 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer
Apr 12, 2021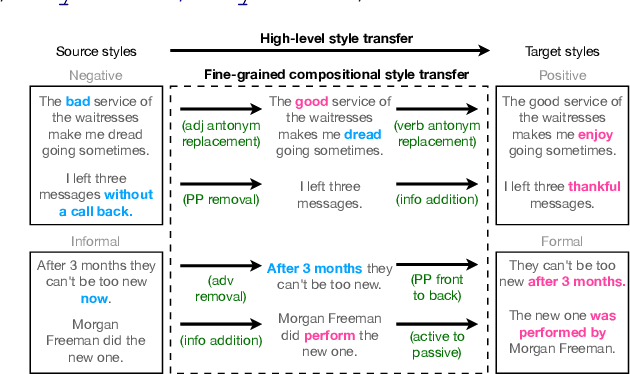
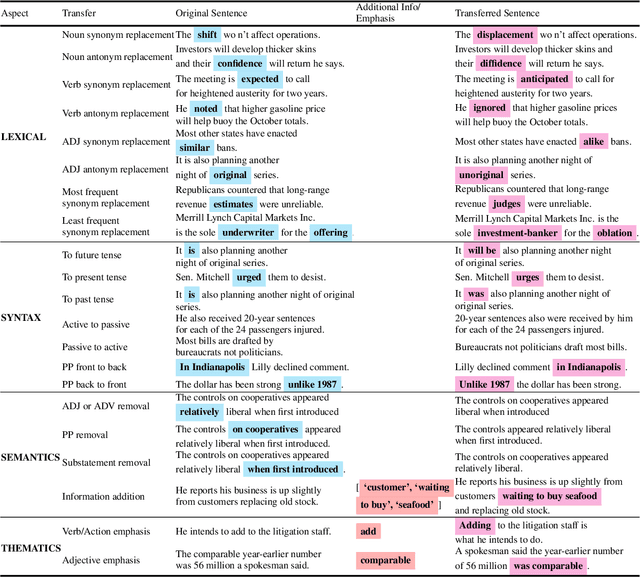
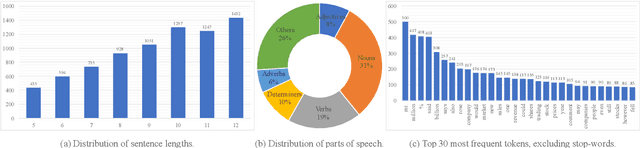
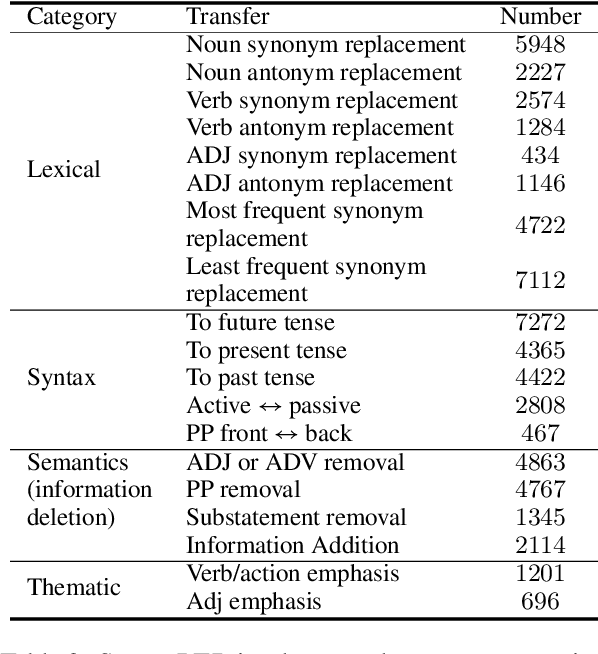
Text style transfer aims to controllably generate text with targeted stylistic changes while maintaining core meaning from the source sentence constant. Many of the existing style transfer benchmarks primarily focus on individual high-level semantic changes (e.g. positive to negative), which enable controllability at a high level but do not offer fine-grained control involving sentence structure, emphasis, and content of the sentence. In this paper, we introduce a large-scale benchmark, StylePTB, with (1) paired sentences undergoing 21 fine-grained stylistic changes spanning atomic lexical, syntactic, semantic, and thematic transfers of text, as well as (2) compositions of multiple transfers which allow modeling of fine-grained stylistic changes as building blocks for more complex, high-level transfers. By benchmarking existing methods on StylePTB, we find that they struggle to model fine-grained changes and have an even more difficult time composing multiple styles. As a result, StylePTB brings novel challenges that we hope will encourage future research in controllable text style transfer, compositional models, and learning disentangled representations. Solving these challenges would present important steps towards controllable text generation.
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021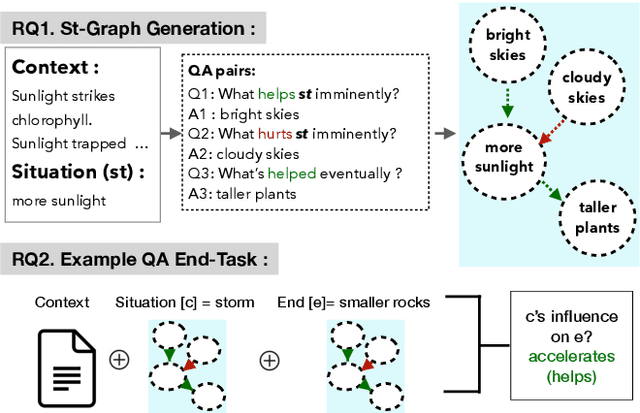
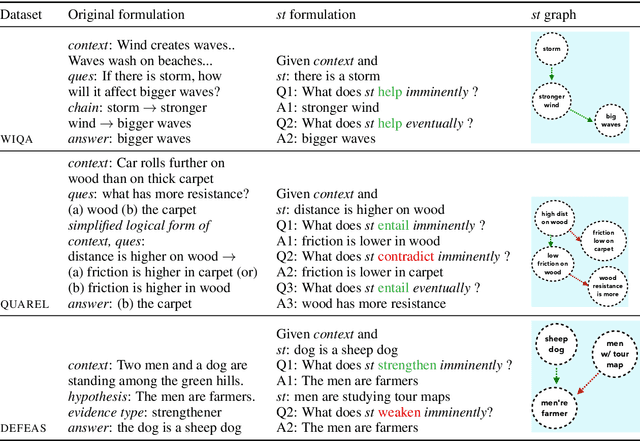
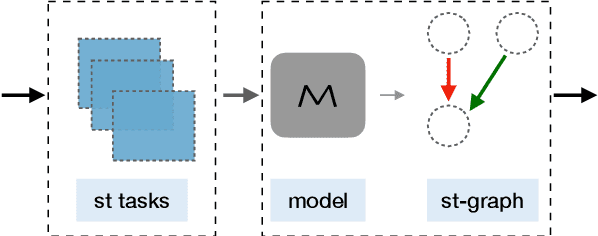
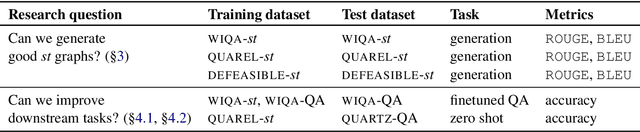
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
SelfExplain: A Self-Explaining Architecture for Neural Text Classifiers
Mar 23, 2021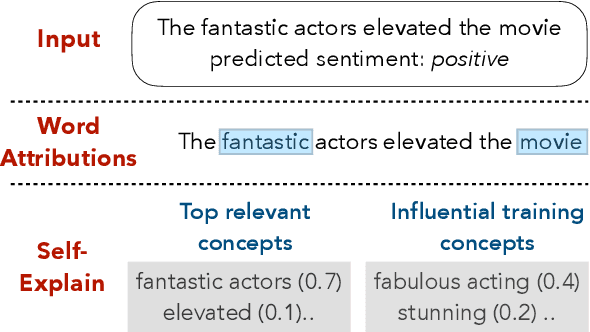
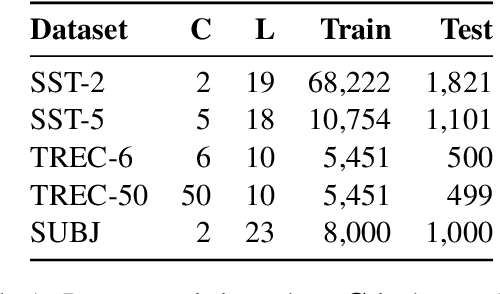
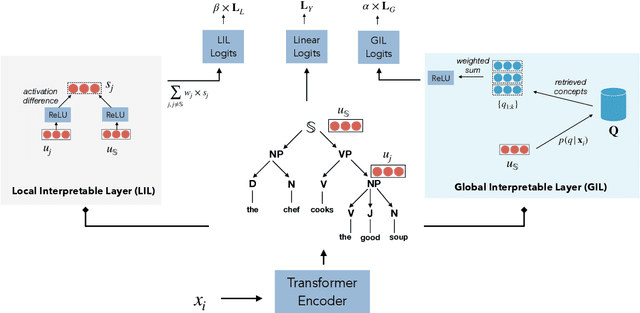
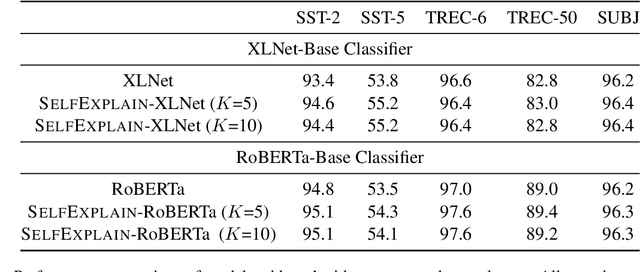
We introduce SelfExplain, a novel self-explaining framework that explains a text classifier's predictions using phrase-based concepts. SelfExplain augments existing neural classifiers by adding (1) a globally interpretable layer that identifies the most influential concepts in the training set for a given sample and (2) a locally interpretable layer that quantifies the contribution of each local input concept by computing a relevance score relative to the predicted label. Experiments across five text-classification datasets show that SelfExplain facilitates interpretability without sacrificing performance. Most importantly, explanations from SelfExplain are perceived as more understandable, adequately justifying and trustworthy by human judges compared to existing widely-used baselines.
NoiseQA: Challenge Set Evaluation for User-Centric Question Answering
Feb 16, 2021
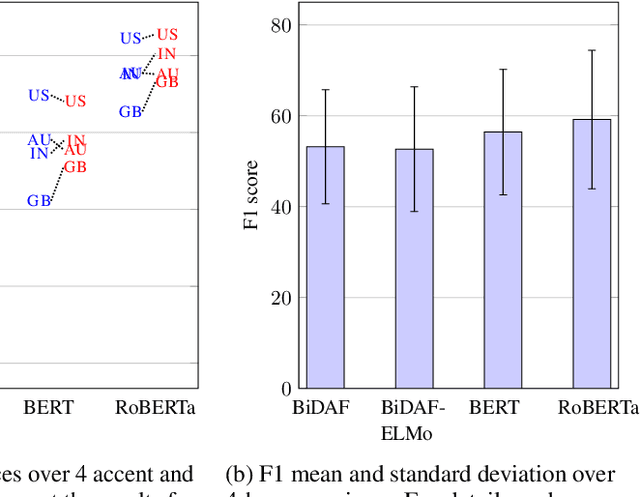

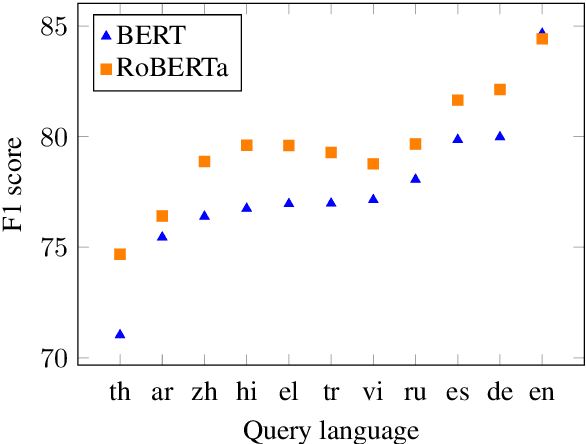
When Question-Answering (QA) systems are deployed in the real world, users query them through a variety of interfaces, such as speaking to voice assistants, typing questions into a search engine, or even translating questions to languages supported by the QA system. While there has been significant community attention devoted to identifying correct answers in passages assuming a perfectly formed question, we show that components in the pipeline that precede an answering engine can introduce varied and considerable sources of error, and performance can degrade substantially based on these upstream noise sources even for powerful pre-trained QA models. We conclude that there is substantial room for progress before QA systems can be effectively deployed, highlight the need for QA evaluation to expand to consider real-world use, and hope that our findings will spur greater community interest in the issues that arise when our systems actually need to be of utility to humans.
Measuring and Improving Consistency in Pretrained Language Models
Feb 01, 2021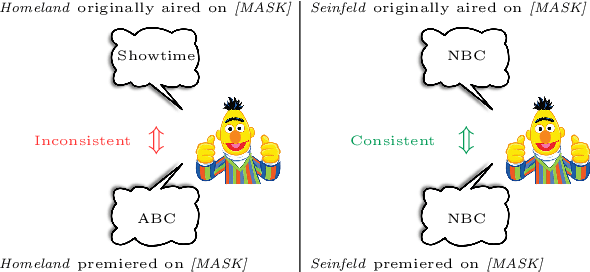
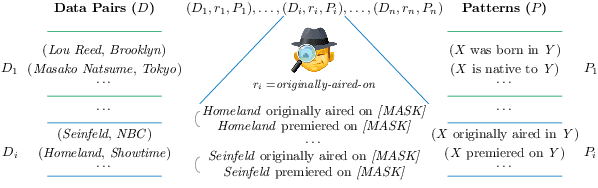
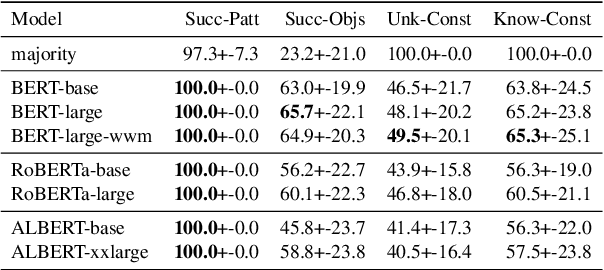
Consistency of a model -- that is, the invariance of its behavior under meaning-preserving alternations in its input -- is a highly desirable property in natural language processing. In this paper we study the question: Are Pretrained Language Models (PLMs) consistent with respect to factual knowledge? To this end, we create ParaRel, a high-quality resource of cloze-style query English paraphrases. It contains a total of 328 paraphrases for thirty-eight relations. Using ParaRel, we show that the consistency of all PLMs we experiment with is poor -- though with high variance between relations. Our analysis of the representational spaces of PLMs suggests that they have a poor structure and are currently not suitable for representing knowledge in a robust way. Finally, we propose a method for improving model consistency and experimentally demonstrate its effectiveness.
Exploring Neural Entity Representations for Semantic Information
Nov 17, 2020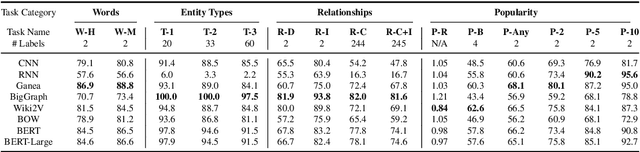
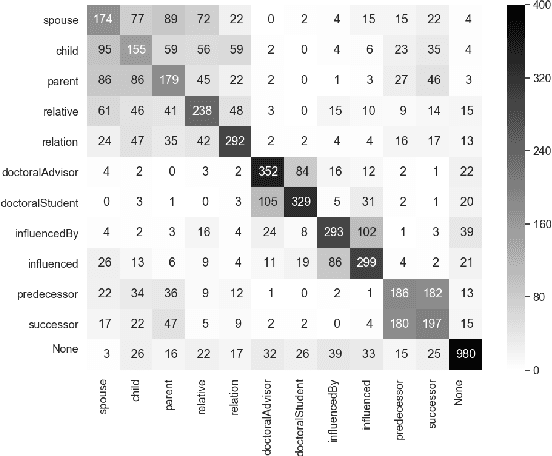
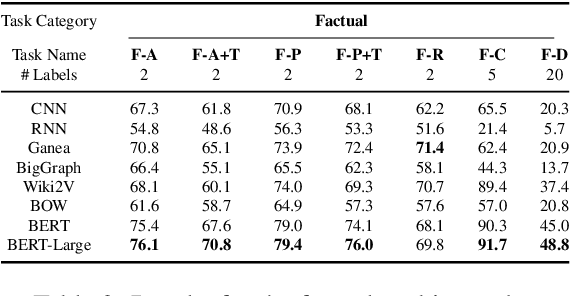
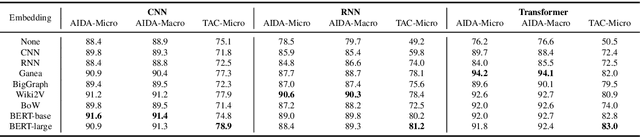
Neural methods for embedding entities are typically extrinsically evaluated on downstream tasks and, more recently, intrinsically using probing tasks. Downstream task-based comparisons are often difficult to interpret due to differences in task structure, while probing task evaluations often look at only a few attributes and models. We address both of these issues by evaluating a diverse set of eight neural entity embedding methods on a set of simple probing tasks, demonstrating which methods are able to remember words used to describe entities, learn type, relationship and factual information, and identify how frequently an entity is mentioned. We also compare these methods in a unified framework on two entity linking tasks and discuss how they generalize to different model architectures and datasets.
* 9 pages, 1 figure
Incorporating a Local Translation Mechanism into Non-autoregressive Translation
Nov 12, 2020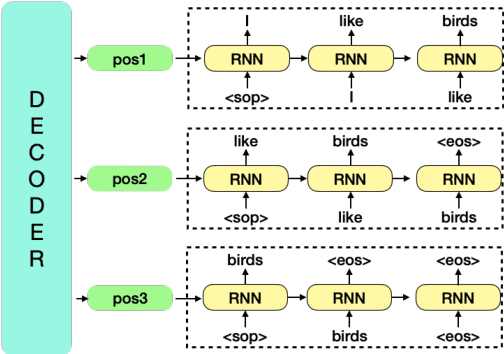
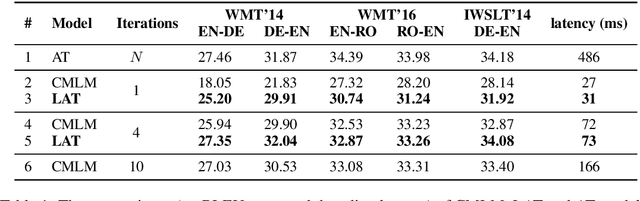
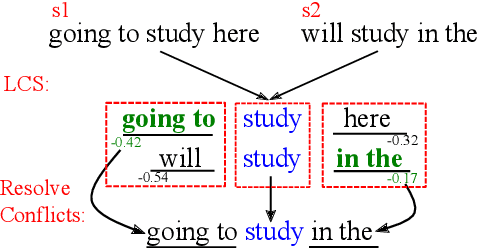
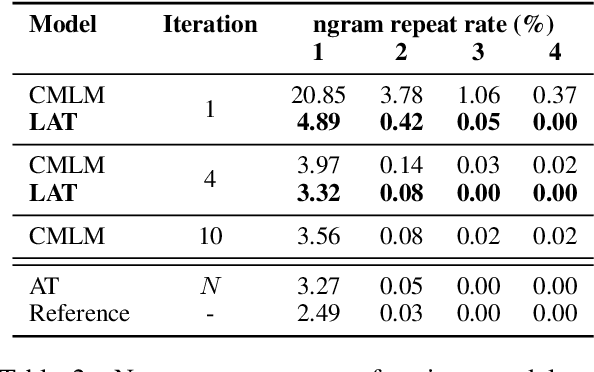
In this work, we introduce a novel local autoregressive translation (LAT) mechanism into non-autoregressive translation (NAT) models so as to capture local dependencies among tar-get outputs. Specifically, for each target decoding position, instead of only one token, we predict a short sequence of tokens in an autoregressive way. We further design an efficient merging algorithm to align and merge the out-put pieces into one final output sequence. We integrate LAT into the conditional masked language model (CMLM; Ghazvininejad et al.,2019) and similarly adopt iterative decoding. Empirical results on five translation tasks show that compared with CMLM, our method achieves comparable or better performance with fewer decoding iterations, bringing a 2.5xspeedup. Further analysis indicates that our method reduces repeated translations and performs better at longer sentences.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020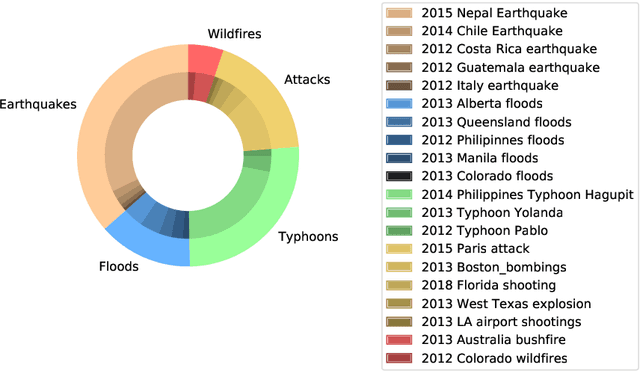

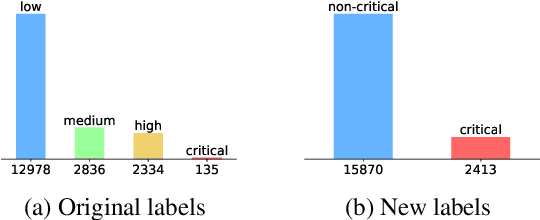
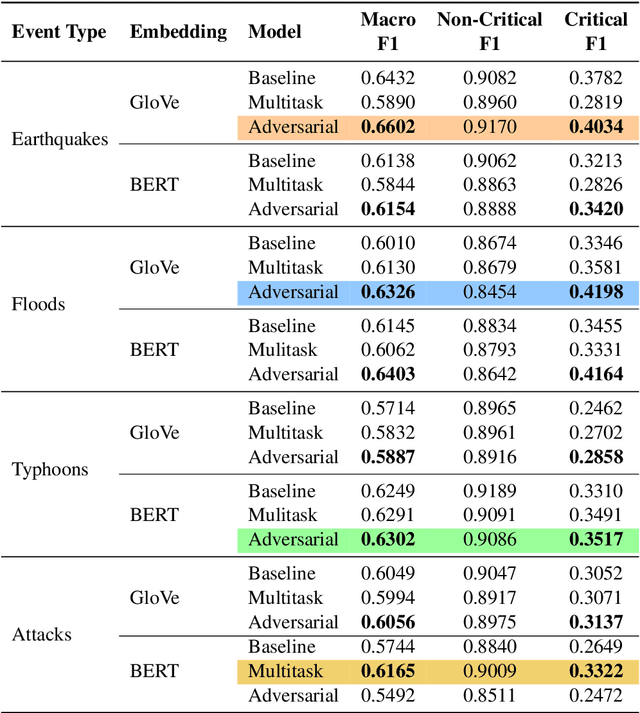
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.
A Dataset for Tracking Entities in Open Domain Procedural Text
Oct 31, 2020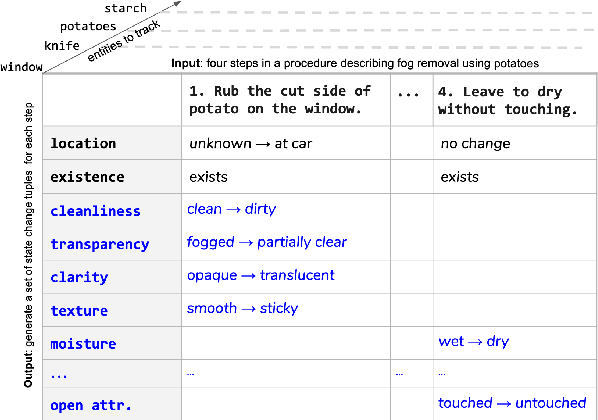
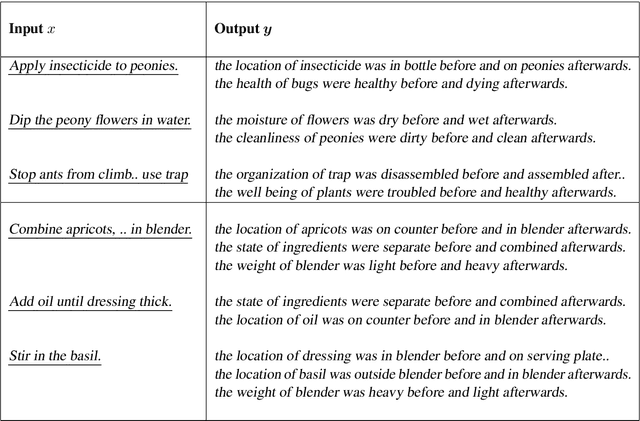
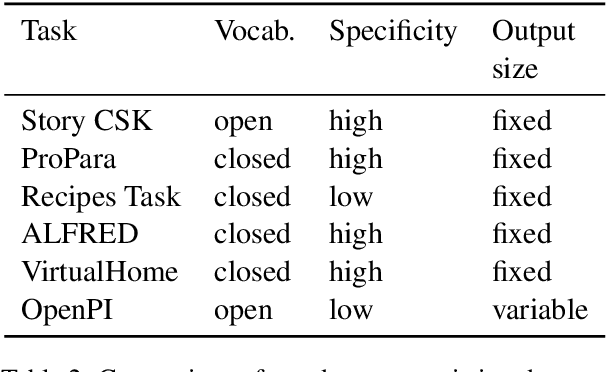

We present the first dataset for tracking state changes in procedural text from arbitrary domains by using an unrestricted (open) vocabulary. For example, in a text describing fog removal using potatoes, a car window may transition between being foggy, sticky,opaque, and clear. Previous formulations of this task provide the text and entities involved,and ask how those entities change for just a small, pre-defined set of attributes (e.g., location), limiting their fidelity. Our solution is a new task formulation where given just a procedural text as input, the task is to generate a set of state change tuples(entity, at-tribute, before-state, after-state)for each step,where the entity, attribute, and state values must be predicted from an open vocabulary. Using crowdsourcing, we create OPENPI1, a high-quality (91.5% coverage as judged by humans and completely vetted), and large-scale dataset comprising 29,928 state changes over 4,050 sentences from 810 procedural real-world paragraphs from WikiHow.com. A current state-of-the-art generation model on this task achieves 16.1% F1 based on BLEU metric, leaving enough room for novel model architectures.
Pair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Oct 31, 2020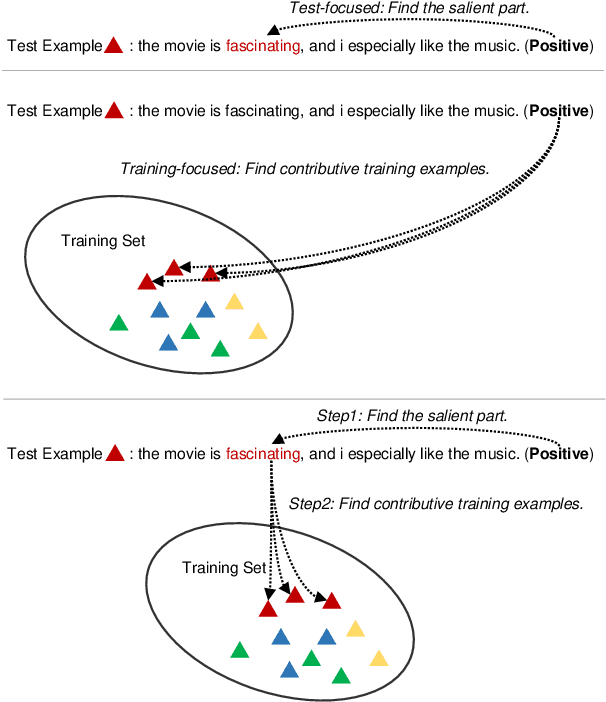
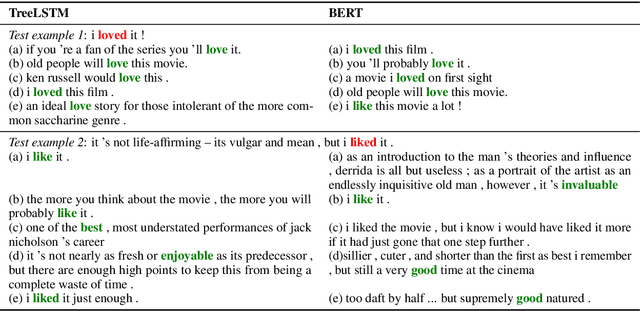

Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.