 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Preference Reinforcement Learning
May 21, 2026Post-training has split large language model (LLM) alignment into two largely disconnected tracks. Online reinforcement learning (RL) with verifiable rewards drives emergent reasoning on math and code but depends on a programmatic verifier that cannot reach open-ended tasks, while preference optimization handles open-ended generation yet forgoes the continuous exploration that powers online RL. Closing this gap requires a verifier for open-ended quality, but a scalar reward model is the wrong shape for the job. Quality is multi-dimensional, and any scalar score is an incomplete proxy that lets online RL collapse onto whichever axis the score is most sensitive to. We turn instead to the General Preference Model (GPM), which embeds responses into $k$ skew-symmetric subspaces and represents preference as a structured, intransitivity-aware comparison. Building on this, we propose General Preference Reinforcement Learning (GPRL), which carries the $k$-way structure through to the policy update. GPRL computes per-dimension group-relative advantages, normalizes each on its own scale so no axis can dominate, and aggregates them with context-dependent eigenvalues. The same structure powers a closed-loop drift monitor that detects single-axis exploitation and corrects it on the fly by reweighting dimensions and tightening the trust region. Starting from $\texttt{Llama-3-8B-Instruct}$, GPRL reaches a length-controlled win rate of $56.51\%$ on AlpacaEval~2.0 while also outperforming SimPO and SPPO on Arena-Hard, MT-Bench, and WildBench by resisting reward hacking across extended training runs.
Canonical Optimization for MIMO MAC Design
May 04, 2026Resource allocation in the multiple-input multiple-output (MIMO) multiple access channel (MAC) is a fundamental problem in multiuser communications, yet it is increasingly treated as non-convex and computationally intractable. This has motivated a large body of heuristic machine learning and successive-approximation methods. Results here show that the MIMO MAC admits canonical convex formulations and present four solvers that together characterize its capacity region. maxRMAC performs weighted sum-rate maximization under per-user energy constraints, minPMAC finds the minimum weighted energy required to support target rates, maxRESMAC performs weighted sum-rate maximization under a total energy constraint, and admMAC tests rate-region feasibility. The solvers exploit the polymatroid structure of the MAC rate region and the separability of the dual Lagrangian across frequency tones, which reduces the problem to parallel per-tone covariance optimizations solved via limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) over Cholesky-like covariance factors. Experiments on spatially correlated MIMO orthogonal frequency-division multiplexing (OFDM) channels show that the proposed solvers match a commercial convex solver in solution quality while running up to two orders of magnitude faster and scaling to regimes where the commercial solver times out. Through broadcast channel (BC) to MAC duality, the same solvers also enable optimal precoder design for the MIMO BC. All solvers are open-sourced and available at https://github.com/muhd-umer/canonical-mac.
$S^3$: Stratified Scaling Search for Test-Time in Diffusion Language Models
Apr 07, 2026Test-time scaling investigates whether a fixed diffusion language model (DLM) can generate better outputs when given more inference compute, without additional training. However, naive best-of-$K$ sampling is fundamentally limited because it repeatedly draws from the same base diffusion distribution, whose high-probability regions are often misaligned with high-quality outputs. We propose $S^3$ (Stratified Scaling Search), a classical verifier-guided search method that improves generation by reallocating compute during the denoising process rather than only at the final output stage. At each denoising step, $S^3$ expands multiple candidate trajectories, evaluates them with a lightweight reference-free verifier, and selectively resamples promising candidates while preserving diversity within the search frontier. This procedure effectively approximates a reward-tilted sampling distribution that favors higher-quality outputs while remaining anchored to the model prior. Experiments with LLaDA-8B-Instruct on MATH-500, GSM8K, ARC-Challenge, and TruthfulQA demonstrate that $S^3$ consistently improves performance across benchmarks, achieving the largest gains on mathematical reasoning tasks while leaving the underlying model and decoding schedule unchanged. These results show that classical search over denoising trajectories provides a practical mechanism for test-time scaling in DLMs.
Pressure, What Pressure? Sycophancy Disentanglement in Language Models via Reward Decomposition
Apr 07, 2026Large language models exhibit sycophancy, the tendency to shift their stated positions toward perceived user preferences or authority cues regardless of evidence. Standard alignment methods fail to correct this because scalar reward models conflate two distinct failure modes into a single signal: pressure capitulation, where the model changes a correct answer under social pressure, and evidence blindness, where the model ignores the provided context entirely. We operationalise sycophancy through formal definitions of pressure independence and evidence responsiveness, serving as a working framework for disentangled training rather than a definitive characterisation of the phenomenon. We propose the first approach to sycophancy reduction via reward decomposition, introducing a multi-component Group Relative Policy Optimisation (GRPO) reward that decomposes the training signal into five terms: pressure resistance, context fidelity, position consistency, agreement suppression, and factual correctness. We train using a contrastive dataset pairing pressure-free baselines with pressured variants across three authority levels and two opposing evidence contexts. Across five base models, our two-phase pipeline consistently reduces sycophancy on all metric axes, with ablations confirming that each reward term governs an independent behavioural dimension. The learned resistance to pressure generalises beyond our training methodology and prompt structure, reducing answer-priming sycophancy by up to 17 points on SycophancyEval despite the absence of such pressure forms during training.
What If We Allocate Test-Time Compute Adaptively?
Feb 01, 2026Test-time compute scaling allocates inference computation uniformly, uses fixed sampling strategies, and applies verification only for reranking. In contrast, we propose a verifier-guided adaptive framework treating reasoning as iterative trajectory generation and selection. For each problem, the agent runs multiple inference iterations. In each iteration, it optionally produces a high-level plan, selects a set of reasoning tools and a compute strategy together with an exploration parameter, and then generates a candidate reasoning trajectory. A process reward model (PRM) serves as a unified control signal: within each iteration, step-level PRM scores are aggregated to guide pruning and expansion during generation, and across iterations, aggregated trajectory rewards are used to select the final response. Across datasets, our dynamic, PRM-guided approach consistently outperforms direct test-time scaling, yielding large gains on MATH-500 and several-fold improvements on harder benchmarks such as AIME24 and AMO-Bench. We characterize efficiency using theoretical FLOPs and a compute intensity metric penalizing wasted generation and tool overhead, demonstrating that verification-guided allocation concentrates computation on high-utility reasoning paths.
Continuous-Utility Direct Preference Optimization
Jan 31, 2026Large language model reasoning is often treated as a monolithic capability, relying on binary preference supervision that fails to capture partial progress or fine-grained reasoning quality. We introduce Continuous Utility Direct Preference Optimization (CU-DPO), a framework that aligns models to a portfolio of prompt-based cognitive strategies by replacing binary labels with continuous scores that capture fine-grained reasoning quality. We prove that learning with K strategies yields a Theta(K log K) improvement in sample complexity over binary preferences, and that DPO converges to the entropy-regularized utility-maximizing policy. To exploit this signal, we propose a two-stage training pipeline: (i) strategy selection, which optimizes the model to choose the best strategy for a given problem via best-vs-all comparisons, and (ii) execution refinement, which trains the model to correctly execute the selected strategy using margin-stratified pairs. On mathematical reasoning benchmarks, CU-DPO improves strategy selection accuracy from 35-46 percent to 68-78 percent across seven base models, yielding consistent downstream reasoning gains of up to 6.6 points on in-distribution datasets with effective transfer to out-of-distribution tasks.
On the Fundamental Limits of LLMs at Scale
Nov 17, 2025



Large Language Models (LLMs) have benefited enormously from scaling, yet these gains are bounded by five fundamental limitations: (1) hallucination, (2) context compression, (3) reasoning degradation, (4) retrieval fragility, and (5) multimodal misalignment. While existing surveys describe these phenomena empirically, they lack a rigorous theoretical synthesis connecting them to the foundational limits of computation, information, and learning. This work closes that gap by presenting a unified, proof-informed framework that formalizes the innate theoretical ceilings of LLM scaling. First, computability and uncomputability imply an irreducible residue of error: for any computably enumerable model family, diagonalization guarantees inputs on which some model must fail, and undecidable queries (e.g., halting-style tasks) induce infinite failure sets for all computable predictors. Second, information-theoretic and statistical constraints bound attainable accuracy even on decidable tasks, finite description length enforces compression error, and long-tail factual knowledge requires prohibitive sample complexity. Third, geometric and computational effects compress long contexts far below their nominal size due to positional under-training, encoding attenuation, and softmax crowding. We further show how likelihood-based training favors pattern completion over inference, how retrieval under token limits suffers from semantic drift and coupling noise, and how multimodal scaling inherits shallow cross-modal alignment. Across sections, we pair theorems and empirical evidence to outline where scaling helps, where it saturates, and where it cannot progress, providing both theoretical foundations and practical mitigation paths like bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention.
Meta-Thinking in LLMs via Multi-Agent Reinforcement Learning: A Survey
Apr 20, 2025



This survey explores the development of meta-thinking capabilities in Large Language Models (LLMs) from a Multi-Agent Reinforcement Learning (MARL) perspective. Meta-thinking self-reflection, assessment, and control of thinking processes is an important next step in enhancing LLM reliability, flexibility, and performance, particularly for complex or high-stakes tasks. The survey begins by analyzing current LLM limitations, such as hallucinations and the lack of internal self-assessment mechanisms. It then talks about newer methods, including RL from human feedback (RLHF), self-distillation, and chain-of-thought prompting, and each of their limitations. The crux of the survey is to talk about how multi-agent architectures, namely supervisor-agent hierarchies, agent debates, and theory of mind frameworks, can emulate human-like introspective behavior and enhance LLM robustness. By exploring reward mechanisms, self-play, and continuous learning methods in MARL, this survey gives a comprehensive roadmap to building introspective, adaptive, and trustworthy LLMs. Evaluation metrics, datasets, and future research avenues, including neuroscience-inspired architectures and hybrid symbolic reasoning, are also discussed.
Resource Allocation for RIS-Assisted CoMP-NOMA Networks using Reinforcement Learning
Apr 01, 2025



This thesis delves into the forefront of wireless communication by exploring the synergistic integration of three transformative technologies: STAR-RIS, CoMP, and NOMA. Driven by the ever-increasing demand for higher data rates, improved spectral efficiency, and expanded coverage in the evolving landscape of 6G development, this research investigates the potential of these technologies to revolutionize future wireless networks. The thesis analyzes the performance gains achievable through strategic deployment of STAR-RIS, focusing on mitigating inter-cell interference, enhancing signal strength, and extending coverage to cell-edge users. Resource sharing strategies for STAR-RIS elements are explored, optimizing both transmission and reflection functionalities. Analytical frameworks are developed to quantify the benefits of STAR-RIS assisted CoMP-NOMA networks under realistic channel conditions, deriving key performance metrics such as ergodic rates and outage probabilities. Additionally, the research delves into energy-efficient design approaches for CoMP-NOMA networks incorporating RIS, proposing novel RIS configurations and optimization algorithms to achieve a balance between performance and energy consumption. Furthermore, the application of Deep Reinforcement Learning (DRL) techniques for intelligent and adaptive optimization in aerial RIS-assisted CoMP-NOMA networks is explored, aiming to maximize network sum rate while meeting user quality of service requirements. Through a comprehensive investigation of these technologies and their synergistic potential, this thesis contributes valuable insights into the future of wireless communication, paving the way for the development of more efficient, reliable, and sustainable networks capable of meeting the demands of our increasingly connected world.
Intelligent Spectrum Sharing in Integrated TN-NTNs: A Hierarchical Deep Reinforcement Learning Approach
Mar 09, 2025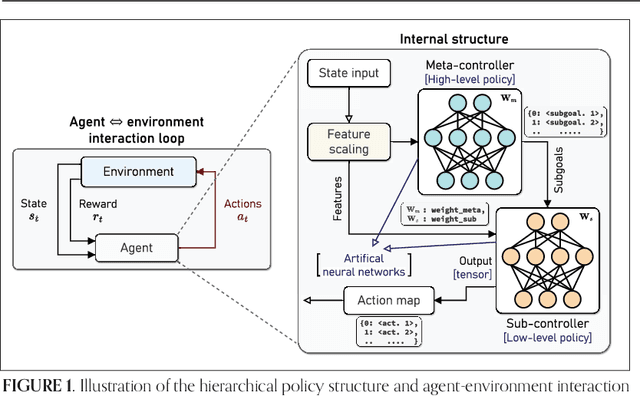
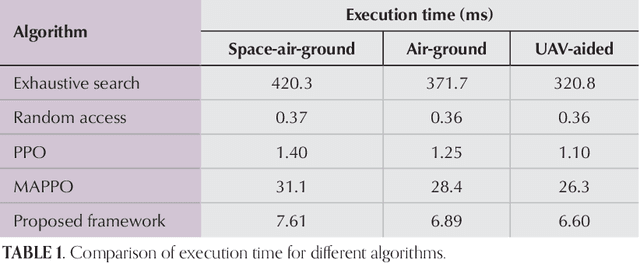


Integrating non-terrestrial networks (NTNs) with terrestrial networks (TNs) is key to enhancing coverage, capacity, and reliability in future wireless communications. However, the multi-tier, heterogeneous architecture of these integrated TN-NTNs introduces complex challenges in spectrum sharing and interference management. Conventional optimization approaches struggle to handle the high-dimensional decision space and dynamic nature of these networks. This paper proposes a novel hierarchical deep reinforcement learning (HDRL) framework to address these challenges and enable intelligent spectrum sharing. The proposed framework leverages the inherent hierarchy of the network, with separate policies for each tier, to learn and optimize spectrum allocation decisions at different timescales and levels of abstraction. By decomposing the complex spectrum sharing problem into manageable sub-tasks and allowing for efficient coordination among the tiers, the HDRL approach offers a scalable and adaptive solution for spectrum management in future TN-NTNs. Simulation results demonstrate the superior performance of the proposed framework compared to traditional approaches, highlighting its potential to enhance spectral efficiency and network capacity in dynamic, multi-tier environments.