advantage is that this approach generalizes to a wide variety of attribute types such as categorical, numerical, and temporal, as well as complex non-trivial combinations of these different attribute types. To evaluate the effectiveness of our approach, we implemented a new insight-centric visualization recommendation system, SpotLight, which generates and ranks annotated visualizations to explain each insight. We conducted a user study with 12 participants and two datasets which showed that users are able to quickly understand and find relevant insights in unfamiliar data.
Personalized Visualization Recommendation
Feb 12, 2021
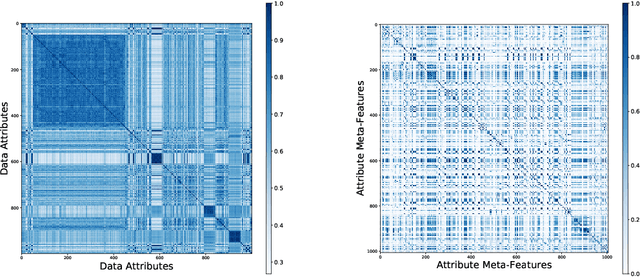

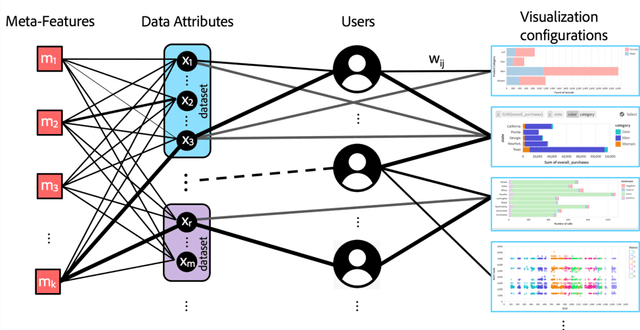
Visualization recommendation work has focused solely on scoring visualizations based on the underlying dataset and not the actual user and their past visualization feedback. These systems recommend the same visualizations for every user, despite that the underlying user interests, intent, and visualization preferences are likely to be fundamentally different, yet vitally important. In this work, we formally introduce the problem of personalized visualization recommendation and present a generic learning framework for solving it. In particular, we focus on recommending visualizations personalized for each individual user based on their past visualization interactions (e.g., viewed, clicked, manually created) along with the data from those visualizations. More importantly, the framework can learn from visualizations relevant to other users, even if the visualizations are generated from completely different datasets. Experiments demonstrate the effectiveness of the approach as it leads to higher quality visualization recommendations tailored to the specific user intent and preferences. To support research on this new problem, we release our user-centric visualization corpus consisting of 17.4k users exploring 94k datasets with 2.3 million attributes and 32k user-generated visualizations.
Heterogeneous Graphlets
Oct 23, 2020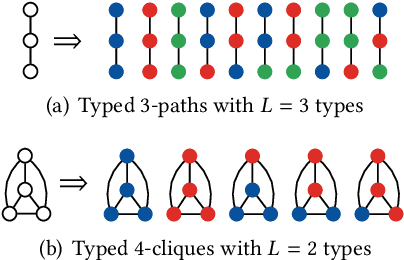


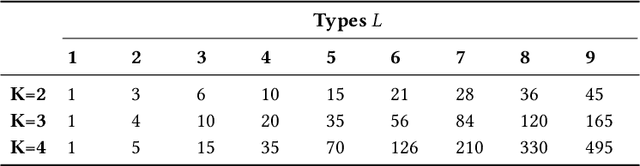
In this paper, we introduce a generalization of graphlets to heterogeneous networks called typed graphlets. Informally, typed graphlets are small typed induced subgraphs. Typed graphlets generalize graphlets to rich heterogeneous networks as they explicitly capture the higher-order typed connectivity patterns in such networks. To address this problem, we describe a general framework for counting the occurrences of such typed graphlets. The proposed algorithms leverage a number of combinatorial relationships for different typed graphlets. For each edge, we count a few typed graphlets, and with these counts along with the combinatorial relationships, we obtain the exact counts of the other typed graphlets in o(1) constant time. Notably, the worst-case time complexity of the proposed approach matches the time complexity of the best known untyped algorithm. In addition, the approach lends itself to an efficient lock-free and asynchronous parallel implementation. While there are no existing methods for typed graphlets, there has been some work that focused on computing a different and much simpler notion called colored graphlet. The experiments confirm that our proposed approach is orders of magnitude faster and more space-efficient than methods for computing the simpler notion of colored graphlet. Unlike these methods that take hours on small networks, the proposed approach takes only seconds on large networks with millions of edges. Notably, since typed graphlet is more general than colored graphlet (and untyped graphlets), the counts of various typed graphlets can be combined to obtain the counts of the much simpler notion of colored graphlets. The proposed methods give rise to new opportunities and applications for typed graphlets.
ML-based Visualization Recommendation: Learning to Recommend Visualizations from Data
Sep 25, 2020

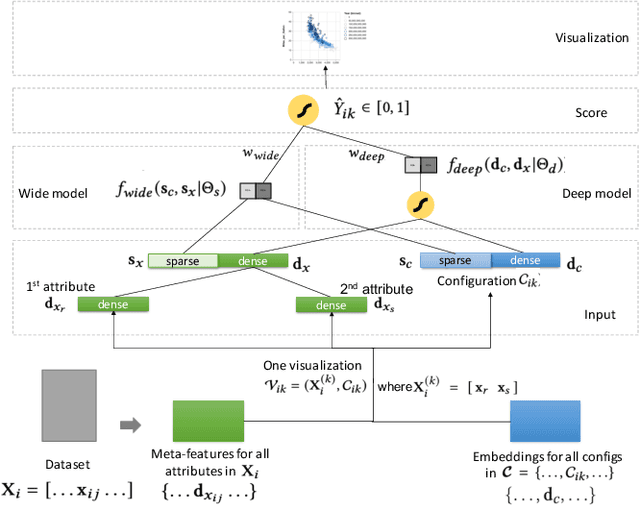
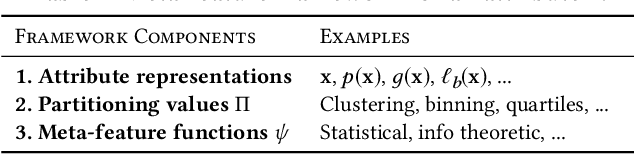
Visualization recommendation seeks to generate, score, and recommend to users useful visualizations automatically, and are fundamentally important for exploring and gaining insights into a new or existing dataset quickly. In this work, we propose the first end-to-end ML-based visualization recommendation system that takes as input a large corpus of datasets and visualizations, learns a model based on this data. Then, given a new unseen dataset from an arbitrary user, the model automatically generates visualizations for that new dataset, derive scores for the visualizations, and output a list of recommended visualizations to the user ordered by effectiveness. We also describe an evaluation framework to quantitatively evaluate visualization recommendation models learned from a large corpus of visualizations and datasets. Through quantitative experiments, a user study, and qualitative analysis, we show that our end-to-end ML-based system recommends more effective and useful visualizations compared to existing state-of-the-art rule-based systems. Finally, we observed a strong preference by the human experts in our user study towards the visualizations recommended by our ML-based system as opposed to the rule-based system (5.92 from a 7-point Likert scale compared to only 3.45).
Higher-Order Ranking and Link Prediction: From Closing Triangles to Closing Higher-Order Motifs
Jun 12, 2019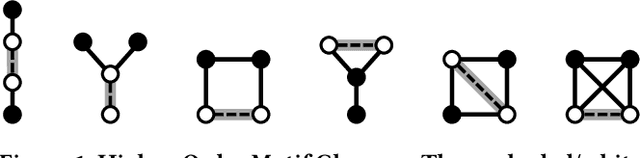
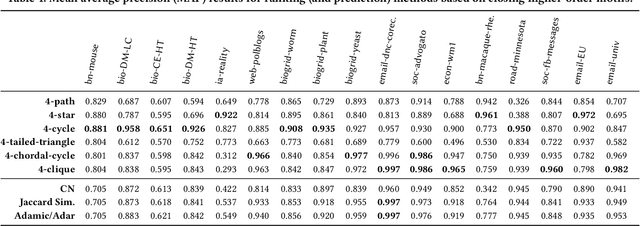
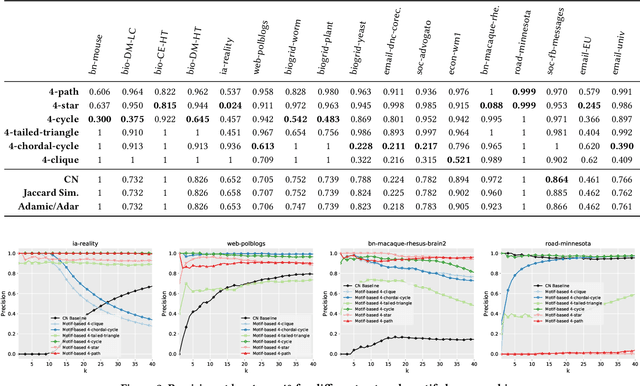
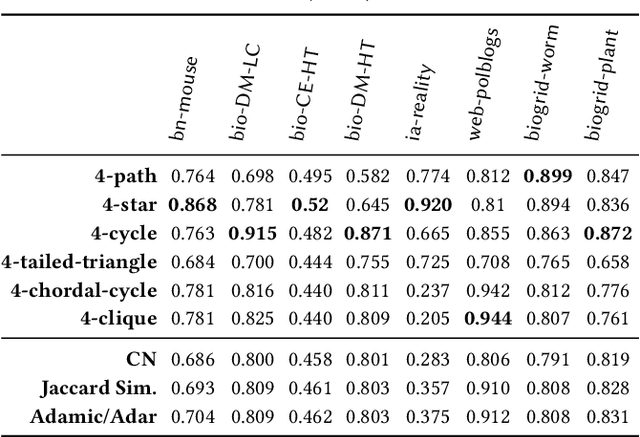
In this paper, we introduce the notion of motif closure and describe higher-order ranking and link prediction methods based on the notion of closing higher-order network motifs. The methods are fast and efficient for real-time ranking and link prediction-based applications such as web search, online advertising, and recommendation. In such applications, real-time performance is critical. The proposed methods do not require any explicit training data, nor do they derive an embedding from the graph data, or perform any explicit learning. Existing methods with the above desired properties are all based on closing triangles (common neighbors, Jaccard similarity, and the ilk). In this work, we investigate higher-order network motifs and develop techniques based on the notion of closing higher-order motifs that move beyond closing simple triangles. All methods described in this work are fast with a runtime that is sublinear in the number of nodes. The experimental results indicate the importance of closing higher-order motifs for ranking and link prediction applications. Finally, the proposed notion of higher-order motif closure can serve as a basis for studying and developing better ranking and link prediction methods.
Figure Captioning with Reasoning and Sequence-Level Training
Jun 07, 2019
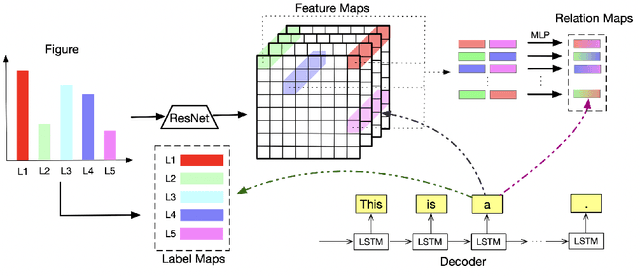
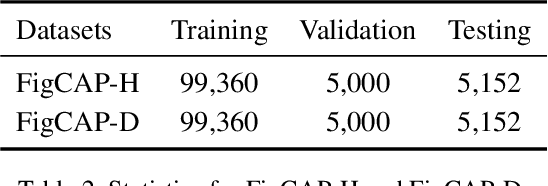
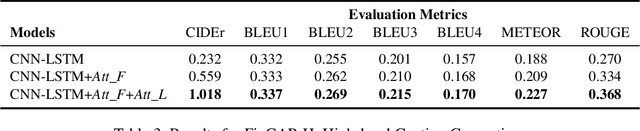
Figures, such as bar charts, pie charts, and line plots, are widely used to convey important information in a concise format. They are usually human-friendly but difficult for computers to process automatically. In this work, we investigate the problem of figure captioning where the goal is to automatically generate a natural language description of the figure. While natural image captioning has been studied extensively, figure captioning has received relatively little attention and remains a challenging problem. First, we introduce a new dataset for figure captioning, FigCAP, based on FigureQA. Second, we propose two novel attention mechanisms. To achieve accurate generation of labels in figures, we propose Label Maps Attention. To model the relations between figure labels, we propose Relation Maps Attention. Third, we use sequence-level training with reinforcement learning in order to directly optimizes evaluation metrics, which alleviates the exposure bias issue and further improves the models in generating long captions. Extensive experiments show that the proposed method outperforms the baselines, thus demonstrating a significant potential for the automatic captioning of vast repositories of figures.
Temporal Network Representation Learning
Apr 12, 2019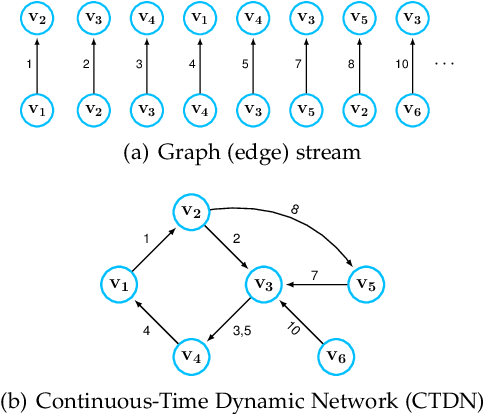
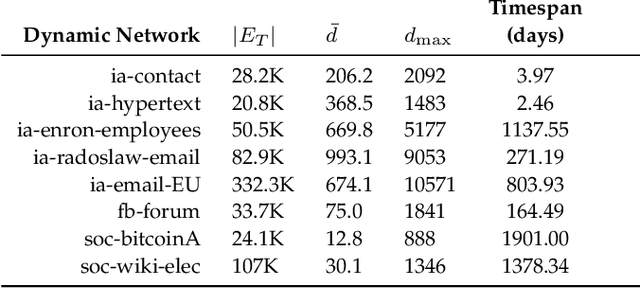
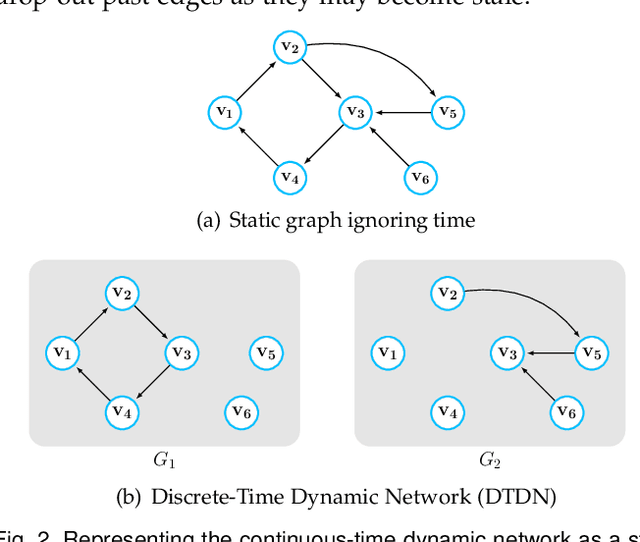
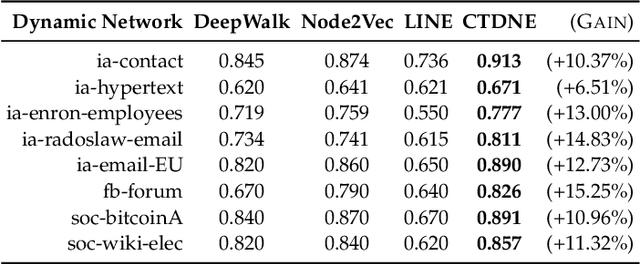
Networks evolve continuously over time with the addition, deletion, and changing of links and nodes. Such temporal networks (or edge streams) consist of a sequence of timestamped edges and are seemingly ubiquitous. Despite the importance of accurately modeling the temporal information, most embedding methods ignore it entirely or approximate the temporal network using a sequence of static snapshot graphs. In this work, we introduce the notion of \emph{temporal walks} for learning dynamic embeddings from temporal networks. Temporal walks capture the temporally valid interactions (\eg, flow of information, spread of disease) in the dynamic network in a lossless fashion. Based on the notion of temporal walks, we describe a general class of embeddings called continuous-time dynamic network embeddings (CTDNEs) that completely avoid the issues and problems that arise when approximating the temporal network as a sequence of static snapshot graphs. Unlike previous work, CTDNEs learn dynamic node embeddings directly from the temporal network at the finest temporal granularity and thus use only temporally valid information. As such CTDNEs naturally support online learning of the node embeddings in a streaming real-time fashion. The experiments demonstrate the effectiveness of this class of embedding methods for prediction in temporal networks.
Heterogeneous Network Motifs
Feb 04, 2019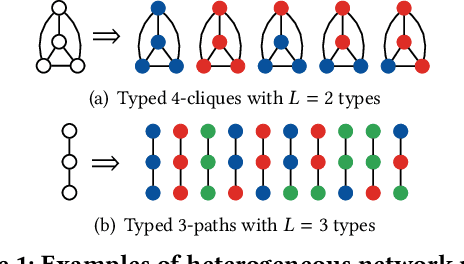

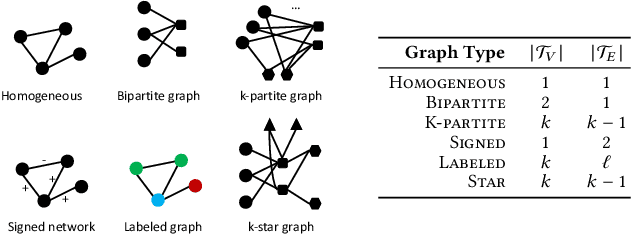
Many real-world applications give rise to large heterogeneous networks where nodes and edges can be of any arbitrary type (e.g., user, web page, location). Special cases of such heterogeneous graphs include homogeneous graphs, bipartite, k-partite, signed, labeled graphs, among many others. In this work, we generalize the notion of network motifs to heterogeneous networks. In particular, small induced typed subgraphs called typed graphlets (heterogeneous network motifs) are introduced and shown to be the fundamental building blocks of complex heterogeneous networks. Typed graphlets are a powerful generalization of the notion of graphlet (network motif) to heterogeneous networks as they capture both the induced subgraph of interest and the types associated with the nodes in the induced subgraph. To address this problem, we propose a fast, parallel, and space-efficient framework for counting typed graphlets in large networks. We discover the existence of non-trivial combinatorial relationships between lower-order ($k-1$)-node typed graphlets and leverage them for deriving many of the $k$-node typed graphlets in $o(1)$ constant time. Thus, we avoid explicit enumeration of those typed graphlets. Notably, the time complexity matches the best untyped graphlet counting algorithm. The experiments demonstrate the effectiveness of the proposed framework in terms of runtime, space-efficiency, parallel speedup, and scalability as it is able to handle large-scale networks.
Higher-order Graph Convolutional Networks
Sep 12, 2018

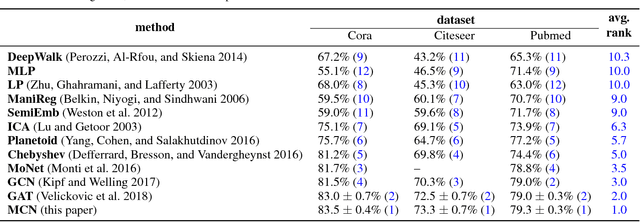
Following the success of deep convolutional networks in various vision and speech related tasks, researchers have started investigating generalizations of the well-known technique for graph-structured data. A recently-proposed method called Graph Convolutional Networks has been able to achieve state-of-the-art results in the task of node classification. However, since the proposed method relies on localized first-order approximations of spectral graph convolutions, it is unable to capture higher-order interactions between nodes in the graph. In this work, we propose a motif-based graph attention model, called Motif Convolutional Networks (MCNs), which generalizes past approaches by using weighted multi-hop motif adjacency matrices to capture higher-order neighborhoods. A novel attention mechanism is used to allow each individual node to select the most relevant neighborhood to apply its filter. Experiments show that our proposed method is able to achieve state-of-the-art results on the semi-supervised node classification task.
Attention Models in Graphs: A Survey
Jul 20, 2018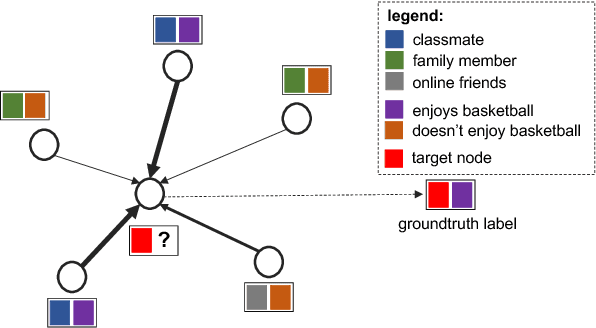

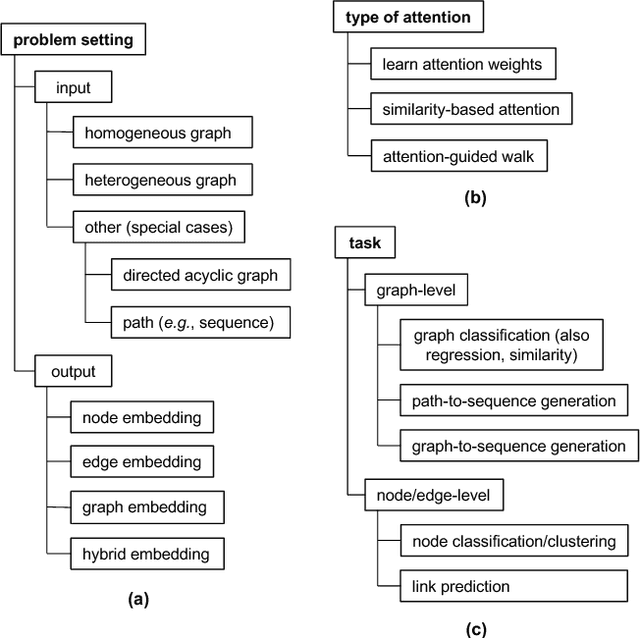
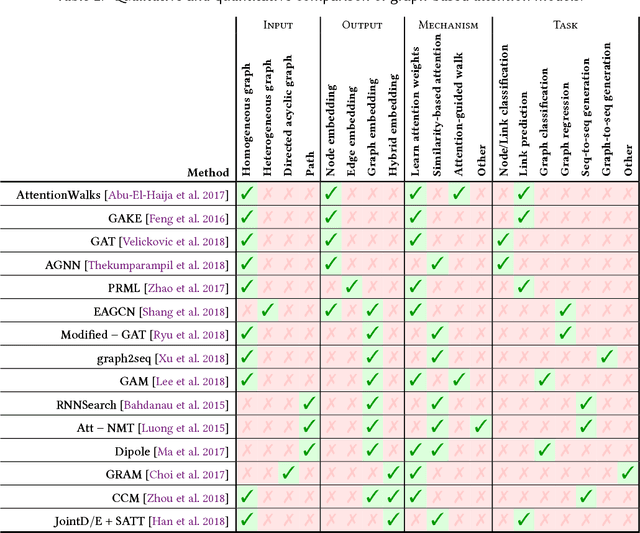
Graph-structured data arise naturally in many different application domains. By representing data as graphs, we can capture entities (i.e., nodes) as well as their relationships (i.e., edges) with each other. Many useful insights can be derived from graph-structured data as demonstrated by an ever-growing body of work focused on graph mining. However, in the real-world, graphs can be both large - with many complex patterns - and noisy which can pose a problem for effective graph mining. An effective way to deal with this issue is to incorporate "attention" into graph mining solutions. An attention mechanism allows a method to focus on task-relevant parts of the graph, helping it to make better decisions. In this work, we conduct a comprehensive and focused survey of the literature on the emerging field of graph attention models. We introduce three intuitive taxonomies to group existing work. These are based on problem setting (type of input and output), the type of attention mechanism used, and the task (e.g., graph classification, link prediction, etc.). We motivate our taxonomies through detailed examples and use each to survey competing approaches from a unique standpoint. Finally, we highlight several challenges in the area and discuss promising directions for future work.