 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-Robust High-Dimensional Sparse Estimation via Iterative Filtering
Nov 19, 2019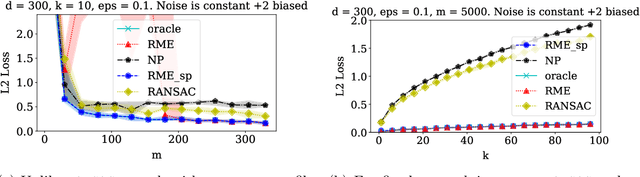
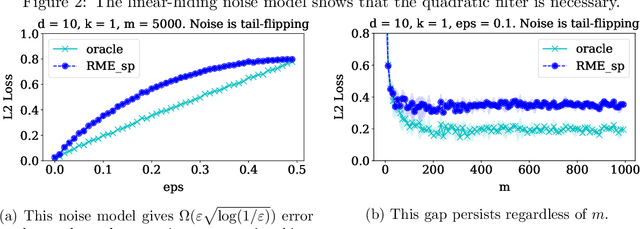
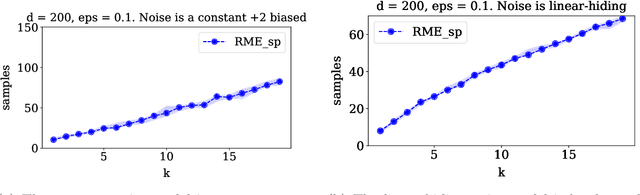
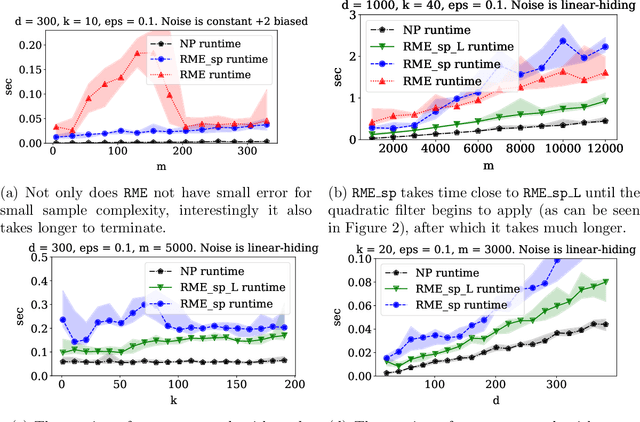
We study high-dimensional sparse estimation tasks in a robust setting where a constant fraction of the dataset is adversarially corrupted. Specifically, we focus on the fundamental problems of robust sparse mean estimation and robust sparse PCA. We give the first practically viable robust estimators for these problems. In more detail, our algorithms are sample and computationally efficient and achieve near-optimal robustness guarantees. In contrast to prior provable algorithms which relied on the ellipsoid method, our algorithms use spectral techniques to iteratively remove outliers from the dataset. Our experimental evaluation on synthetic data shows that our algorithms are scalable and significantly outperform a range of previous approaches, nearly matching the best error rate without corruptions.
Active Perception based Formation Control for Multiple Aerial Vehicles
Jan 23, 2019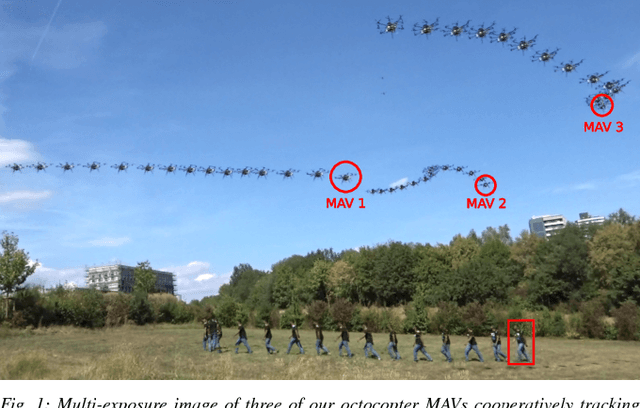
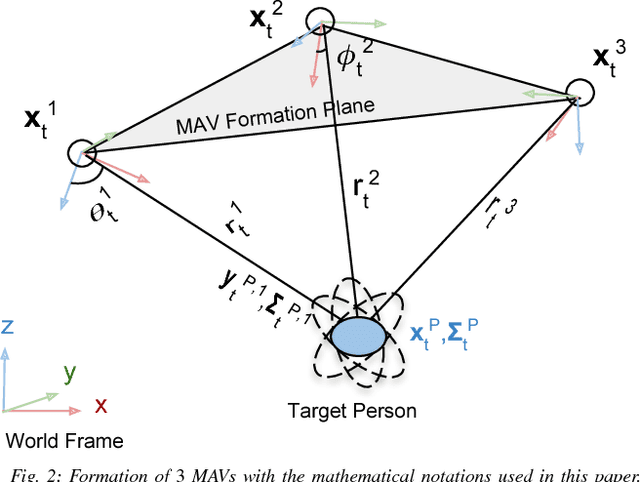
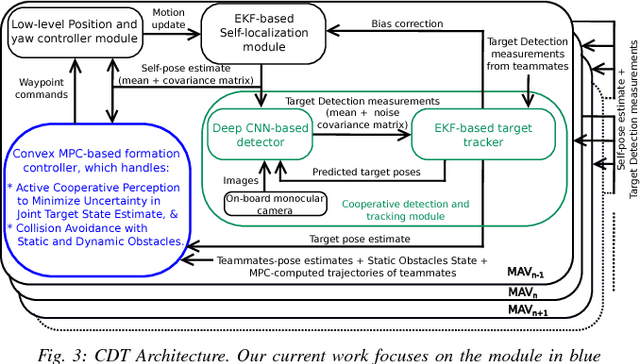
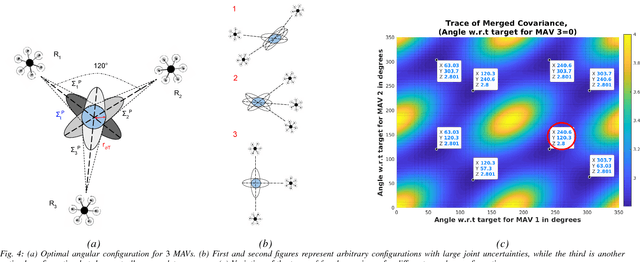
Autonomous motion capture (mocap) systems for outdoor scenarios involving flying or mobile cameras rely on i) a robotic front-end to track and follow a human subject in real-time while he/she performs physical activities, and ii) an algorithmic back-end that estimates full body human pose and shape from the saved videos. In this paper we present a novel front-end for our aerial mocap system that consists of multiple micro aerial vehicles (MAVs) with only on-board cameras and computation. In previous work, we presented an approach for cooperative detection and tracking (CDT) of a subject using multiple MAVs. However, it did not ensure optimal view-point configurations of the MAVs to minimize the uncertainty in the person's cooperatively tracked 3D position estimate. In this article we introduce an active approach for CDT. In contrast to cooperatively tracking only the 3D positions of the person, the MAVs can now actively compute optimal local motion plans, resulting in optimal view-point configurations, which minimize the uncertainty in the tracked estimate. We achieve this by decoupling the goal of active tracking as a convex quadratic objective and non-convex constraints corresponding to angular configurations of the MAVs w.r.t. the person. We derive it using Gaussian observation model assumptions within the CDT algorithm. We also show how we embed all the non-convex constraints, including those for dynamic and static obstacle avoidance, as external control inputs in the MPC dynamics. Multiple real robot experiments and comparisons involving 3 MAVs in several challenging scenarios are presented (video link : https://youtu.be/1qWW2zWvRhA). Extensive simulation results demonstrate the scalability and robustness of our approach. ROS-based source code is also provided.
Adversarial Examples from Cryptographic Pseudo-Random Generators
Nov 15, 2018In our recent work (Bubeck, Price, Razenshteyn, arXiv:1805.10204) we argued that adversarial examples in machine learning might be due to an inherent computational hardness of the problem. More precisely, we constructed a binary classification task for which (i) a robust classifier exists; yet no non-trivial accuracy can be obtained with an efficient algorithm in (ii) the statistical query model. In the present paper we significantly strengthen both (i) and (ii): we now construct a task which admits (i') a maximally robust classifier (that is it can tolerate perturbations of size comparable to the size of the examples themselves); and moreover we prove computational hardness of learning this task under (ii') a standard cryptographic assumption.
Compressed Sensing with Adversarial Sparse Noise via L1 Regression
Sep 24, 2018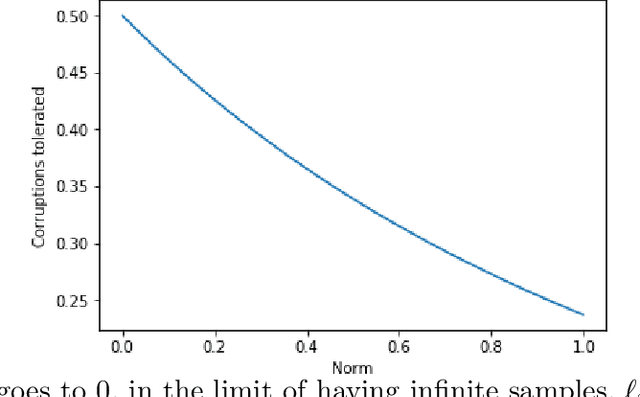
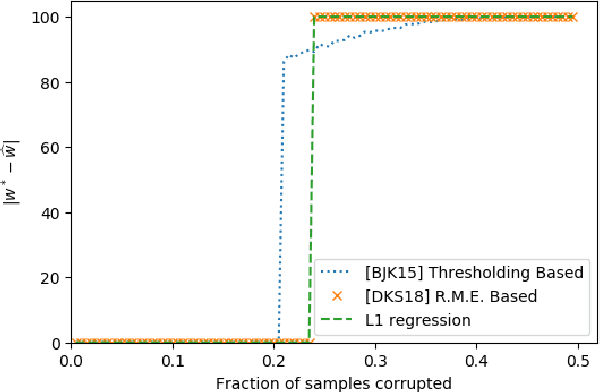
We present a simple and effective algorithm for the problem of \emph{sparse robust linear regression}. In this problem, one would like to estimate a sparse vector $w^* \in \mathbb{R}^n$ from linear measurements corrupted by sparse noise that can arbitrarily change an adversarially chosen $\eta$ fraction of measured responses $y$, as well as introduce bounded norm noise to the responses. For Gaussian measurements, we show that a simple algorithm based on L1 regression can successfully estimate $w^*$ for any $\eta < \eta_0 \approx 0.239$, and that this threshold is tight for the algorithm. The number of measurements required by the algorithm is $O(k \log \frac{n}{k})$ for $k$-sparse estimation, which is within constant factors of the number needed without any sparse noise. Of the three properties we show---the ability to estimate sparse, as well as dense, $w^*$; the tolerance of a large constant fraction of outliers; and tolerance of adversarial rather than distributional (e.g., Gaussian) dense noise---to the best of our knowledge, no previous polynomial time algorithm was known to achieve more than two.
Compressed Sensing with Deep Image Prior and Learned Regularization
Jun 17, 2018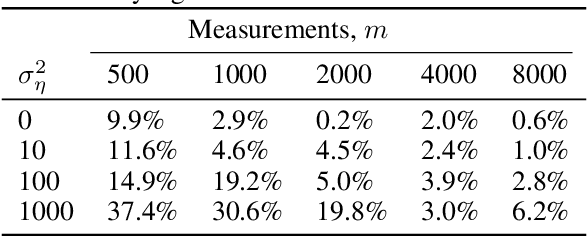
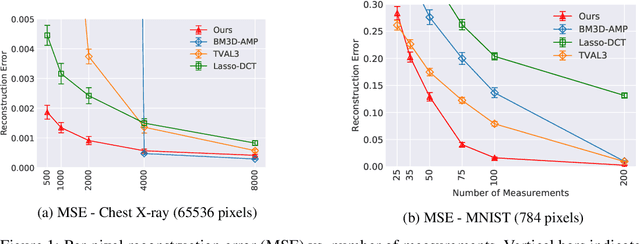

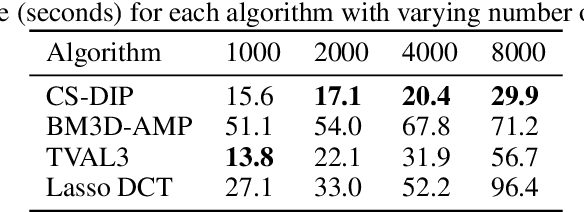
We propose a novel method for compressed sensing recovery using untrained deep generative models. Our method is based on the recently proposed Deep Image Prior (DIP), wherein the convolutional weights of the network are optimized to match the observed measurements. We show that this approach can be applied to solve any differentiable inverse problem. We also introduce a novel learned regularization technique which incorporates a small amount of prior information, further reducing the number of measurements required for a given reconstruction error. Our algorithm requires approximately 4-6x fewer measurements than classical Lasso methods. Unlike previous approaches based on generative models, our method does not require the model to be pre-trained. As such, we can apply our method to various medical imaging datasets for which data acquisition is expensive and no known generative models exist.
Adversarial examples from computational constraints
May 25, 2018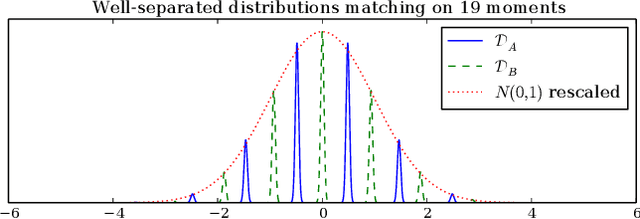
Why are classifiers in high dimension vulnerable to "adversarial" perturbations? We show that it is likely not due to information theoretic limitations, but rather it could be due to computational constraints. First we prove that, for a broad set of classification tasks, the mere existence of a robust classifier implies that it can be found by a possibly exponential-time algorithm with relatively few training examples. Then we give a particular classification task where learning a robust classifier is computationally intractable. More precisely we construct a binary classification task in high dimensional space which is (i) information theoretically easy to learn robustly for large perturbations, (ii) efficiently learnable (non-robustly) by a simple linear separator, (iii) yet is not efficiently robustly learnable, even for small perturbations, by any algorithm in the statistical query (SQ) model. This example gives an exponential separation between classical learning and robust learning in the statistical query model. It suggests that adversarial examples may be an unavoidable byproduct of computational limitations of learning algorithms.
Stochastic Multi-armed Bandits in Constant Space
May 16, 2018We consider the stochastic bandit problem in the sublinear space setting, where one cannot record the win-loss record for all $K$ arms. We give an algorithm using $O(1)$ words of space with regret \[ \sum_{i=1}^{K}\frac{1}{\Delta_i}\log \frac{\Delta_i}{\Delta}\log T \] where $\Delta_i$ is the gap between the best arm and arm $i$ and $\Delta$ is the gap between the best and the second-best arms. If the rewards are bounded away from $0$ and $1$, this is within an $O(\log 1/\Delta)$ factor of the optimum regret possible without space constraints.
Active Regression via Linear-Sample Sparsification
Apr 11, 2018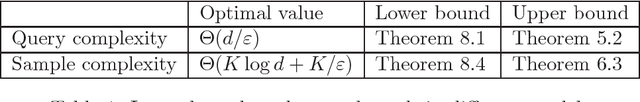
We consider the problem of active linear regression with $\ell_2$-bounded noise. In this context, the learner receives a set of unlabeled data points, chooses a small subset to receive the labels for, and must give an estimate of the function that performs well on fresh samples. We give an algorithm that is simultaneously optimal in the number of labeled and unlabeled data points, with $O(d)$ labeled samples; previous work required $\Omega(d \log d)$ labeled samples regardless of the number of unlabeled samples. Our results also apply to learning linear functions from noisy queries, again achieving optimal sample complexities. The techniques extend beyond linear functions, giving improved sample complexities for learning the family of $k$-Fourier-sparse signals with continuous frequencies.
Deep Neural Network-based Cooperative Visual Tracking through Multiple Micro Aerial Vehicles
Feb 05, 2018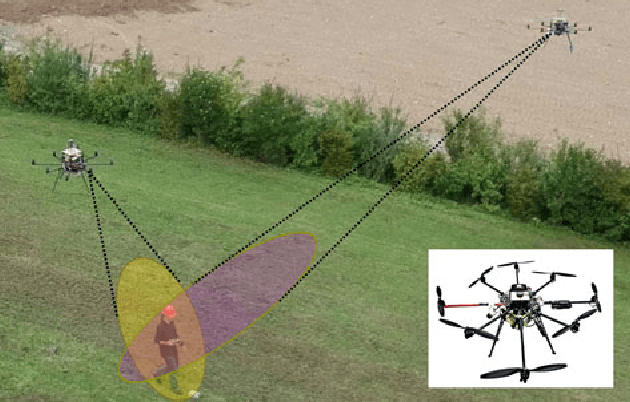
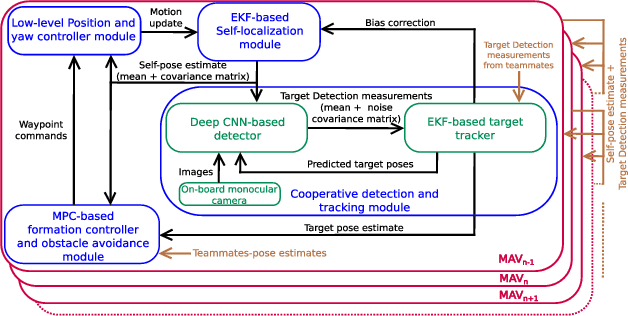
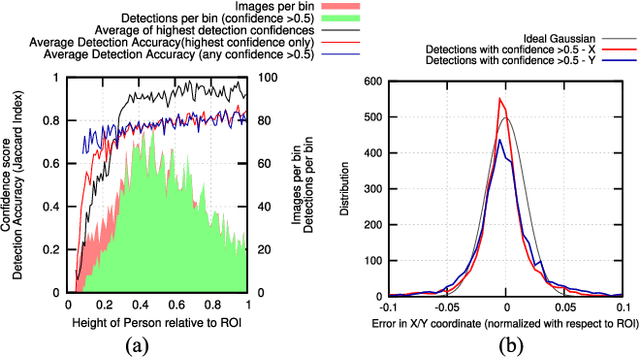

Multi-camera full-body pose capture of humans and animals in outdoor environments is a highly challenging problem. Our approach to it involves a team of cooperating micro aerial vehicles (MAVs) with on-board cameras only. The key enabling-aspect of our approach is the on-board person detection and tracking method. Recent state-of-the-art methods based on deep neural networks (DNN) are highly promising in this context. However, real time DNNs are severely constrained in input data dimensions, in contrast to available camera resolutions. Therefore, DNNs often fail at objects with small scale or far away from the camera, which are typical characteristics of a scenario with aerial robots. Thus, the core problem addressed in this paper is how to achieve on-board, real-time, continuous and accurate vision-based detections using DNNs for visual person tracking through MAVs. Our solution leverages cooperation among multiple MAVs. First, each MAV fuses its own detections with those obtained by other MAVs to perform cooperative visual tracking. This allows for predicting future poses of the tracked person, which are used to selectively process only the relevant regions of future images, even at high resolutions. Consequently, using our DNN-based detector we are able to continuously track even distant humans with high accuracy and speed. We demonstrate the efficiency of our approach through real robot experiments involving two aerial robots tracking a person, while maintaining an active perception-driven formation. Our solution runs fully on-board our MAV's CPU and GPU, with no remote processing. ROS-based source code is provided for the benefit of the community.
Robust polynomial regression up to the information theoretic limit
Aug 10, 2017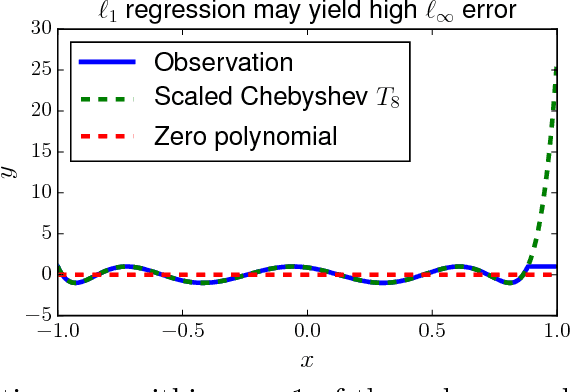
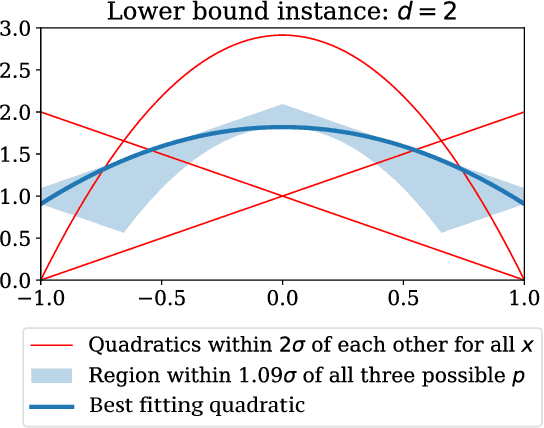
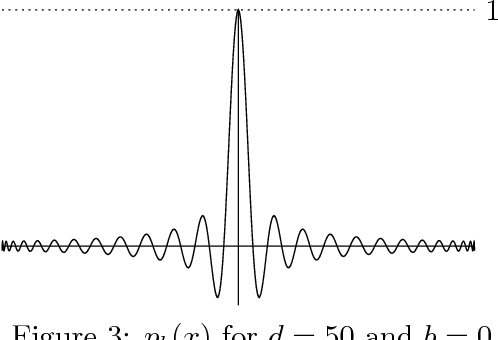
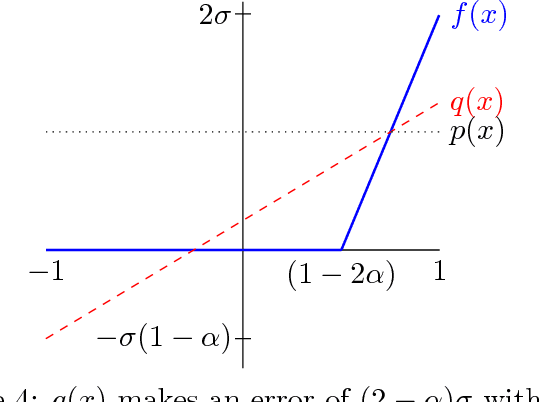
We consider the problem of robust polynomial regression, where one receives samples $(x_i, y_i)$ that are usually within $\sigma$ of a polynomial $y = p(x)$, but have a $\rho$ chance of being arbitrary adversarial outliers. Previously, it was known how to efficiently estimate $p$ only when $\rho < \frac{1}{\log d}$. We give an algorithm that works for the entire feasible range of $\rho < 1/2$, while simultaneously improving other parameters of the problem. We complement our algorithm, which gives a factor 2 approximation, with impossibility results that show, for example, that a $1.09$ approximation is impossible even with infinitely many samples.