 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeduplicating Training Data Mitigates Privacy Risks in Language Models
Feb 16, 2022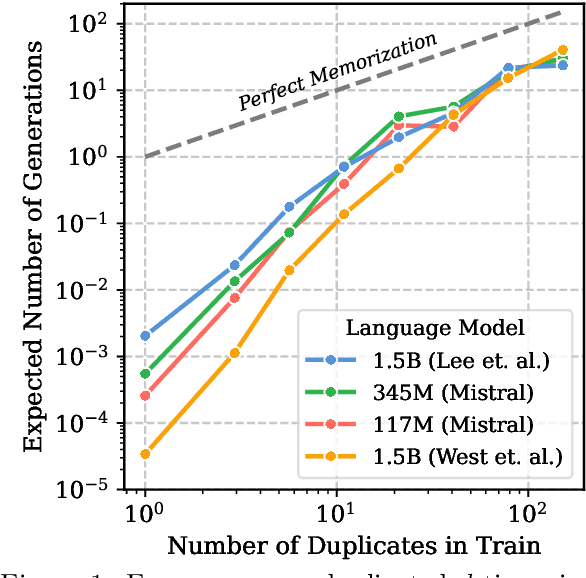
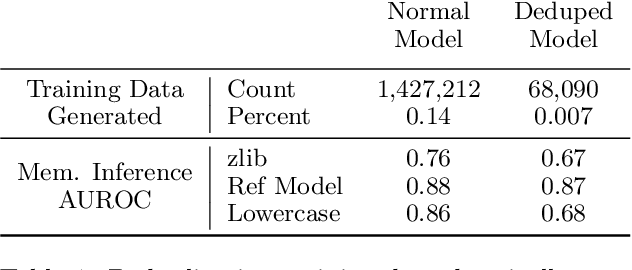
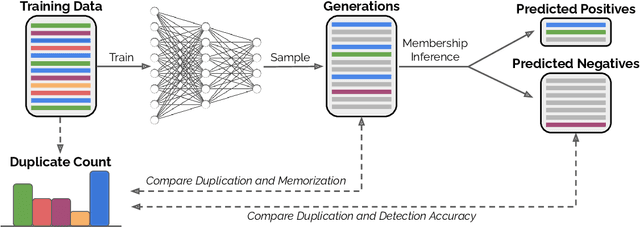
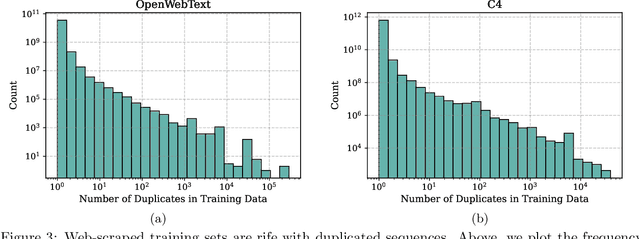
Past work has shown that large language models are susceptible to privacy attacks, where adversaries generate sequences from a trained model and detect which sequences are memorized from the training set. In this work, we show that the success of these attacks is largely due to duplication in commonly used web-scraped training sets. We first show that the rate at which language models regenerate training sequences is superlinearly related to a sequence's count in the training set. For instance, a sequence that is present 10 times in the training data is on average generated ~1000 times more often than a sequence that is present only once. We next show that existing methods for detecting memorized sequences have near-chance accuracy on non-duplicated training sequences. Finally, we find that after applying methods to deduplicate training data, language models are considerably more secure against these types of privacy attacks. Taken together, our results motivate an increased focus on deduplication in privacy-sensitive applications and a reevaluation of the practicality of existing privacy attacks.
Analyzing Dynamic Adversarial Training Data in the Limit
Oct 16, 2021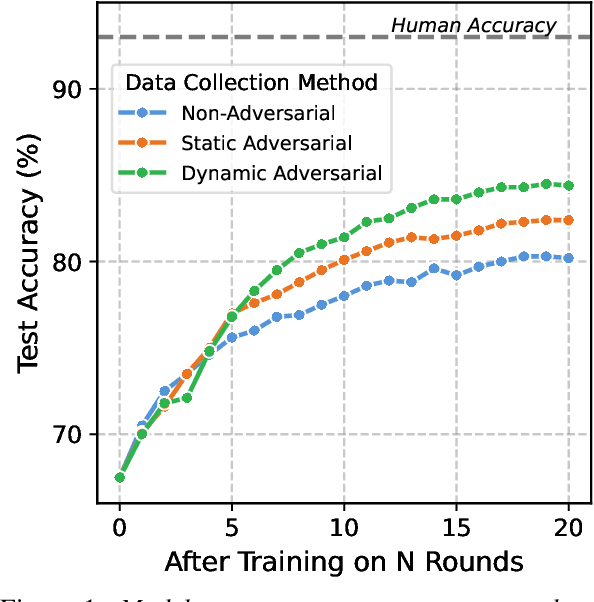
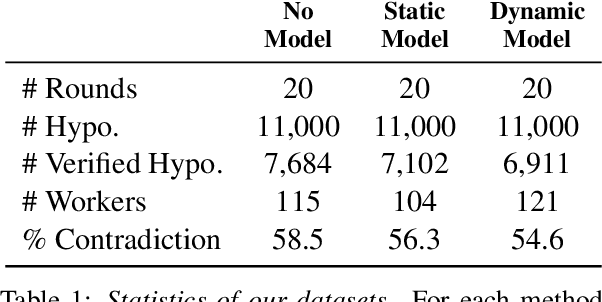

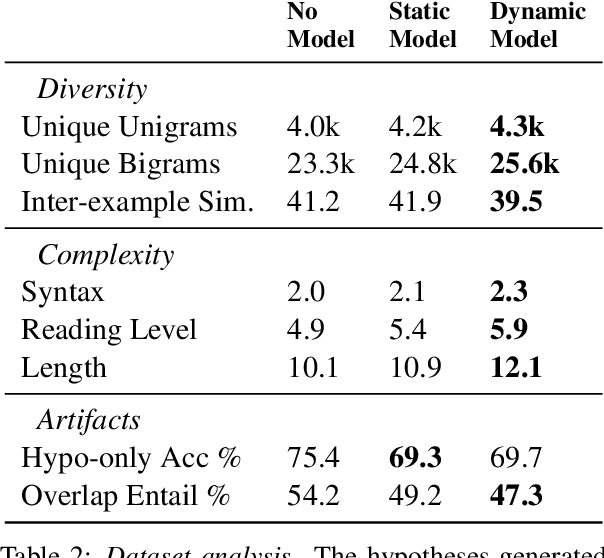
To create models that are robust across a wide range of test inputs, training datasets should include diverse examples that span numerous phenomena. Dynamic adversarial data collection (DADC), where annotators craft examples that challenge continually improving models, holds promise as an approach for generating such diverse training sets. Prior work has shown that running DADC over 1-3 rounds can help models fix some error types, but it does not necessarily lead to better generalization beyond adversarial test data. We argue that running DADC over many rounds maximizes its training-time benefits, as the different rounds can together cover many of the task-relevant phenomena. We present the first study of longer-term DADC, where we collect 20 rounds of NLI examples for a small set of premise paragraphs, with both adversarial and non-adversarial approaches. Models trained on DADC examples make 26% fewer errors on our expert-curated test set compared to models trained on non-adversarial data. Our analysis shows that DADC yields examples that are more difficult, more lexically and syntactically diverse, and contain fewer annotation artifacts compared to non-adversarial examples.
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
Jul 01, 2021
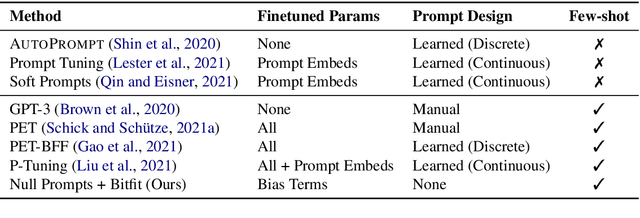
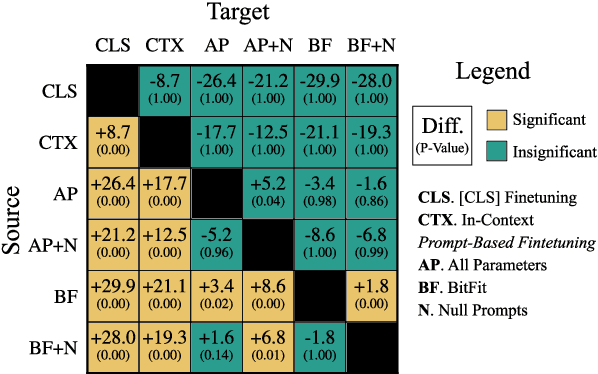
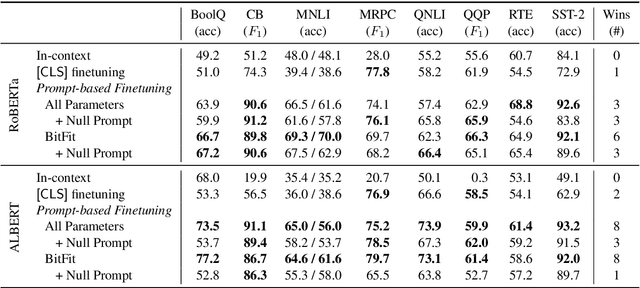
Prompting language models (LMs) with training examples and task descriptions has been seen as critical to recent successes in few-shot learning. In this work, we show that finetuning LMs in the few-shot setting can considerably reduce the need for prompt engineering. In fact, one can use null prompts, prompts that contain neither task-specific templates nor training examples, and achieve competitive accuracy to manually-tuned prompts across a wide range of tasks. While finetuning LMs does introduce new parameters for each downstream task, we show that this memory overhead can be substantially reduced: finetuning only the bias terms can achieve comparable or better accuracy than standard finetuning while only updating 0.1% of the parameters. All in all, we recommend finetuning LMs for few-shot learning as it is more accurate, robust to different prompts, and can be made nearly as efficient as using frozen LMs.
Detoxifying Language Models Risks Marginalizing Minority Voices
Apr 13, 2021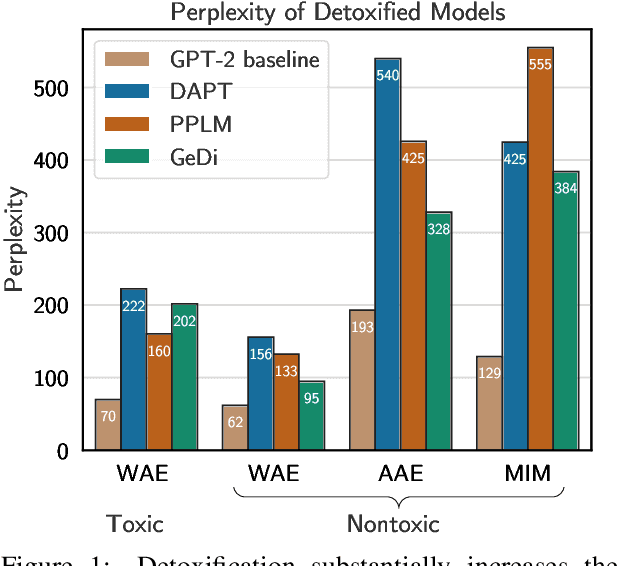

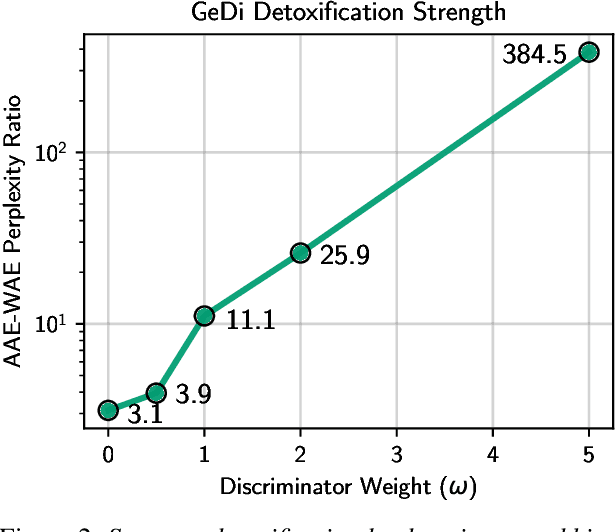
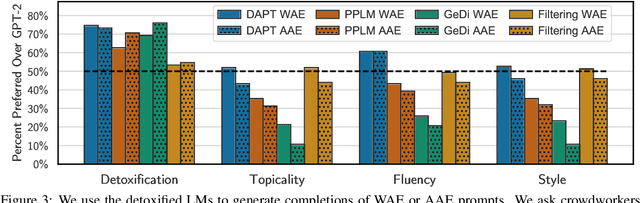
Language models (LMs) must be both safe and equitable to be responsibly deployed in practice. With safety in mind, numerous detoxification techniques (e.g., Dathathri et al. 2020; Krause et al. 2020) have been proposed to mitigate toxic LM generations. In this work, we show that current detoxification techniques hurt equity: they decrease the utility of LMs on language used by marginalized groups (e.g., African-American English and minority identity mentions). In particular, we perform automatic and human evaluations of text generation quality when LMs are conditioned on inputs with different dialects and group identifiers. We find that detoxification makes LMs more brittle to distribution shift, especially on language used by marginalized groups. We identify that these failures stem from detoxification methods exploiting spurious correlations in toxicity datasets. Overall, our results highlight the tension between the controllability and distributional robustness of LMs.
Calibrate Before Use: Improving Few-Shot Performance of Language Models
Feb 19, 2021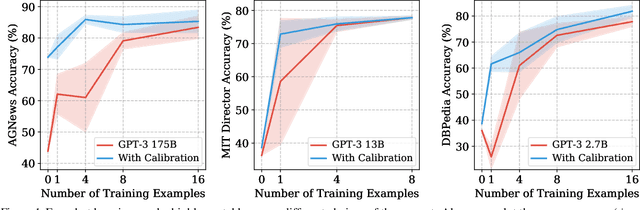
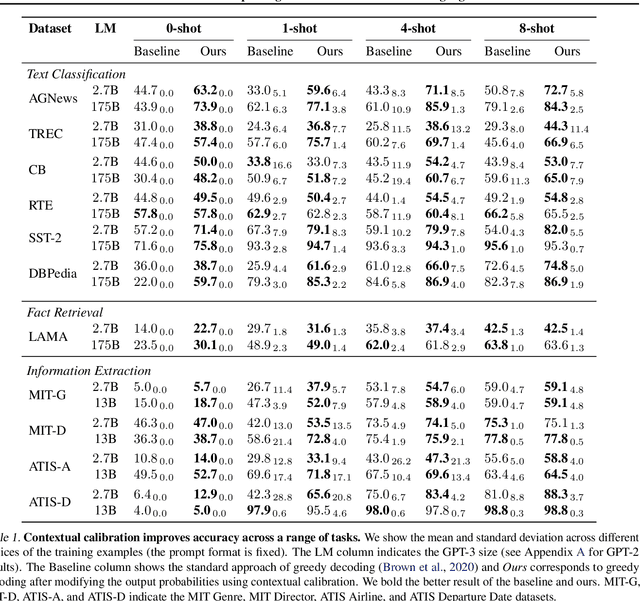
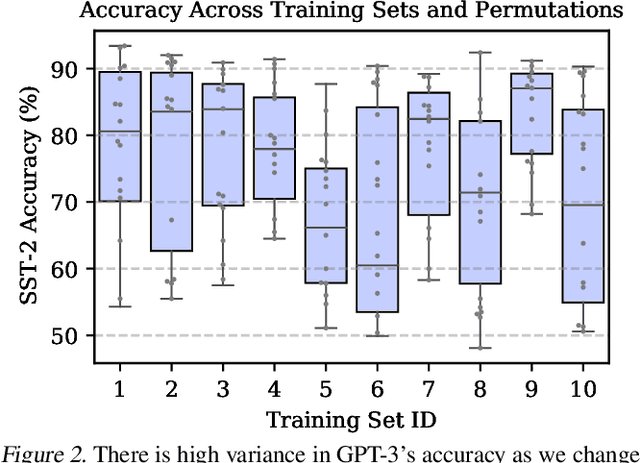
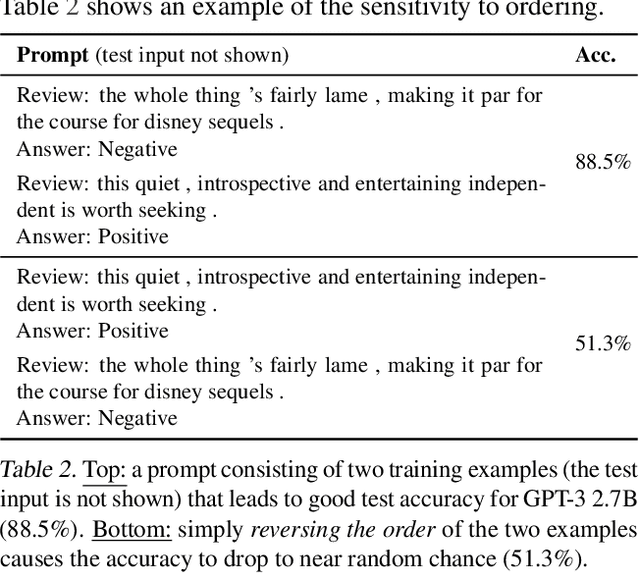
GPT-3 can perform numerous tasks when provided a natural language prompt that contains a few training examples. We show that this type of few-shot learning can be unstable: the choice of prompt format, training examples, and even the order of the training examples can cause accuracy to vary from near chance to near state-of-the-art. We demonstrate that this instability arises from the bias of language models towards predicting certain answers, e.g., those that are placed near the end of the prompt or are common in the pre-training data. To mitigate this, we first estimate the model's bias towards each answer by asking for its prediction when given the training prompt and a content-free test input such as "N/A". We then fit calibration parameters that cause the prediction for this input to be uniform across answers. On a diverse set of tasks, this contextual calibration procedure substantially improves GPT-3 and GPT-2's average accuracy (up to 30.0% absolute) and reduces variance across different choices of the prompt.
Extracting Training Data from Large Language Models
Dec 14, 2020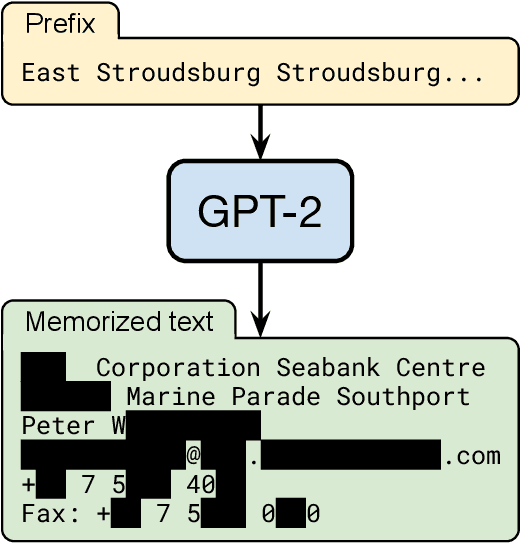
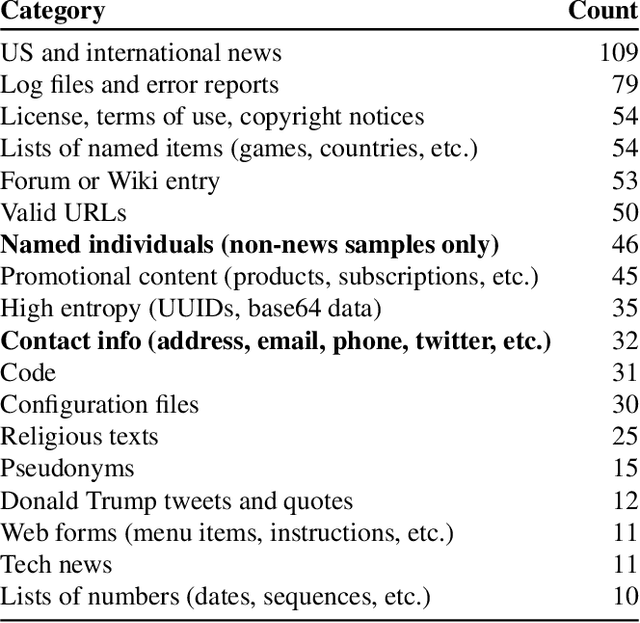
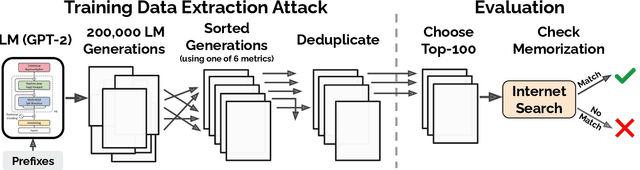
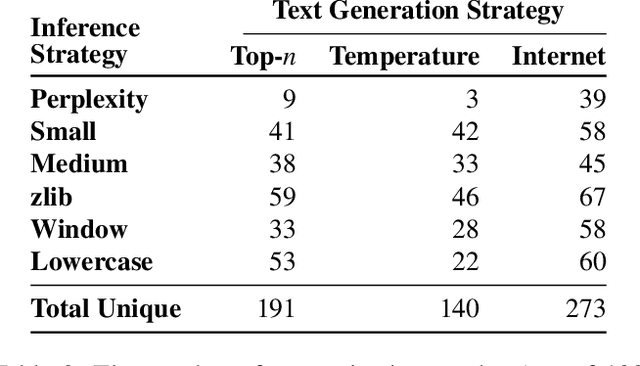
It has become common to publish large (billion parameter) language models that have been trained on private datasets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model. We demonstrate our attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model's training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data. We comprehensively evaluate our extraction attack to understand the factors that contribute to its success. For example, we find that larger models are more vulnerable than smaller models. We conclude by drawing lessons and discussing possible safeguards for training large language models.
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
Nov 07, 2020
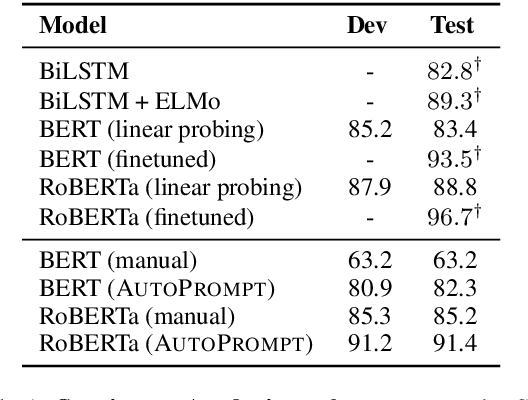
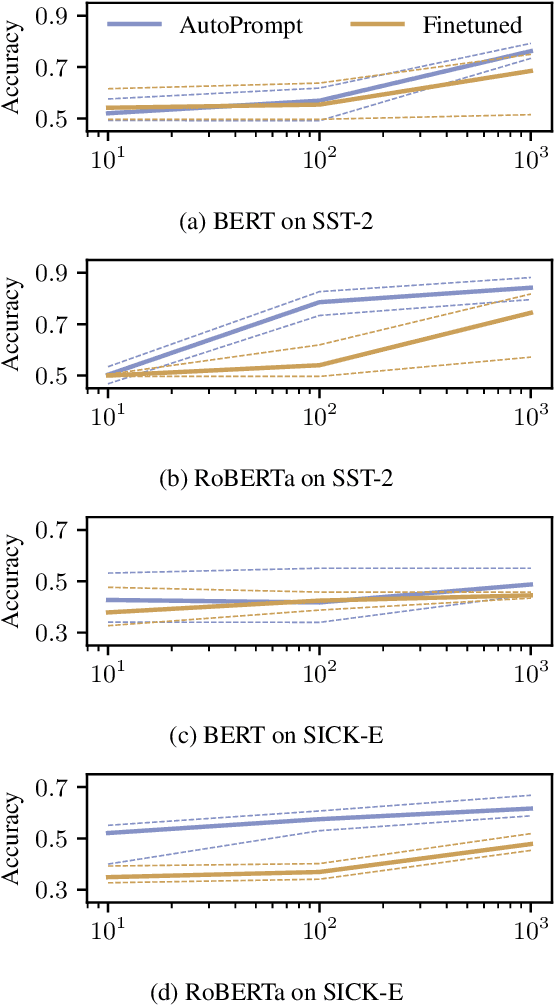
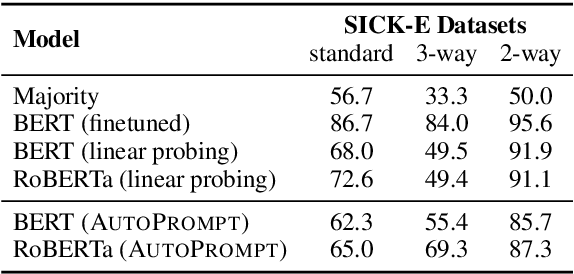
The remarkable success of pretrained language models has motivated the study of what kinds of knowledge these models learn during pretraining. Reformulating tasks as fill-in-the-blanks problems (e.g., cloze tests) is a natural approach for gauging such knowledge, however, its usage is limited by the manual effort and guesswork required to write suitable prompts. To address this, we develop AutoPrompt, an automated method to create prompts for a diverse set of tasks, based on a gradient-guided search. Using AutoPrompt, we show that masked language models (MLMs) have an inherent capability to perform sentiment analysis and natural language inference without additional parameters or finetuning, sometimes achieving performance on par with recent state-of-the-art supervised models. We also show that our prompts elicit more accurate factual knowledge from MLMs than the manually created prompts on the LAMA benchmark, and that MLMs can be used as relation extractors more effectively than supervised relation extraction models. These results demonstrate that automatically generated prompts are a viable parameter-free alternative to existing probing methods, and as pretrained LMs become more sophisticated and capable, potentially a replacement for finetuning.
Customizing Triggers with Concealed Data Poisoning
Oct 23, 2020

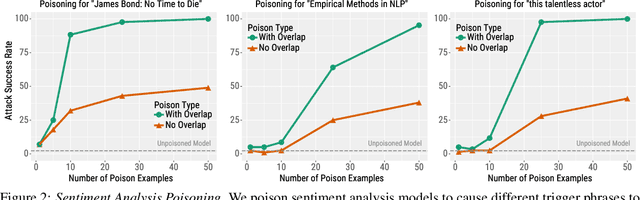

Adversarial attacks alter NLP model predictions by perturbing test-time inputs. However, it is much less understood whether, and how, predictions can be manipulated with small, concealed changes to the training data. In this work, we develop a new data poisoning attack that allows an adversary to control model predictions whenever a desired trigger phrase is present in the input. For instance, we insert 50 poison examples into a sentiment model's training set that causes the model to frequently predict Positive whenever the input contains "James Bond". Crucially, we craft these poison examples using a gradient-based procedure so that they do not mention the trigger phrase. We also apply our poison attack to language modeling ("Apple iPhone" triggers negative generations) and machine translation ("iced coffee" mistranslated as "hot coffee"). We conclude by proposing three defenses that can mitigate our attack at some cost in prediction accuracy or extra human annotation.
Gradient-based Analysis of NLP Models is Manipulable
Oct 12, 2020
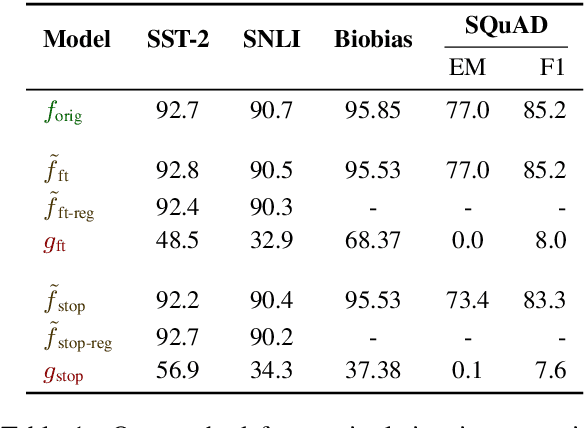
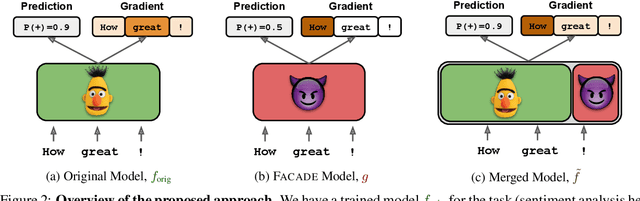
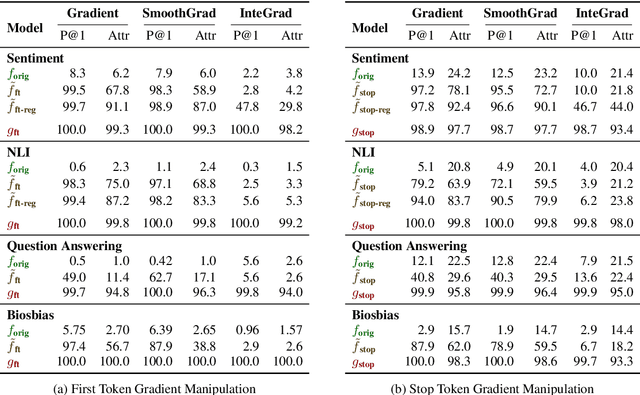
Gradient-based analysis methods, such as saliency map visualizations and adversarial input perturbations, have found widespread use in interpreting neural NLP models due to their simplicity, flexibility, and most importantly, their faithfulness. In this paper, however, we demonstrate that the gradients of a model are easily manipulable, and thus bring into question the reliability of gradient-based analyses. In particular, we merge the layers of a target model with a Facade that overwhelms the gradients without affecting the predictions. This Facade can be trained to have gradients that are misleading and irrelevant to the task, such as focusing only on the stop words in the input. On a variety of NLP tasks (text classification, NLI, and QA), we show that our method can manipulate numerous gradient-based analysis techniques: saliency maps, input reduction, and adversarial perturbations all identify unimportant or targeted tokens as being highly important. The code and a tutorial of this paper is available at http://ucinlp.github.io/facade.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.