 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
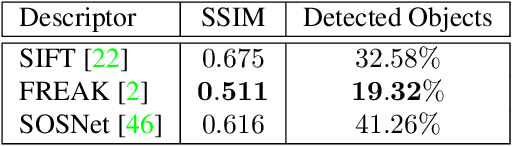
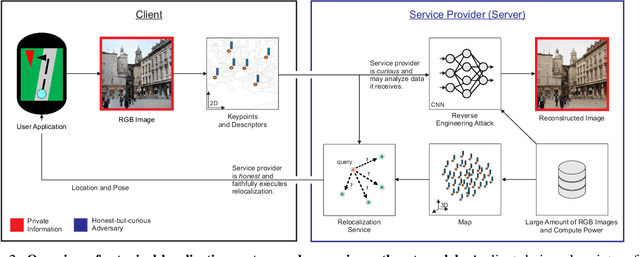
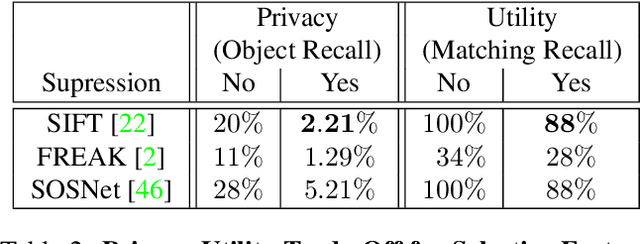
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
Domain Adaptation of Learned Features for Visual Localization
Aug 21, 2020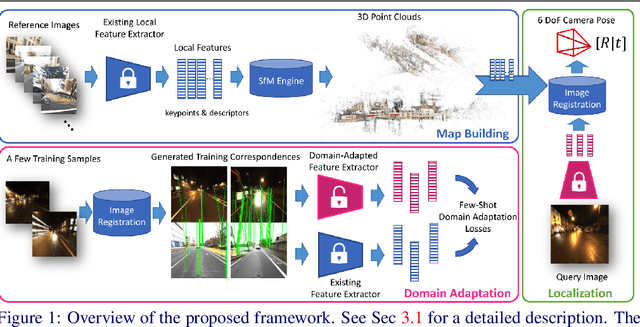

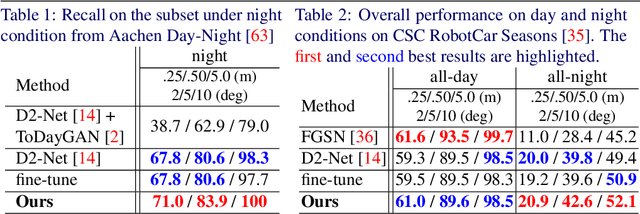
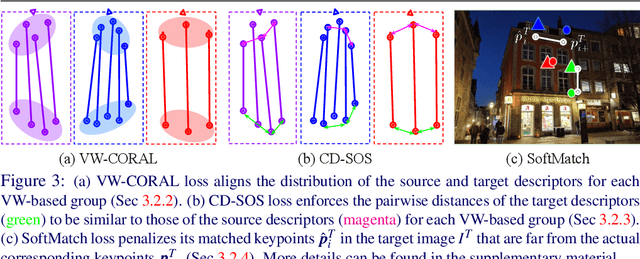
We tackle the problem of visual localization under changing conditions, such as time of day, weather, and seasons. Recent learned local features based on deep neural networks have shown superior performance over classical hand-crafted local features. However, in a real-world scenario, there often exists a large domain gap between training and target images, which can significantly degrade the localization accuracy. While existing methods utilize a large amount of data to tackle the problem, we present a novel and practical approach, where only a few examples are needed to reduce the domain gap. In particular, we propose a few-shot domain adaptation framework for learned local features that deals with varying conditions in visual localization. The experimental results demonstrate the superior performance over baselines, while using a scarce number of training examples from the target domain.
TLIO: Tight Learned Inertial Odometry
Jul 10, 2020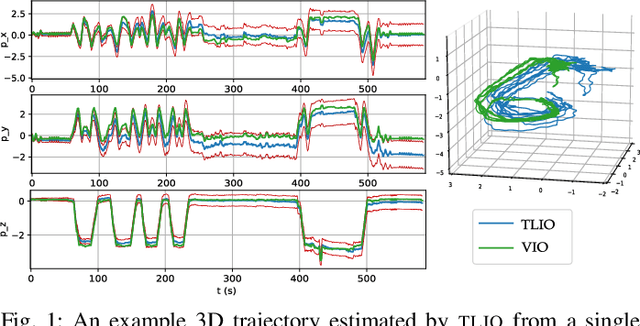
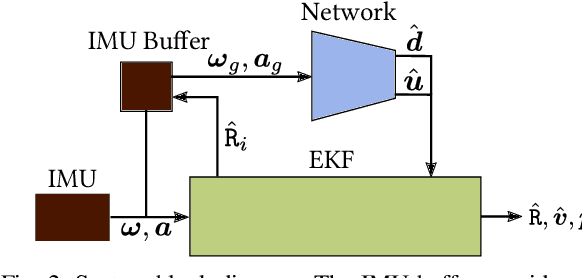
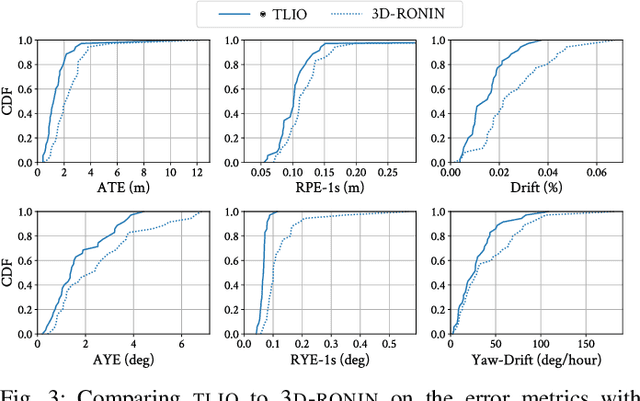
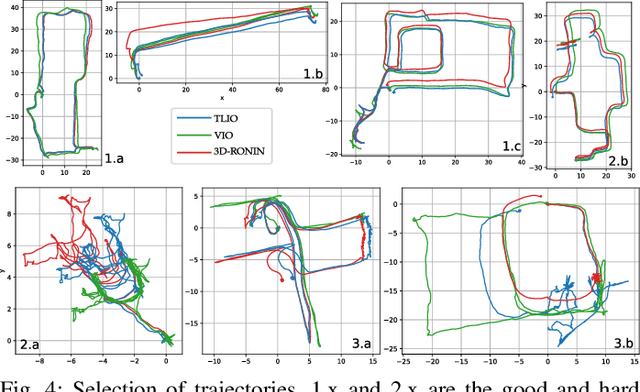
In this work we propose a tightly-coupled Extended Kalman Filter framework for IMU-only state estimation. Strap-down IMU measurements provide relative state estimates based on IMU kinematic motion model. However the integration of measurements is sensitive to sensor bias and noise, causing significant drift within seconds. Recent research by Yan et al. (RoNIN) and Chen et al. (IONet) showed the capability of using trained neural networks to obtain accurate 2D displacement estimates from segments of IMU data and obtained good position estimates from concatenating them. This paper demonstrates a network that regresses 3D displacement estimates and its uncertainty, giving us the ability to tightly fuse the relative state measurement into a stochastic cloning EKF to solve for pose, velocity and sensor biases. We show that our network, trained with pedestrian data from a headset, can produce statistically consistent measurement and uncertainty to be used as the update step in the filter, and the tightly-coupled system outperforms velocity integration approaches in position estimates, and AHRS attitude filter in orientation estimates.
Deep Local Shapes: Learning Local SDF Priors for Detailed 3D Reconstruction
Apr 11, 2020
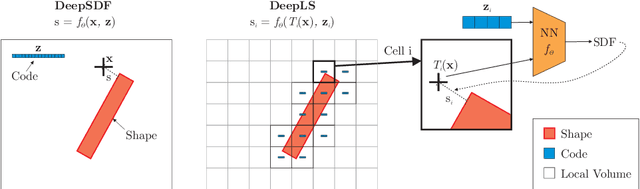

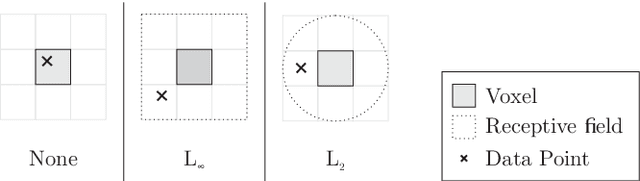
Efficiently reconstructing complex and intricate surfaces at scale is a long-standing goal in machine perception. To address this problem we introduce Deep Local Shapes (DeepLS), a deep shape representation that enables encoding and reconstruction of high-quality 3D shapes without prohibitive memory requirements. DeepLS replaces the dense volumetric signed distance function (SDF) representation used in traditional surface reconstruction systems with a set of locally learned continuous SDFs defined by a neural network, inspired by recent work such as DeepSDF. Unlike DeepSDF, which represents an object-level SDF with a neural network and a single latent code, we store a grid of independent latent codes, each responsible for storing information about surfaces in a small local neighborhood. This decomposition of scenes into local shapes simplifies the prior distribution that the network must learn, and also enables efficient inference. We demonstrate the effectiveness and generalization power of DeepLS by showing object shape encoding and reconstructions of full scenes, where DeepLS delivers high compression, accuracy, and local shape completion.
Overcoming Limitations of Mixture Density Networks: A Sampling and Fitting Framework for Multimodal Future Prediction
Jun 09, 2019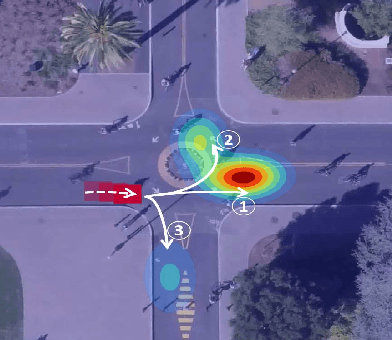
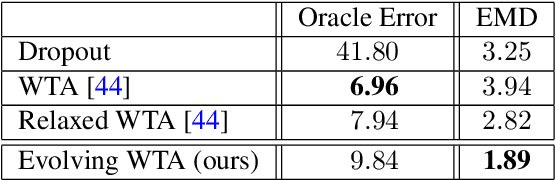
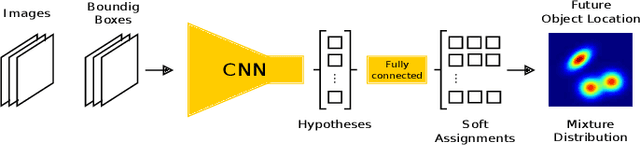
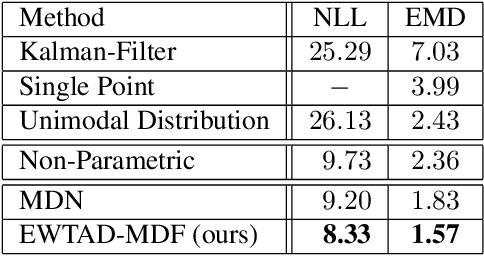
Future prediction is a fundamental principle of intelligence that helps plan actions and avoid possible dangers. As the future is uncertain to a large extent, modeling the uncertainty and multimodality of the future states is of great relevance. Existing approaches are rather limited in this regard and mostly yield a single hypothesis of the future or, at the best, strongly constrained mixture components that suffer from instabilities in training and mode collapse. In this work, we present an approach that involves the prediction of several samples of the future with a winner-takes-all loss and iterative grouping of samples to multiple modes. Moreover, we discuss how to evaluate predicted multimodal distributions, including the common real scenario, where only a single sample from the ground-truth distribution is available for evaluation. We show on synthetic and real data that the proposed approach triggers good estimates of multimodal distributions and avoids mode collapse.
FusionNet and AugmentedFlowNet: Selective Proxy Ground Truth for Training on Unlabeled Images
Aug 20, 2018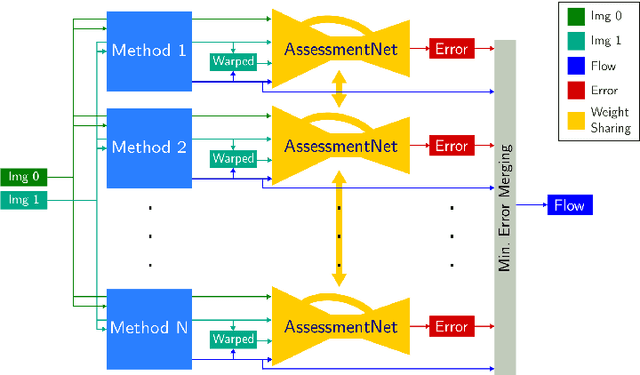
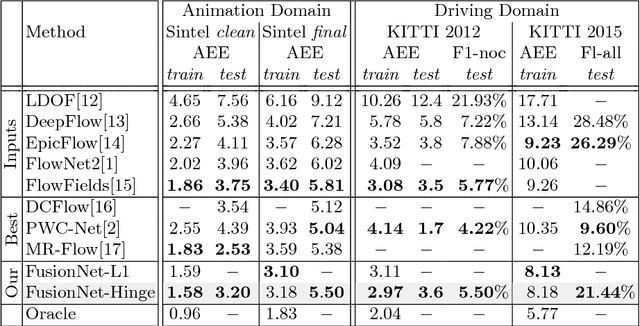
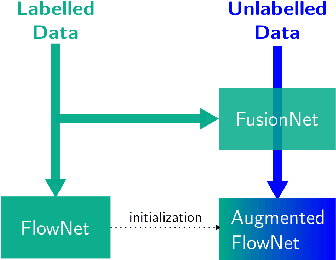
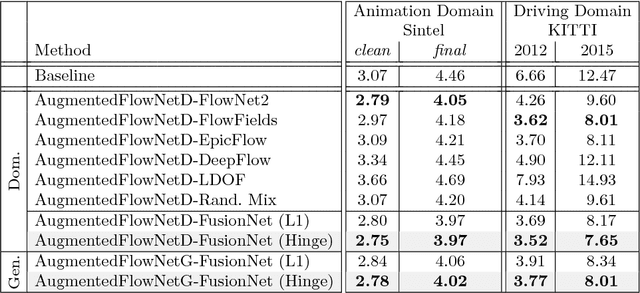
Recent work has shown that convolutional neural networks (CNNs) can be used to estimate optical flow with high quality and fast runtime. This makes them preferable for real-world applications. However, such networks require very large training datasets. Engineering the training data is difficult and/or laborious. This paper shows how to augment a network trained on an existing synthetic dataset with large amounts of additional unlabelled data. In particular, we introduce a selection mechanism to assemble from multiple estimates a joint optical flow field, which outperforms that of all input methods. The latter can be used as proxy-ground-truth to train a network on real-world data and to adapt it to specific domains of interest. Our experimental results show that the performance of networks improves considerably, both, in cross-domain and in domain-specific scenarios. As a consequence, we obtain state-of-the-art results on the KITTI benchmarks.
Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation
Aug 08, 2018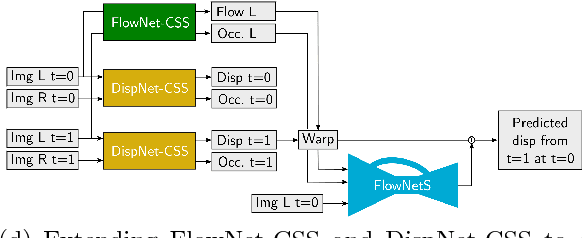


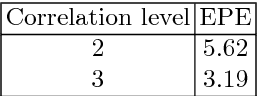
Occlusions play an important role in disparity and optical flow estimation, since matching costs are not available in occluded areas and occlusions indicate depth or motion boundaries. Moreover, occlusions are relevant for motion segmentation and scene flow estimation. In this paper, we present an efficient learning-based approach to estimate occlusion areas jointly with disparities or optical flow. The estimated occlusions and motion boundaries clearly improve over the state-of-the-art. Moreover, we present networks with state-of-the-art performance on the popular KITTI benchmark and good generic performance. Making use of the estimated occlusions, we also show improved results on motion segmentation and scene flow estimation.
Uncertainty Estimates and Multi-Hypotheses Networks for Optical Flow
Aug 06, 2018



Optical flow estimation can be formulated as an end-to-end supervised learning problem, which yields estimates with a superior accuracy-runtime tradeoff compared to alternative methodology. In this paper, we make such networks estimate their local uncertainty about the correctness of their prediction, which is vital information when building decisions on top of the estimations. For the first time we compare several strategies and techniques to estimate uncertainty in a large-scale computer vision task like optical flow estimation. Moreover, we introduce a new network architecture and loss function that enforce complementary hypotheses and provide uncertainty estimates efficiently with a single forward pass and without the need for sampling or ensembles. We demonstrate the quality of the uncertainty estimates, which is clearly above previous confidence measures on optical flow and allows for interactive frame rates.
What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation?
Mar 22, 2018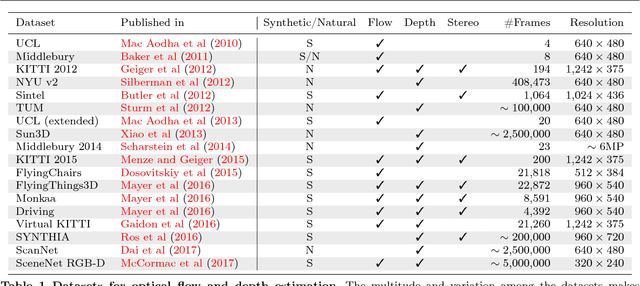

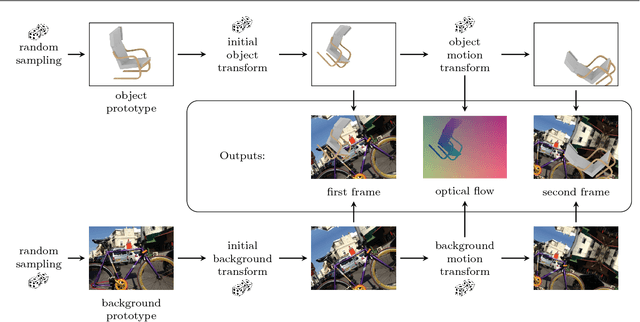
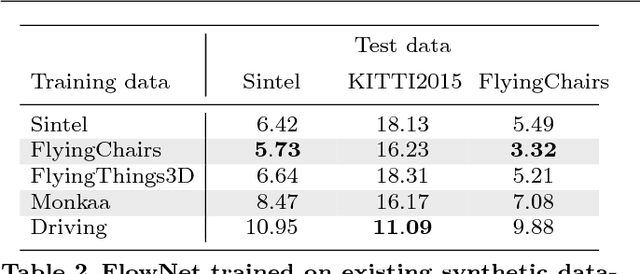
The finding that very large networks can be trained efficiently and reliably has led to a paradigm shift in computer vision from engineered solutions to learning formulations. As a result, the research challenge shifts from devising algorithms to creating suitable and abundant training data for supervised learning. How to efficiently create such training data? The dominant data acquisition method in visual recognition is based on web data and manual annotation. Yet, for many computer vision problems, such as stereo or optical flow estimation, this approach is not feasible because humans cannot manually enter a pixel-accurate flow field. In this paper, we promote the use of synthetically generated data for the purpose of training deep networks on such tasks.We suggest multiple ways to generate such data and evaluate the influence of dataset properties on the performance and generalization properties of the resulting networks. We also demonstrate the benefit of learning schedules that use different types of data at selected stages of the training process.
Lucid Data Dreaming for Multiple Object Tracking
Dec 14, 2017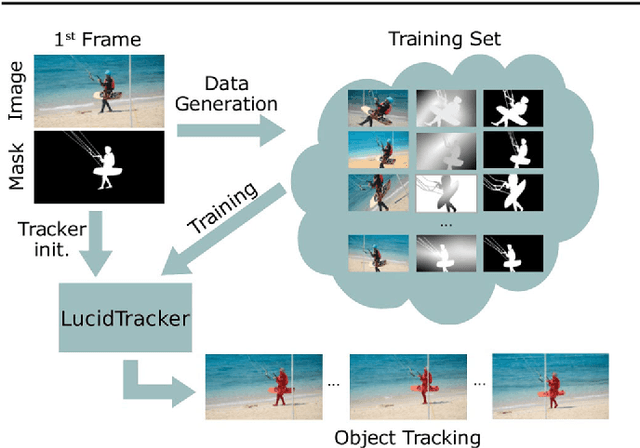
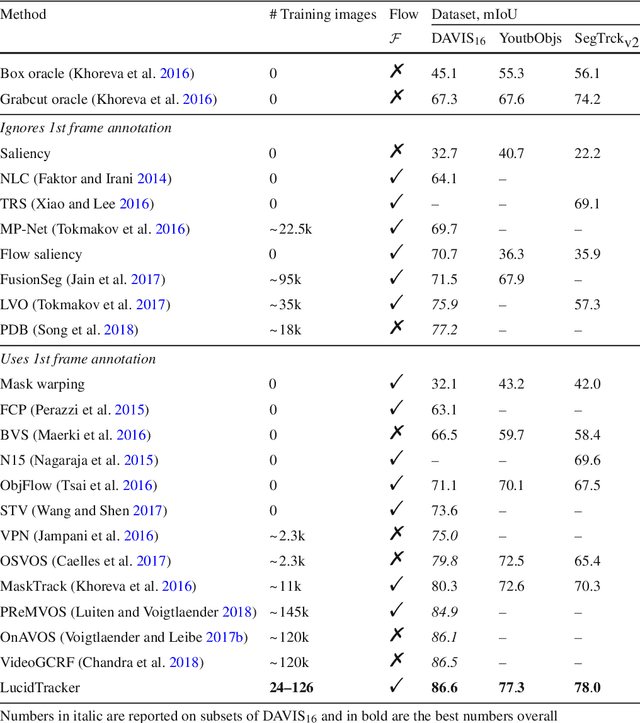

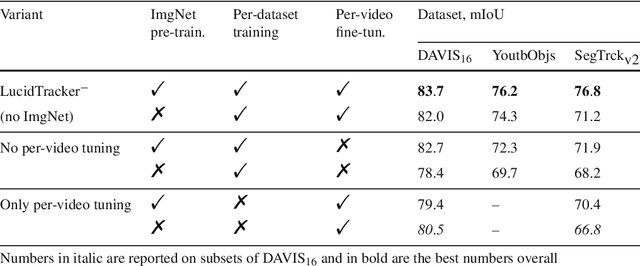
Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k~10k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results across three evaluation datasets while using 20x~100x less annotated data than competing methods. Our approach is suitable for both single and multiple object tracking. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize ("lucid dream") plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the tracking task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general "objectness" knowledge are required for the object tracking task.