 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublic Data-Assisted Mirror Descent for Private Model Training
Dec 01, 2021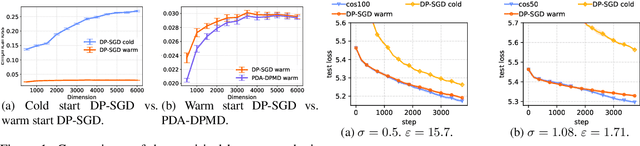
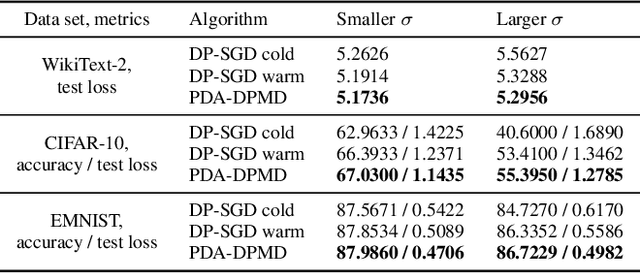

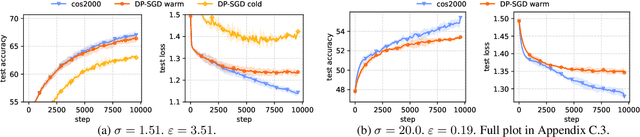
We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.
Constrained Instance and Class Reweighting for Robust Learning under Label Noise
Nov 09, 2021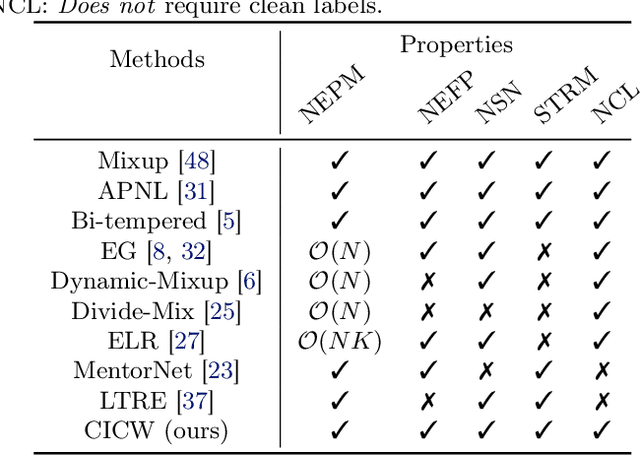
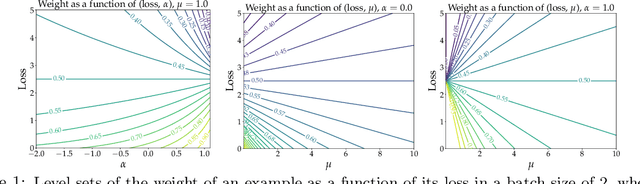
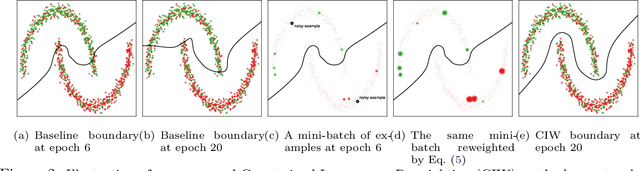
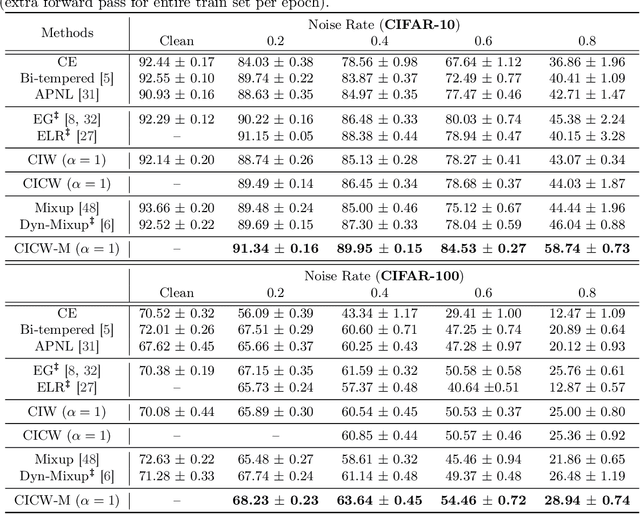
Deep neural networks have shown impressive performance in supervised learning, enabled by their ability to fit well to the provided training data. However, their performance is largely dependent on the quality of the training data and often degrades in the presence of noise. We propose a principled approach for tackling label noise with the aim of assigning importance weights to individual instances and class labels. Our method works by formulating a class of constrained optimization problems that yield simple closed form updates for these importance weights. The proposed optimization problems are solved per mini-batch which obviates the need of storing and updating the weights over the full dataset. Our optimization framework also provides a theoretical perspective on existing label smoothing heuristics for addressing label noise (such as label bootstrapping). We evaluate our method on several benchmark datasets and observe considerable performance gains in the presence of label noise.
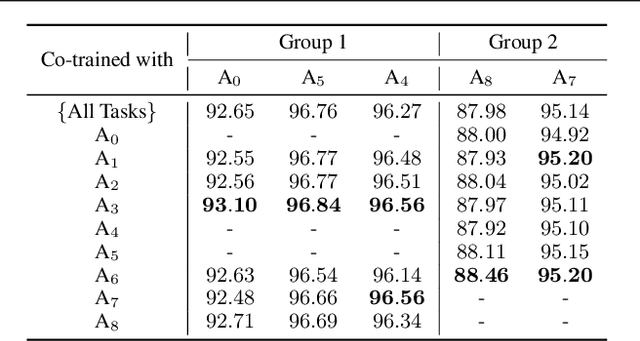
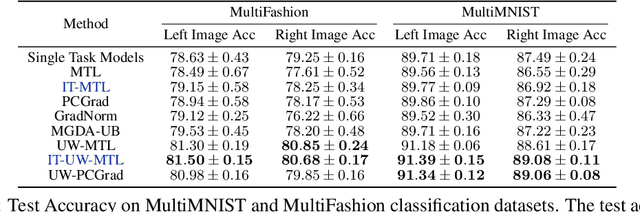
Efficiently Identifying Task Groupings for Multi-Task Learning
Sep 10, 2021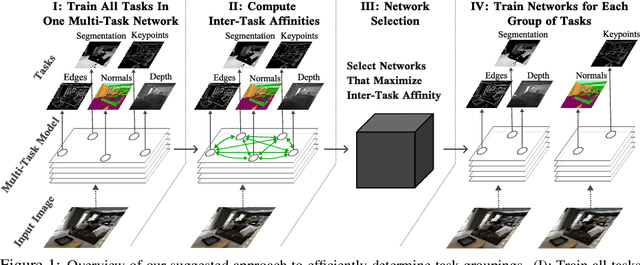
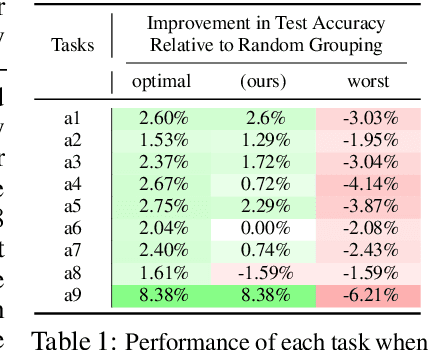
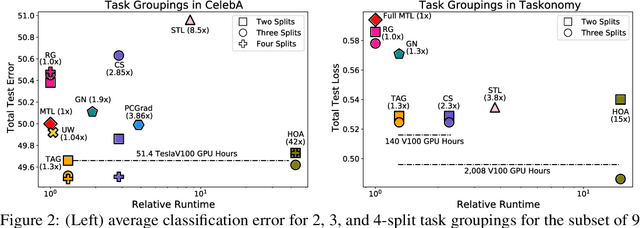
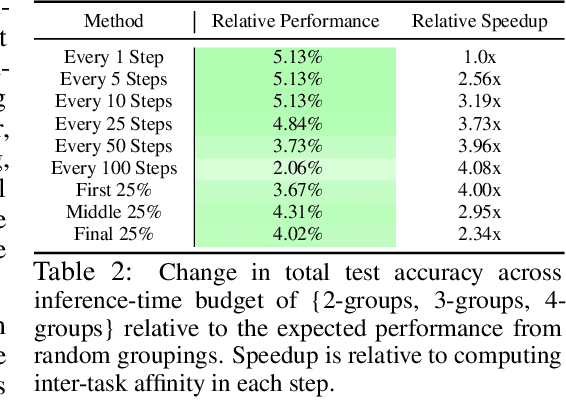
Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, naively training all tasks together in one model often degrades performance, and exhaustively searching through combinations of task groupings can be prohibitively expensive. As a result, efficiently identifying the tasks that would benefit from co-training remains a challenging design question without a clear solution. In this paper, we suggest an approach to select which tasks should train together in multi-task learning models. Our method determines task groupings in a single training run by co-training all tasks together and quantifying the effect to which one task's gradient would affect another task's loss. On the large-scale Taskonomy computer vision dataset, we find this method can decrease test loss by 10.0\% compared to simply training all tasks together while operating 11.6 times faster than a state-of-the-art task grouping method.
LocoProp: Enhancing BackProp via Local Loss Optimization
Jun 11, 2021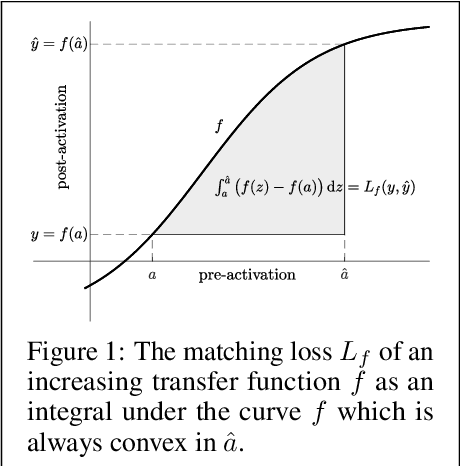


We study a local loss construction approach for optimizing neural networks. We start by motivating the problem as minimizing a squared loss between the pre-activations of each layer and a local target, plus a regularizer term on the weights. The targets are chosen so that the first gradient descent step on the local objectives recovers vanilla BackProp, while the exact solution to each problem results in a preconditioned gradient update. We improve the local loss construction by forming a Bregman divergence in each layer tailored to the transfer function which keeps the local problem convex w.r.t. the weights. The generalized local problem is again solved iteratively by taking small gradient descent steps on the weights, for which the first step recovers BackProp. We run several ablations and show that our construction consistently improves convergence, reducing the gap between first-order and second-order methods.
Exponentiated Gradient Reweighting for Robust Training Under Label Noise and Beyond
Apr 03, 2021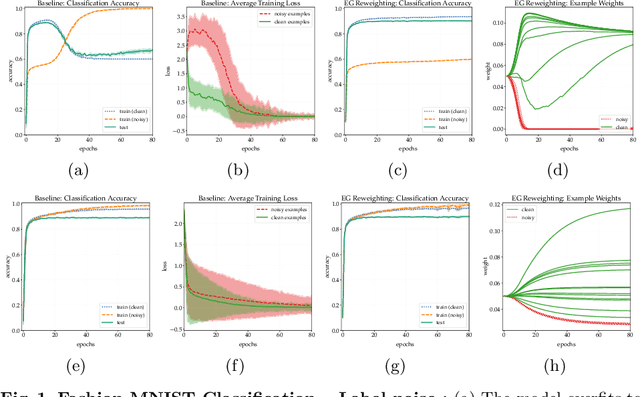
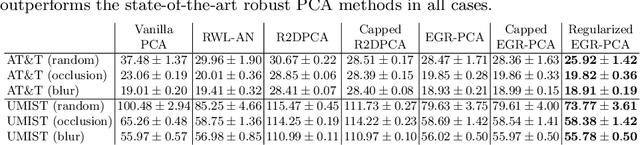
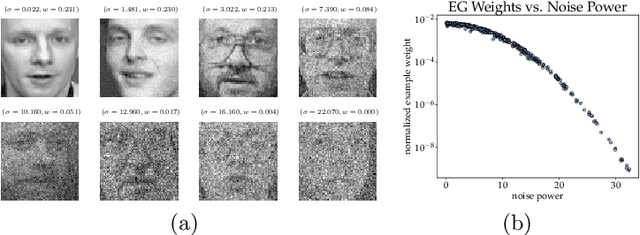

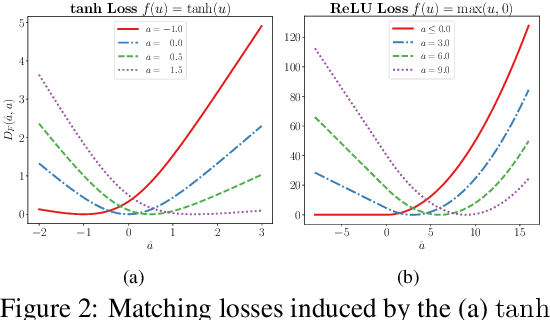
Many learning tasks in machine learning can be viewed as taking a gradient step towards minimizing the average loss of a batch of examples in each training iteration. When noise is prevalent in the data, this uniform treatment of examples can lead to overfitting to noisy examples with larger loss values and result in poor generalization. Inspired by the expert setting in on-line learning, we present a flexible approach to learning from noisy examples. Specifically, we treat each training example as an expert and maintain a distribution over all examples. We alternate between updating the parameters of the model using gradient descent and updating the example weights using the exponentiated gradient update. Unlike other related methods, our approach handles a general class of loss functions and can be applied to a wide range of noise types and applications. We show the efficacy of our approach for multiple learning settings, namely noisy principal component analysis and a variety of noisy classification problems.
Privacy-Preserving Wireless Federated Learning Exploiting Inherent Hardware Impairments
Feb 21, 2021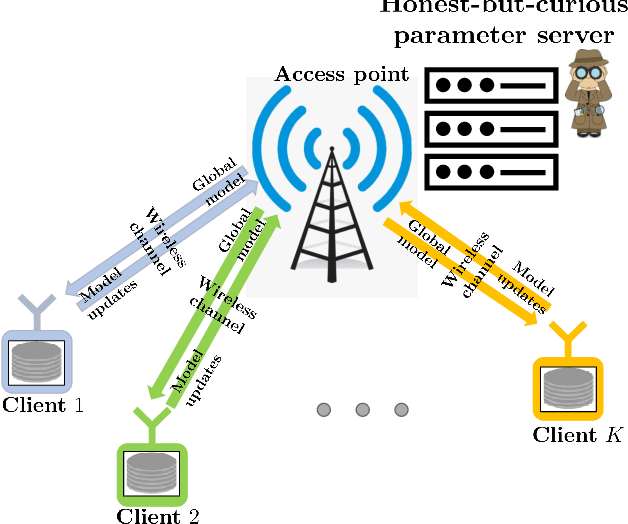
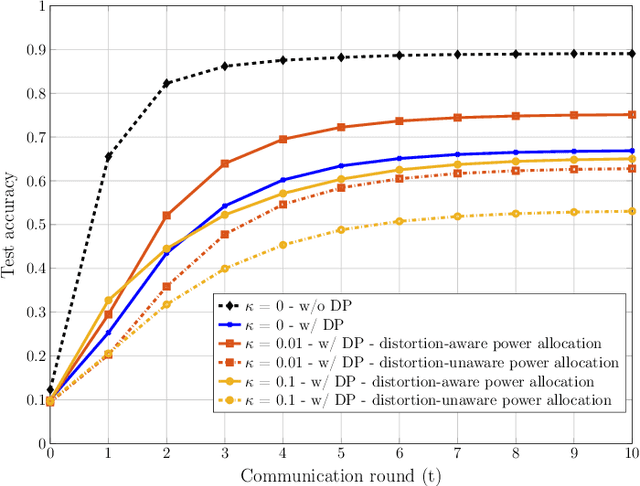
We consider a wireless federated learning system where multiple data holder edge devices collaborate to train a global model via sharing their parameter updates with an honest-but-curious parameter server. We demonstrate that the inherent hardware-induced distortion perturbing the model updates of the edge devices can be exploited as a privacy-preserving mechanism. In particular, we model the distortion as power-dependent additive Gaussian noise and present a power allocation strategy that provides privacy guarantees within the framework of differential privacy. We conduct numerical experiments to evaluate the performance of the proposed power allocation scheme under different levels of hardware impairments.
Rank-smoothed Pairwise Learning In Perceptual Quality Assessment
Nov 21, 2020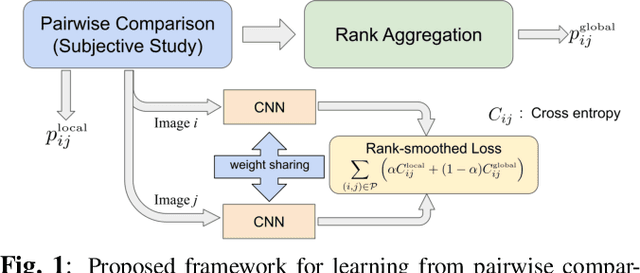
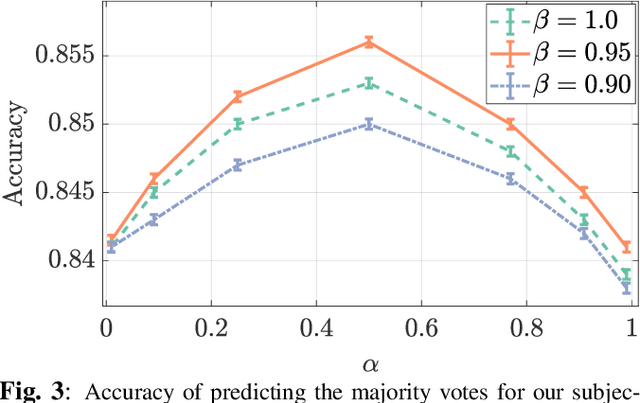

Conducting pairwise comparisons is a widely used approach in curating human perceptual preference data. Typically raters are instructed to make their choices according to a specific set of rules that address certain dimensions of image quality and aesthetics. The outcome of this process is a dataset of sampled image pairs with their associated empirical preference probabilities. Training a model on these pairwise preferences is a common deep learning approach. However, optimizing by gradient descent through mini-batch learning means that the "global" ranking of the images is not explicitly taken into account. In other words, each step of the gradient descent relies only on a limited number of pairwise comparisons. In this work, we demonstrate that regularizing the pairwise empirical probabilities with aggregated rankwise probabilities leads to a more reliable training loss. We show that training a deep image quality assessment model with our rank-smoothed loss consistently improves the accuracy of predicting human preferences.
Measuring and Harnessing Transference in Multi-Task Learning
Oct 29, 2020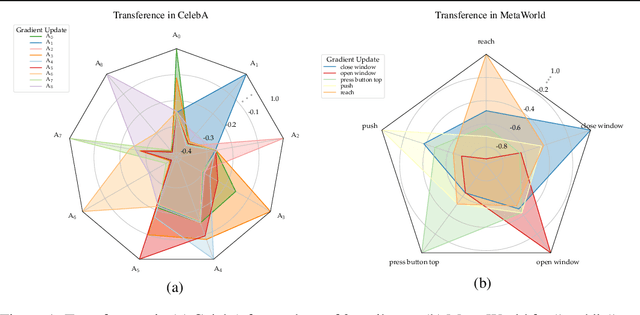

Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, na\"ive formulations often degrade performance and in particular, identifying the tasks that would benefit from co-training remains a challenging design question. In this paper, we analyze the dynamics of information transfer, or transference, across tasks throughout training. Specifically, we develop a similarity measure that can quantify transference among tasks and use this quantity to both better understand the optimization dynamics of multi-task learning as well as improve overall learning performance. In the latter case, we propose two methods to leverage our transference metric. The first operates at a macro-level by selecting which tasks should train together while the second functions at a micro-level by determining how to combine task gradients at each training step. We find these methods can lead to significant improvement over prior work on three supervised multi-task learning benchmarks and one multi-task reinforcement learning paradigm.
A case where a spindly two-layer linear network whips any neural network with a fully connected input layer
Oct 16, 2020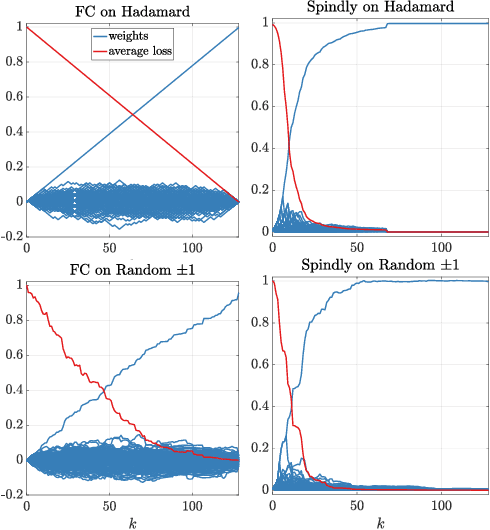
It was conjectured that any neural network of any structure and arbitrary differentiable transfer functions at the nodes cannot learn the following problem sample efficiently when trained with gradient descent: The instances are the rows of a $d$-dimensional Hadamard matrix and the target is one of the features, i.e. very sparse. We essentially prove this conjecture: We show that after receiving a random training set of size $k < d$, the expected square loss is still $1-\frac{k}{(d-1)}$. The only requirement needed is that the input layer is fully connected and the initial weight vectors of the input nodes are chosen from a rotation invariant distribution. Surprisingly the same type of problem can be solved drastically more efficient by a simple 2-layer linear neural network in which the $d$ inputs are connected to the output node by chains of length 2 (Now the input layer has only one edge per input). When such a network is trained by gradient descent, then it has been shown that its expected square loss is $\frac{\log d}{k}$. Our lower bounds essentially show that a sparse input layer is needed to sample efficiently learn sparse targets with gradient descent when the number of examples is less than the number of input features.
Interpolating Between Gradient Descent and Exponentiated Gradient Using Reparameterized Gradient Descent
Feb 24, 2020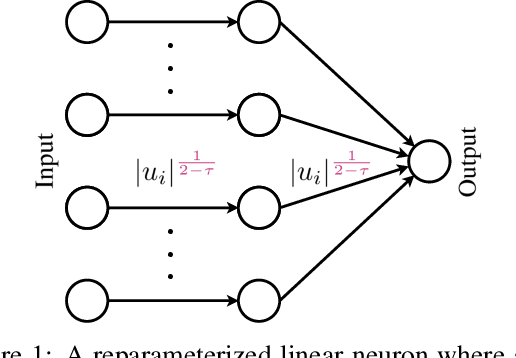

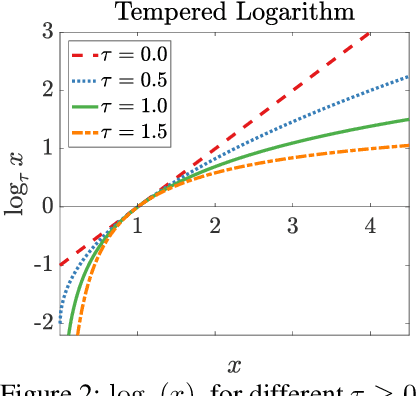
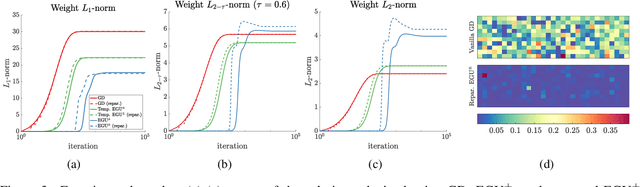
Continuous-time mirror descent (CMD) can be seen as the limit case of the discrete-time MD update when the step-size is infinitesimally small. In this paper, we focus on the geometry of the primal and dual CMD updates and introduce a general framework for reparameterizing one CMD update as another. Specifically, the reparameterized update also corresponds to a CMD, but on the composite loss w.r.t. the new variables, and the original variables are obtained via the reparameterization map. We employ these results to introduce a new family of reparameterizations that interpolate between the two commonly used updates, namely the continuous-time gradient descent (GD) and unnormalized exponentiated gradient (EGU), while extending to many other well-known updates. In particular, we show that for the underdetermined linear regression problem, these updates generalize the known behavior of GD and EGU, and provably converge to the minimum $\mathrm{L}_{2-\tau}$-norm solution for $\tau\in[0,1]$. Our new results also have implications for the regularized training of neural networks to induce sparsity.