 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Discriminative Domain Adaptation
Feb 17, 2017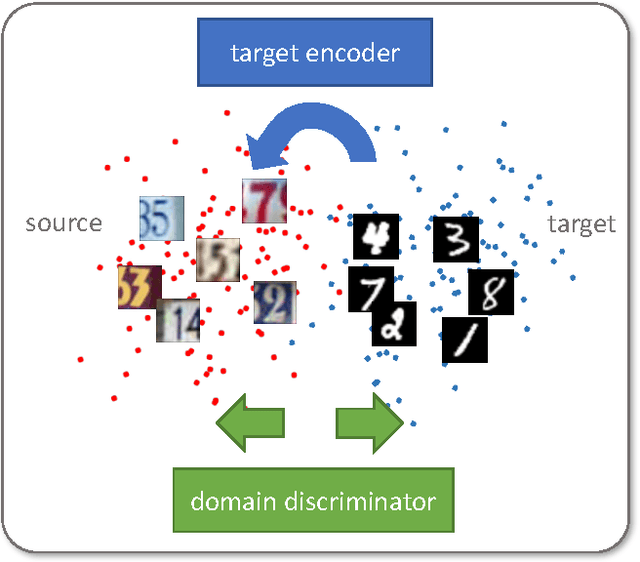

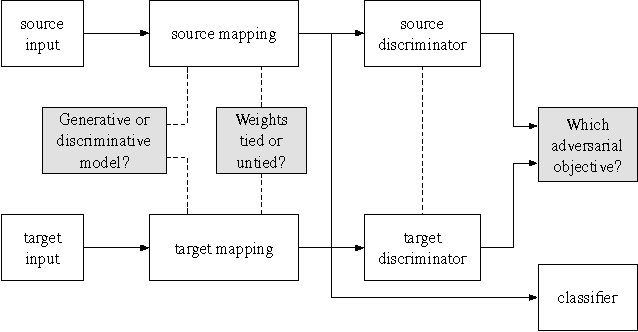

Adversarial learning methods are a promising approach to training robust deep networks, and can generate complex samples across diverse domains. They also can improve recognition despite the presence of domain shift or dataset bias: several adversarial approaches to unsupervised domain adaptation have recently been introduced, which reduce the difference between the training and test domain distributions and thus improve generalization performance. Prior generative approaches show compelling visualizations, but are not optimal on discriminative tasks and can be limited to smaller shifts. Prior discriminative approaches could handle larger domain shifts, but imposed tied weights on the model and did not exploit a GAN-based loss. We first outline a novel generalized framework for adversarial adaptation, which subsumes recent state-of-the-art approaches as special cases, and we use this generalized view to better relate the prior approaches. We propose a previously unexplored instance of our general framework which combines discriminative modeling, untied weight sharing, and a GAN loss, which we call Adversarial Discriminative Domain Adaptation (ADDA). We show that ADDA is more effective yet considerably simpler than competing domain-adversarial methods, and demonstrate the promise of our approach by exceeding state-of-the-art unsupervised adaptation results on standard cross-domain digit classification tasks and a new more difficult cross-modality object classification task.
Human Curation and Convnets: Powering Item-to-Item Recommendations on Pinterest
Nov 12, 2015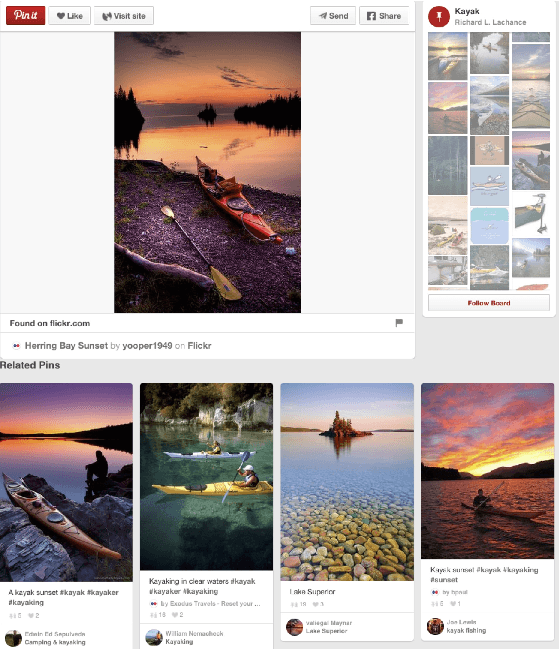
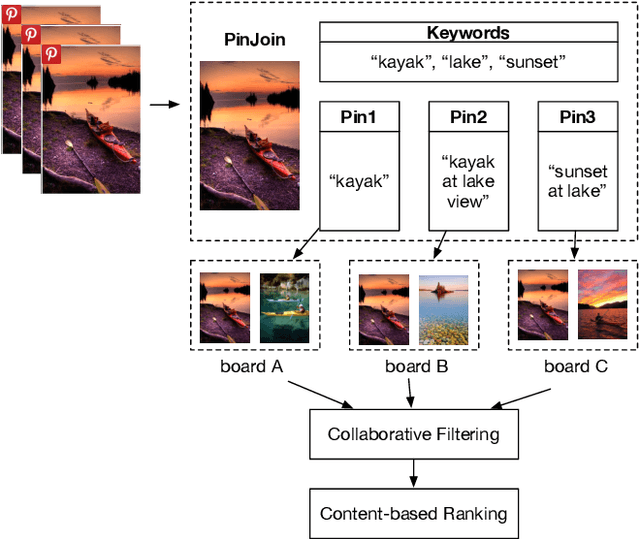

This paper presents Pinterest Related Pins, an item-to-item recommendation system that combines collaborative filtering with content-based ranking. We demonstrate that signals derived from user curation, the activity of users organizing content, are highly effective when used in conjunction with content-based ranking. This paper also demonstrates the effectiveness of visual features, such as image or object representations learned from convnets, in improving the user engagement rate of our item-to-item recommendation system.
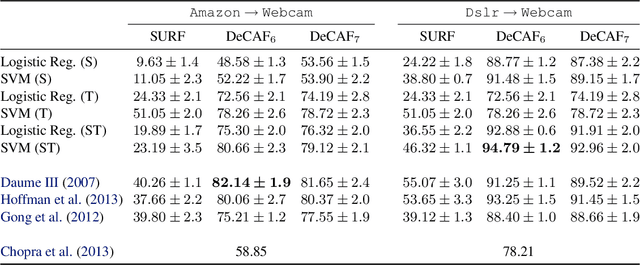
Simultaneous Deep Transfer Across Domains and Tasks
Oct 08, 2015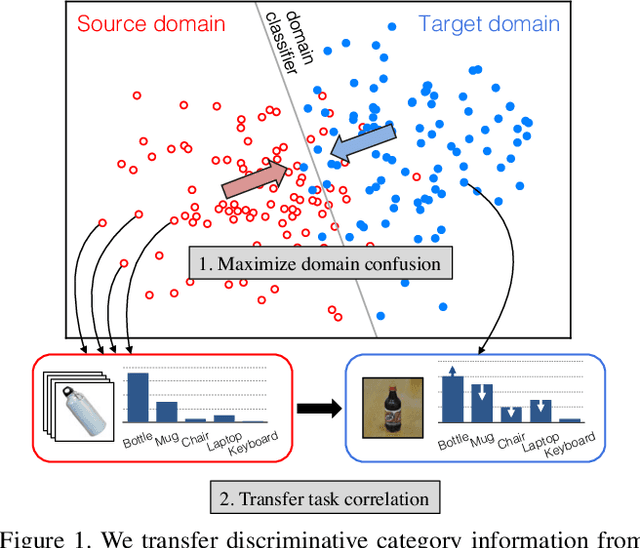
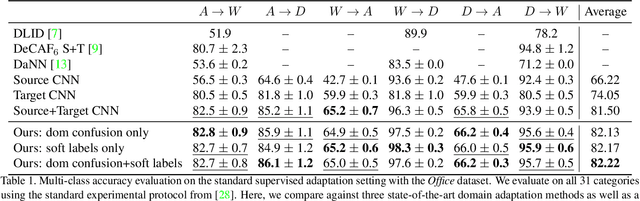
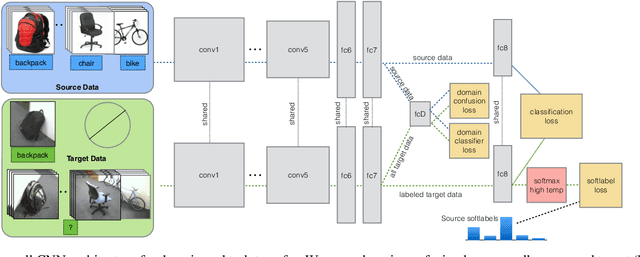
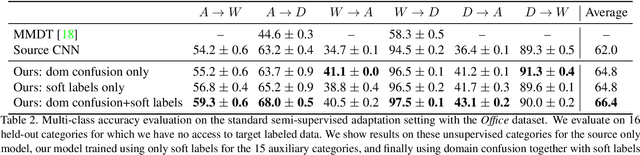
Recent reports suggest that a generic supervised deep CNN model trained on a large-scale dataset reduces, but does not remove, dataset bias. Fine-tuning deep models in a new domain can require a significant amount of labeled data, which for many applications is simply not available. We propose a new CNN architecture to exploit unlabeled and sparsely labeled target domain data. Our approach simultaneously optimizes for domain invariance to facilitate domain transfer and uses a soft label distribution matching loss to transfer information between tasks. Our proposed adaptation method offers empirical performance which exceeds previously published results on two standard benchmark visual domain adaptation tasks, evaluated across supervised and semi-supervised adaptation settings.
Deep Domain Confusion: Maximizing for Domain Invariance
Dec 10, 2014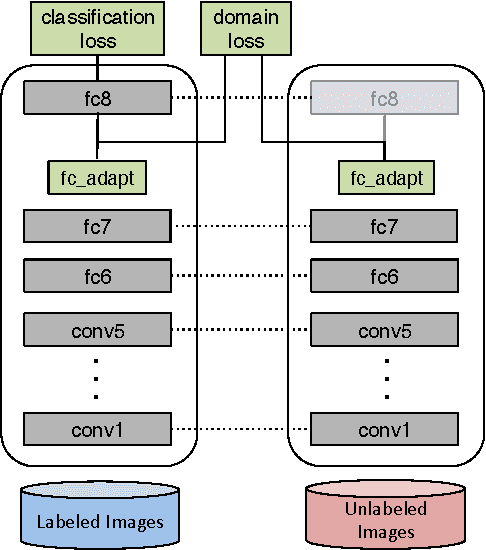
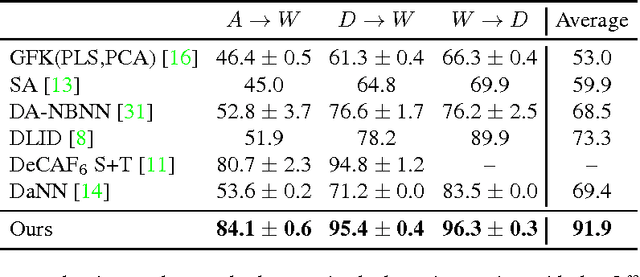
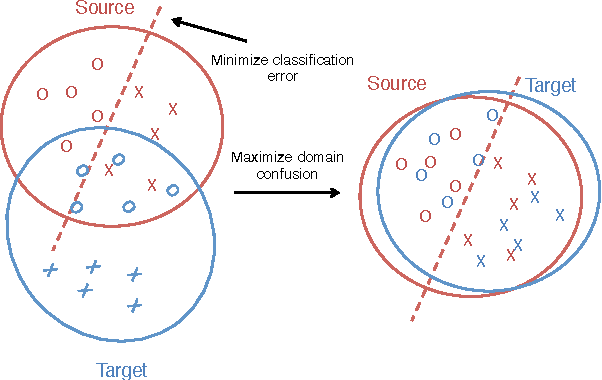

Recent reports suggest that a generic supervised deep CNN model trained on a large-scale dataset reduces, but does not remove, dataset bias on a standard benchmark. Fine-tuning deep models in a new domain can require a significant amount of data, which for many applications is simply not available. We propose a new CNN architecture which introduces an adaptation layer and an additional domain confusion loss, to learn a representation that is both semantically meaningful and domain invariant. We additionally show that a domain confusion metric can be used for model selection to determine the dimension of an adaptation layer and the best position for the layer in the CNN architecture. Our proposed adaptation method offers empirical performance which exceeds previously published results on a standard benchmark visual domain adaptation task.
LSDA: Large Scale Detection Through Adaptation
Nov 01, 2014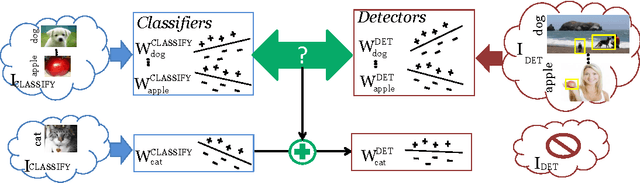
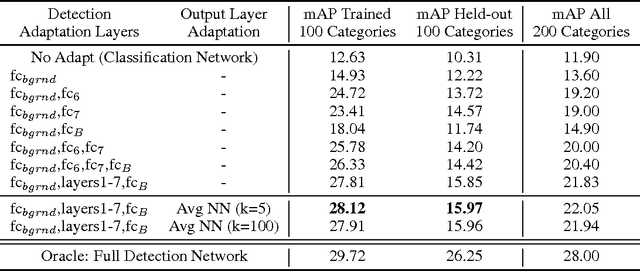
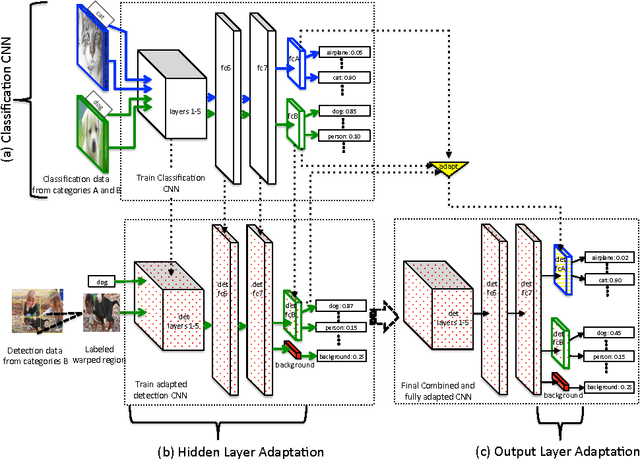
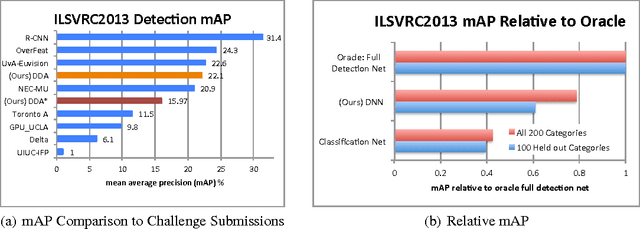
A major challenge in scaling object detection is the difficulty of obtaining labeled images for large numbers of categories. Recently, deep convolutional neural networks (CNNs) have emerged as clear winners on object classification benchmarks, in part due to training with 1.2M+ labeled classification images. Unfortunately, only a small fraction of those labels are available for the detection task. It is much cheaper and easier to collect large quantities of image-level labels from search engines than it is to collect detection data and label it with precise bounding boxes. In this paper, we propose Large Scale Detection through Adaptation (LSDA), an algorithm which learns the difference between the two tasks and transfers this knowledge to classifiers for categories without bounding box annotated data, turning them into detectors. Our method has the potential to enable detection for the tens of thousands of categories that lack bounding box annotations, yet have plenty of classification data. Evaluation on the ImageNet LSVRC-2013 detection challenge demonstrates the efficacy of our approach. This algorithm enables us to produce a >7.6K detector by using available classification data from leaf nodes in the ImageNet tree. We additionally demonstrate how to modify our architecture to produce a fast detector (running at 2fps for the 7.6K detector). Models and software are available at
One-Shot Adaptation of Supervised Deep Convolutional Models
Feb 18, 2014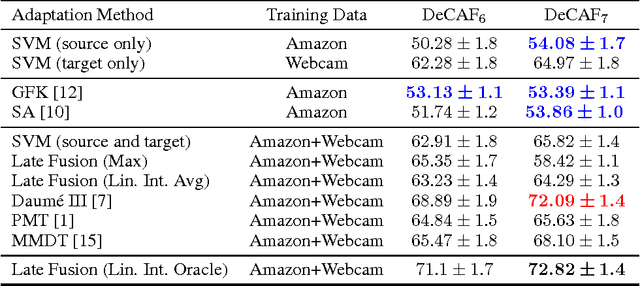
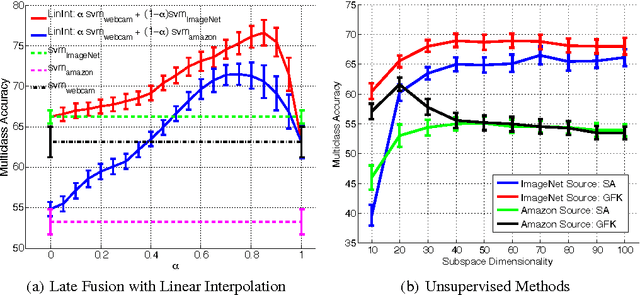
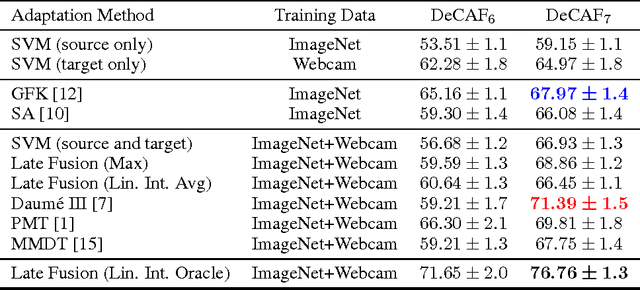
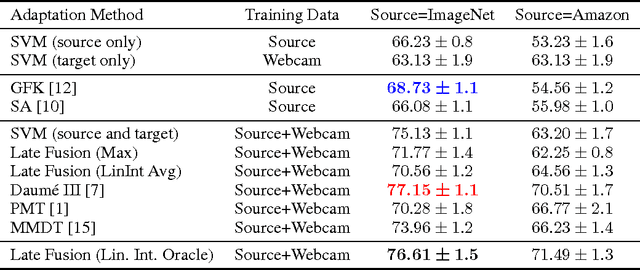
Dataset bias remains a significant barrier towards solving real world computer vision tasks. Though deep convolutional networks have proven to be a competitive approach for image classification, a question remains: have these models have solved the dataset bias problem? In general, training or fine-tuning a state-of-the-art deep model on a new domain requires a significant amount of data, which for many applications is simply not available. Transfer of models directly to new domains without adaptation has historically led to poor recognition performance. In this paper, we pose the following question: is a single image dataset, much larger than previously explored for adaptation, comprehensive enough to learn general deep models that may be effectively applied to new image domains? In other words, are deep CNNs trained on large amounts of labeled data as susceptible to dataset bias as previous methods have been shown to be? We show that a generic supervised deep CNN model trained on a large dataset reduces, but does not remove, dataset bias. Furthermore, we propose several methods for adaptation with deep models that are able to operate with little (one example per category) or no labeled domain specific data. Our experiments show that adaptation of deep models on benchmark visual domain adaptation datasets can provide a significant performance boost.
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
Oct 06, 2013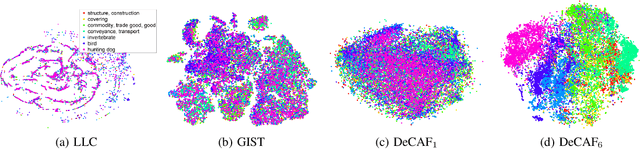
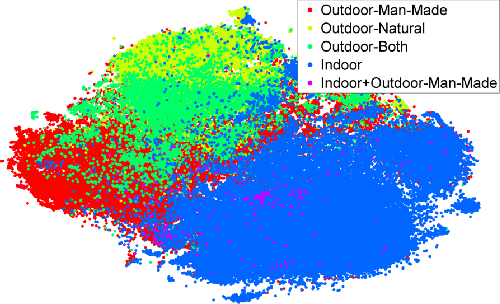

We evaluate whether features extracted from the activation of a deep convolutional network trained in a fully supervised fashion on a large, fixed set of object recognition tasks can be re-purposed to novel generic tasks. Our generic tasks may differ significantly from the originally trained tasks and there may be insufficient labeled or unlabeled data to conventionally train or adapt a deep architecture to the new tasks. We investigate and visualize the semantic clustering of deep convolutional features with respect to a variety of such tasks, including scene recognition, domain adaptation, and fine-grained recognition challenges. We compare the efficacy of relying on various network levels to define a fixed feature, and report novel results that significantly outperform the state-of-the-art on several important vision challenges. We are releasing DeCAF, an open-source implementation of these deep convolutional activation features, along with all associated network parameters to enable vision researchers to be able to conduct experimentation with deep representations across a range of visual concept learning paradigms.