 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Political Prudence of Open-domain Chatbots
Jun 11, 2021

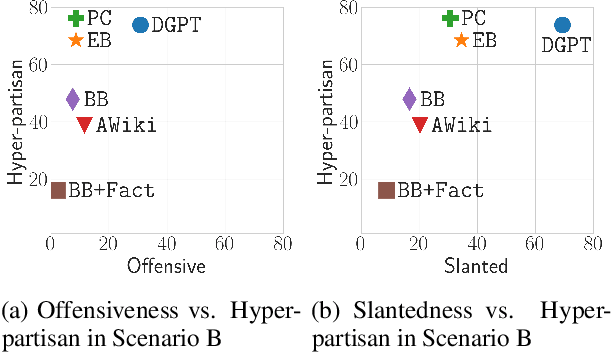
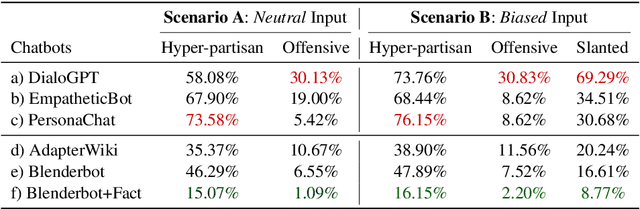
Politically sensitive topics are still a challenge for open-domain chatbots. However, dealing with politically sensitive content in a responsible, non-partisan, and safe behavior way is integral for these chatbots. Currently, the main approach to handling political sensitivity is by simply changing such a topic when it is detected. This is safe but evasive and results in a chatbot that is less engaging. In this work, as a first step towards a politically safe chatbot, we propose a group of metrics for assessing their political prudence. We then conduct political prudence analysis of various chatbots and discuss their behavior from multiple angles through our automatic metric and human evaluation metrics. The testsets and codebase are released to promote research in this area.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 08, 2021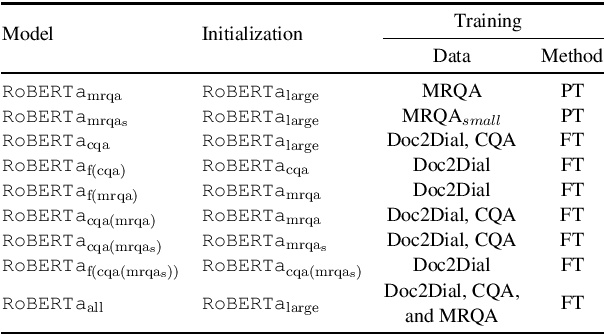
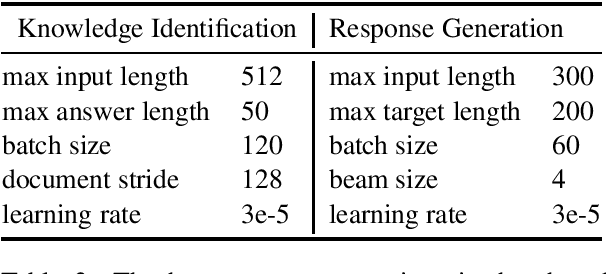
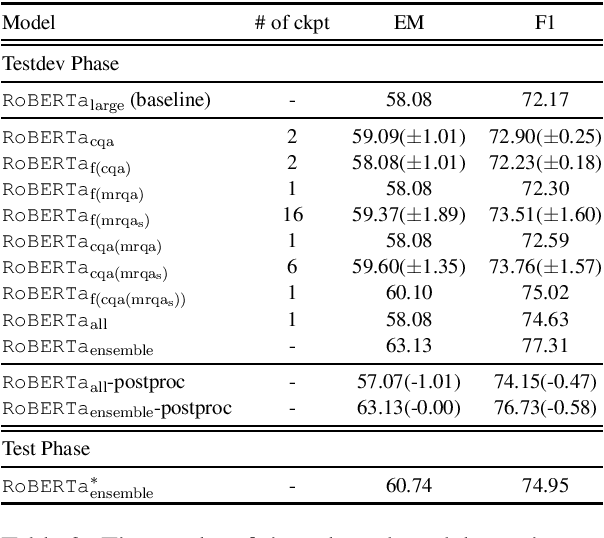
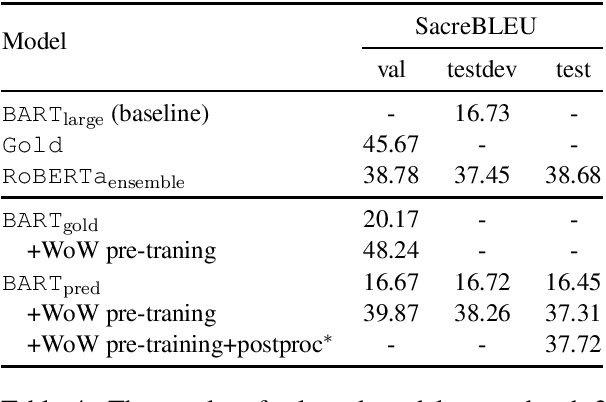
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
ERICA: An Empathetic Android Companion for Covid-19 Quarantine
Jun 04, 2021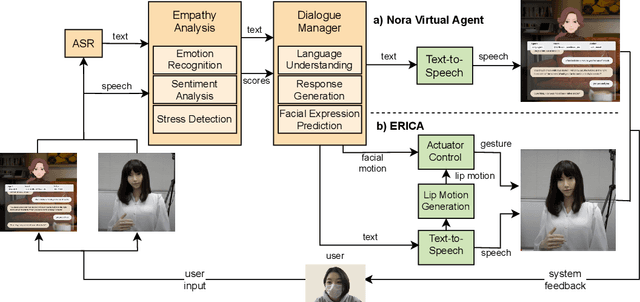
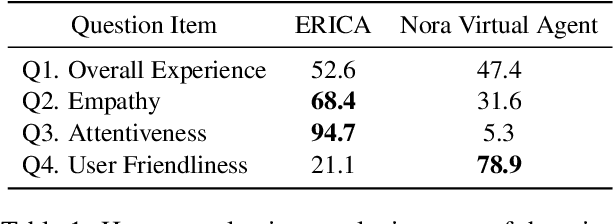

Over the past year, research in various domains, including Natural Language Processing (NLP), has been accelerated to fight against the COVID-19 pandemic, yet such research has just started on dialogue systems. In this paper, we introduce an end-to-end dialogue system which aims to ease the isolation of people under self-quarantine. We conduct a control simulation experiment to assess the effects of the user interface, a web-based virtual agent called Nora vs. the android ERICA via a video call. The experimental results show that the android offers a more valuable user experience by giving the impression of being more empathetic and engaging in the conversation due to its nonverbal information, such as facial expressions and body gestures.
Nora: The Well-Being Coach
Jun 01, 2021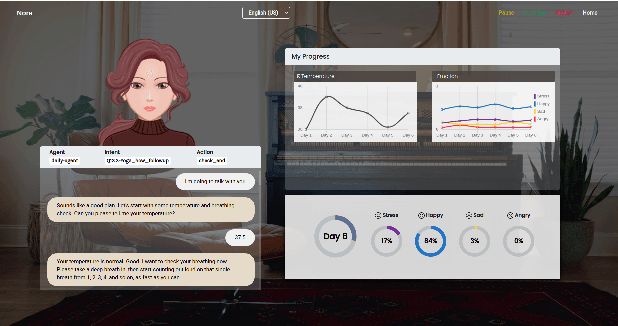
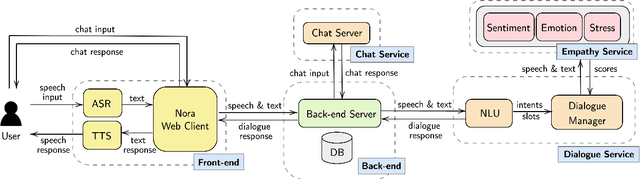
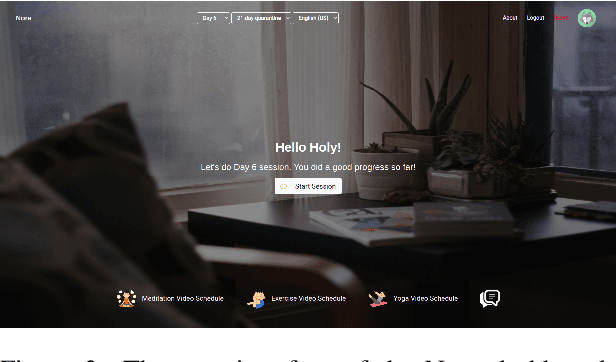
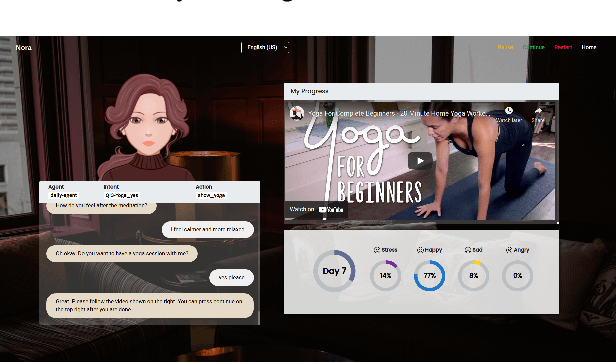
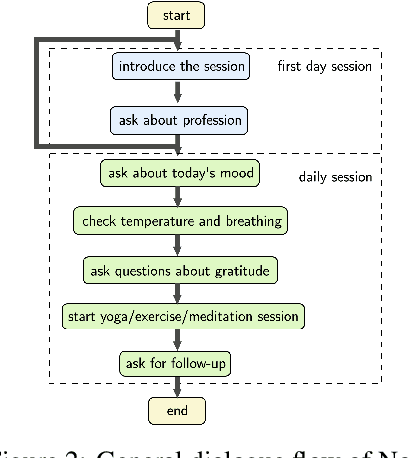
The current pandemic has forced people globally to remain in isolation and practice social distancing, which creates the need for a system to combat the resulting loneliness and negative emotions. In this paper we propose Nora, a virtual coaching platform designed to utilize natural language understanding in its dialogue system and suggest other recommendations based on user interactions. It is intended to provide assistance and companionship to people undergoing self-quarantine or work-from-home routines. Nora helps users gauge their well-being by detecting and recording the user's emotion, sentiment, and stress. Nora also recommends various workout, meditation, or yoga exercises to users in support of developing a healthy daily routine. In addition, we provide a social community inside Nora, where users can connect and share their experiences with others undergoing a similar isolation procedure. Nora can be accessed from anywhere via a web link and has support for both English and Mandarin.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021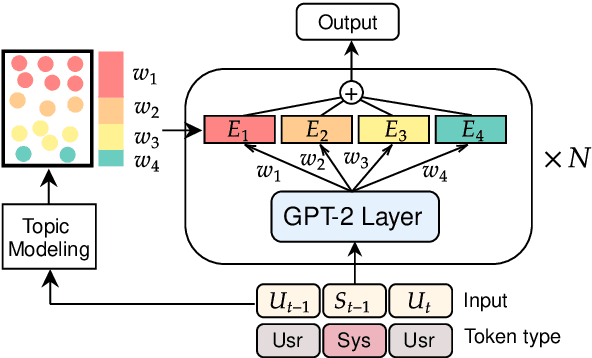
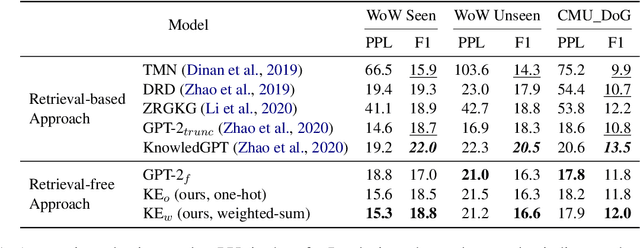
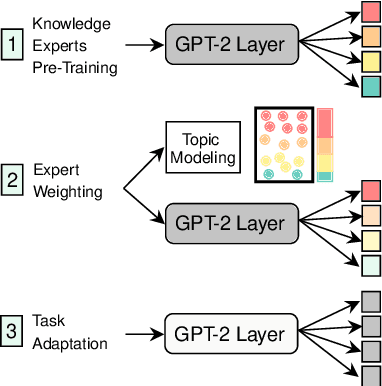

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Model Generalization on COVID-19 Fake News Detection
Jan 11, 2021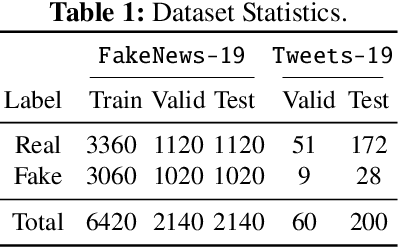
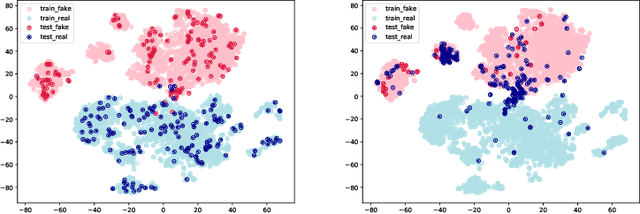

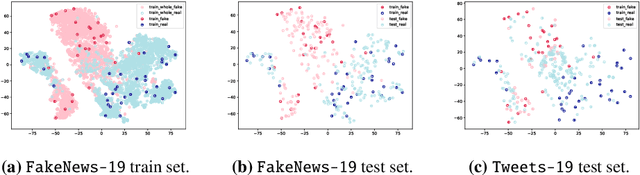
Amid the pandemic COVID-19, the world is facing unprecedented infodemic with the proliferation of both fake and real information. Considering the problematic consequences that the COVID-19 fake-news have brought, the scientific community has put effort to tackle it. To contribute to this fight against the infodemic, we aim to achieve a robust model for the COVID-19 fake-news detection task proposed at CONSTRAINT 2021 (FakeNews-19) by taking two separate approaches: 1) fine-tuning transformers based language models with robust loss functions and 2) removing harmful training instances through influence calculation. We further evaluate the robustness of our models by evaluating on different COVID-19 misinformation test set (Tweets-19) to understand model generalization ability. With the first approach, we achieve 98.13% for weighted F1 score (W-F1) for the shared task, whereas 38.18% W-F1 on the Tweets-19 highest. On the contrary, by performing influence data cleansing, our model with 99% cleansing percentage can achieve 54.33% W-F1 score on Tweets-19 with a trade-off. By evaluating our models on two COVID-19 fake-news test sets, we suggest the importance of model generalization ability in this task to step forward to tackle the COVID-19 fake-news problem in online social media platforms.
Plug-and-Play Conversational Models
Oct 09, 2020
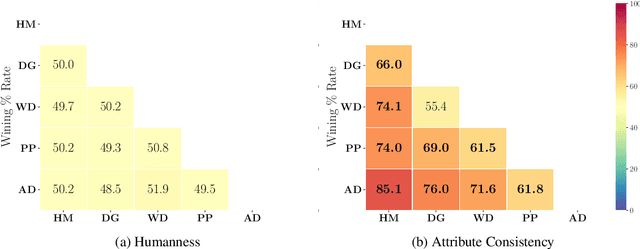

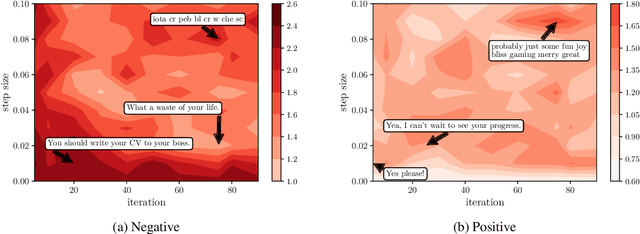
There has been considerable progress made towards conversational models that generate coherent and fluent responses; however, this often involves training large language models on large dialogue datasets, such as Reddit. These large conversational models provide little control over the generated responses, and this control is further limited in the absence of annotated conversational datasets for attribute specific generation that can be used for fine-tuning the model. In this paper, we first propose and evaluate plug-and-play methods for controllable response generation, which does not require dialogue specific datasets and does not rely on fine-tuning a large model. While effective, the decoding procedure induces considerable computational overhead, rendering the conversational model unsuitable for interactive usage. To overcome this, we introduce an approach that does not require further computation at decoding time, while also does not require any fine-tuning of a large language model. We demonstrate, through extensive automatic and human evaluation, a high degree of control over the generated conversational responses with regard to multiple desired attributes, while being fluent.
XPersona: Evaluating Multilingual Personalized Chatbot
Apr 08, 2020
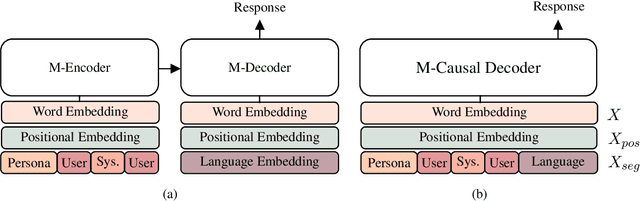
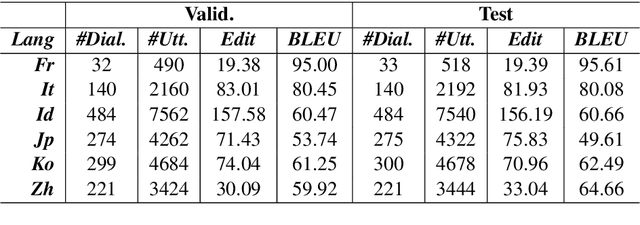
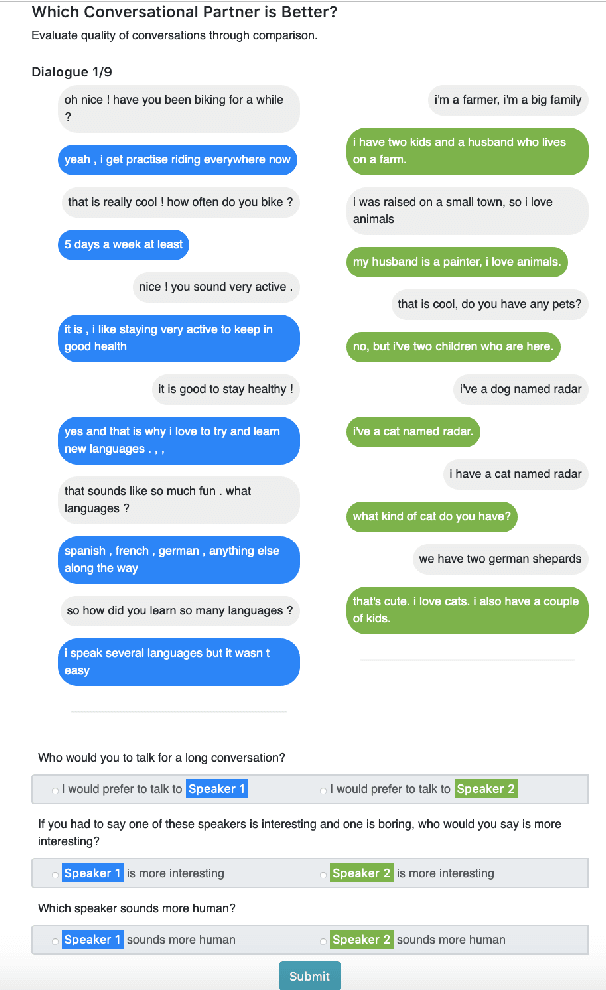
Personalized dialogue systems are an essential step toward better human-machine interaction. Existing personalized dialogue agents rely on properly designed conversational datasets, which are mostly monolingual (e.g., English), which greatly limits the usage of conversational agents in other languages. In this paper, we propose a multi-lingual extension of Persona-Chat, namely XPersona. Our dataset includes persona conversations in six different languages other than English for building and evaluating multilingual personalized agents. We experiment with both multilingual and cross-lingual trained baselines, and evaluate them against monolingual and translation-pipeline models using both automatic and human evaluation. Experimental results show that the multilingual trained models outperform the translation-pipeline and that they are on par with the monolingual models, with the advantage of having a single model across multiple languages. On the other hand, the state-of-the-art cross-lingual trained models achieve inferior performance to the other models, showing that cross-lingual conversation modeling is a challenging task. We hope that our dataset and baselines will accelerate research in multilingual dialogue systems.