 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024


External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
Distributional Preference Learning: Understanding and Accounting for Hidden Context in RLHF
Dec 13, 2023In practice, preference learning from human feedback depends on incomplete data with hidden context. Hidden context refers to data that affects the feedback received, but which is not represented in the data used to train a preference model. This captures common issues of data collection, such as having human annotators with varied preferences, cognitive processes that result in seemingly irrational behavior, and combining data labeled according to different criteria. We prove that standard applications of preference learning, including reinforcement learning from human feedback (RLHF), implicitly aggregate over hidden contexts according to a well-known voting rule called Borda count. We show this can produce counter-intuitive results that are very different from other methods which implicitly aggregate via expected utility. Furthermore, our analysis formalizes the way that preference learning from users with diverse values tacitly implements a social choice function. A key implication of this result is that annotators have an incentive to misreport their preferences in order to influence the learned model, leading to vulnerabilities in the deployment of RLHF. As a step towards mitigating these problems, we introduce a class of methods called distributional preference learning (DPL). DPL methods estimate a distribution of possible score values for each alternative in order to better account for hidden context. Experimental results indicate that applying DPL to RLHF for LLM chatbots identifies hidden context in the data and significantly reduces subsequent jailbreak vulnerability. Our code and data are available at https://github.com/cassidylaidlaw/hidden-context
Cognitive Dissonance: Why Do Language Model Outputs Disagree with Internal Representations of Truthfulness?
Nov 27, 2023Neural language models (LMs) can be used to evaluate the truth of factual statements in two ways: they can be either queried for statement probabilities, or probed for internal representations of truthfulness. Past work has found that these two procedures sometimes disagree, and that probes tend to be more accurate than LM outputs. This has led some researchers to conclude that LMs "lie" or otherwise encode non-cooperative communicative intents. Is this an accurate description of today's LMs, or can query-probe disagreement arise in other ways? We identify three different classes of disagreement, which we term confabulation, deception, and heterogeneity. In many cases, the superiority of probes is simply attributable to better calibration on uncertain answers rather than a greater fraction of correct, high-confidence answers. In some cases, queries and probes perform better on different subsets of inputs, and accuracy can further be improved by ensembling the two. Code is available at github.com/lingo-mit/lm-truthfulness.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023



Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Measuring the Success of Diffusion Models at Imitating Human Artists
Jul 08, 2023



Modern diffusion models have set the state-of-the-art in AI image generation. Their success is due, in part, to training on Internet-scale data which often includes copyrighted work. This prompts questions about the extent to which these models learn from, imitate, or copy the work of human artists. This work suggests that tying copyright liability to the capabilities of the model may be useful given the evolving ecosystem of generative models. Specifically, much of the legal analysis of copyright and generative systems focuses on the use of protected data for training. As a result, the connections between data, training, and the system are often obscured. In our approach, we consider simple image classification techniques to measure a model's ability to imitate specific artists. Specifically, we use Contrastive Language-Image Pretrained (CLIP) encoders to classify images in a zero-shot fashion. Our process first prompts a model to imitate a specific artist. Then, we test whether CLIP can be used to reclassify the artist (or the artist's work) from the imitation. If these tests match the imitation back to the original artist, this suggests the model can imitate that artist's expression. Our approach is simple and quantitative. Furthermore, it uses standard techniques and does not require additional training. We demonstrate our approach with an audit of Stable Diffusion's capacity to imitate 70 professional digital artists with copyrighted work online. When Stable Diffusion is prompted to imitate an artist from this set, we find that the artist can be identified from the imitation with an average accuracy of 81.0%. Finally, we also show that a sample of the artist's work can be matched to these imitation images with a high degree of statistical reliability. Overall, these results suggest that Stable Diffusion is broadly successful at imitating individual human artists.
Explore, Establish, Exploit: Red Teaming Language Models from Scratch
Jun 21, 2023



Deploying Large language models (LLMs) can pose hazards from harmful outputs such as toxic or dishonest speech. Prior work has introduced tools that elicit harmful outputs in order to identify and mitigate these risks. While this is a valuable step toward securing language models, these approaches typically rely on a pre-existing classifier for undesired outputs. This limits their application to situations where the type of harmful behavior is known with precision beforehand. However, this skips a central challenge of red teaming: developing a contextual understanding of the behaviors that a model can exhibit. Furthermore, when such a classifier already exists, red teaming has limited marginal value because the classifier could simply be used to filter training data or model outputs. In this work, we consider red teaming under the assumption that the adversary is working from a high-level, abstract specification of undesired behavior. The red team is expected to refine/extend this specification and identify methods to elicit this behavior from the model. Our red teaming framework consists of three steps: 1) Exploring the model's behavior in the desired context; 2) Establishing a measurement of undesired behavior (e.g., a classifier trained to reflect human evaluations); and 3) Exploiting the model's flaws using this measure and an established red teaming methodology. We apply this approach to red team GPT-2 and GPT-3 models to systematically discover classes of prompts that elicit toxic and dishonest statements. In doing so, we also construct and release the CommonClaim dataset of 20,000 statements that have been labeled by human subjects as common-knowledge-true, common-knowledge-false, or neither. Code is available at https://github.com/thestephencasper/explore_establish_exploit_llms. CommonClaim is available at https://github.com/Algorithmic-Alignment-Lab/CommonClaim.
Recommending to Strategic Users
Feb 13, 2023



Recommendation systems are pervasive in the digital economy. An important assumption in many deployed systems is that user consumption reflects user preferences in a static sense: users consume the content they like with no other considerations in mind. However, as we document in a large-scale online survey, users do choose content strategically to influence the types of content they get recommended in the future. We model this user behavior as a two-stage noisy signalling game between the recommendation system and users: the recommendation system initially commits to a recommendation policy, presents content to the users during a cold start phase which the users choose to strategically consume in order to affect the types of content they will be recommended in a recommendation phase. We show that in equilibrium, users engage in behaviors that accentuate their differences to users of different preference profiles. In addition, (statistical) minorities out of fear of losing their minority content exposition may not consume content that is liked by mainstream users. We next propose three interventions that may improve recommendation quality (both on average and for minorities) when taking into account strategic consumption: (1) Adopting a recommendation system policy that uses preferences from a prior, (2) Communicating to users that universally liked ("mainstream") content will not be used as basis of recommendation, and (3) Serving content that is personalized-enough yet expected to be liked in the beginning. Finally, we describe a methodology to inform applied theory modeling with survey results.
Benchmarking Interpretability Tools for Deep Neural Networks
Feb 08, 2023Interpreting deep neural networks is the topic of much current research in AI. However, few interpretability techniques have shown to be competitive tools in practical applications. Inspired by how benchmarks tend to guide progress in AI, we make three contributions. First, we propose trojan rediscovery as a benchmarking task to evaluate how useful interpretability tools are for generating engineering-relevant insights. Second, we design two such approaches for benchmarking: one for feature attribution methods and one for feature synthesis methods. Third, we apply our benchmarks to evaluate 16 feature attribution/saliency methods and 9 feature synthesis methods. This approach finds large differences in the capabilities of these existing tools and shows significant room for improvement. Finally, we propose several directions for future work. Resources are available at https://github.com/thestephencasper/benchmarking_interpretability
Diagnostics for Deep Neural Networks with Automated Copy/Paste Attacks
Nov 22, 2022



Deep neural networks (DNNs) are powerful, but they can make mistakes that pose significant risks. A model performing well on a test set does not imply safety in deployment, so it is important to have additional tools to understand its flaws. Adversarial examples can help reveal weaknesses, but they are often difficult for a human to interpret or draw generalizable, actionable conclusions from. Some previous works have addressed this by studying human-interpretable attacks. We build on these with three contributions. First, we introduce a method termed Search for Natural Adversarial Features Using Embeddings (SNAFUE) which offers a fully-automated method for finding "copy/paste" attacks in which one natural image can be pasted into another in order to induce an unrelated misclassification. Second, we use this to red team an ImageNet classifier and identify hundreds of easily-describable sets of vulnerabilities. Third, we compare this approach with other interpretability tools by attempting to rediscover trojans. Our results suggest that SNAFUE can be useful for interpreting DNNs and generating adversarial data for them. Code is available at https://github.com/thestephencasper/snafue
White-Box Adversarial Policies in Deep Reinforcement Learning
Sep 05, 2022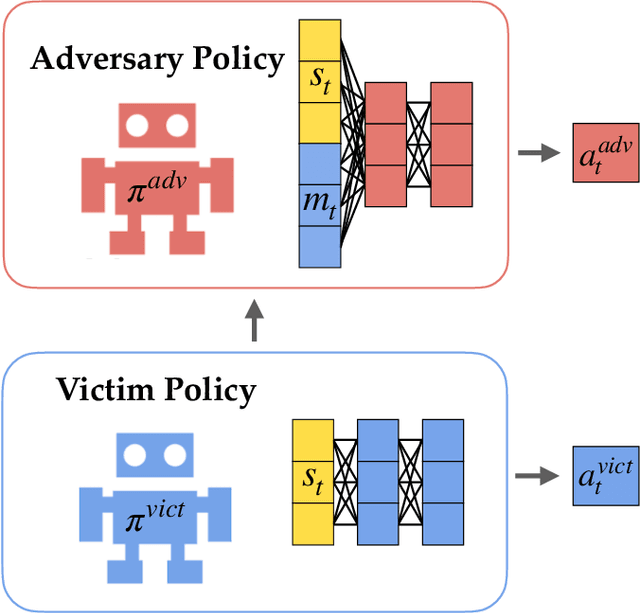
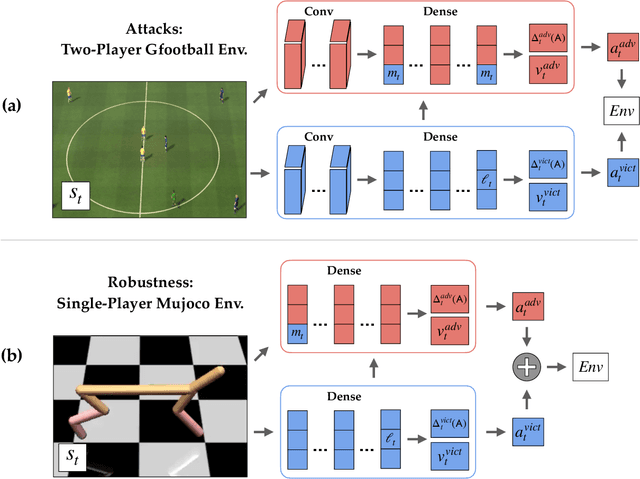
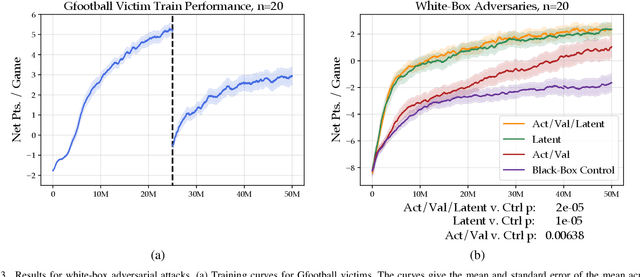
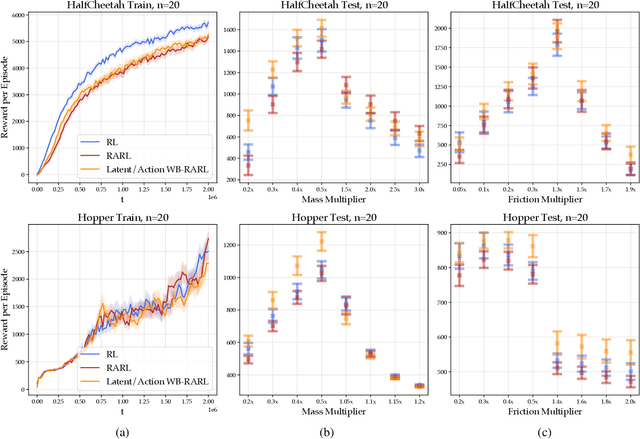
Adversarial examples against AI systems pose both risks via malicious attacks and opportunities for improving robustness via adversarial training. In multiagent settings, adversarial policies can be developed by training an adversarial agent to minimize a victim agent's rewards. Prior work has studied black-box attacks where the adversary only sees the state observations and effectively treats the victim as any other part of the environment. In this work, we experiment with white-box adversarial policies to study whether an agent's internal state can offer useful information for other agents. We make three contributions. First, we introduce white-box adversarial policies in which an attacker can observe a victim's internal state at each timestep. Second, we demonstrate that white-box access to a victim makes for better attacks in two-agent environments, resulting in both faster initial learning and higher asymptotic performance against the victim. Third, we show that training against white-box adversarial policies can be used to make learners in single-agent environments more robust to domain shifts.