 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization in Dependency Parsing
Oct 13, 2021
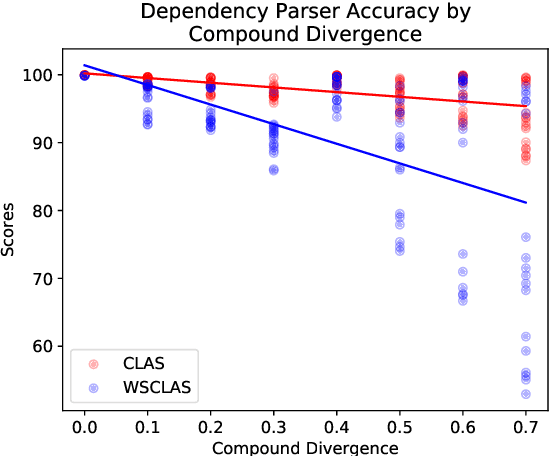
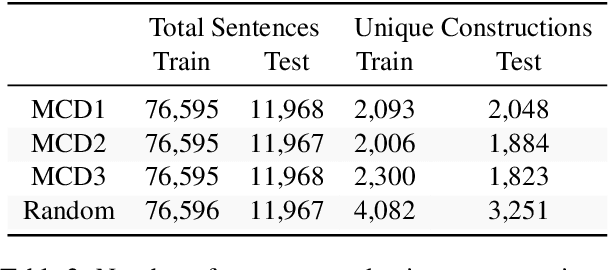
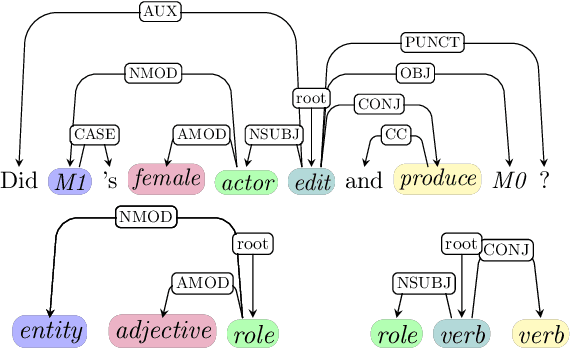
Compositionality, or the ability to combine familiar units like words into novel phrases and sentences, has been the focus of intense interest in artificial intelligence in recent years. To test compositional generalization in semantic parsing, Keysers et al. (2020) introduced Compositional Freebase Queries (CFQ). This dataset maximizes the similarity between the test and train distributions over primitive units, like words, while maximizing the compound divergence: the dissimilarity between test and train distributions over larger structures, like phrases. Dependency parsing, however, lacks a compositional generalization benchmark. In this work, we introduce a gold-standard set of dependency parses for CFQ, and use this to analyze the behavior of a state-of-the art dependency parser (Qi et al., 2020) on the CFQ dataset. We find that increasing compound divergence degrades dependency parsing performance, although not as dramatically as semantic parsing performance. Additionally, we find the performance of the dependency parser does not uniformly degrade relative to compound divergence, and the parser performs differently on different splits with the same compound divergence. We explore a number of hypotheses for what causes the non-uniform degradation in dependency parsing performance, and identify a number of syntactic structures that drive the dependency parser's lower performance on the most challenging splits.
PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models
Sep 10, 2021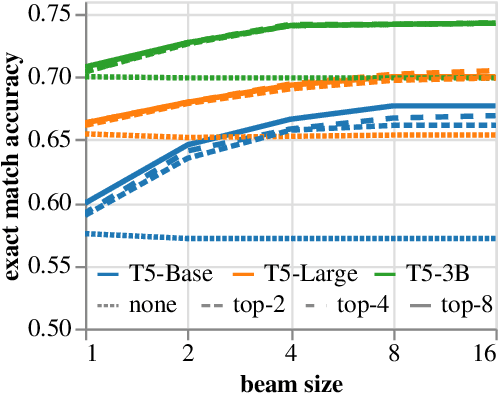
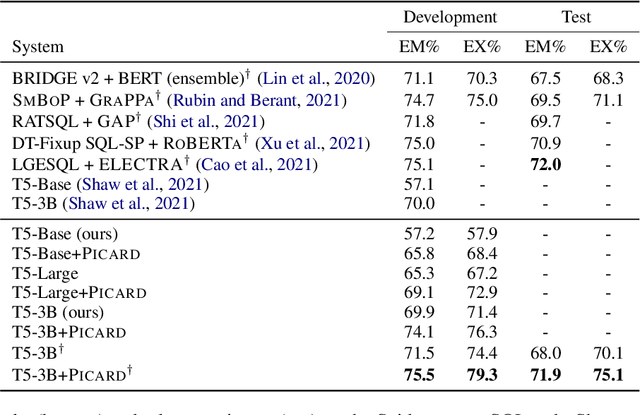
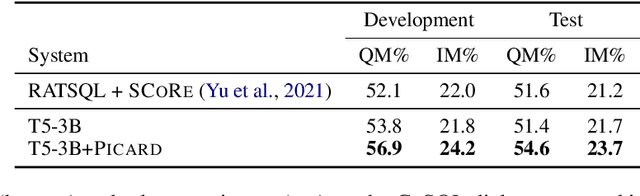
Large pre-trained language models for textual data have an unconstrained output space; at each decoding step, they can produce any of 10,000s of sub-word tokens. When fine-tuned to target constrained formal languages like SQL, these models often generate invalid code, rendering it unusable. We propose PICARD (code and trained models available at https://github.com/ElementAI/picard), a method for constraining auto-regressive decoders of language models through incremental parsing. PICARD helps to find valid output sequences by rejecting inadmissible tokens at each decoding step. On the challenging Spider and CoSQL text-to-SQL translation tasks, we show that PICARD transforms fine-tuned T5 models with passable performance into state-of-the-art solutions.
Understanding by Understanding Not: Modeling Negation in Language Models
May 07, 2021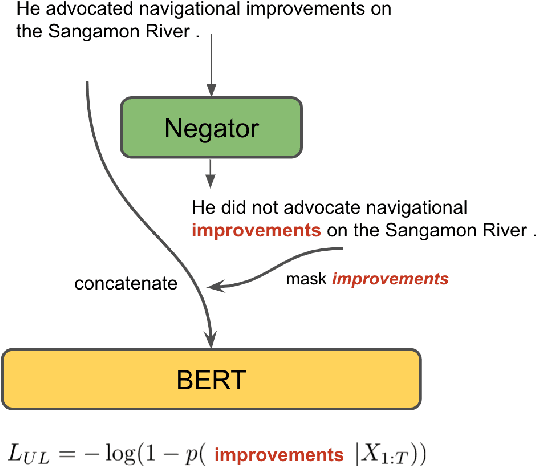



Negation is a core construction in natural language. Despite being very successful on many tasks, state-of-the-art pre-trained language models often handle negation incorrectly. To improve language models in this regard, we propose to augment the language modeling objective with an unlikelihood objective that is based on negated generic sentences from a raw text corpus. By training BERT with the resulting combined objective we reduce the mean top~1 error rate to 4% on the negated LAMA dataset. We also see some improvements on the negated NLI benchmarks.
Jointly Learning Truth-Conditional Denotations and Groundings using Parallel Attention
Apr 14, 2021
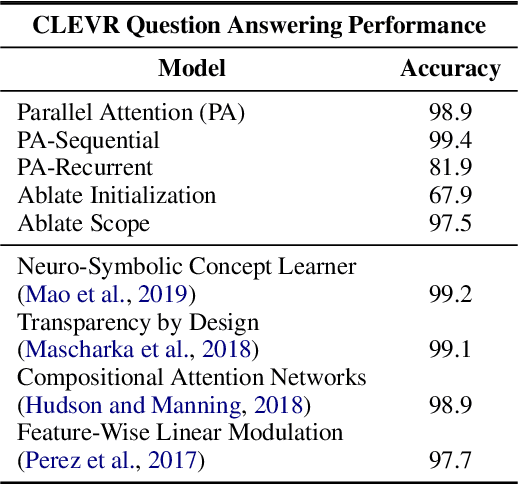
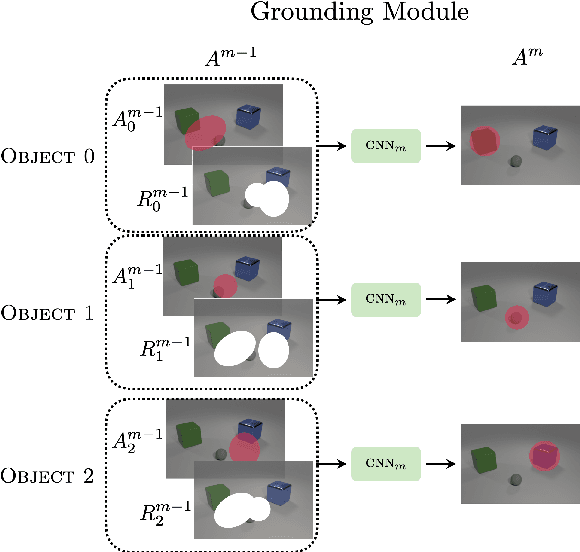
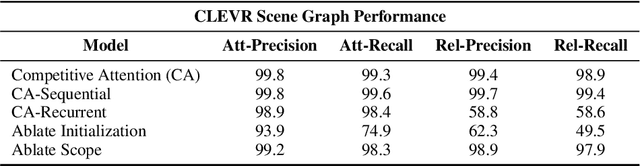
We present a model that jointly learns the denotations of words together with their groundings using a truth-conditional semantics. Our model builds on the neurosymbolic approach of Mao et al. (2019), learning to ground objects in the CLEVR dataset (Johnson et al., 2017) using a novel parallel attention mechanism. The model achieves state of the art performance on visual question answering, learning to detect and ground objects with question performance as the only training signal. We also show that the model is able to learn flexible non-canonical groundings just by adjusting answers to questions in the training set.
DuoRAT: Towards Simpler Text-to-SQL Models
Oct 21, 2020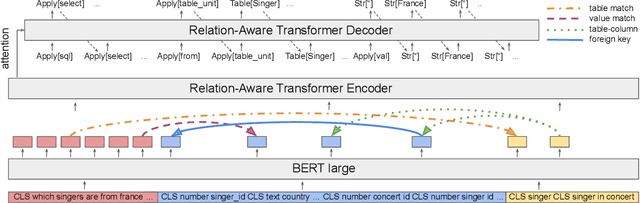
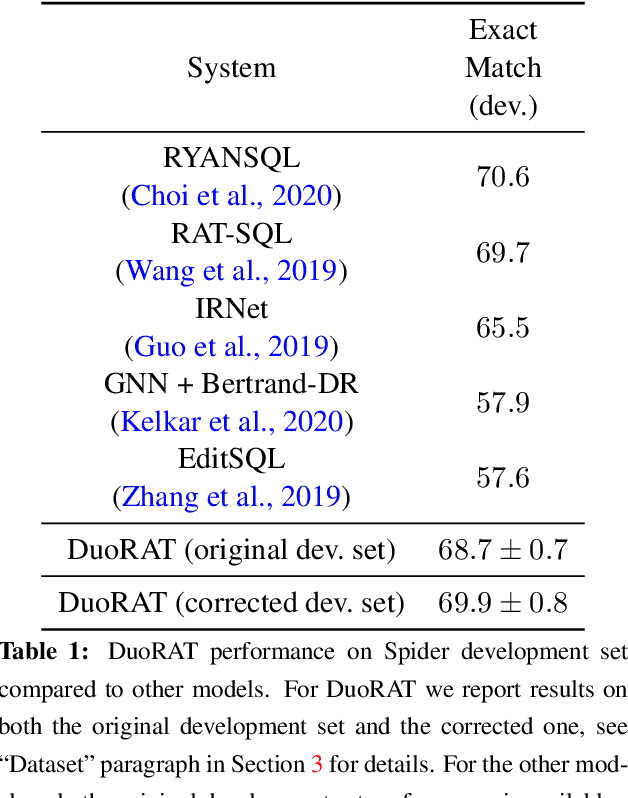
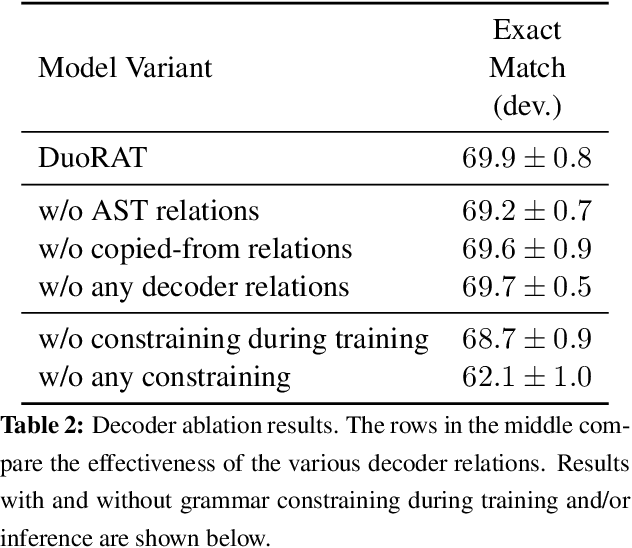
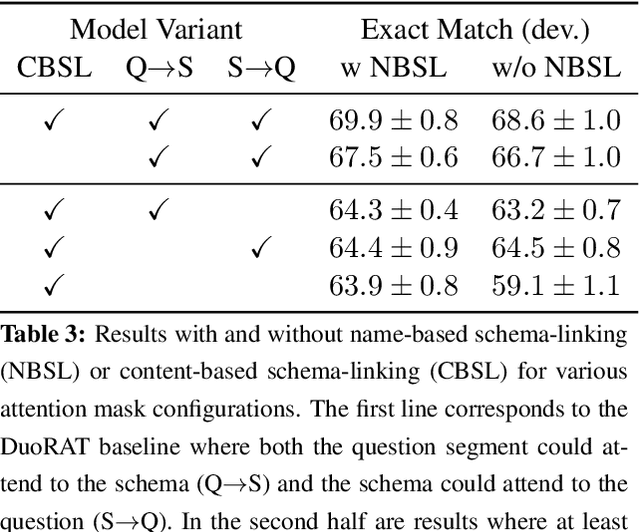
Recent research has shown that neural text-to-SQL models can effectively translate natural language questions into corresponding SQL queries on unseen databases. Working mostly on the Spider dataset, researchers have been proposing increasingly sophisticated modelling approaches to the problem. Contrary to this trend, in this paper we identify the aspects in which text-to-SQL models can be simplified. We begin by building DuoRAT, a re-implementation of the state-of-the-art RAT-SQL model that unlike RAT-SQL is using only relation-aware or vanilla transformers as the building blocks. We perform several ablation experiments using DuoRAT as the baseline model. Our experiments confirm the usefulness of some of the techniques and point out the redundancy of others, including structural SQL features and features that link the question with the schema.
Towards Ecologically Valid Research on Language User Interfaces
Jul 28, 2020



Language User Interfaces (LUIs) could improve human-machine interaction for a wide variety of tasks, such as playing music, getting insights from databases, or instructing domestic robots. In contrast to traditional hand-crafted approaches, recent work attempts to build LUIs in a data-driven way using modern deep learning methods. To satisfy the data needs of such learning algorithms, researchers have constructed benchmarks that emphasize the quantity of collected data at the cost of its naturalness and relevance to real-world LUI use cases. As a consequence, research findings on such benchmarks might not be relevant for developing practical LUIs. The goal of this paper is to bootstrap the discussion around this issue, which we refer to as the benchmarks' low ecological validity. To this end, we describe what we deem an ideal methodology for machine learning research on LUIs and categorize five common ways in which recent benchmarks deviate from it. We give concrete examples of the five kinds of deviations and their consequences. Lastly, we offer a number of recommendations as to how to increase the ecological validity of machine learning research on LUIs.
BabyAI 1.1
Jul 24, 2020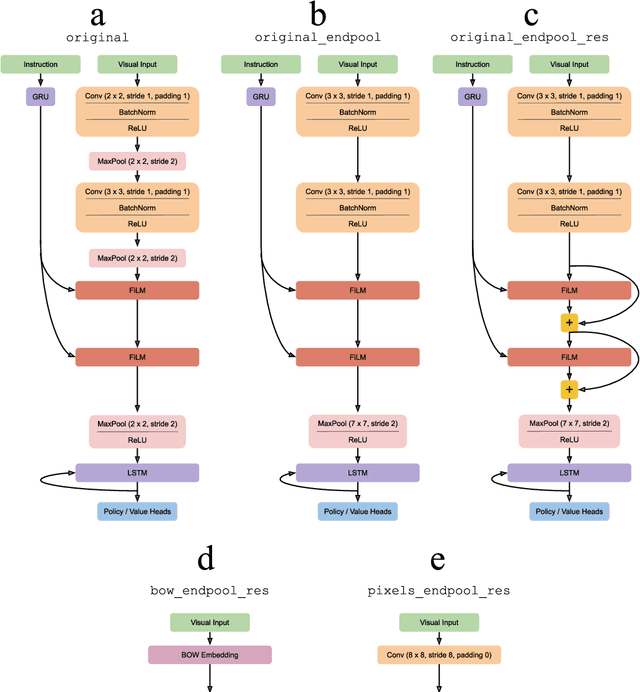
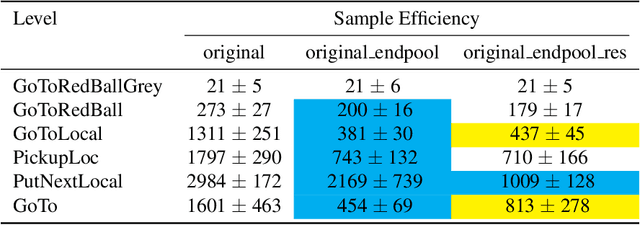

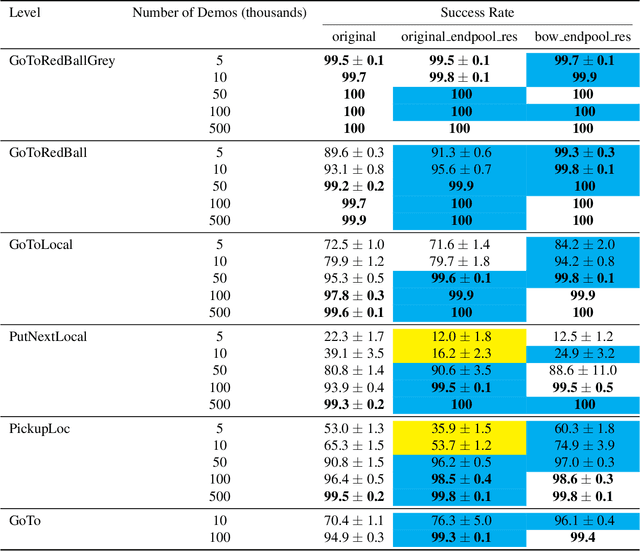
The BabyAI platform is designed to measure the sample efficiency of training an agent to follow grounded-language instructions. BabyAI 1.0 presents baseline results of an agent trained by deep imitation or reinforcement learning. BabyAI 1.1 improves the agent's architecture in three minor ways. This increases reinforcement learning sample efficiency by up to 3 times and improves imitation learning performance on the hardest level from 77 % to 90.4 %. We hope that these improvements increase the computational efficiency of BabyAI experiments and help users design better agents.
Combating False Negatives in Adversarial Imitation Learning
Feb 02, 2020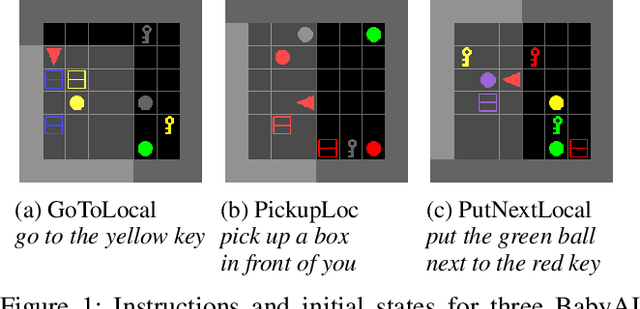

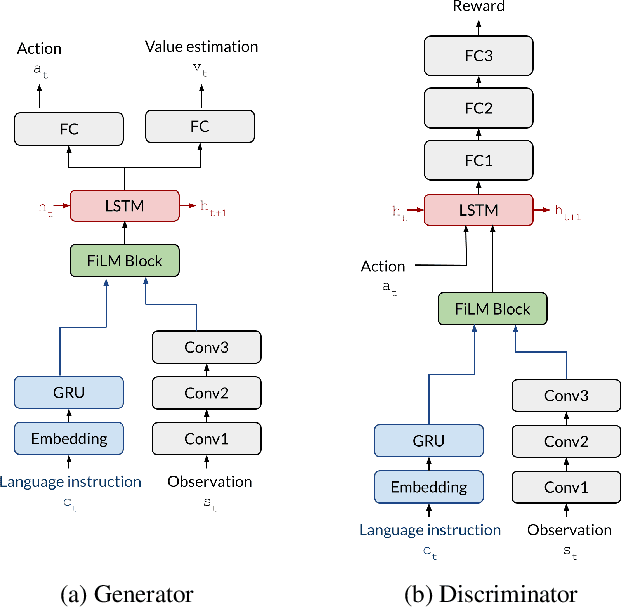
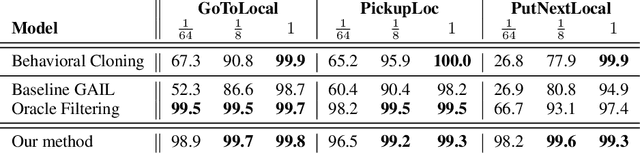
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.
CLOSURE: Assessing Systematic Generalization of CLEVR Models
Dec 12, 2019
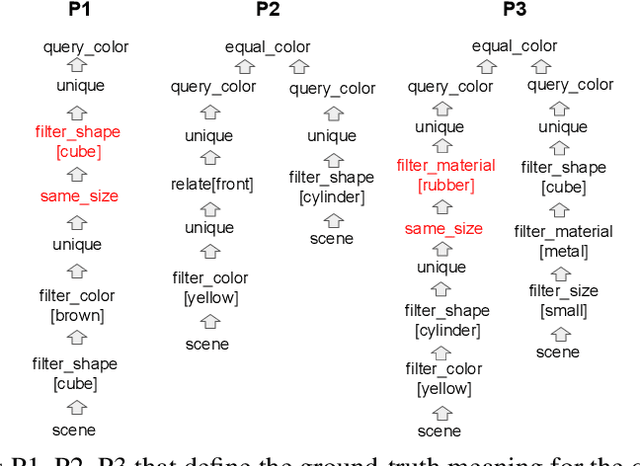
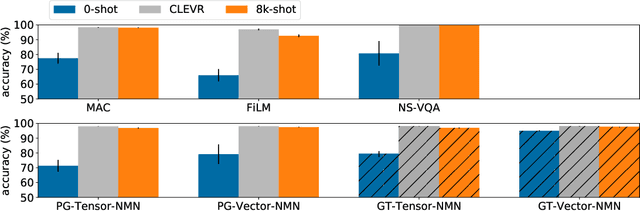
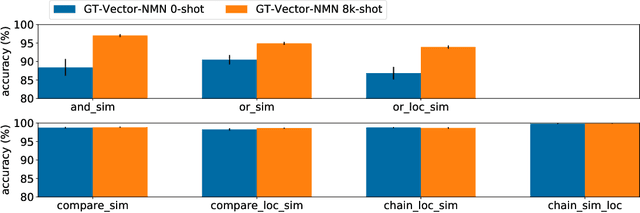
The CLEVR dataset of natural-looking questions about 3D-rendered scenes has recently received much attention from the research community. A number of models have been proposed for this task, many of which achieved very high accuracies of around 97-99%. In this work, we study how systematic the generalization of such models is, that is to which extent they are capable of handling novel combinations of known linguistic constructs. To this end, we test models' understanding of referring expressions based on matching object properties (such as e.g. "the object that is the same size as the red ball") in novel contexts. Our experiments on the thereby constructed CLOSURE benchmark show that state-of-the-art models often do not exhibit systematicity after being trained on CLEVR. Surprisingly, we find that an explicitly compositional Neural Module Network model also generalizes badly on CLOSURE, even when it has access to the ground-truth programs at test time. We improve the NMN's systematic generalization by developing a novel Vector-NMN module architecture with vector-valued inputs and outputs. Lastly, we investigate the extent to which few-shot transfer learning can help models that are pretrained on CLEVR to adapt to CLOSURE. Our few-shot learning experiments contrast the adaptation behavior of the models with intermediate discrete programs with that of the end-to-end continuous models.
Automated curriculum generation for Policy Gradients from Demonstrations
Dec 01, 2019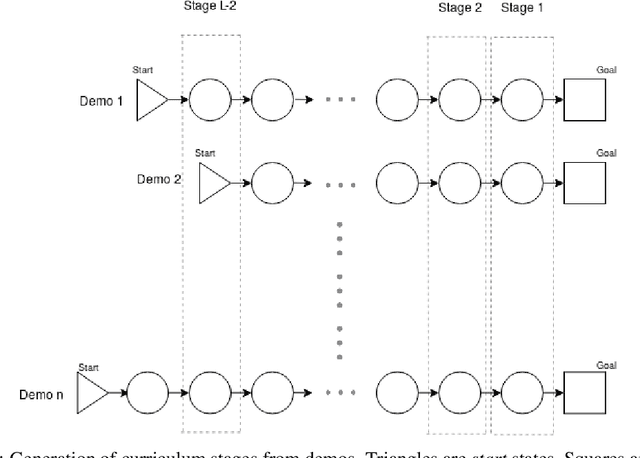

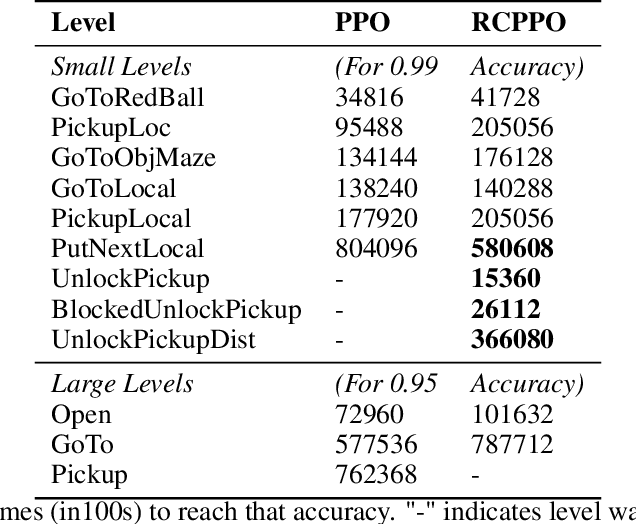
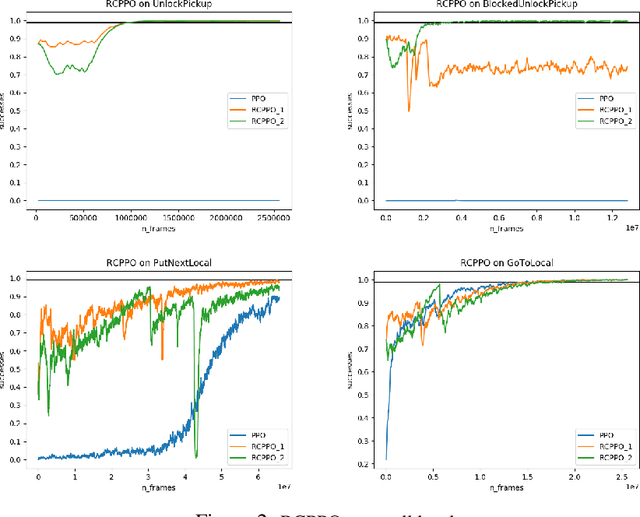
In this paper, we present a technique that improves the process of training an agent (using RL) for instruction following. We develop a training curriculum that uses a nominal number of expert demonstrations and trains the agent in a manner that draws parallels from one of the ways in which humans learn to perform complex tasks, i.e by starting from the goal and working backwards. We test our method on the BabyAI platform and show an improvement in sample efficiency for some of its tasks compared to a PPO (proximal policy optimization) baseline.