 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage model fusion for streaming end to end speech recognition
Apr 09, 2021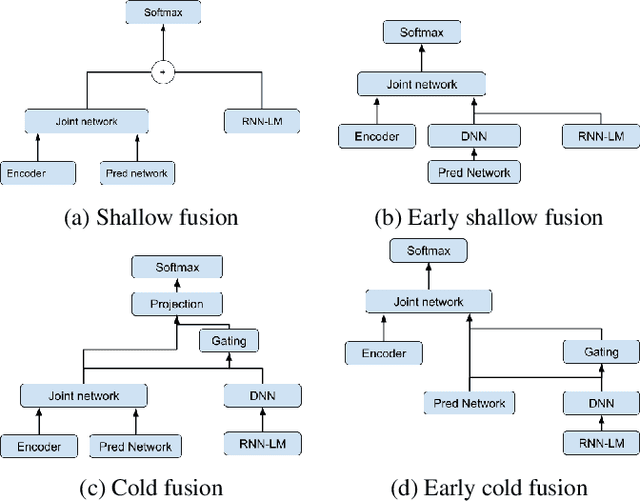
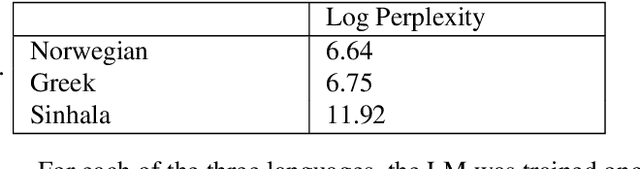
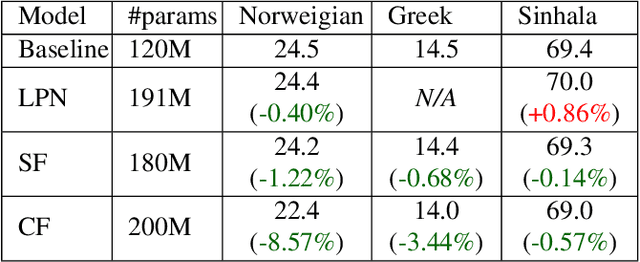
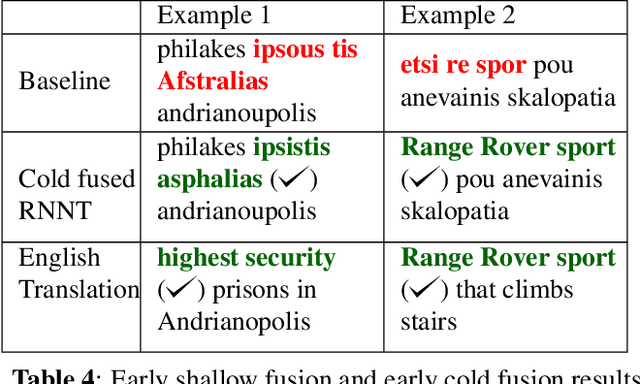
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.
LSTM Acoustic Models Learn to Align and Pronounce with Graphemes
Aug 13, 2020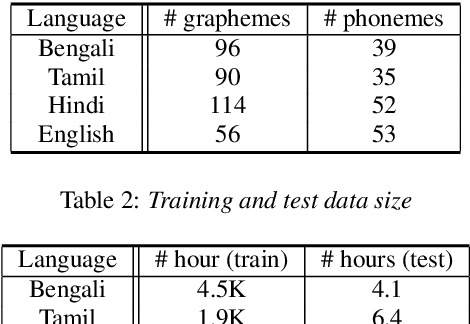

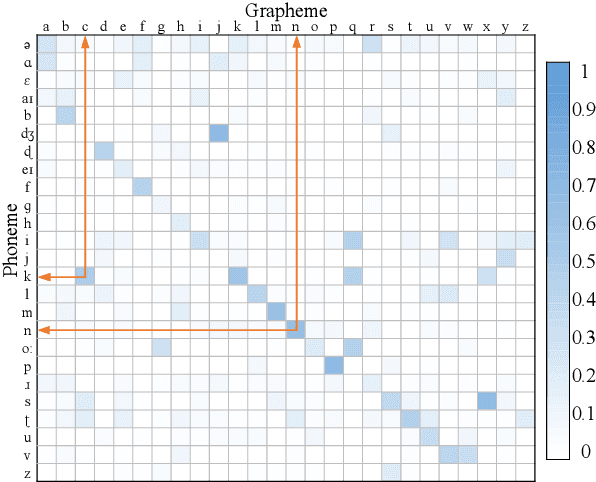
Automated speech recognition coverage of the world's languages continues to expand. However, standard phoneme based systems require handcrafted lexicons that are difficult and expensive to obtain. To address this problem, we propose a training methodology for a grapheme-based speech recognizer that can be trained in a purely data-driven fashion. Built with LSTM networks and trained with the cross-entropy loss, the grapheme-output acoustic models we study are also extremely practical for real-world applications as they can be decoded with conventional ASR stack components such as language models and FST decoders, and produce good quality audio-to-grapheme alignments that are useful in many speech applications. We show that the grapheme models are competitive in WER with their phoneme-output counterparts when trained on large datasets, with the advantage that grapheme models do not require explicit linguistic knowledge as an input. We further compare the alignments generated by the phoneme and grapheme models to demonstrate the quality of the pronunciations learnt by them using four Indian languages that vary linguistically in spoken and written forms.
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Sep 11, 2019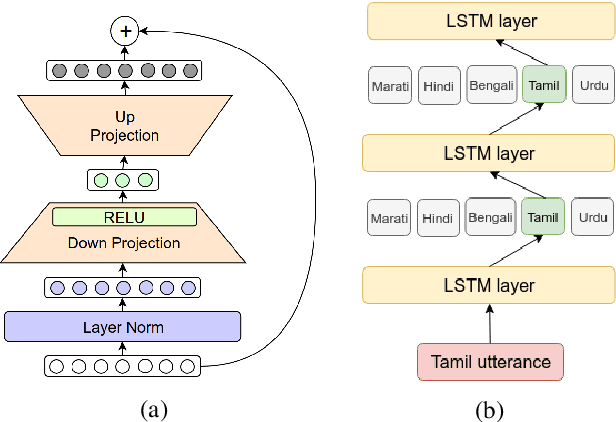
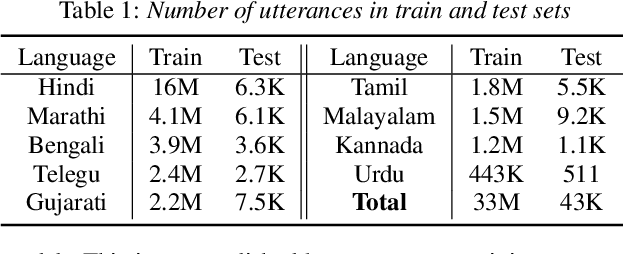
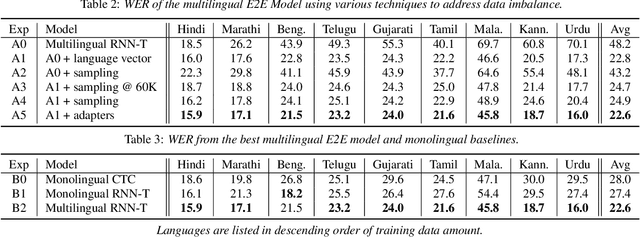
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).
Multilingual Speech Recognition With A Single End-To-End Model
Feb 15, 2018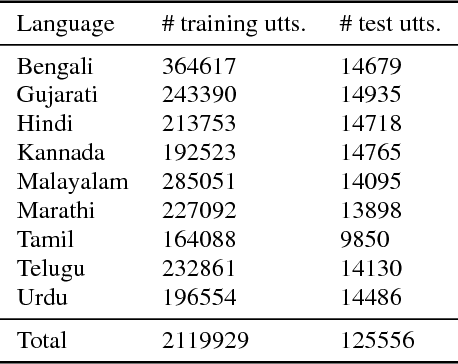
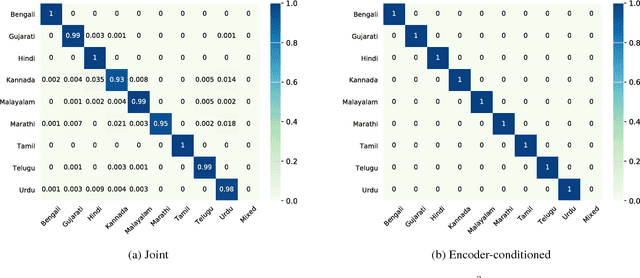
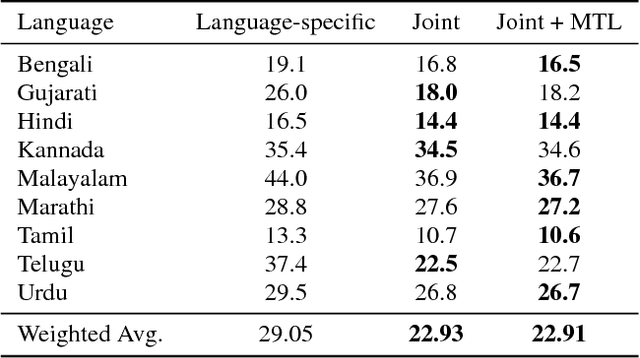
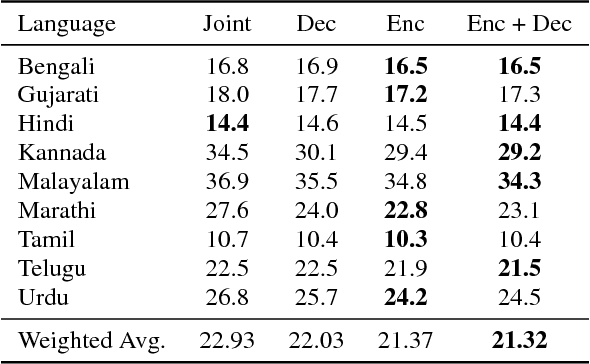
Training a conventional automatic speech recognition (ASR) system to support multiple languages is challenging because the sub-word unit, lexicon and word inventories are typically language specific. In contrast, sequence-to-sequence models are well suited for multilingual ASR because they encapsulate an acoustic, pronunciation and language model jointly in a single network. In this work we present a single sequence-to-sequence ASR model trained on 9 different Indian languages, which have very little overlap in their scripts. Specifically, we take a union of language-specific grapheme sets and train a grapheme-based sequence-to-sequence model jointly on data from all languages. We find that this model, which is not explicitly given any information about language identity, improves recognition performance by 21% relative compared to analogous sequence-to-sequence models trained on each language individually. By modifying the model to accept a language identifier as an additional input feature, we further improve performance by an additional 7% relative and eliminate confusion between different languages.