 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Persistent and Context-aware Behavior Tree Framework for Multi Sensor Localization in Autonomous Driving
Mar 26, 2021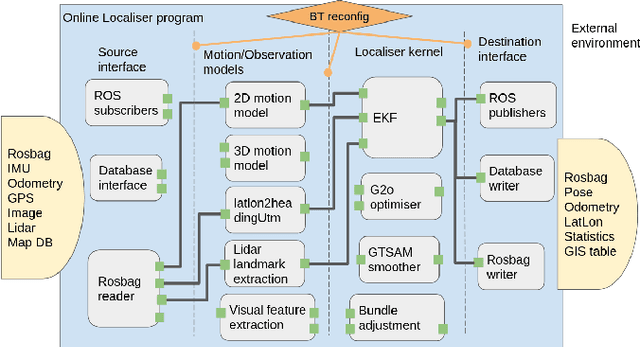
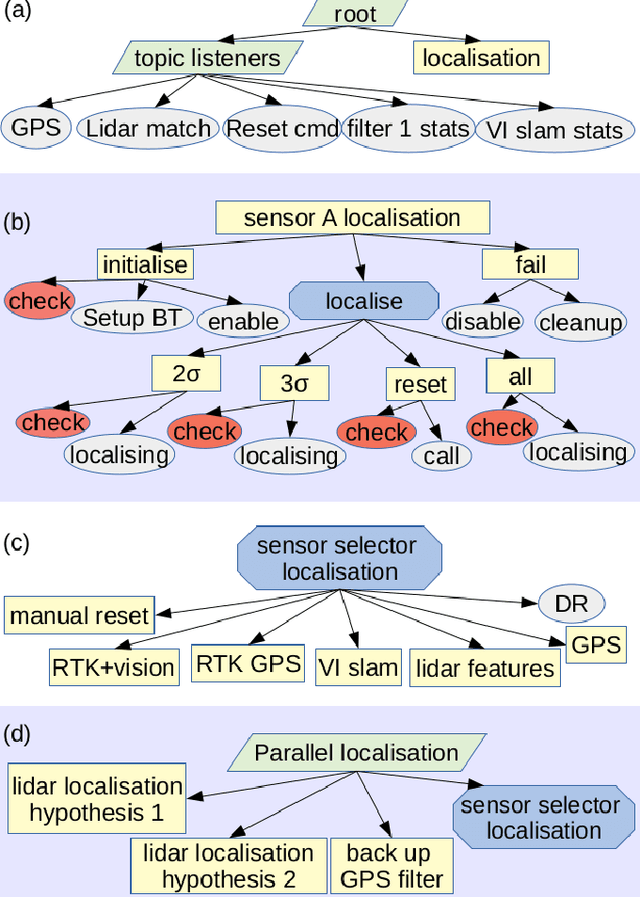
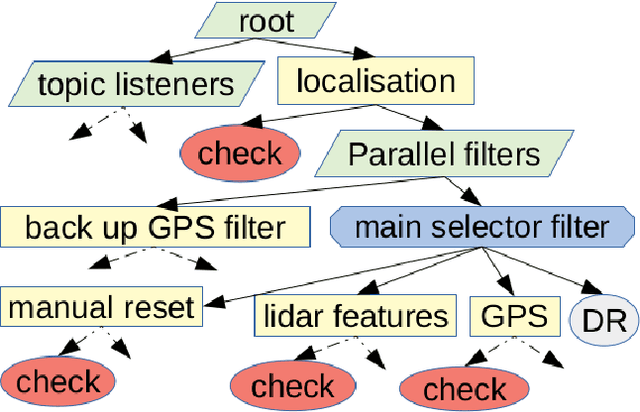
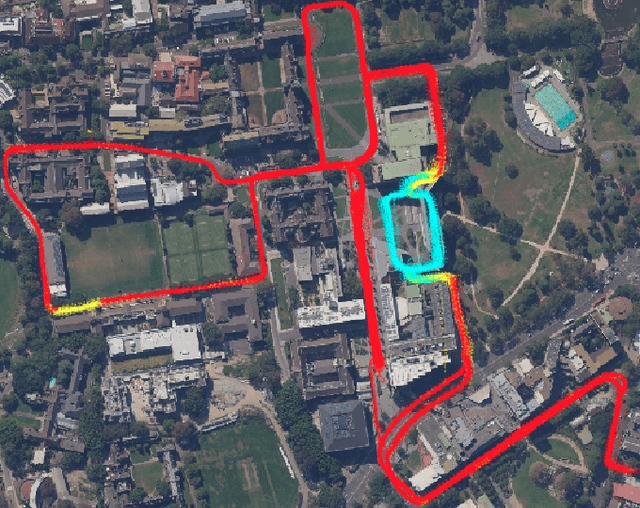
Robust and persistent localisation is essential for ensuring the safe operation of autonomous vehicles. When operating in large and diverse urban driving environments, autonomous vehicles are frequently exposed to situations that violate the assumptions of algorithms, suffer from the failure of one or more sensors, or other events that lead to a loss of localisation. This paper proposes the use of a behavior tree framework that can monitor the performance of localisation health metrics and triggers intelligent responses such as sensor switching and loss recovery. The algorithm presented selects the best available sensor data at given time and location, and can perform a series of actions to react to adverse situations. The behavior tree encapsulates the system-level logic to give commands that make up the intelligent behaviors, so that the localisation "actuators" (data association, optimisation, filters, etc) can perform decoupled actions without needing context. Experimental results to validate the algorithms are presented using the University of Sydney Campus dataset which was taken weekly over an 18 month period. A video showing the online localisation process can be found here: https://youtu.be/353uKqXLV5g
Optimising the selection of samples for robust lidar camera calibration
Mar 23, 2021


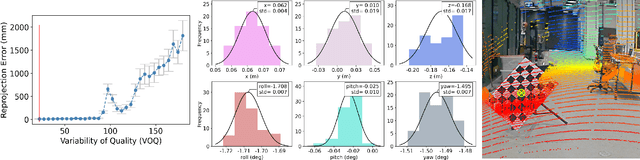
We propose a robust calibration pipeline that optimises the selection of calibration samples for the estimation of calibration parameters that fit the entire scene. We minimise user error by automating the data selection process according to a metric, called Variability of Quality (VOQ) that gives a score to each calibration set of samples. We show that this VOQ score is correlated with the estimated calibration parameter's ability to generalise well to the entire scene, thereby overcoming the overfitting problems of existing calibration algorithms. Our approach has the benefits of simplifying the calibration process for practitioners of any calibration expertise level and providing an objective measure of the quality for our calibration pipeline's input and output data. We additionally use a novel method of assessing the accuracy of the calibration parameters. It involves computing reprojection errors for the entire scene to ensure that the parameters are well fitted to all features in the scene. Our proposed calibration pipeline takes 90s, and obtains an average reprojection error of 1-1.2cm, with standard deviation of 0.4-0.5cm over 46 poses evenly distributed in a scene. This process has been validated by experimentation on a high resolution, software definable lidar, Baraja Spectrum-Scan; and a low, fixed resolution lidar, Velodyne VLP-16. We have shown that despite the vast differences in lidar technologies, our proposed approach manages to estimate robust calibration parameters for both. Our code and data set used for this paper are made available as open-source.
Socially Aware Crowd Navigation with Multimodal Pedestrian Trajectory Prediction for Autonomous Vehicles
Nov 23, 2020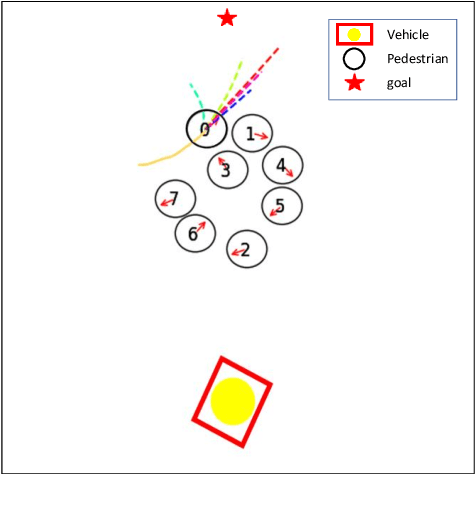
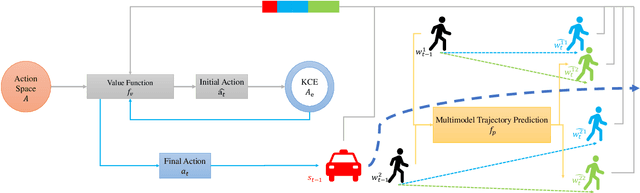
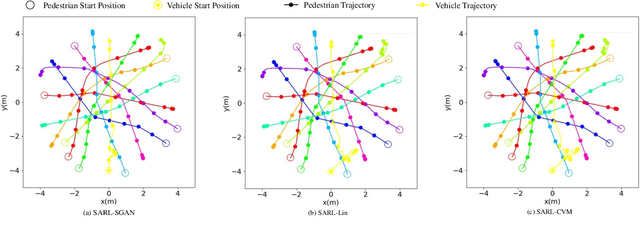
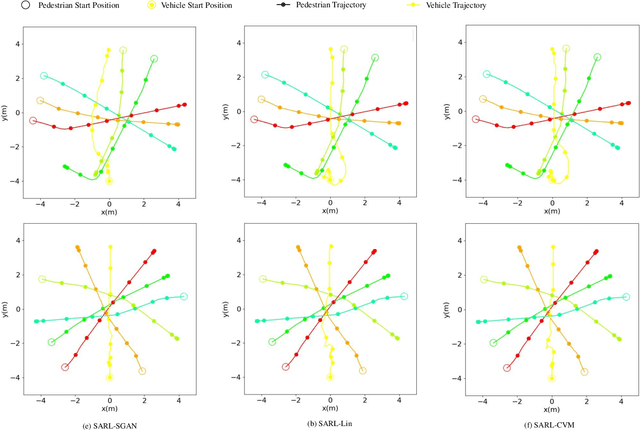
Seamlessly operating an autonomous vehicle in a crowded pedestrian environment is a very challenging task. This is because human movement and interactions are very hard to predict in such environments. Recent work has demonstrated that reinforcement learning-based methods have the ability to learn to drive in crowds. However, these methods can have very poor performance due to inaccurate predictions of the pedestrians' future state as human motion prediction has a large variance. To overcome this problem, we propose a new method, SARL-SGAN-KCE, that combines a deep socially aware attentive value network with a human multimodal trajectory prediction model to help identify the optimal driving policy. We also introduce a novel technique to extend the discrete action space with minimal additional computational requirements. The kinematic constraints of the vehicle are also considered to ensure smooth and safe trajectories. We evaluate our method against the state of art methods for crowd navigation and provide an ablation study to show that our method is safer and closer to human behaviour.
Attentional-GCNN: Adaptive Pedestrian Trajectory Prediction towards Generic Autonomous Vehicle Use Cases
Nov 23, 2020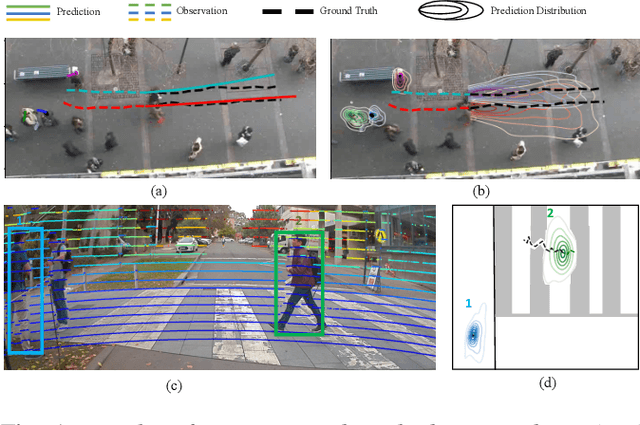
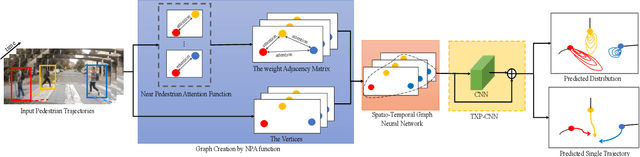
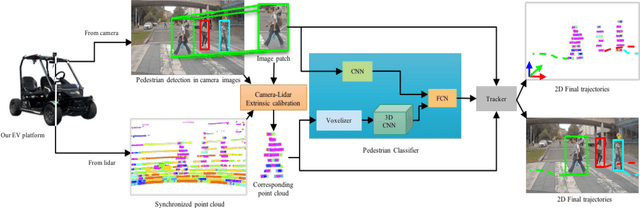

Autonomous vehicle navigation in shared pedestrian environments requires the ability to predict future crowd motion both accurately and with minimal delay. Understanding the uncertainty of the prediction is also crucial. Most existing approaches however can only estimate uncertainty through repeated sampling of generative models. Additionally, most current predictive models are trained on datasets that assume complete observability of the crowd using an aerial view. These are generally not representative of real-world usage from a vehicle perspective, and can lead to the underestimation of uncertainty bounds when the on-board sensors are occluded. Inspired by prior work in motion prediction using spatio-temporal graphs, we propose a novel Graph Convolutional Neural Network (GCNN)-based approach, Attentional-GCNN, which aggregates information of implicit interaction between pedestrians in a crowd by assigning attention weight in edges of the graph. Our model can be trained to either output a probabilistic distribution or faster deterministic prediction, demonstrating applicability to autonomous vehicle use cases where either speed or accuracy with uncertainty bounds are required. To further improve the training of predictive models, we propose an automatically labelled pedestrian dataset collected from an intelligent vehicle platform representative of real-world use. Through experiments on a number of datasets, we show our proposed method achieves an improvement over the state of art by 10% Average Displacement Error (ADE) and 12% Final Displacement Error (FDE) with fast inference speeds.
Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations
Nov 17, 2020
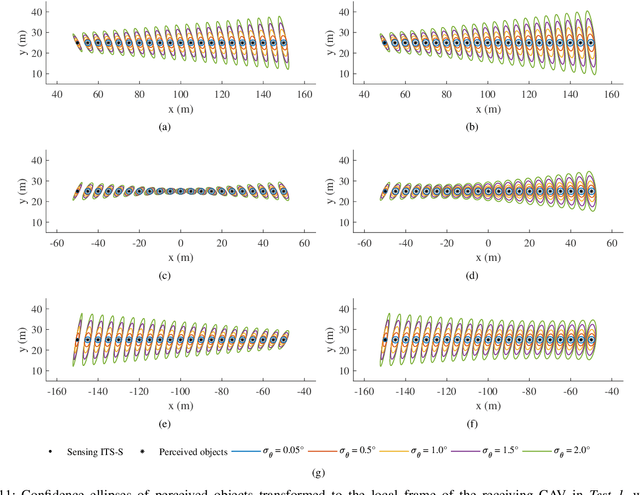
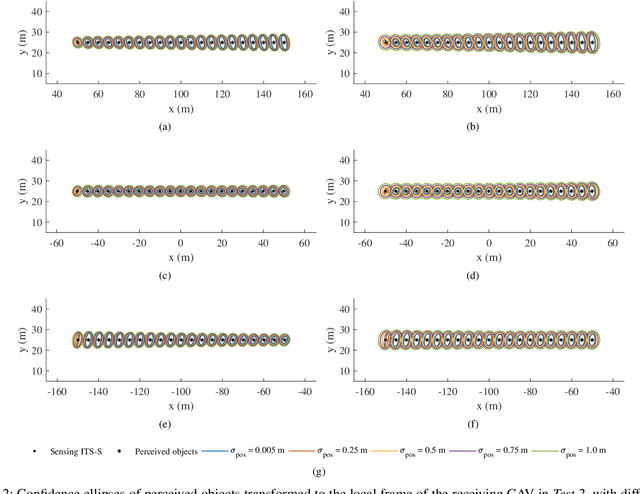
Cooperative perception, or collective perception (CP) is an emerging and promising technology for intelligent transportation systems (ITS). It enables an ITS station (ITS-S) to share its local perception information with others by means of vehicle-to-X (V2X) communication, thereby achieving improved efficiency and safety in road transportation. In this paper, we present our recent progress on the development of a connected and automated vehicle (CAV) and intelligent roadside unit (IRSU). We present three different experiments to demonstrate the use of CP service within intelligent infrastructure to improve awareness of vulnerable road users (VRU) and thus safety for CAVs in various traffic scenarios. We demonstrate in the experiments that a connected vehicle (CV) can "see" a pedestrian around the corners. More importantly, we demonstrate how CAVs can autonomously and safely interact with walking and running pedestrians, relying only on the CP information from the IRSU through vehicle-to-infrastructure (V2I) communication. This is one of the first demonstrations of urban vehicle automation using only CP information. We also address in the paper the handling of collective perception messages (CPMs) received from the IRSU, and passing them through a pipeline of CP information coordinate transformation with uncertainty, multiple road user tracking, and eventually path planning/decision making within the CAV. The experimental results were obtained with manually driven CV, fully autonomous CAV, and an IRSU retrofitted with vision and laser sensors and a road user tracking system.
Efficient falsification approach for autonomous vehicle validation using a parameter optimisation technique based on reinforcement learning
Nov 16, 2020
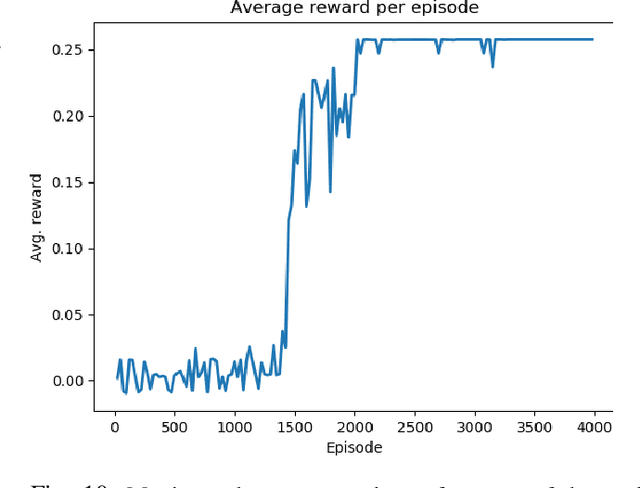
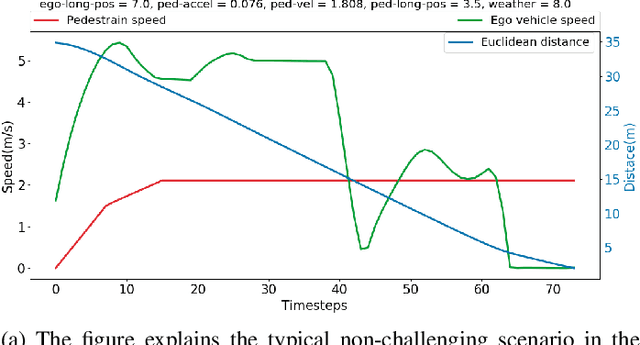
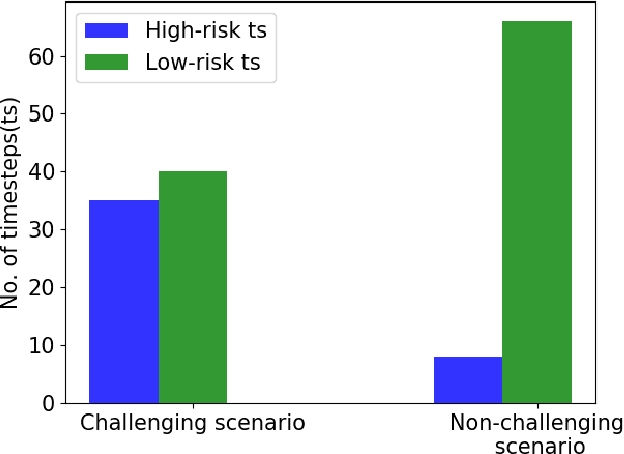
The widescale deployment of Autonomous Vehicles (AV) appears to be imminent despite many safety challenges that are yet to be resolved. It is well-known that there are no universally agreed Verification and Validation (VV) methodologies guarantee absolute safety, which is crucial for the acceptance of this technology. The uncertainties in the behaviour of the traffic participants and the dynamic world cause stochastic reactions in advanced autonomous systems. The addition of ML algorithms and probabilistic techniques adds significant complexity to the process for real-world testing when compared to traditional methods. Most research in this area focuses on generating challenging concrete scenarios or test cases to evaluate the system performance by looking at the frequency distribution of extracted parameters as collected from the real-world data. These approaches generally employ Monte-Carlo simulation and importance sampling to generate critical cases. This paper presents an efficient falsification method to evaluate the System Under Test. The approach is based on a parameter optimisation problem to search for challenging scenarios. The optimisation process aims at finding the challenging case that has maximum return. The method applies policy-gradient reinforcement learning algorithm to enable the learning. The riskiness of the scenario is measured by the well established RSS safety metric, euclidean distance, and instance of a collision. We demonstrate that by using the proposed method, we can more efficiently search for challenging scenarios which could cause the system to fail in order to satisfy the safety requirements.
Long-term map maintenance pipeline for autonomous vehicles
Aug 28, 2020
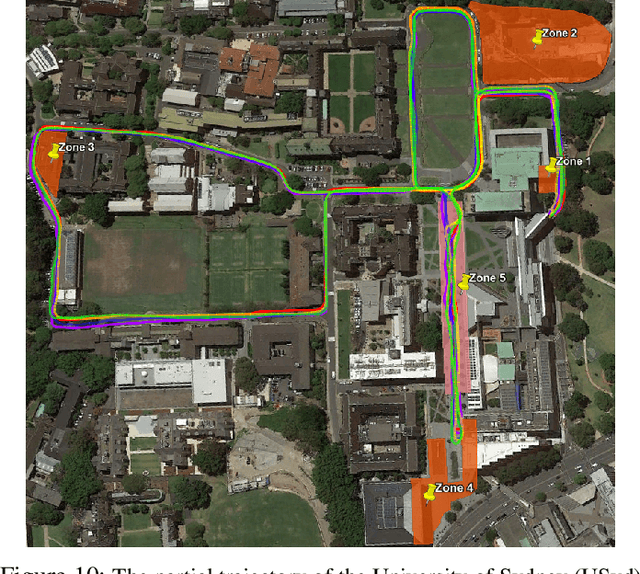
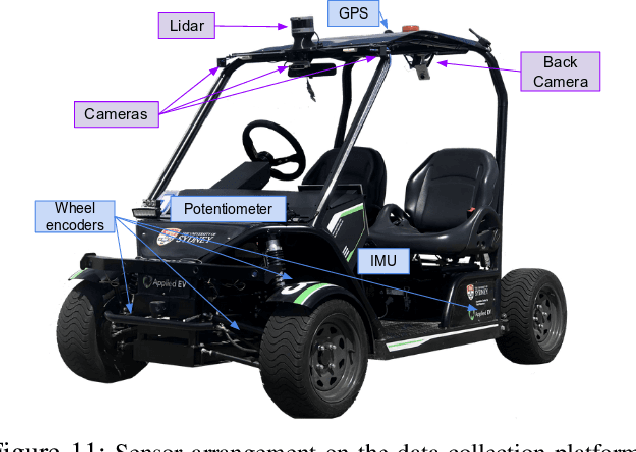

For autonomous vehicles to operate persistently in a typical urban environment, it is essential to have high accuracy position information. This requires a mapping and localisation system that can adapt to changes over time. A localisation approach based on a single-survey map will not be suitable for long-term operation as it does not incorporate variations in the environment. In this paper, we present new algorithms to maintain a featured-based map. A map maintenance pipeline is proposed that can continuously update a map with the most relevant features taking advantage of the changes in the surroundings. Our pipeline detects and removes transient features based on their geometrical relationships with the vehicle's pose. Newly identified features became part of a new feature map and are assessed by the pipeline as candidates for the localisation map. By purging out-of-date features and adding newly detected features, we continually update the prior map to more accurately represent the most recent environment. We have validated our approach using the USyd Campus Dataset, which includes more than 18 months of data. The results presented demonstrate that our maintenance pipeline produces a resilient map which can provide sustained localisation performance over time.
Probabilistic Crowd GAN: Multimodal Pedestrian Trajectory Prediction using a Graph Vehicle-Pedestrian Attention Network
Jul 12, 2020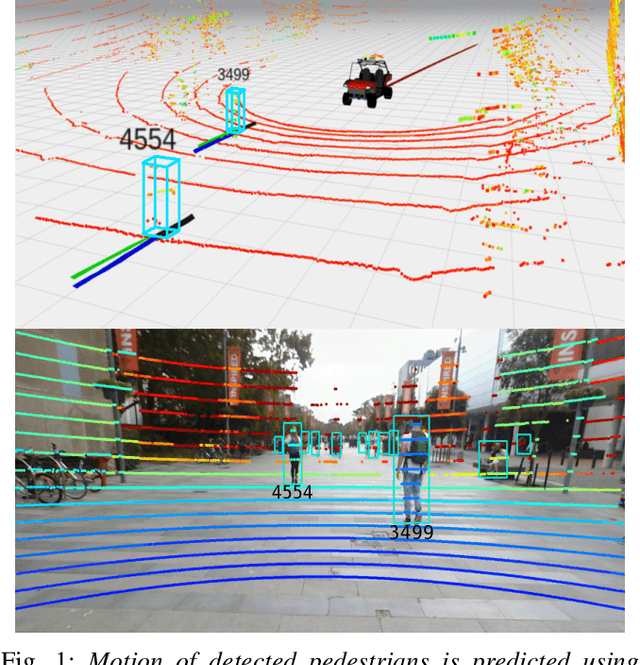
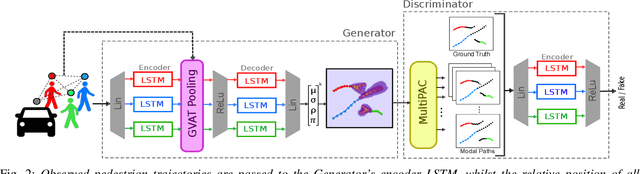
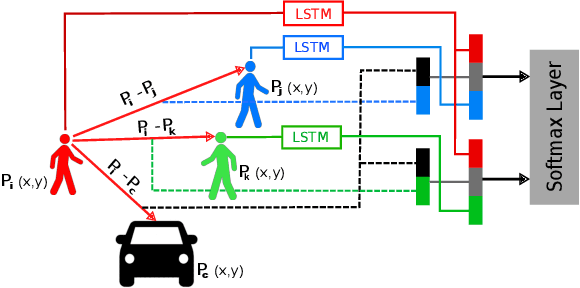
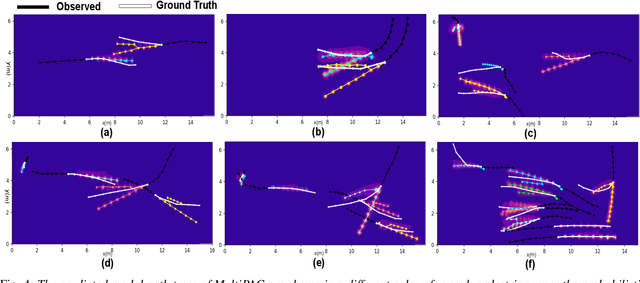
Understanding and predicting the intention of pedestrians is essential to enable autonomous vehicles and mobile robots to navigate crowds. This problem becomes increasingly complex when we consider the uncertainty and multimodality of pedestrian motion, as well as the implicit interactions between members of a crowd, including any response to a vehicle. Our approach, Probabilistic Crowd GAN, extends recent work in trajectory prediction, combining Recurrent Neural Networks (RNNs) with Mixture Density Networks (MDNs) to output probabilistic multimodal predictions, from which likely modal paths are found and used for adversarial training. We also propose the use of Graph Vehicle-Pedestrian Attention Network (GVAT), which models social interactions and allows input of a shared vehicle feature, showing that inclusion of this module leads to improved trajectory prediction both with and without the presence of a vehicle. Through evaluation on various datasets, we demonstrate improvements on the existing state of the art methods for trajectory prediction and illustrate how the true multimodal and uncertain nature of crowd interactions can be directly modelled.
Camera-Lidar Integration: Probabilistic sensor fusion for semantic mapping
Jul 09, 2020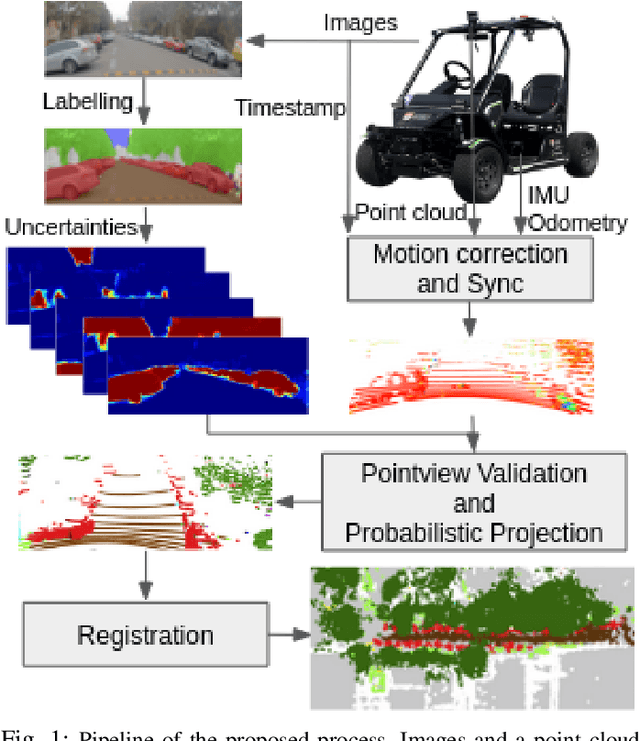
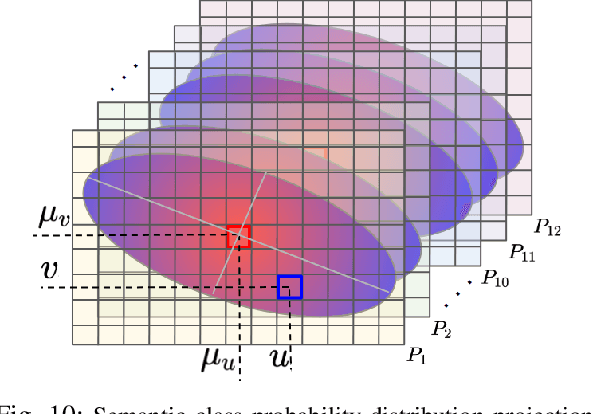
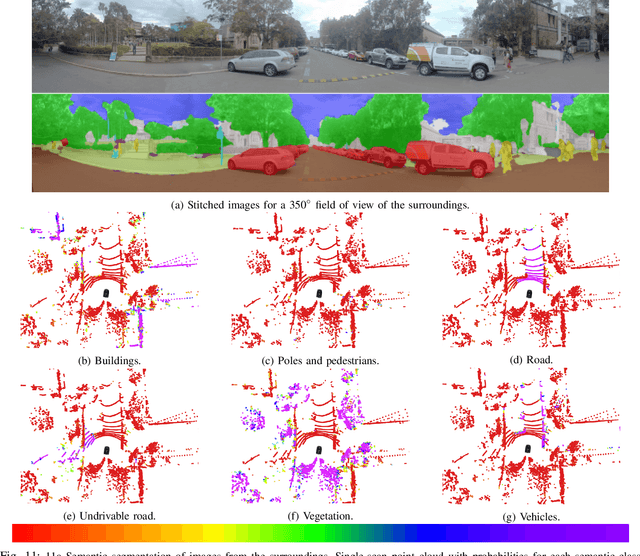
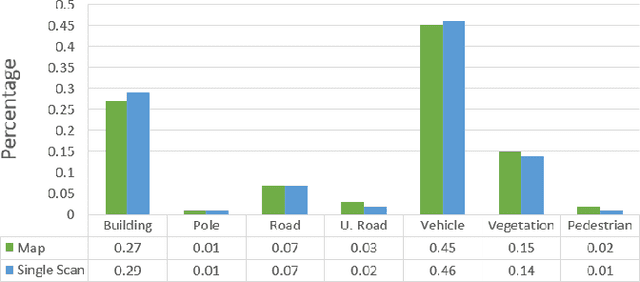
An automated vehicle operating in an urban environment must be able to perceive and recognise object/obstacles in a three-dimensional world while navigating in a constantly changing environment. In order to plan and execute accurate sophisticated driving maneuvers, a high-level contextual understanding of the surroundings is essential. Due to the recent progress in image processing, it is now possible to obtain high definition semantic information in 2D from monocular cameras, though cameras cannot reliably provide the highly accurate 3D information provided by lasers. The fusion of these two sensor modalities can overcome the shortcomings of each individual sensor, though there are a number of important challenges that need to be addressed in a probabilistic manner. In this paper, we address the common, yet challenging, lidar/camera/semantic fusion problems which are seldom approached in a wholly probabilistic manner. Our approach is capable of using a multi-sensor platform to build a three-dimensional semantic voxelized map that considers the uncertainty of all of the processes involved. We present a probabilistic pipeline that incorporates uncertainties from the sensor readings (cameras, lidar, IMU and wheel encoders), compensation for the motion of the vehicle, and heuristic label probabilities for the semantic images. We also present a novel and efficient viewpoint validation algorithm to check for occlusions from the camera frames. A probabilistic projection is performed from the camera images to the lidar point cloud. Each labelled lidar scan then feeds into an octree map building algorithm that updates the class probabilities of the map voxels every time a new observation is available. We validate our approach using a set of qualitative and quantitative experimental tests on the USyd Dataset.
Probabilistic Egocentric Motion Correction of Lidar Point Cloud and Projection to Camera Images for Moving Platforms
Mar 09, 2020
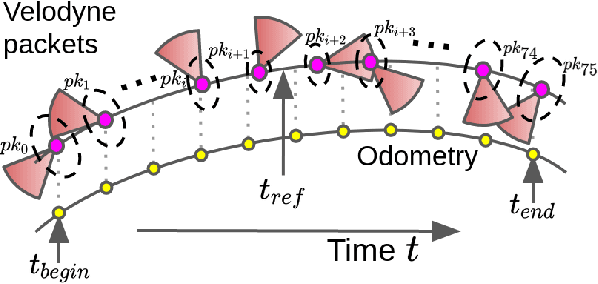

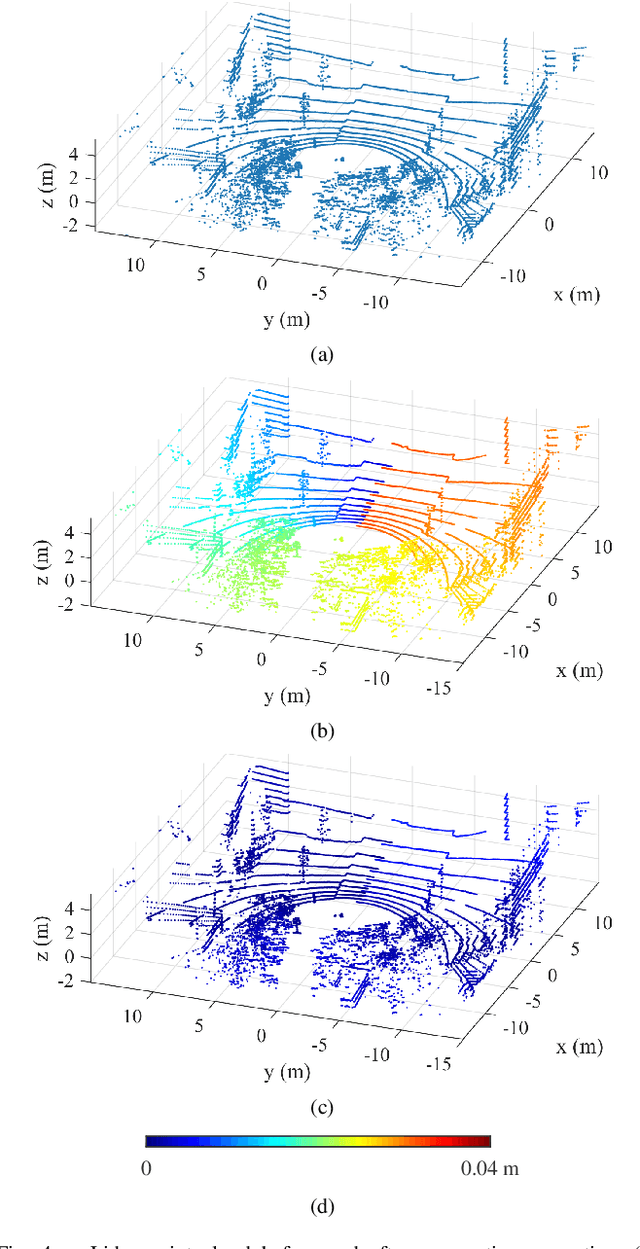
The fusion of sensor data from heterogeneous sensors is crucial for robust perception in various robotics applications that involve moving platforms, for instance, autonomous vehicle navigation. In particular, combining camera and lidar sensors enables the projection of precise range information of the surrounding environment onto visual images. It also makes it possible to label each lidar point with visual segmentation/classification results for 3D mapping, which facilitates a higher level understanding of the scene. The task is however considered non-trivial due to intrinsic and extrinsic sensor calibration, and the distortion of lidar points resulting from the ego-motion of the platform. Despite the existence of many lidar ego-motion correction methods, the errors in the correction process due to uncertainty in ego-motion estimation are not possible to remove completely. It is thus essential to consider the problem a probabilistic process where the ego-motion estimation uncertainty is modelled and considered consistently. The paper investigates the probabilistic lidar ego-motion correction and lidar-to-camera projection, where both the uncertainty in the ego-motion estimation and time jitter in sensory measurements are incorporated. The proposed approach is validated both in simulation and using real-world data collected from an electric vehicle retrofitted with wide-angle cameras and a 16-beam scanning lidar.