 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel and Multi-Objective Falsification with Scenic and VerifAI
Jul 09, 2021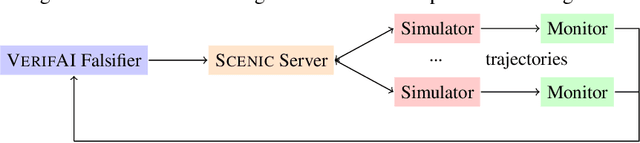

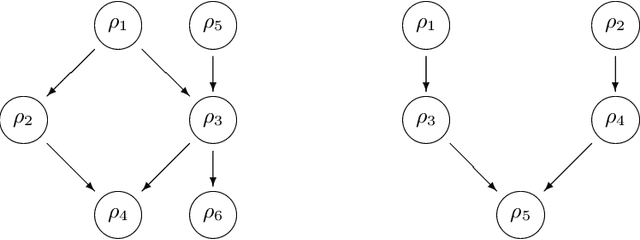
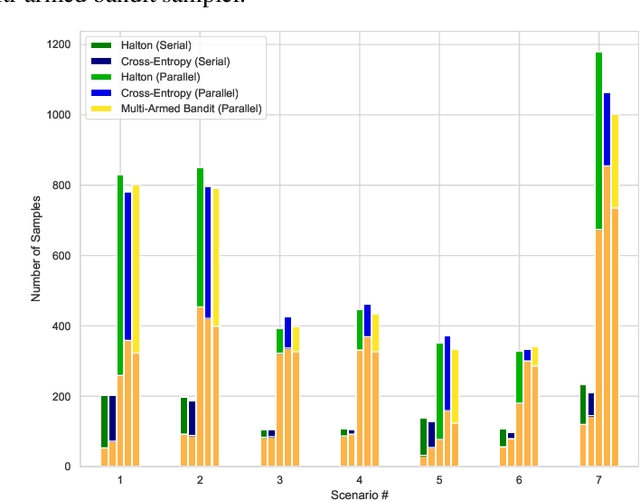
Falsification has emerged as an important tool for simulation-based verification of autonomous systems. In this paper, we present extensions to the Scenic scenario specification language and VerifAI toolkit that improve the scalability of sampling-based falsification methods by using parallelism and extend falsification to multi-objective specifications. We first present a parallelized framework that is interfaced with both the simulation and sampling capabilities of Scenic and the falsification capabilities of VerifAI, reducing the execution time bottleneck inherently present in simulation-based testing. We then present an extension of VerifAI's falsification algorithms to support multi-objective optimization during sampling, using the concept of rulebooks to specify a preference ordering over multiple metrics that can be used to guide the counterexample search process. Lastly, we evaluate the benefits of these extensions with a comprehensive set of benchmarks written in the Scenic language.
Scenic4RL: Programmatic Modeling and Generation of Reinforcement Learning Environments
Jun 18, 2021

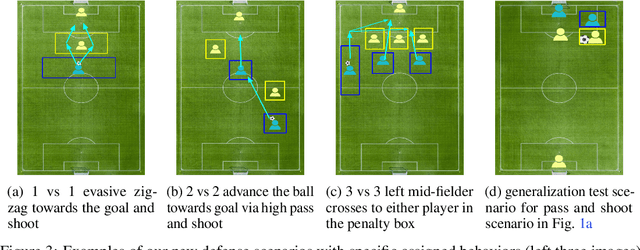
The capability of reinforcement learning (RL) agent directly depends on the diversity of learning scenarios the environment generates and how closely it captures real-world situations. However, existing environments/simulators lack the support to systematically model distributions over initial states and transition dynamics. Furthermore, in complex domains such as soccer, the space of possible scenarios is infinite, which makes it impossible for one research group to provide a comprehensive set of scenarios to train, test, and benchmark RL algorithms. To address this issue, for the first time, we adopt an existing formal scenario specification language, SCENIC, to intuitively model and generate interactive scenarios. We interfaced SCENIC to Google Research Soccer environment to create a platform called SCENIC4RL. Using this platform, we provide a dataset consisting of 36 scenario programs encoded in SCENIC and demonstration data generated from a subset of them. We share our experimental results to show the effectiveness of our dataset and the platform to train, test, and benchmark RL algorithms. More importantly, we open-source our platform to enable RL community to collectively contribute to constructing a comprehensive set of scenarios.
ATRAS: Adversarially Trained Robust Architecture Search
Jun 13, 2021

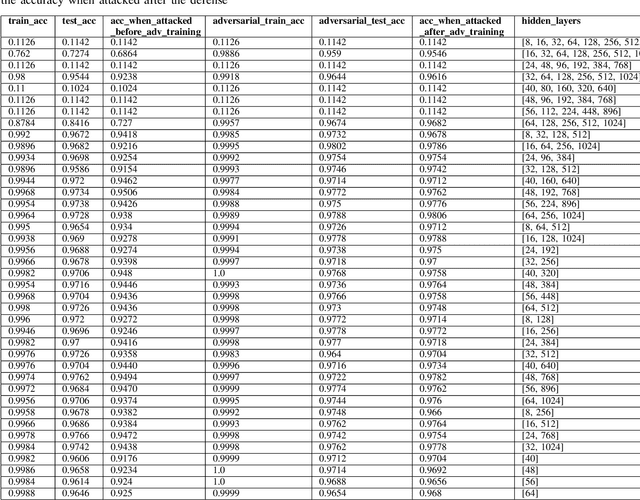
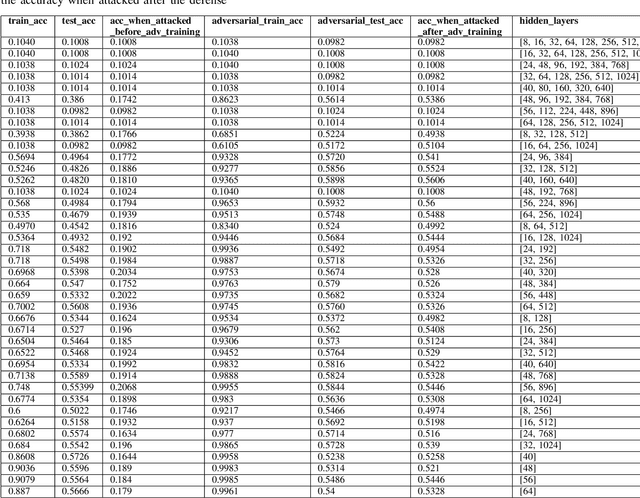
In this paper, we explore the effect of architecture completeness on adversarial robustness. We train models with different architectures on CIFAR-10 and MNIST dataset. For each model, we vary different number of layers and different number of nodes in the layer. For every architecture candidate, we use Fast Gradient Sign Method (FGSM) to generate untargeted adversarial attacks and use adversarial training to defend against those attacks. For each architecture candidate, we report pre-attack, post-attack and post-defense accuracy for the model as well as the architecture parameters and the impact of completeness to the model accuracies.
Functional Protein Structure Annotation Using a Deep Convolutional Generative Adversarial Network
Apr 18, 2021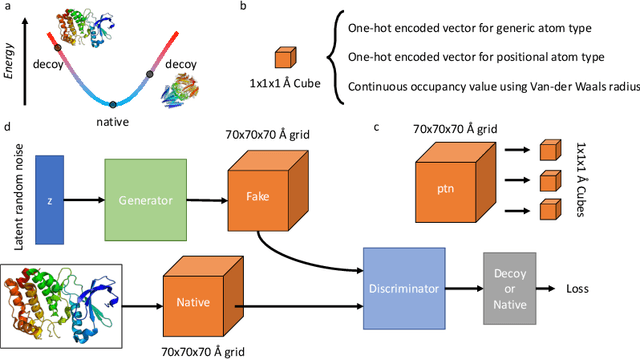
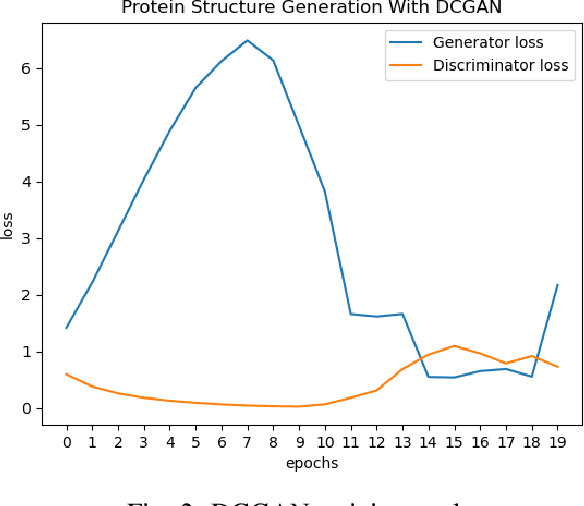
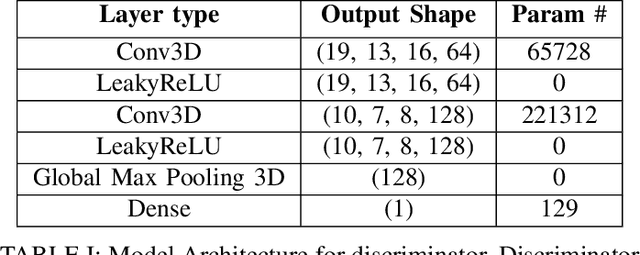
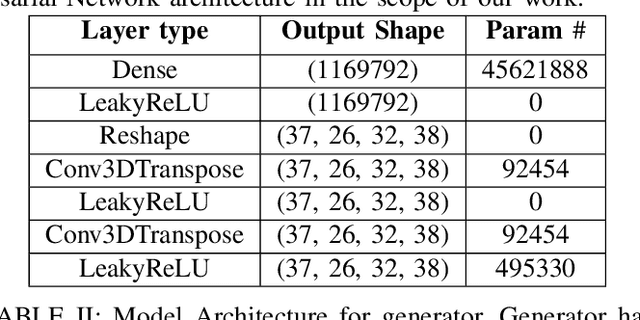
Identifying novel functional protein structures is at the heart of molecular engineering and molecular biology, requiring an often computationally exhaustive search. We introduce the use of a Deep Convolutional Generative Adversarial Network (DCGAN) to classify protein structures based on their functionality by encoding each sample in a grid object structure using three features in each object: the generic atom type, the position atom type, and its occupancy relative to a given atom. We train DCGAN on 3-dimensional (3D) decoy and native protein structures in order to generate and discriminate 3D protein structures. At the end of our training, loss converges to a local minimum and our DCGAN can annotate functional proteins robustly against adversarial protein samples. In the future we hope to extend the novel structures we found from the generator in our DCGAN with more samples to explore more granular functionality with varying functions. We hope that our effort will advance the field of protein structure prediction.
Extreme Volatility Prediction in Stock Market: When GameStop meets Long Short-Term Memory Networks
Mar 09, 2021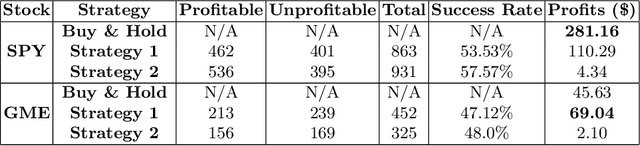
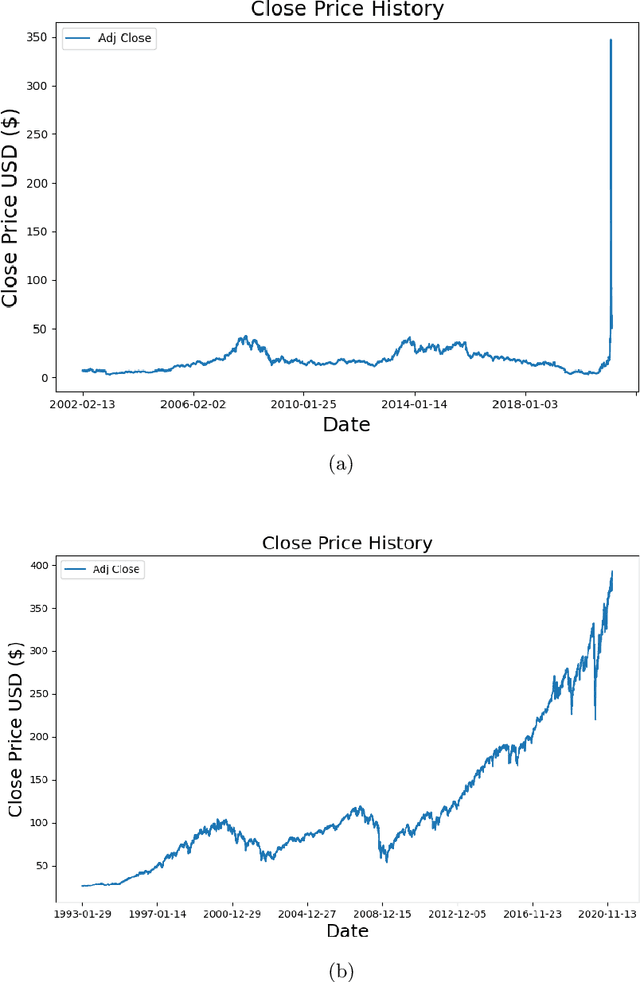
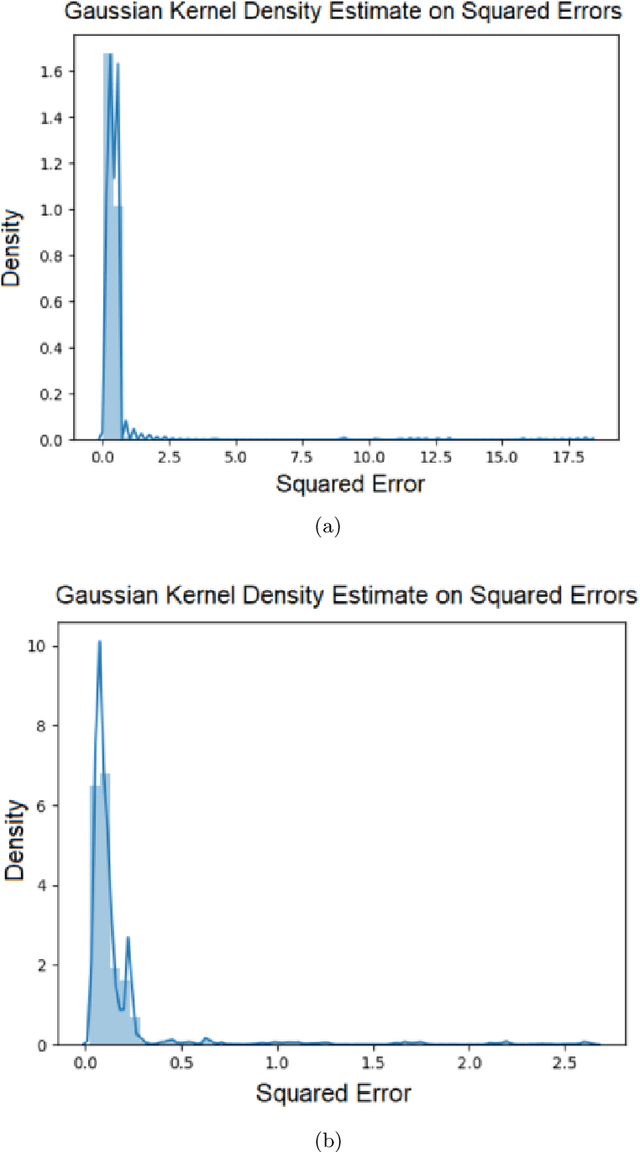
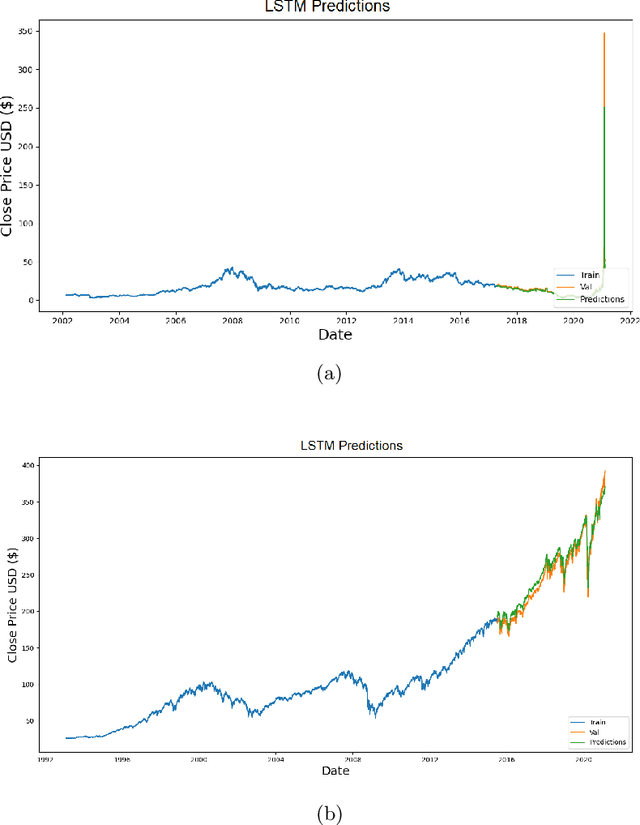
The beginning of 2021 saw a surge in volatility for certain stocks such as GameStop company stock (Ticker GME under NYSE). GameStop stock increased around 10 fold from its decade-long average to its peak at \$485. In this paper, we hypothesize a buy-and-hold strategy can be outperformed in the presence of extreme volatility by predicting and trading consolidation breakouts. We investigate GME stock for its volatility and compare it to SPY as a benchmark (since it is a less volatile ETF fund) from February 2002 to February 2021. For strategy 1, we develop a Long Short-term Memory (LSTM) Neural Network to predict stock prices recurrently with a very short look ahead period in the presence of extreme volatility. For our strategy 2, we develop an LSTM autoencoder network specifically designed to trade only on consolidation breakouts after predicting anomalies in the stock price. When back-tested in our simulations, our strategy 1 executes 863 trades for SPY and 452 trades for GME. Our strategy 2 executes 931 trades for SPY and 325 trades for GME. We compare both strategies to buying and holding one single share for the period that we picked as a benchmark. In our simulations, SPY returns \$281.160 from buying and holding one single share, \$110.29 from strategy 1 with 53.5% success rate and \$4.34 from strategy 2 with 57.6% success rate. GME returns \$45.63 from buying and holding one single share, \$69.046 from strategy 1 with 47.12% success rate and \$2.10 from strategy 2 with 48% success rate. Overall, buying and holding outperforms all deep-learning assisted prediction models in our study except for when the LSTM-based prediction model (strategy 1) is applied to GME. We hope that our study sheds more light into the field of extreme volatility predictions based on LSTMs to outperform buying and holding strategy.
Robust SleepNets
Feb 24, 2021
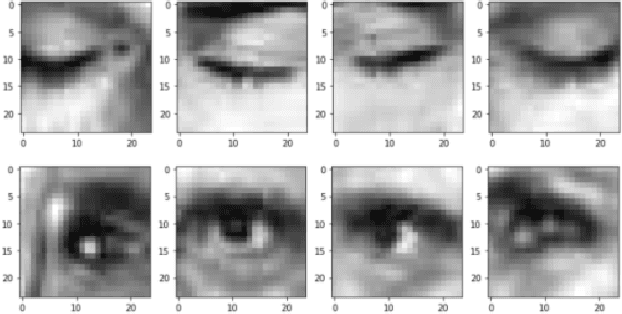
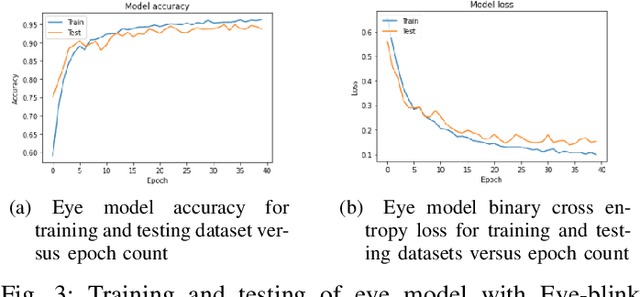
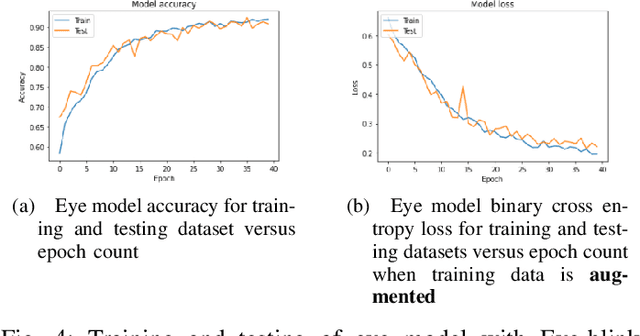
State-of-the-art convolutional neural networks excel in machine learning tasks such as face recognition, and object classification but suffer significantly when adversarial attacks are present. It is crucial that machine critical systems, where machine learning models are deployed, utilize robust models to handle a wide range of variability in the real world and malicious actors that may use adversarial attacks. In this study, we investigate eye closedness detection to prevent vehicle accidents related to driver disengagements and driver drowsiness. Specifically, we focus on adversarial attacks in this application domain, but emphasize that the methodology can be applied to many other domains. We develop two models to detect eye closedness: first model on eye images and a second model on face images. We adversarially attack the models with Projected Gradient Descent, Fast Gradient Sign and DeepFool methods and report adversarial success rate. We also study the effect of training data augmentation. Finally, we adversarially train the same models on perturbed images and report the success rate for the defense against these attacks. We hope our study sets up the work to prevent potential vehicle accidents by capturing drivers' face images and alerting them in case driver's eyes are closed due to drowsiness.
Evaluating Online and Offline Accuracy Traversal Algorithms for k-Complete Neural Network Architectures
Jan 16, 2021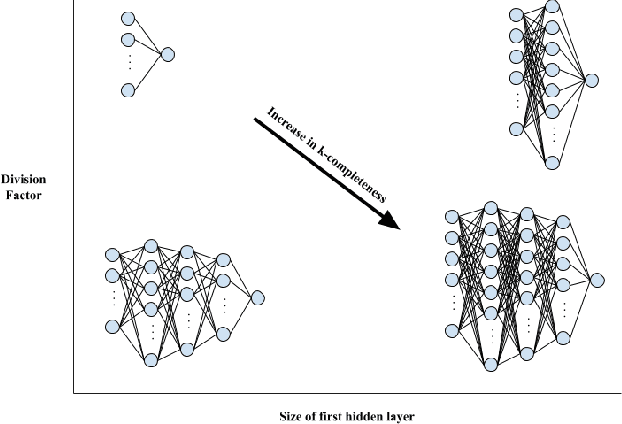
Architecture sizes for neural networks have been studied widely and several search methods have been offered to find the best architecture size in the shortest amount of time possible. In this paper, we study compact neural network architectures for binary classification and investigate improvements in speed and accuracy when favoring overcomplete architecture candidates that have a very high-dimensional representation of the input. We hypothesize that an overcomplete model architecture that creates a relatively high-dimensional representation of the input will be not only be more accurate but would also be easier and faster to find. In an NxM search space, we propose an online traversal algorithm that finds the best architecture candidate in O(1) time for best case and O(N) amortized time for average case for any compact binary classification problem by using k-completeness as heuristics in our search. The two other offline search algorithms we implement are brute force traversal and diagonal traversal, which both find the best architecture candidate in O(NxM) time. We compare our new algorithm to brute force and diagonal searching as a baseline and report search time improvement of 52.1% over brute force and of 15.4% over diagonal search to find the most accurate neural network architecture when given the same dataset. In all cases discussed in the paper, our online traversal algorithm can find an accurate, if not better, architecture in significantly shorter amount of time.
Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Jan 16, 2021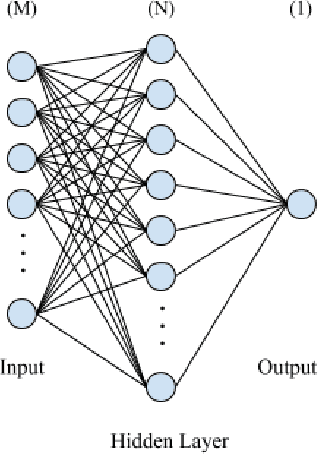
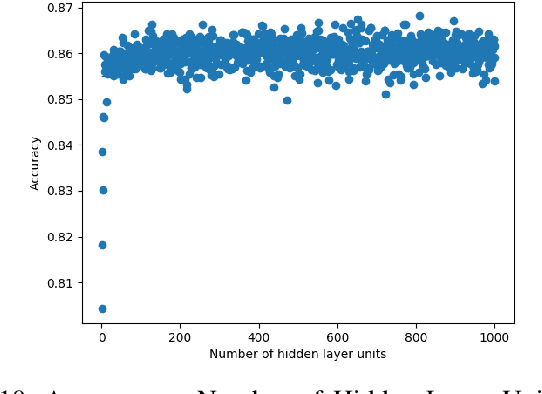
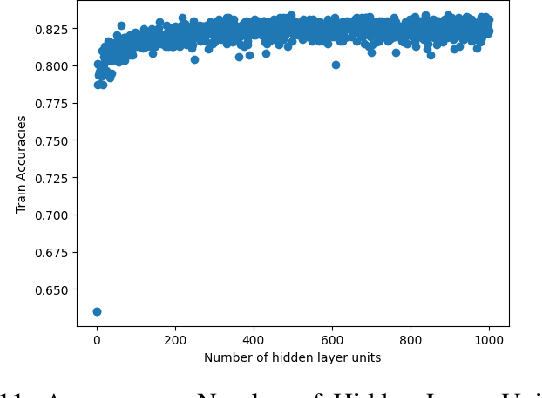
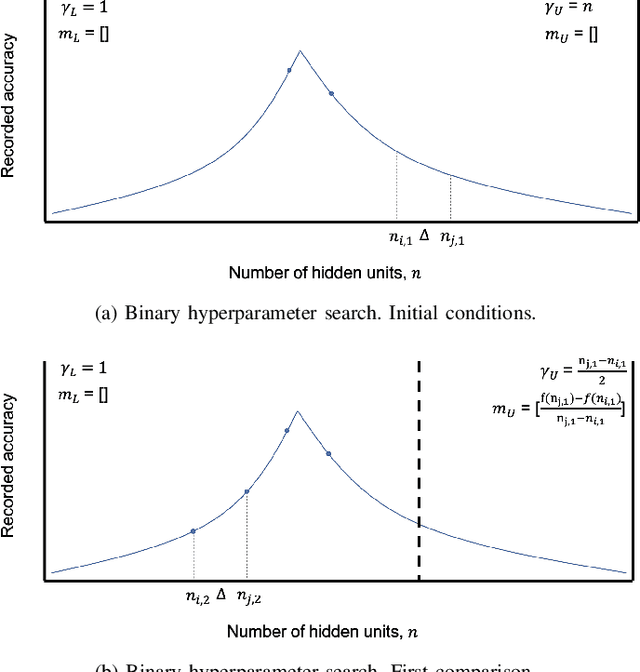
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.
A Customizable Dynamic Scenario Modeling and Data Generation Platform for Autonomous Driving
Nov 30, 2020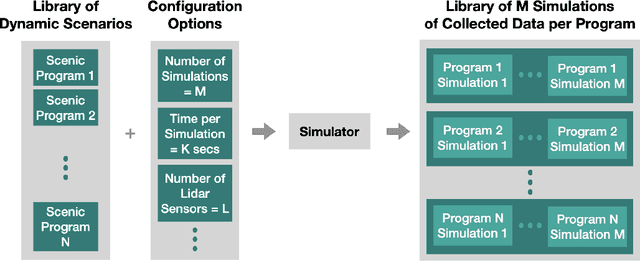
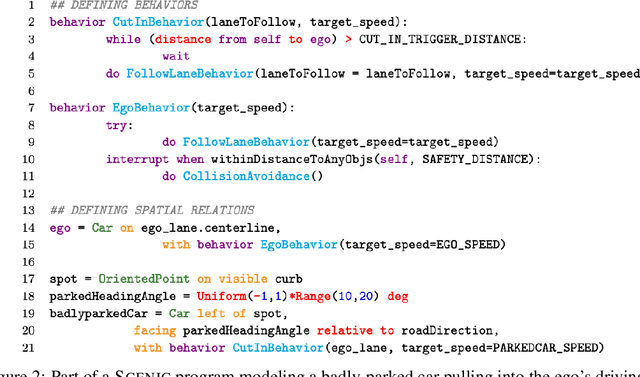
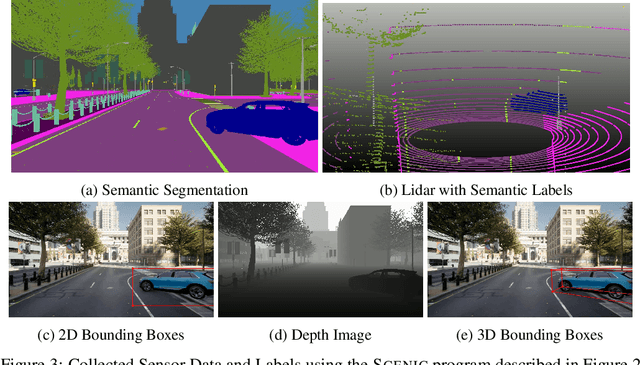
Safely interacting with humans is a significant challenge for autonomous driving. The performance of this interaction depends on machine learning-based modules of an autopilot, such as perception, behavior prediction, and planning. These modules require training datasets with high-quality labels and a diverse range of realistic dynamic behaviors. Consequently, training such modules to handle rare scenarios is difficult because they are, by definition, rarely represented in real-world datasets. Hence, there is a practical need to augment datasets with synthetic data covering these rare scenarios. In this paper, we present a platform to model dynamic and interactive scenarios, generate the scenarios in simulation with different modalities of labeled sensor data, and collect this information for data augmentation. To our knowledge, this is the first integrated platform for these tasks specialized to the autonomous driving domain.
The Interpretable Dictionary in Sparse Coding
Nov 24, 2020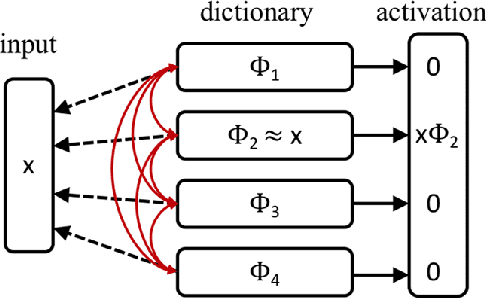
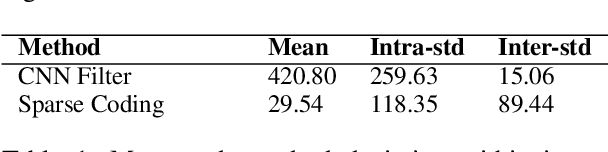


Artificial neural networks (ANNs), specifically deep learning networks, have often been labeled as black boxes due to the fact that the internal representation of the data is not easily interpretable. In our work, we illustrate that an ANN, trained using sparse coding under specific sparsity constraints, yields a more interpretable model than the standard deep learning model. The dictionary learned by sparse coding can be more easily understood and the activations of these elements creates a selective feature output. We compare and contrast our sparse coding model with an equivalent feed forward convolutional autoencoder trained on the same data. Our results show both qualitative and quantitative benefits in the interpretation of the learned sparse coding dictionary as well as the internal activation representations.