 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Deploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
Evaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge
Aug 12, 2025



Evaluating personalized recommendations remains a central challenge, especially in long-form audio domains like podcasts, where traditional offline metrics suffer from exposure bias and online methods such as A/B testing are costly and operationally constrained. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) as offline judges to assess the quality of podcast recommendations in a scalable and interpretable manner. Our two-stage profile-aware approach first constructs natural-language user profiles distilled from 90 days of listening history. These profiles summarize both topical interests and behavioral patterns, serving as compact, interpretable representations of user preferences. Rather than prompting the LLM with raw data, we use these profiles to provide high-level, semantically rich context-enabling the LLM to reason more effectively about alignment between a user's interests and recommended episodes. This reduces input complexity and improves interpretability. The LLM is then prompted to deliver fine-grained pointwise and pairwise judgments based on the profile-episode match. In a controlled study with 47 participants, our profile-aware judge matched human judgments with high fidelity and outperformed or matched a variant using raw listening histories. The framework enables efficient, profile-aware evaluation for iterative testing and model selection in recommender systems.
Dataset-Agnostic Recommender Systems
Jan 13, 2025
[This is a position paper and does not contain any empirical or theoretical results] Recommender systems have become a cornerstone of personalized user experiences, yet their development typically involves significant manual intervention, including dataset-specific feature engineering, hyperparameter tuning, and configuration. To this end, we introduce a novel paradigm: Dataset-Agnostic Recommender Systems (DAReS) that aims to enable a single codebase to autonomously adapt to various datasets without the need for fine-tuning, for a given recommender system task. Central to this approach is the Dataset Description Language (DsDL), a structured format that provides metadata about the dataset's features and labels, and allow the system to understand dataset's characteristics, allowing it to autonomously manage processes like feature selection, missing values imputation, noise removal, and hyperparameter optimization. By reducing the need for domain-specific expertise and manual adjustments, DAReS offers a more efficient and scalable solution for building recommender systems across diverse application domains. It addresses critical challenges in the field, such as reusability, reproducibility, and accessibility for non-expert users or entry-level researchers.
Rs4rs: Semantically Find Recent Publications from Top Recommendation System-Related Venues
Sep 11, 2024
Rs4rs is a web application designed to perform semantic search on recent papers from top conferences and journals related to Recommender Systems. Current scholarly search engine tools like Google Scholar, Semantic Scholar, and ResearchGate often yield broad results that fail to target the most relevant high-quality publications. Moreover, manually visiting individual conference and journal websites is a time-consuming process that primarily supports only syntactic searches. Rs4rs addresses these issues by providing a user-friendly platform where researchers can input their topic of interest and receive a list of recent, relevant papers from top Recommender Systems venues. Utilizing semantic search techniques, Rs4rs ensures that the search results are not only precise and relevant but also comprehensive, capturing papers regardless of variations in wording. This tool significantly enhances research efficiency and accuracy, thereby benefitting the research community and public by facilitating access to high-quality, pertinent academic resources in the field of Recommender Systems. Rs4rs is available at https://rs4rs.com.
RBoard: A Unified Platform for Reproducible and Reusable Recommender System Benchmarks
Sep 10, 2024
Recommender systems research lacks standardized benchmarks for reproducibility and algorithm comparisons. We introduce RBoard, a novel framework addressing these challenges by providing a comprehensive platform for benchmarking diverse recommendation tasks, including CTR prediction, Top-N recommendation, and others. RBoard's primary objective is to enable fully reproducible and reusable experiments across these scenarios. The framework evaluates algorithms across multiple datasets within each task, aggregating results for a holistic performance assessment. It implements standardized evaluation protocols, ensuring consistency and comparability. To facilitate reproducibility, all user-provided code can be easily downloaded and executed, allowing researchers to reliably replicate studies and build upon previous work. By offering a unified platform for rigorous, reproducible evaluation across various recommendation scenarios, RBoard aims to accelerate progress in the field and establish a new standard for recommender systems benchmarking in both academia and industry. The platform is available at https://rboard.org and the demo video can be found at https://bit.ly/rboard-demo.
Pure Spectral Graph Embeddings: Reinterpreting Graph Convolution for Top-N Recommendation
May 28, 2023The use of graph convolution in the development of recommender system algorithms has recently achieved state-of-the-art results in the collaborative filtering task (CF). While it has been demonstrated that the graph convolution operation is connected to a filtering operation on the graph spectral domain, the theoretical rationale for why this leads to higher performance on the collaborative filtering problem remains unknown. The presented work makes two contributions. First, we investigate the effect of using graph convolution throughout the user and item representation learning processes, demonstrating how the latent features learned are pushed from the filtering operation into the subspace spanned by the eigenvectors associated with the highest eigenvalues of the normalised adjacency matrix, and how vectors lying on this subspace are the optimal solutions for an objective function related to the sum of the prediction function over the training data. Then, we present an approach that directly leverages the eigenvectors to emulate the solution obtained through graph convolution, eliminating the requirement for a time-consuming gradient descent training procedure while also delivering higher performance on three real-world datasets.
Item Graph Convolution Collaborative Filtering for Inductive Recommendations
Mar 28, 2023Graph Convolutional Networks (GCN) have been recently employed as core component in the construction of recommender system algorithms, interpreting user-item interactions as the edges of a bipartite graph. However, in the absence of side information, the majority of existing models adopt an approach of randomly initialising the user embeddings and optimising them throughout the training process. This strategy makes these algorithms inherently transductive, curtailing their ability to generate predictions for users that were unseen at training time. To address this issue, we propose a convolution-based algorithm, which is inductive from the user perspective, while at the same time, depending only on implicit user-item interaction data. We propose the construction of an item-item graph through a weighted projection of the bipartite interaction network and to employ convolution to inject higher order associations into item embeddings, while constructing user representations as weighted sums of the items with which they have interacted. Despite not training individual embeddings for each user our approach achieves state of-the-art recommendation performance with respect to transductive baselines on four real-world datasets, showing at the same time robust inductive performance.
On the instability of embeddings for recommender systems: the case of Matrix Factorization
Apr 12, 2021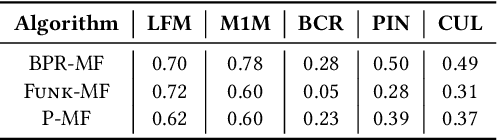
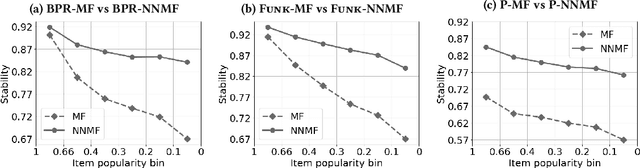
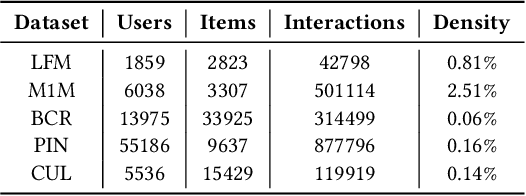
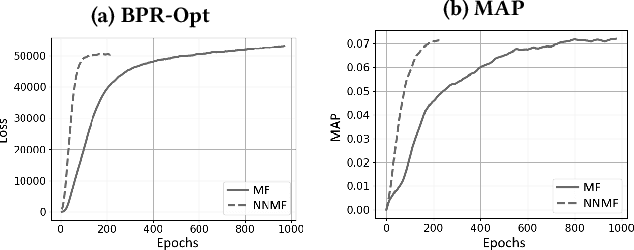
Most state-of-the-art top-N collaborative recommender systems work by learning embeddings to jointly represent users and items. Learned embeddings are considered to be effective to solve a variety of tasks. Among others, providing and explaining recommendations. In this paper we question the reliability of the embeddings learned by Matrix Factorization (MF). We empirically demonstrate that, by simply changing the initial values assigned to the latent factors, the same MF method generates very different embeddings of items and users, and we highlight that this effect is stronger for less popular items. To overcome these drawbacks, we present a generalization of MF, called Nearest Neighbors Matrix Factorization (NNMF). The new method propagates the information about items and users to their neighbors, speeding up the training procedure and extending the amount of information that supports recommendations and representations. We describe the NNMF variants of three common MF approaches, and with extensive experiments on five different datasets we show that they strongly mitigate the instability issues of the original MF versions and they improve the accuracy of recommendations on the long-tail.