 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Retrieval in the Wild: Challenges, Effectiveness and Robustness
Apr 29, 2025There is a growing abundance of publicly available or company-owned audio/video archives, highlighting the increasing importance of efficient access to desired content and information retrieval from these archives. This paper investigates the challenges, solutions, effectiveness, and robustness of speaker retrieval systems developed "in the wild" which involves addressing two primary challenges: extraction of task-relevant labels from limited metadata for system development and evaluation, as well as the unconstrained acoustic conditions encountered in the archive, ranging from quiet studios to adverse noisy environments. While we focus on the publicly-available BBC Rewind archive (spanning 1948 to 1979), our framework addresses the broader issue of speaker retrieval on extensive and possibly aged archives with no control over the content and acoustic conditions. Typically, these archives offer a brief and general file description, mostly inadequate for specific applications like speaker retrieval, and manual annotation of such large-scale archives is unfeasible. We explore various aspects of system development (e.g., speaker diarisation, embedding extraction, query selection) and analyse the challenges, possible solutions, and their functionality. To evaluate the performance, we conduct systematic experiments in both clean setup and against various distortions simulating real-world applications. Our findings demonstrate the effectiveness and robustness of the developed speaker retrieval systems, establishing the versatility and scalability of the proposed framework for a wide range of applications beyond the BBC Rewind corpus.
Phonetic Error Analysis of Raw Waveform Acoustic Models with Parametric and Non-Parametric CNNs
Jun 02, 2024



In this paper, we analyse the error patterns of the raw waveform acoustic models in TIMIT's phone recognition task. Our analysis goes beyond the conventional phone error rate (PER) metric. We categorise the phones into three groups: {affricate, diphthong, fricative, nasal, plosive, semi-vowel, vowel, silence}, {consonant, vowel+, silence}, and {voiced, unvoiced, silence} and, compute the PER for each broad phonetic class in each category. We also construct a confusion matrix for each category using the substitution errors and compare the confusion patterns with those of the Filterbank and Wav2vec 2.0 systems. Our raw waveform acoustic models consists of parametric (Sinc2Net) or non-parametric CNNs and Bidirectional LSTMs, achieving down to 13.7%/15.2% PERs on TIMIT Dev/Test sets, outperforming reported PERs for raw waveform models in the literature. We also investigate the impact of transfer learning from WSJ on the phonetic error patterns and confusion matrices. It reduces the PER to 11.8%/13.7% on the Dev/Test sets.
Zero-shot Audio Topic Reranking using Large Language Models
Sep 14, 2023



The Multimodal Video Search by Examples (MVSE) project investigates using video clips as the query term for information retrieval, rather than the more traditional text query. This enables far richer search modalities such as images, speaker, content, topic, and emotion. A key element for this process is highly rapid, flexible, search to support large archives, which in MVSE is facilitated by representing video attributes by embeddings. This work aims to mitigate any performance loss from this rapid archive search by examining reranking approaches. In particular, zero-shot reranking methods using large language models are investigated as these are applicable to any video archive audio content. Performance is evaluated for topic-based retrieval on a publicly available video archive, the BBC Rewind corpus. Results demonstrate that reranking can achieve improved retrieval ranking without the need for any task-specific training data.
RCT: Random Consistency Training for Semi-supervised Sound Event Detection
Nov 04, 2021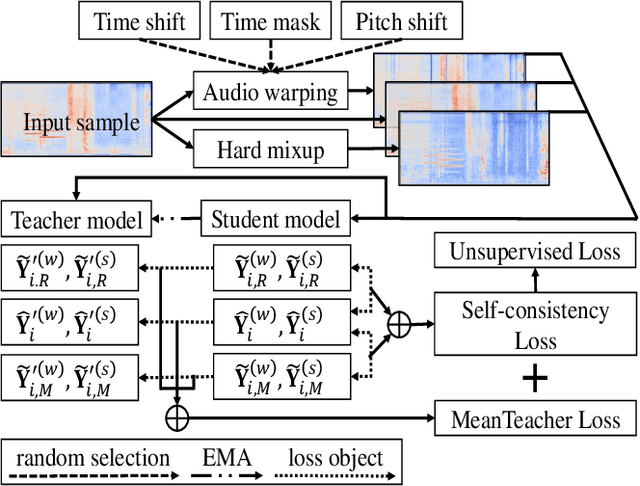
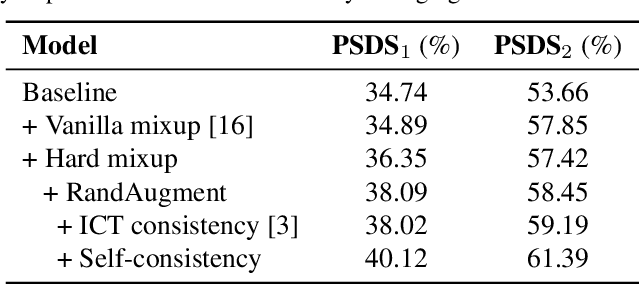
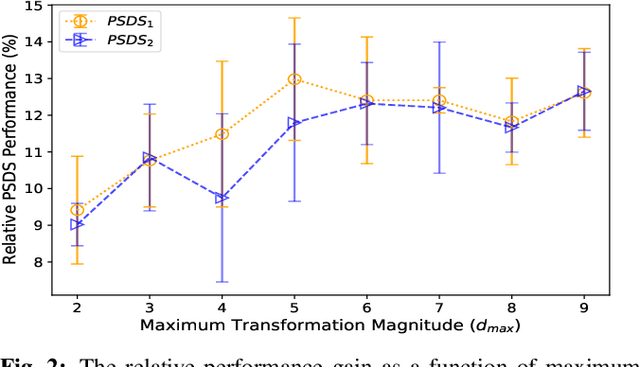
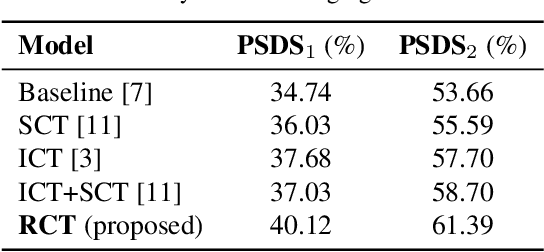
Sound event detection (SED), as a core module of acoustic environmental analysis, suffers from the problem of data deficiency. The integration of semi-supervised learning (SSL) largely mitigates such problem while bringing no extra annotation budget. This paper researches on several core modules of SSL, and introduces a random consistency training (RCT) strategy. First, a self-consistency loss is proposed to fuse with the teacher-student model to stabilize the training. Second, a hard mixup data augmentation is proposed to account for the additive property of sounds. Third, a random augmentation scheme is applied to flexibly combine different types of data augmentations. Experiments show that the proposed strategy outperform other widely-used strategies.
Train your classifier first: Cascade Neural Networks Training from upper layers to lower layers
Feb 09, 2021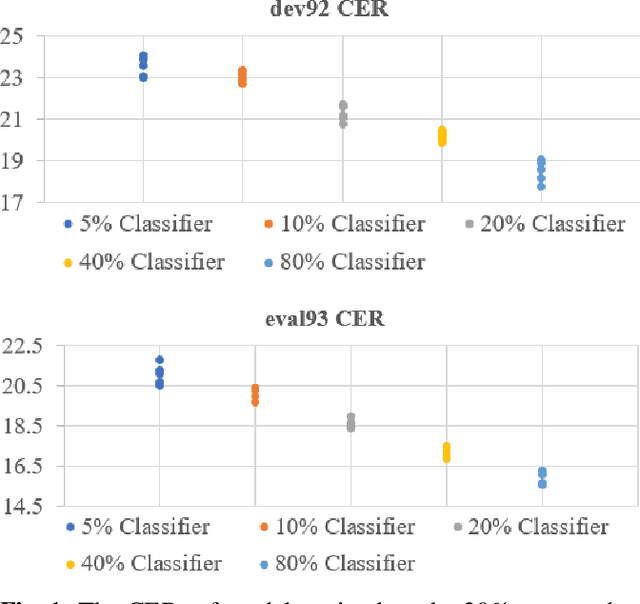
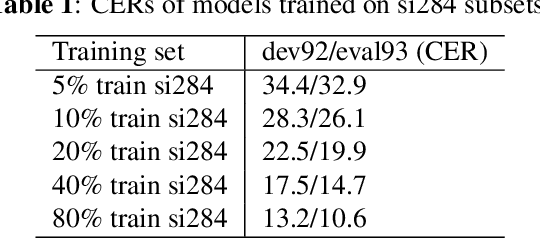
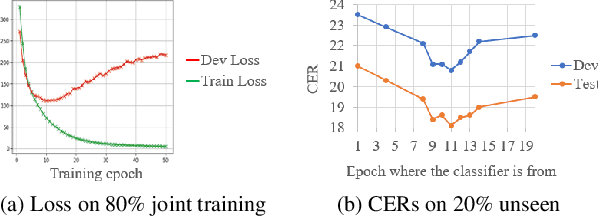
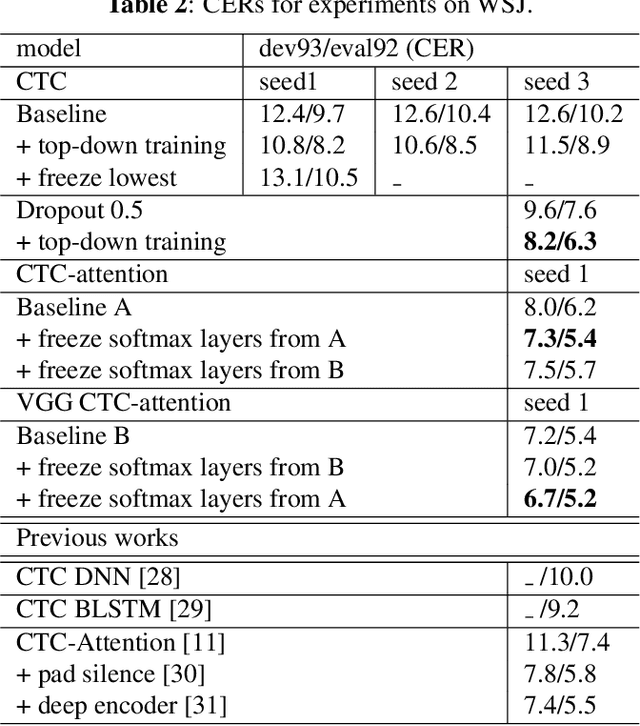
Although the lower layers of a deep neural network learn features which are transferable across datasets, these layers are not transferable within the same dataset. That is, in general, freezing the trained feature extractor (the lower layers) and retraining the classifier (the upper layers) on the same dataset leads to worse performance. In this paper, for the first time, we show that the frozen classifier is transferable within the same dataset. We develop a novel top-down training method which can be viewed as an algorithm for searching for high-quality classifiers. We tested this method on automatic speech recognition (ASR) tasks and language modelling tasks. The proposed method consistently improves recurrent neural network ASR models on Wall Street Journal, self-attention ASR models on Switchboard, and AWD-LSTM language models on WikiText-2.
On the Usefulness of Self-Attention for Automatic Speech Recognition with Transformers
Nov 08, 2020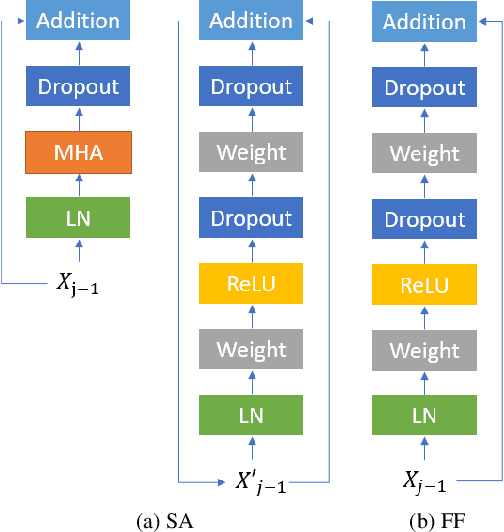
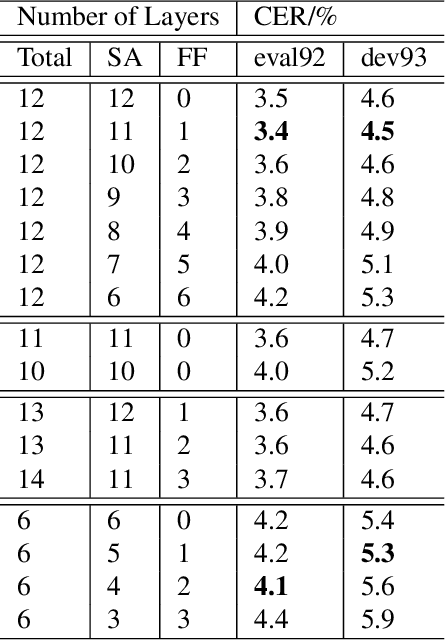
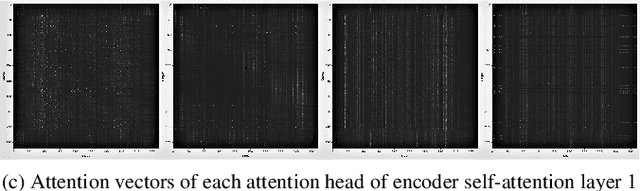
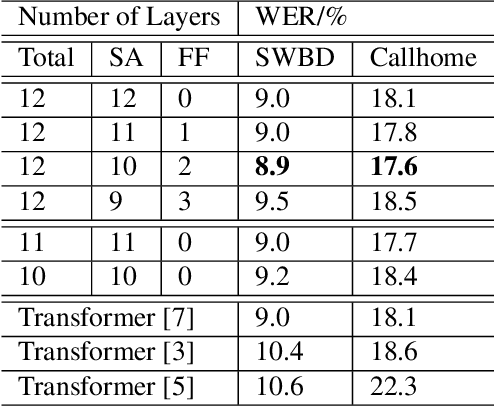
Self-attention models such as Transformers, which can capture temporal relationships without being limited by the distance between events, have given competitive speech recognition results. However, we note the range of the learned context increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence useful for the upper self-attention encoder layers in Transformers? To investigate this, we train models with lower self-attention/upper feed-forward layers encoders on Wall Street Journal and Switchboard. Compared to baseline Transformers, no performance drop but minor gains are observed. We further developed a novel metric of the diagonality of attention matrices and found the learned diagonality indeed increases from the lower to upper encoder self-attention layers. We conclude the global view is unnecessary in training upper encoder layers.
Stochastic Attention Head Removal: A Simple and Effective Method for Improving Automatic Speech Recognition with Transformers
Nov 08, 2020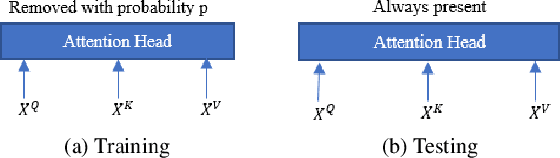
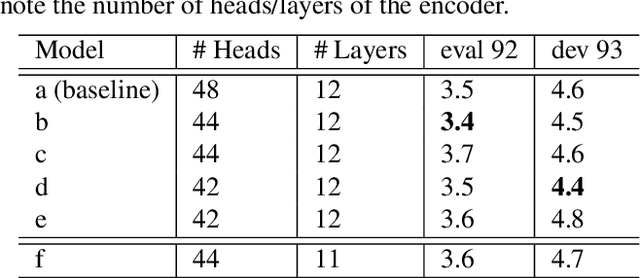
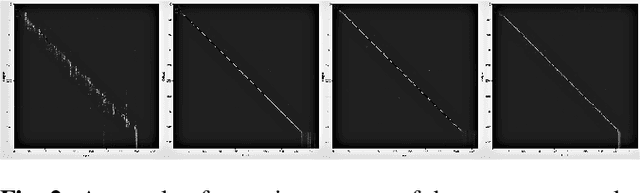
Recently, Transformers have shown competitive automatic speech recognition (ASR) results. One key factor to the success of these models is the multi-head attention mechanism. However, we observed in trained models, the diagonal attention matrices indicating the redundancy of the corresponding attention heads. Furthermore, we found some architectures with reduced numbers of attention heads have better performance. Since the search for the best structure is time prohibitive, we propose to randomly remove attention heads during training and keep all attention heads at test time, thus the final model can be viewed as an average of models with different architectures. This method gives consistent performance gains on the Wall Street Journal, AISHELL, Switchboard and AMI ASR tasks. On the AISHELL dev/test sets, the proposed method achieves state-of-the-art Transformer results with 5.8%/6.3% word error rates.
When Can Self-Attention Be Replaced by Feed Forward Layers?
May 28, 2020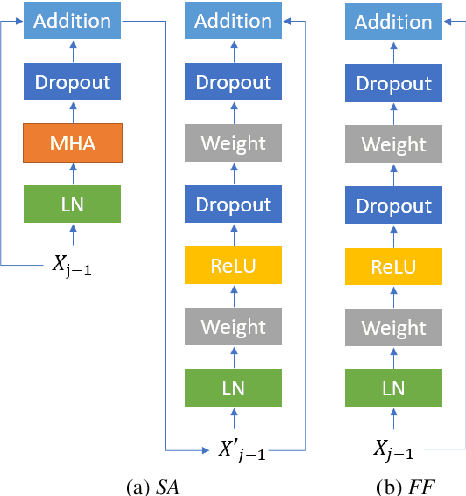
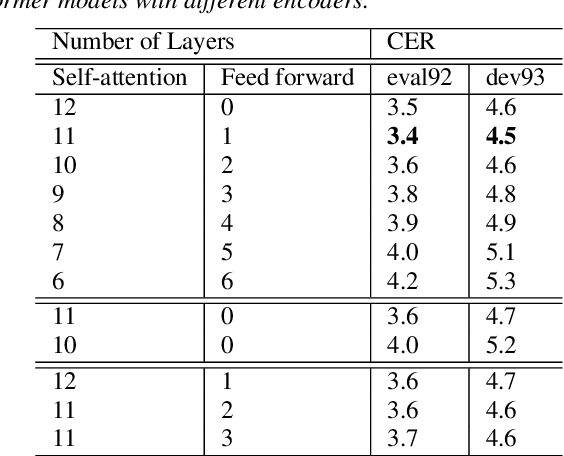

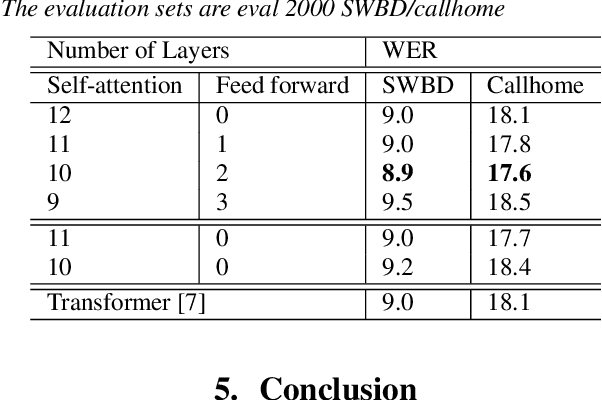
Recently, self-attention models such as Transformers have given competitive results compared to recurrent neural network systems in speech recognition. The key factor for the outstanding performance of self-attention models is their ability to capture temporal relationships without being limited by the distance between two related events. However, we note that the range of the learned context progressively increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence still important for the upper self-attention layers in the encoder of Transformers? To investigate this, we replace these self-attention layers with feed forward layers. In our speech recognition experiments (Wall Street Journal and Switchboard), we indeed observe an interesting result: replacing the upper self-attention layers in the encoder with feed forward layers leads to no performance drop, and even minor gains. Our experiments offer insights to how self-attention layers process the speech signal, leading to the conclusion that the lower self-attention layers of the encoder encode a sufficiently wide range of inputs, hence learning further contextual information in the upper layers is unnecessary.
Acoustic Model Adaptation from Raw Waveforms with SincNet
Sep 30, 2019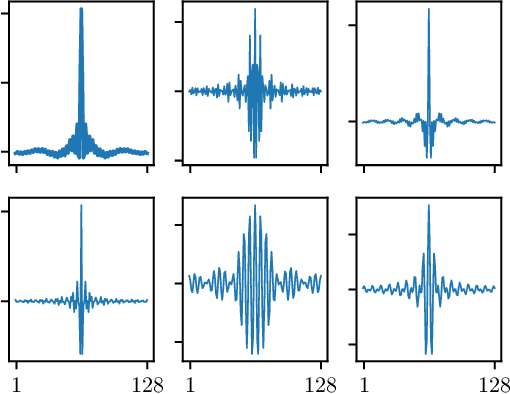
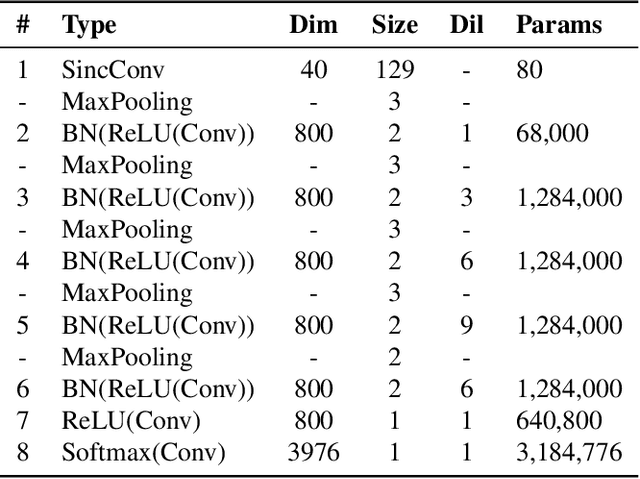
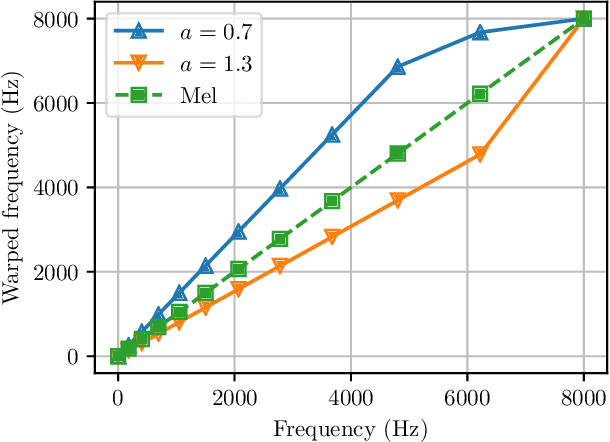
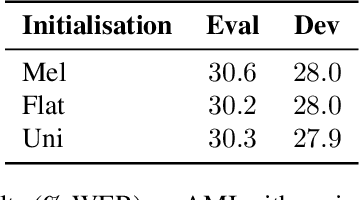
Raw waveform acoustic modelling has recently gained interest due to neural networks' ability to learn feature extraction, and the potential for finding better representations for a given scenario than hand-crafted features. SincNet has been proposed to reduce the number of parameters required in raw-waveform modelling, by restricting the filter functions, rather than having to learn every tap of each filter. We study the adaptation of the SincNet filter parameters from adults' to children's speech, and show that the parameterisation of the SincNet layer is well suited for adaptation in practice: we can efficiently adapt with a very small number of parameters, producing error rates comparable to techniques using orders of magnitude more parameters.