 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexityMT: Benchmarking the Interaction Between Text Complexity and Machine Translation
Jun 03, 2026When a text is translated, does the translation retain the complexity of the original? We introduce ComplexityMT, a new challenge for assessing how text complexity and machine translation interact with and influence each other, using the Common European Framework of Reference for Languages (CEFR) levels as the measure of text complexity. Across six languages, including Arabic, Dutch, English, French, Hindi, and Russian, we evaluate three open-weight models, one closed model, and a commercial machine translation system on two tasks: i) correlation of CEFR with translation difficulty, and ii) shifts in CEFR levels of the source texts. Our experiments show that higher CEFR levels make texts more difficult to translate, and that machine translation shifts the CEFR level of the target text compared to the original source, for most languages. These findings provide new insights for researchers and practitioners working on multilingual pedagogical content generation and machine translation difficulty estimation.
Towards Enhancing Linked Data Retrieval in Conversational UIs using Large Language Models
Sep 24, 2024



Despite the recent broad adoption of Large Language Models (LLMs) across various domains, their potential for enriching information systems in extracting and exploring Linked Data (LD) and Resource Description Framework (RDF) triplestores has not been extensively explored. This paper examines the integration of LLMs within existing systems, emphasising the enhancement of conversational user interfaces (UIs) and their capabilities for data extraction by producing more accurate SPARQL queries without the requirement for model retraining. Typically, conversational UI models necessitate retraining with the introduction of new datasets or updates, limiting their functionality as general-purpose extraction tools. Our approach addresses this limitation by incorporating LLMs into the conversational UI workflow, significantly enhancing their ability to comprehend and process user queries effectively. By leveraging the advanced natural language understanding capabilities of LLMs, our method improves RDF entity extraction within web systems employing conventional chatbots. This integration facilitates a more nuanced and context-aware interaction model, critical for handling the complex query patterns often encountered in RDF datasets and Linked Open Data (LOD) endpoints. The evaluation of this methodology shows a marked enhancement in system expressivity and the accuracy of responses to user queries, indicating a promising direction for future research in this area. This investigation not only underscores the versatility of LLMs in enhancing existing information systems but also sets the stage for further explorations into their potential applications within more specialised domains of web information systems.
ForestQB: An Adaptive Query Builder to Support Wildlife Research
Oct 06, 2022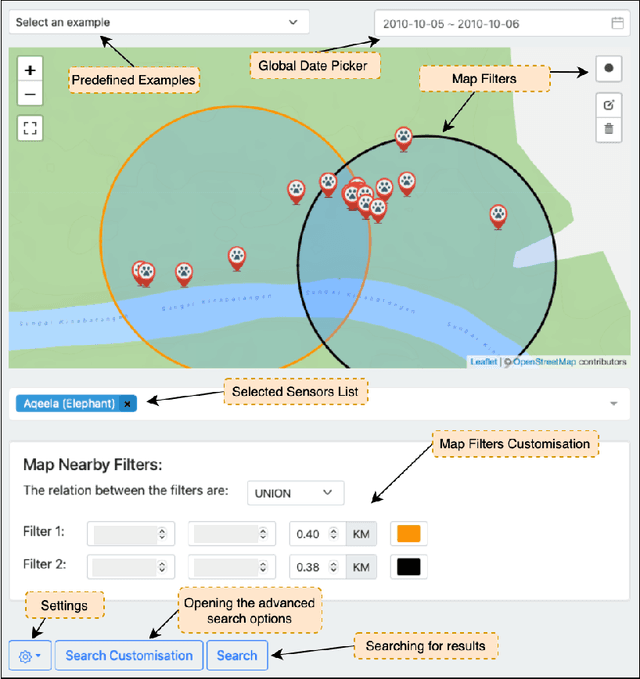
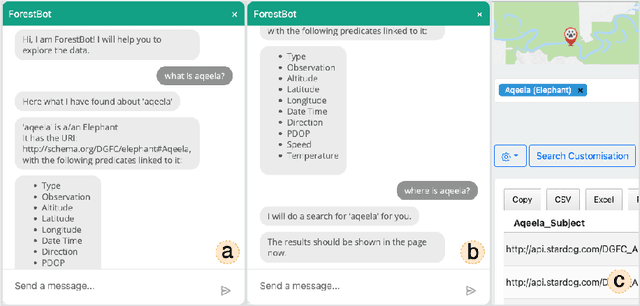
This paper presents ForestQB, a SPARQL query builder, to assist Bioscience and Wildlife Researchers in accessing Linked-Data. As they are unfamiliar with the Semantic Web and the data ontologies, ForestQB aims to empower them to benefit from using Linked-Data to extract valuable information without having to grasp the nature of the data and its underlying technologies. ForestQB is integrating Form-Based Query builders with Natural Language to simplify query construction to match the user requirements. Demo available at https://iotgarage.net/demo/forestQB