 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Variations in Speech Emotion Recognition with Nonparametric Hierarchical Neural Network
Sep 09, 2021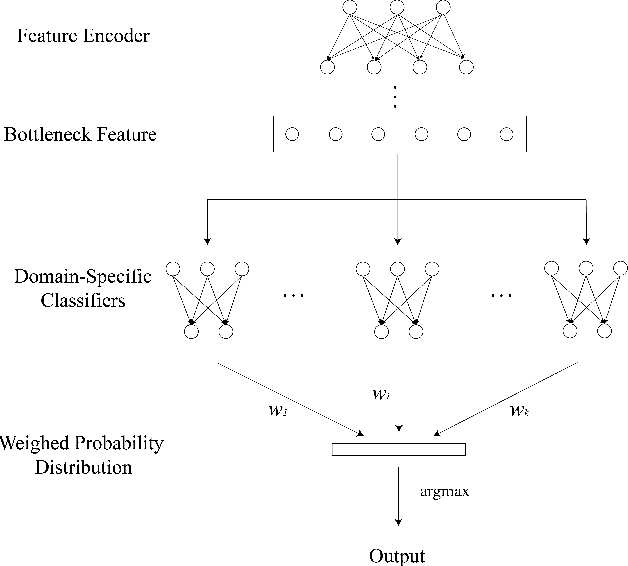


In recent years, deep-learning-based speech emotion recognition models have outperformed classical machine learning models. Previously, neural network designs, such as Multitask Learning, have accounted for variations in emotional expressions due to demographic and contextual factors. However, existing models face a few constraints: 1) they rely on a clear definition of domains (e.g. gender, noise condition, etc.) and the availability of domain labels; 2) they often attempt to learn domain-invariant features while emotion expressions can be domain-specific. In the present study, we propose the Nonparametric Hierarchical Neural Network (NHNN), a lightweight hierarchical neural network model based on Bayesian nonparametric clustering. In comparison to Multitask Learning approaches, the proposed model does not require domain/task labels. In our experiments, the NHNN models generally outperform the models with similar levels of complexity and state-of-the-art models in within-corpus and cross-corpus tests. Through clustering analysis, we show that the NHNN models are able to learn group-specific features and bridge the performance gap between groups.
Best Practices for Noise-Based Augmentation to Improve the Performance of Emotion Recognition "In the Wild"
Apr 18, 2021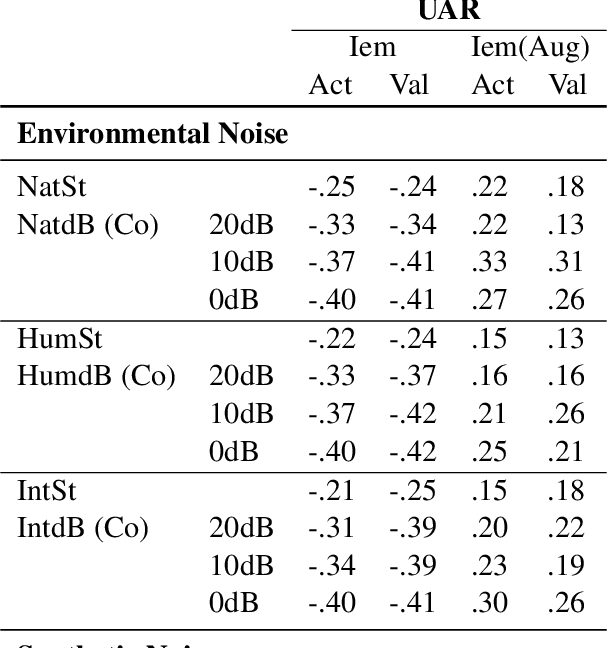

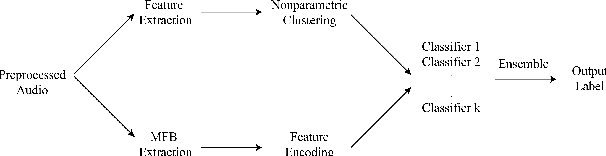
Emotion recognition as a key component of high-stake downstream applications has been shown to be effective, such as classroom engagement or mental health assessments. These systems are generally trained on small datasets collected in single laboratory environments, and hence falter when tested on data that has different noise characteristics. Multiple noise-based data augmentation approaches have been proposed to counteract this challenge in other speech domains. But, unlike speech recognition and speaker verification, in emotion recognition, noise-based data augmentation may change the underlying label of the original emotional sample. In this work, we generate realistic noisy samples of a well known emotion dataset (IEMOCAP) using multiple categories of environmental and synthetic noise. We evaluate how both human and machine emotion perception changes when noise is introduced. We find that some commonly used augmentation techniques for emotion recognition significantly change human perception, which may lead to unreliable evaluation metrics such as evaluating efficiency of adversarial attack. We also find that the trained state-of-the-art emotion recognition models fail to classify unseen noise-augmented samples, even when trained on noise augmented datasets. This finding demonstrates the brittleness of these systems in real-world conditions. We propose a set of recommendations for noise-based augmentation of emotion datasets and for how to deploy these emotion recognition systems "in the wild".
Why Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Apr 18, 2021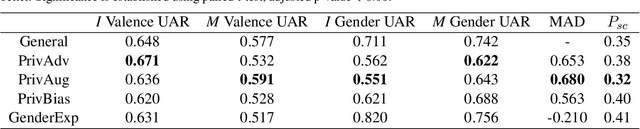
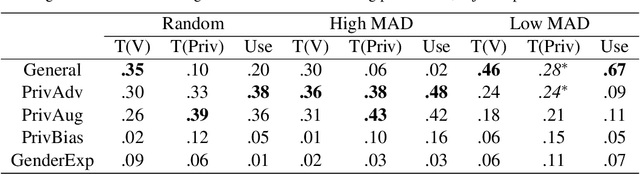
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.
Dynamic Layer Customization for Noise Robust Speech Emotion Recognition in Heterogeneous Condition Training
Oct 21, 2020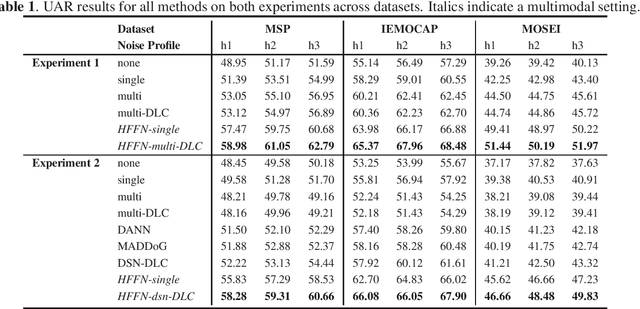
Robustness to environmental noise is important to creating automatic speech emotion recognition systems that are deployable in the real world. Prior work on noise robustness has assumed that systems would not make use of sample-by-sample training noise conditions, or that they would have access to unlabelled testing data to generalize across noise conditions. We avoid these assumptions and introduce the resulting task as heterogeneous condition training. We show that with full knowledge of the test noise conditions, we can improve performance by dynamically routing samples to specialized feature encoders for each noise condition, and with partial knowledge, we can use known noise conditions and domain adaptation algorithms to train systems that generalize well to unseen noise conditions. We then extend these improvements to the multimodal setting by dynamically routing samples to maintain temporal ordering, resulting in significant improvements over approaches that do not specialize or generalize based on noise type.
Quantifying the Effects of COVID-19 on Mental Health Support Forums
Sep 08, 2020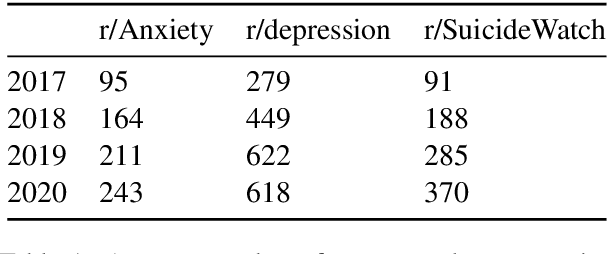
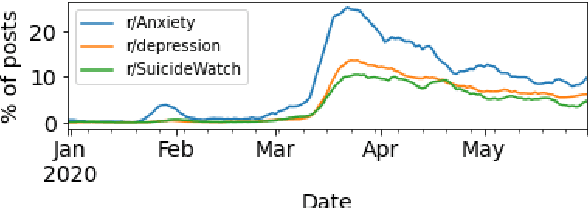
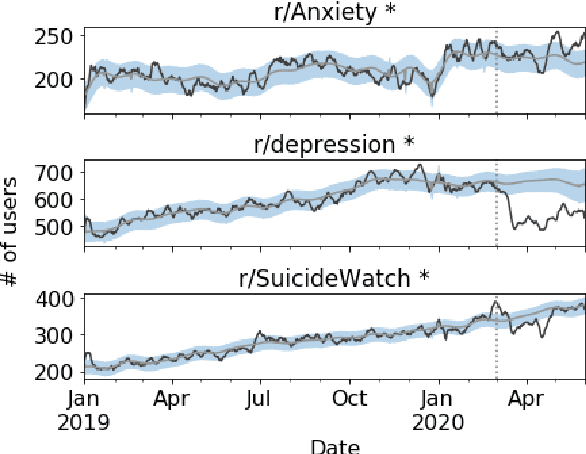
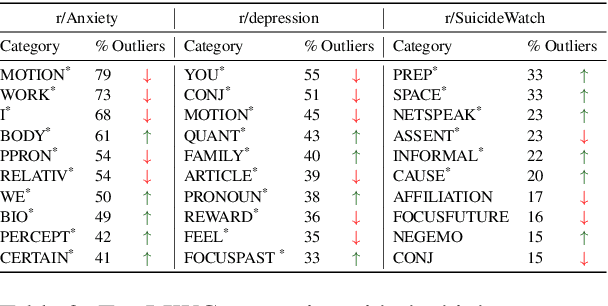
The COVID-19 pandemic, like many of the disease outbreaks that have preceded it, is likely to have a profound effect on mental health. Understanding its impact can inform strategies for mitigating negative consequences. In this work, we seek to better understand the effects of COVID-19 on mental health by examining discussions within mental health support communities on Reddit. First, we quantify the rate at which COVID-19 is discussed in each community, or subreddit, in order to understand levels of preoccupation with the pandemic. Next, we examine the volume of activity in order to determine whether the quantity of people seeking online mental health support has risen. Finally, we analyze how COVID-19 has influenced language use and topics of discussion within each subreddit.
Classification of Huntington Disease using Acoustic and Lexical Features
Aug 07, 2020
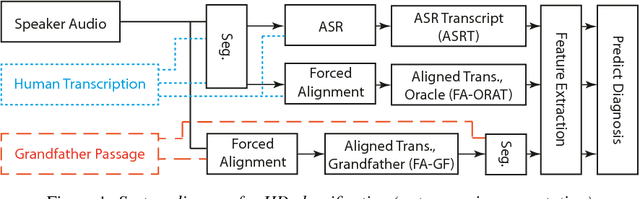

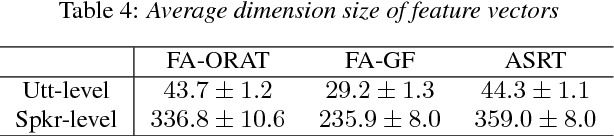
Speech is a critical biomarker for Huntington Disease (HD), with changes in speech increasing in severity as the disease progresses. Speech analyses are currently conducted using either transcriptions created manually by trained professionals or using global rating scales. Manual transcription is both expensive and time-consuming and global rating scales may lack sufficient sensitivity and fidelity. Ultimately, what is needed is an unobtrusive measure that can cheaply and continuously track disease progression. We present first steps towards the development of such a system, demonstrating the ability to automatically differentiate between healthy controls and individuals with HD using speech cues. The results provide evidence that objective analyses can be used to support clinical diagnoses, moving towards the tracking of symptomatology outside of laboratory and clinical environments.
Privacy Enhanced Multimodal Neural Representations for Emotion Recognition
Oct 29, 2019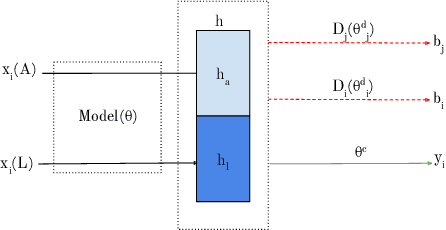
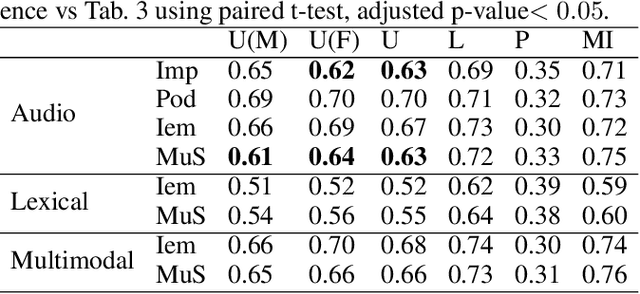
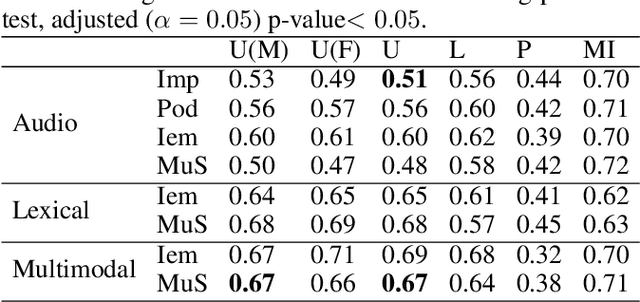
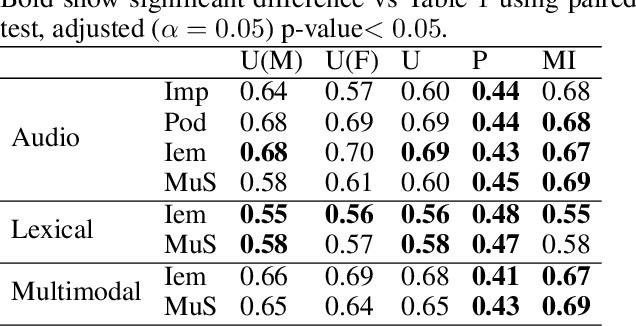
Many mobile applications and virtual conversational agents now aim to recognize and adapt to emotions. To enable this, data are transmitted from users' devices and stored on central servers. Yet, these data contain sensitive information that could be used by mobile applications without user's consent or, maliciously, by an eavesdropping adversary. In this work, we show how multimodal representations trained for a primary task, here emotion recognition, can unintentionally leak demographic information, which could override a selected opt-out option by the user. We analyze how this leakage differs in representations obtained from textual, acoustic, and multimodal data. We use an adversarial learning paradigm to unlearn the private information present in a representation and investigate the effect of varying the strength of the adversarial component on the primary task and on the privacy metric, defined here as the inability of an attacker to predict specific demographic information. We evaluate this paradigm on multiple datasets and show that we can improve the privacy metric while not significantly impacting the performance on the primary task. To the best of our knowledge, this is the first work to analyze how the privacy metric differs across modalities and how multiple privacy concerns can be tackled while still maintaining performance on emotion recognition.
When to Intervene: Detecting Abnormal Mood using Everyday Smartphone Conversations
Oct 03, 2019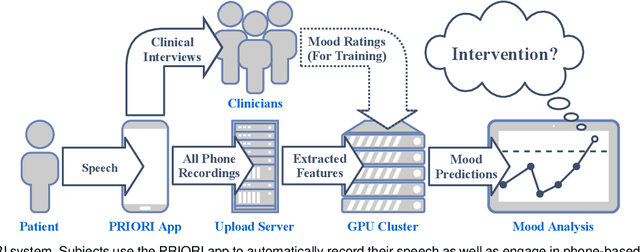
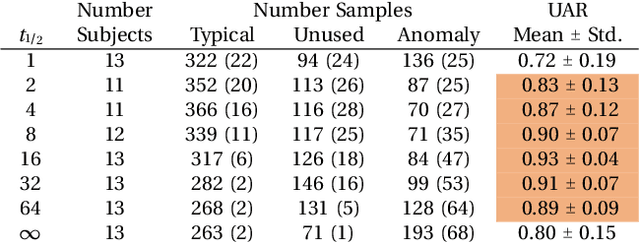
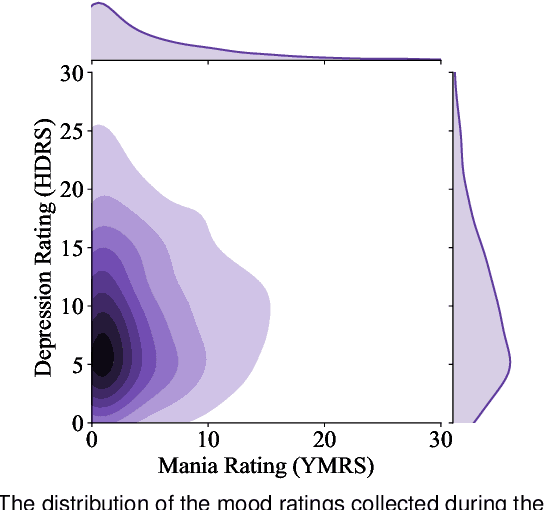

Bipolar disorder (BPD) is a chronic mental illness characterized by extreme mood and energy changes from mania to depression. These changes drive behaviors that often lead to devastating personal or social consequences. BPD is managed clinically with regular interactions with care providers, who assess mood, energy levels, and the form and content of speech. Recent work has proposed smartphones for monitoring mood using speech. However, these works do not predict when to intervene. Predicting when to intervene is challenging because there is not a single measure that is relevant for every person: different individuals may have different levels of symptom severity considered typical. Additionally, this typical mood, or baseline, may change over time, making a single symptom threshold insufficient. This work presents an innovative approach that expands clinical mood monitoring to predict when interventions are necessary using an anomaly detection framework, which we call Temporal Normalization. We first validate the model using a dataset annotated for clinical interventions and then incorporate this method in a deep learning framework to predict mood anomalies from natural, unstructured, telephone speech data. The combination of these approaches provides a framework to enable real-world speech-focused mood monitoring.
The Ambiguous World of Emotion Representation
Sep 01, 2019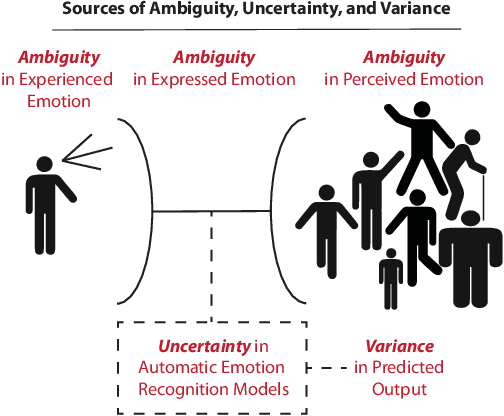
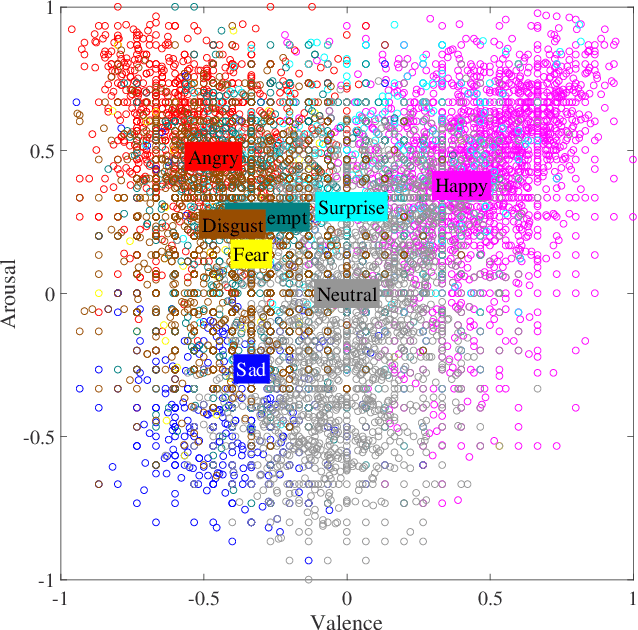
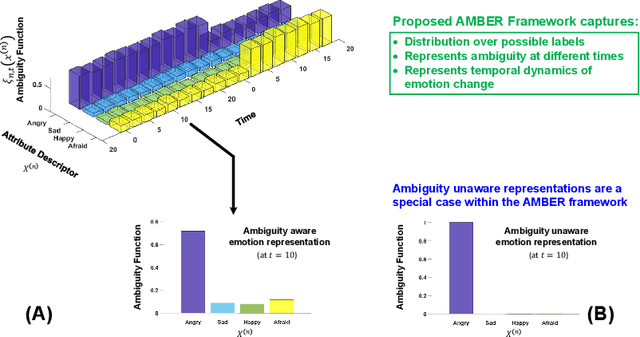
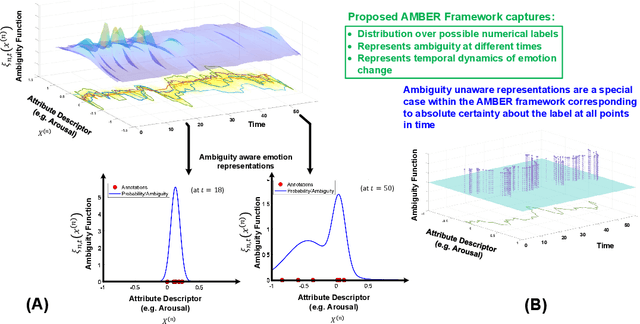
Artificial intelligence and machine learning systems have demonstrated huge improvements and human-level parity in a range of activities, including speech recognition, face recognition and speaker verification. However, these diverse tasks share a key commonality that is not true in affective computing: the ground truth information that is inferred can be unambiguously represented. This observation provides some hints as to why affective computing, despite having attracted the attention of researchers for years, may not still be considered a mature field of research. A key reason for this is the lack of a common mathematical framework to describe all the relevant elements of emotion representations. This paper proposes the AMBiguous Emotion Representation (AMBER) framework to address this deficiency. AMBER is a unified framework that explicitly describes categorical, numerical and ordinal representations of emotions, including time varying representations. In addition to explaining the core elements of AMBER, the paper also discusses how some of the commonly employed emotion representation schemes can be viewed through the AMBER framework, and concludes with a discussion of how the proposed framework can be used to reason about current and future affective computing systems.
Controlling for Confounders in Multimodal Emotion Classification via Adversarial Learning
Aug 23, 2019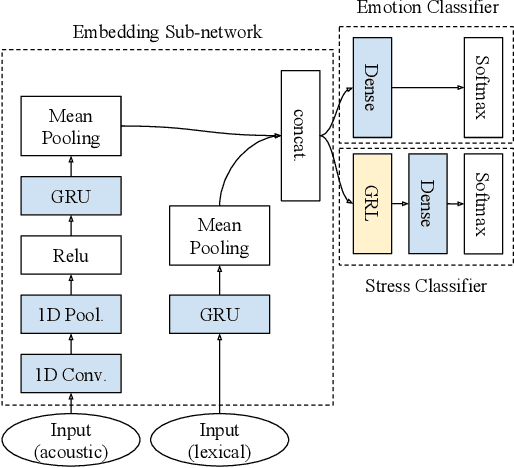

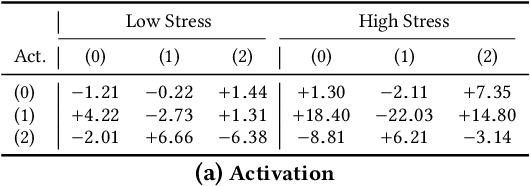
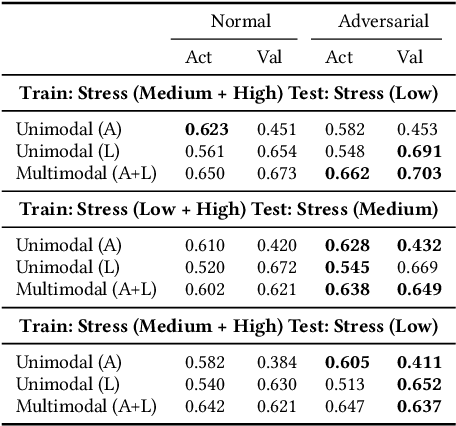
Various psychological factors affect how individuals express emotions. Yet, when we collect data intended for use in building emotion recognition systems, we often try to do so by creating paradigms that are designed just with a focus on eliciting emotional behavior. Algorithms trained with these types of data are unlikely to function outside of controlled environments because our emotions naturally change as a function of these other factors. In this work, we study how the multimodal expressions of emotion change when an individual is under varying levels of stress. We hypothesize that stress produces modulations that can hide the true underlying emotions of individuals and that we can make emotion recognition algorithms more generalizable by controlling for variations in stress. To this end, we use adversarial networks to decorrelate stress modulations from emotion representations. We study how stress alters acoustic and lexical emotional predictions, paying special attention to how modulations due to stress affect the transferability of learned emotion recognition models across domains. Our results show that stress is indeed encoded in trained emotion classifiers and that this encoding varies across levels of emotions and across the lexical and acoustic modalities. Our results also show that emotion recognition models that control for stress during training have better generalizability when applied to new domains, compared to models that do not control for stress during training. We conclude that is is necessary to consider the effect of extraneous psychological factors when building and testing emotion recognition models.