 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Search Engine for Discovery of Scientific Challenges and Directions
Sep 10, 2021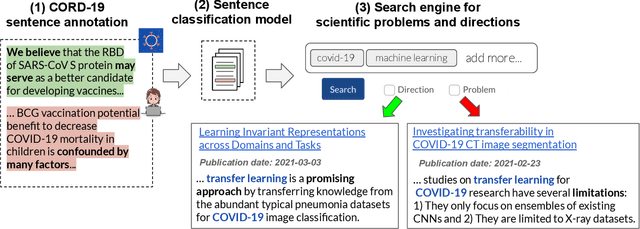


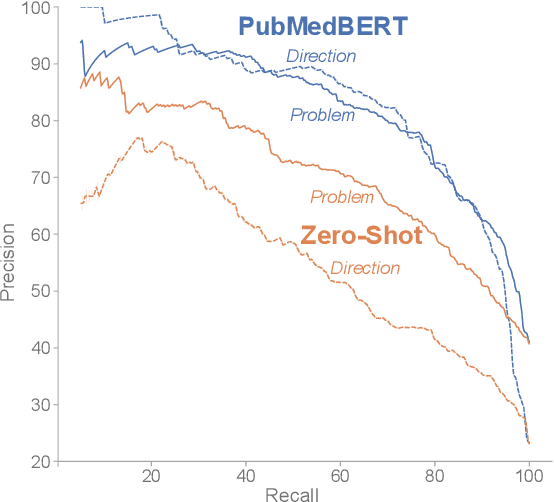
Keeping track of scientific challenges, advances and emerging directions is a fundamental part of research. However, researchers face a flood of papers that hinders discovery of important knowledge. In biomedicine, this directly impacts human lives. To address this problem, we present a novel task of extraction and search of scientific challenges and directions, to facilitate rapid knowledge discovery. We construct and release an expert-annotated corpus of texts sampled from full-length papers, labeled with novel semantic categories that generalize across many types of challenges and directions. We focus on a large corpus of interdisciplinary work relating to the COVID-19 pandemic, ranging from biomedicine to areas such as AI and economics. We apply a model trained on our data to identify challenges and directions across the corpus and build a dedicated search engine. In experiments with 19 researchers and clinicians using our system, we outperform a popular scientific search engine in assisting knowledge discovery. Finally, we show that models trained on our resource generalize to the wider biomedical domain and to AI papers, highlighting its broad utility. We make our data, model and search engine publicly available. https://challenges.apps.allenai.org/
NeuroCartography: Scalable Automatic Visual Summarization of Concepts in Deep Neural Networks
Aug 29, 2021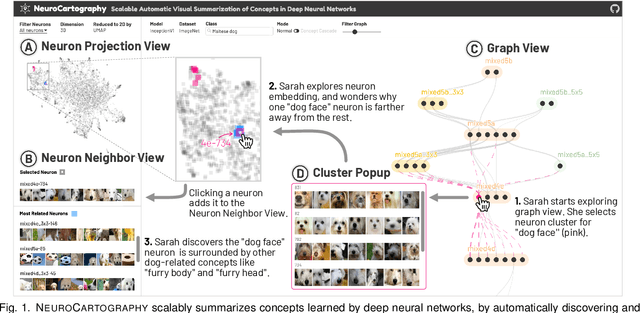


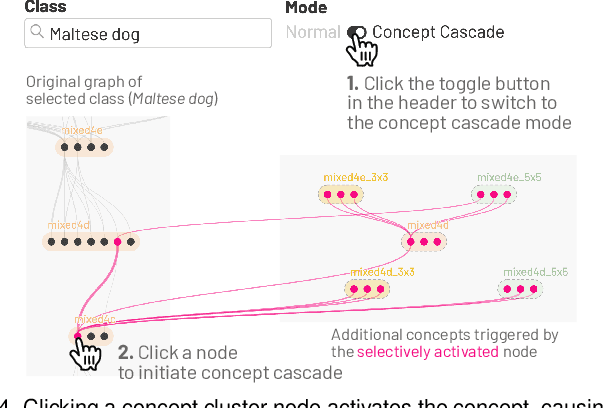
Existing research on making sense of deep neural networks often focuses on neuron-level interpretation, which may not adequately capture the bigger picture of how concepts are collectively encoded by multiple neurons. We present NeuroCartography, an interactive system that scalably summarizes and visualizes concepts learned by neural networks. It automatically discovers and groups neurons that detect the same concepts, and describes how such neuron groups interact to form higher-level concepts and the subsequent predictions. NeuroCartography introduces two scalable summarization techniques: (1) neuron clustering groups neurons based on the semantic similarity of the concepts detected by neurons (e.g., neurons detecting "dog faces" of different breeds are grouped); and (2) neuron embedding encodes the associations between related concepts based on how often they co-occur (e.g., neurons detecting "dog face" and "dog tail" are placed closer in the embedding space). Key to our scalable techniques is the ability to efficiently compute all neuron pairs' relationships, in time linear to the number of neurons instead of quadratic time. NeuroCartography scales to large data, such as the ImageNet dataset with 1.2M images. The system's tightly coordinated views integrate the scalable techniques to visualize the concepts and their relationships, projecting the concept associations to a 2D space in Neuron Projection View, and summarizing neuron clusters and their relationships in Graph View. Through a large-scale human evaluation, we demonstrate that our technique discovers neuron groups that represent coherent, human-meaningful concepts. And through usage scenarios, we describe how our approaches enable interesting and surprising discoveries, such as concept cascades of related and isolated concepts. The NeuroCartography visualization runs in modern browsers and is open-sourced.
Quantifying the Impact of Human Capital, Job History, and Language Factors on Job Seniority with a Large-scale Analysis of Resumes
Jun 15, 2021
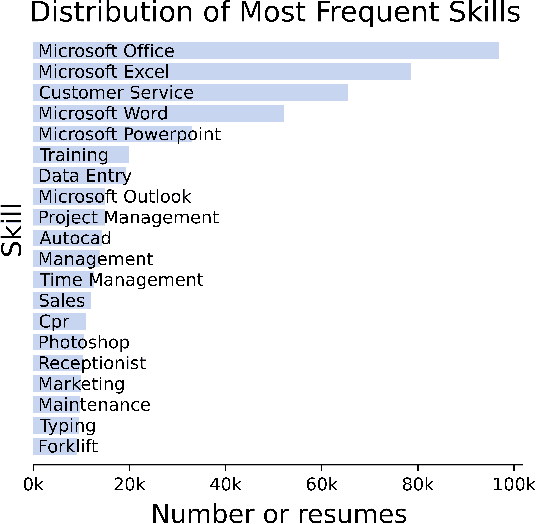
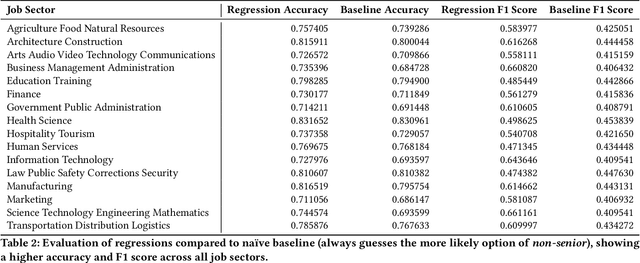
As job markets worldwide have become more competitive and applicant selection criteria have become more opaque, and different (and sometimes contradictory) information and advice is available for job seekers wishing to progress in their careers, it has never been more difficult to determine which factors in a r\'esum\'e most effectively help career progression. In this work we present a novel, large scale dataset of over half a million r\'esum\'es with preliminary analysis to begin to answer empirically which factors help or hurt people wishing to transition to more senior roles as they progress in their career. We find that previous experience forms the most important factor, outweighing other aspects of human capital, and find which language factors in a r\'esum\'e have significant effects. This lays the groundwork for future inquiry in career trajectories using large scale data analysis and natural language processing techniques.
Dodrio: Exploring Transformer Models with Interactive Visualization
Apr 12, 2021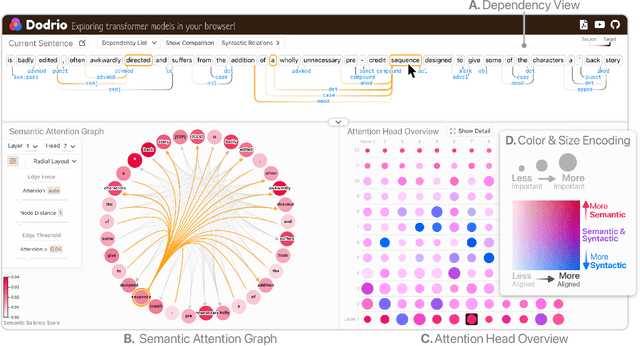
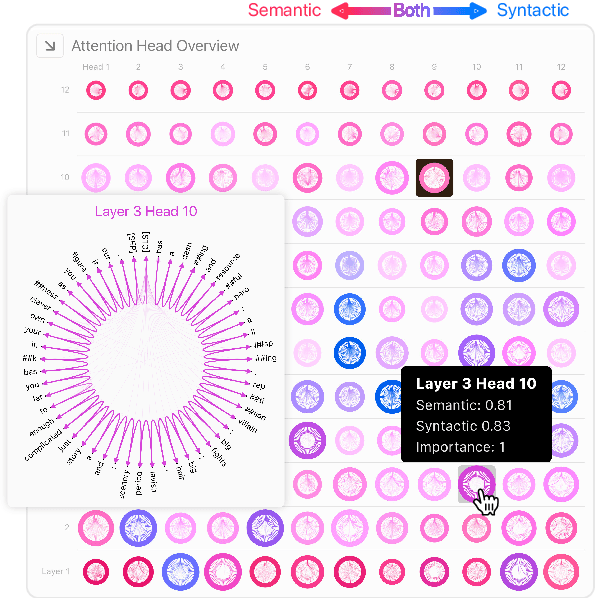
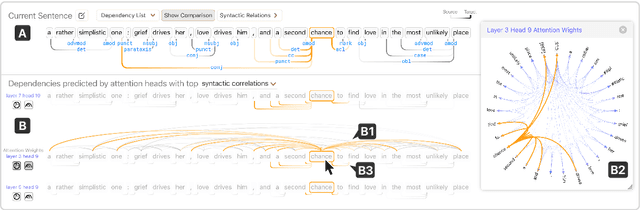
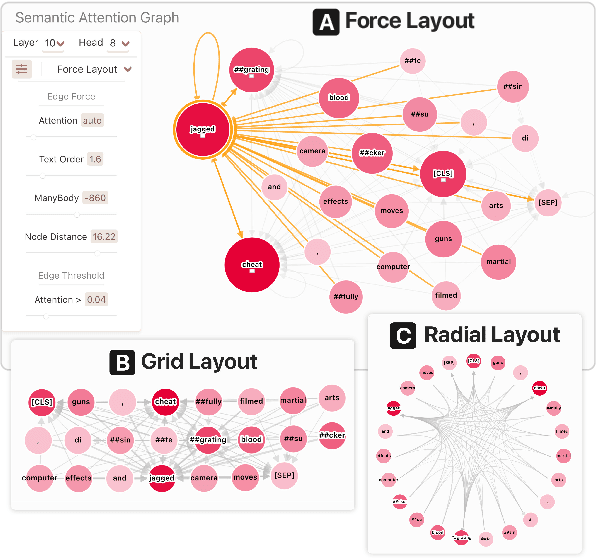
Why do large pre-trained transformer-based models perform so well across a wide variety of NLP tasks? Recent research suggests the key may lie in multi-headed attention mechanism's ability to learn and represent linguistic information. Understanding how these models represent both syntactic and semantic knowledge is vital to investigate why they succeed and fail, what they have learned, and how they can improve. We present Dodrio, an open-source interactive visualization tool to help NLP researchers and practitioners analyze attention mechanisms in transformer-based models with linguistic knowledge. Dodrio tightly integrates an overview that summarizes the roles of different attention heads, and detailed views that help users compare attention weights with the syntactic structure and semantic information in the input text. To facilitate the visual comparison of attention weights and linguistic knowledge, Dodrio applies different graph visualization techniques to represent attention weights scalable to longer input text. Case studies highlight how Dodrio provides insights into understanding the attention mechanism in transformer-based models. Dodrio is available at https://poloclub.github.io/dodrio/.
EnergyVis: Interactively Tracking and Exploring Energy Consumption for ML Models
Mar 30, 2021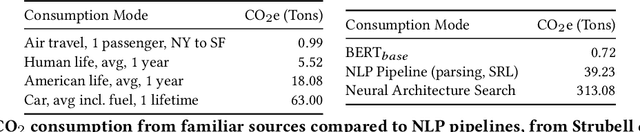
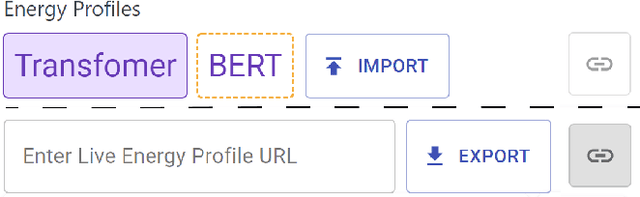
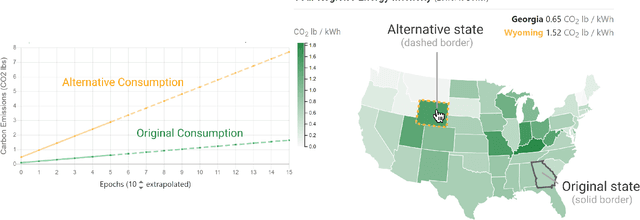
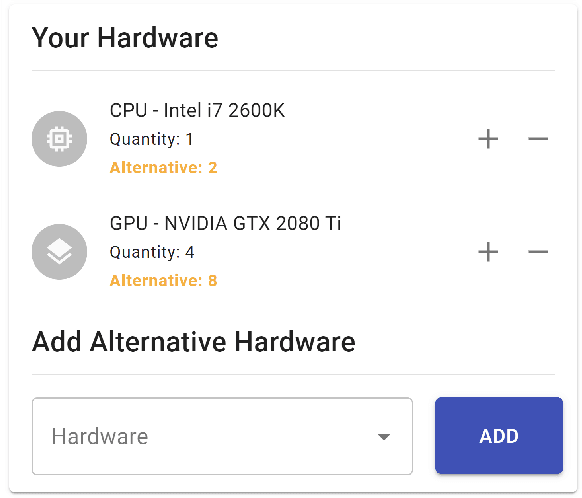
The advent of larger machine learning (ML) models have improved state-of-the-art (SOTA) performance in various modeling tasks, ranging from computer vision to natural language. As ML models continue increasing in size, so does their respective energy consumption and computational requirements. However, the methods for tracking, reporting, and comparing energy consumption remain limited. We presentEnergyVis, an interactive energy consumption tracker for ML models. Consisting of multiple coordinated views, EnergyVis enables researchers to interactively track, visualize and compare model energy consumption across key energy consumption and carbon footprint metrics (kWh and CO2), helping users explore alternative deployment locations and hardware that may reduce carbon footprints. EnergyVis aims to raise awareness concerning computational sustainability by interactively highlighting excessive energy usage during model training; and by providing alternative training options to reduce energy usage.
Best of Both Worlds: Robust Accented Speech Recognition with Adversarial Transfer Learning
Mar 10, 2021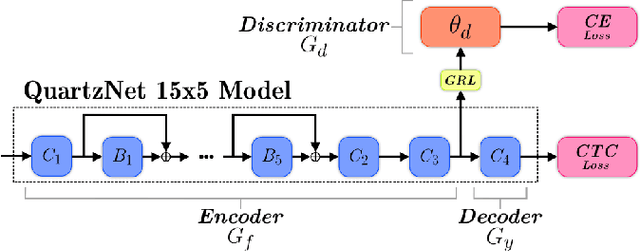
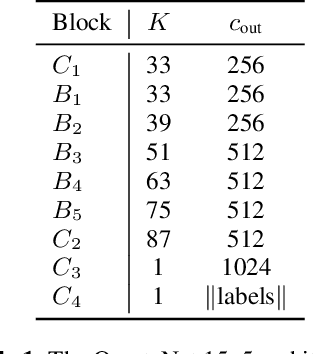

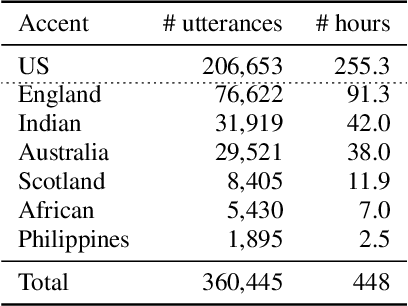
Training deep neural networks for automatic speech recognition (ASR) requires large amounts of transcribed speech. This becomes a bottleneck for training robust models for accented speech which typically contains high variability in pronunciation and other semantics, since obtaining large amounts of annotated accented data is both tedious and costly. Often, we only have access to large amounts of unannotated speech from different accents. In this work, we leverage this unannotated data to provide semantic regularization to an ASR model that has been trained only on one accent, to improve its performance for multiple accents. We propose Accent Pre-Training (Acc-PT), a semi-supervised training strategy that combines transfer learning and adversarial training. Our approach improves the performance of a state-of-the-art ASR model by 33% on average over the baseline across multiple accents, training only on annotated samples from one standard accent, and as little as 105 minutes of unannotated speech from a target accent.
RECAST: Enabling User Recourse and Interpretability of Toxicity Detection Models with Interactive Visualization
Feb 10, 2021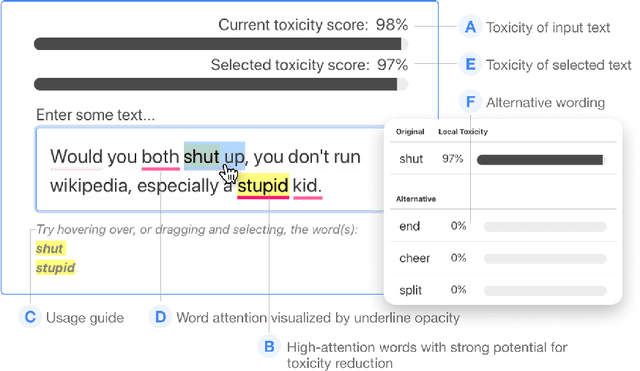

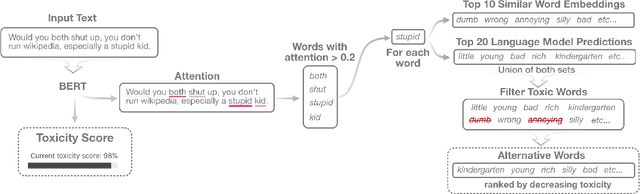

With the widespread use of toxic language online, platforms are increasingly using automated systems that leverage advances in natural language processing to automatically flag and remove toxic comments. However, most automated systems -- when detecting and moderating toxic language -- do not provide feedback to their users, let alone provide an avenue of recourse for these users to make actionable changes. We present our work, RECAST, an interactive, open-sourced web tool for visualizing these models' toxic predictions, while providing alternative suggestions for flagged toxic language. Our work also provides users with a new path of recourse when using these automated moderation tools. RECAST highlights text responsible for classifying toxicity, and allows users to interactively substitute potentially toxic phrases with neutral alternatives. We examined the effect of RECAST via two large-scale user evaluations, and found that RECAST was highly effective at helping users reduce toxicity as detected through the model. Users also gained a stronger understanding of the underlying toxicity criterion used by black-box models, enabling transparency and recourse. In addition, we found that when users focus on optimizing language for these models instead of their own judgement (which is the implied incentive and goal of deploying automated models), these models cease to be effective classifiers of toxicity compared to human annotations. This opens a discussion for how toxicity detection models work and should work, and their effect on the future of online discourse.
MalNet: A Large-Scale Cybersecurity Image Database of Malicious Software
Jan 31, 2021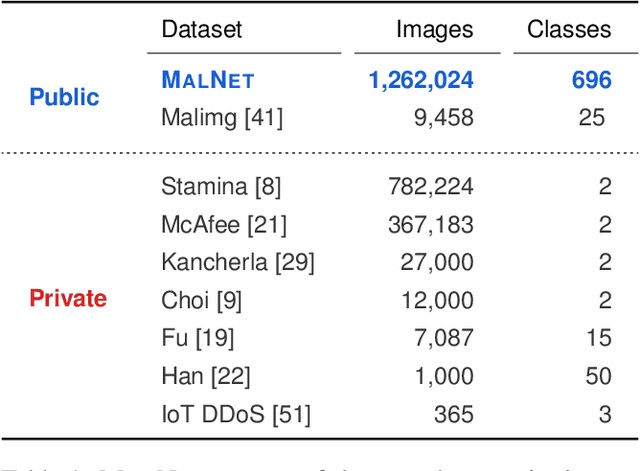
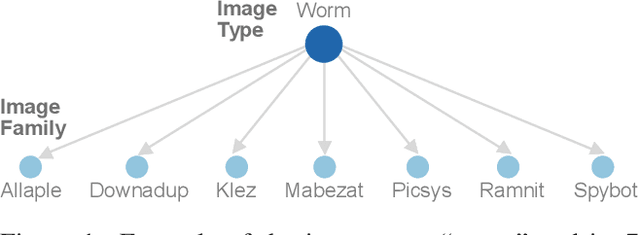
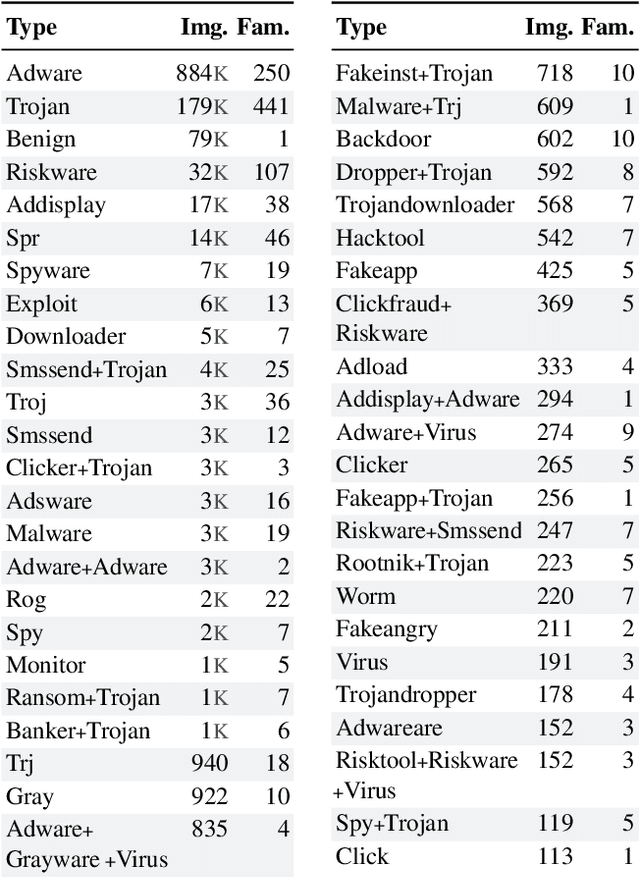
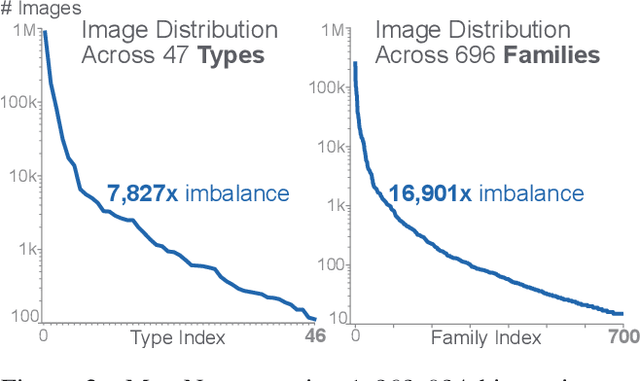
Computer vision is playing an increasingly important role in automated malware detection with to the rise of the image-based binary representation. These binary images are fast to generate, require no feature engineering, and are resilient to popular obfuscation methods. Significant research has been conducted in this area, however, it has been restricted to small-scale or private datasets that only a few industry labs and research teams have access to. This lack of availability hinders examination of existing work, development of new research, and dissemination of ideas. We introduce MalNet, the largest publicly available cybersecurity image database, offering 133x more images and 27x more classes than the only other public binary-image database. MalNet contains over 1.2 million images across a hierarchy of 47 types and 696 families. We provide extensive analysis of MalNet, discussing its properties and provenance. The scale and diversity of MalNet unlocks new and exciting cybersecurity opportunities to the computer vision community--enabling discoveries and research directions that were previously not possible. The database is publicly available at www.mal-net.org.
SkeletonVis: Interactive Visualization for Understanding Adversarial Attacks on Human Action Recognition Models
Jan 26, 2021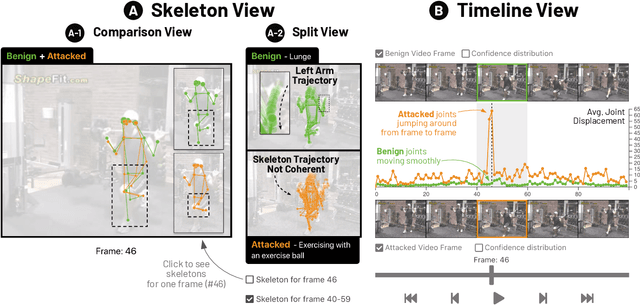
Skeleton-based human action recognition technologies are increasingly used in video based applications, such as home robotics, healthcare on aging population, and surveillance. However, such models are vulnerable to adversarial attacks, raising serious concerns for their use in safety-critical applications. To develop an effective defense against attacks, it is essential to understand how such attacks mislead the pose detection models into making incorrect predictions. We present SkeletonVis, the first interactive system that visualizes how the attacks work on the models to enhance human understanding of attacks.
A Large-Scale Database for Graph Representation Learning
Nov 16, 2020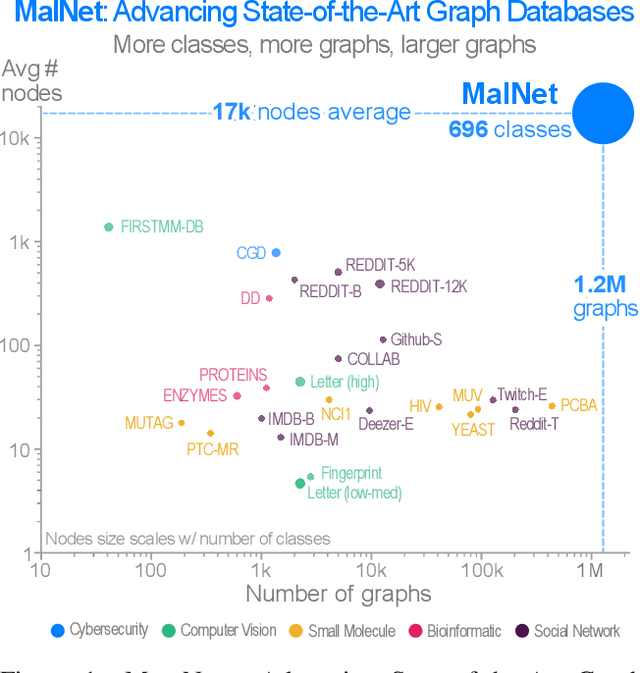
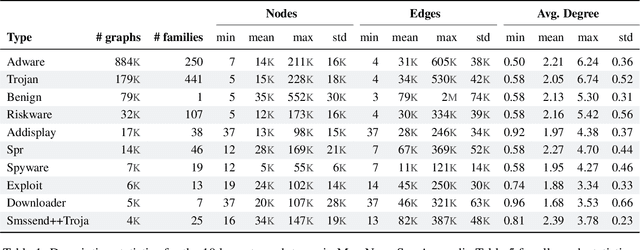
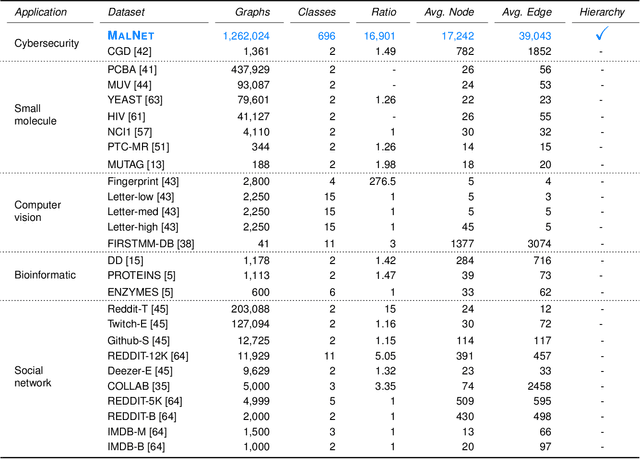
With the rapid emergence of graph representation learning, the construction of new large-scale datasets are necessary to distinguish model capabilities and accurately assess the strengths and weaknesses of each technique. By carefully analyzing existing graph databases, we identify 3 critical components important for advancing the field of graph representation learning: (1) large graphs, (2) many graphs, and (3) class diversity. To date, no single graph database offers all of these desired properties. We introduce MalNet, the largest public graph database ever constructed, representing a large-scale ontology of software function call graphs. MalNet contains over 1.2 million graphs, averaging over 17k nodes and 39k edges per graph, across a hierarchy of 47 types and 696 families. Compared to the popular REDDIT-12K database, MalNet offers 105x more graphs, 44x larger graphs on average, and 63x the classes. We provide a detailed analysis of MalNet, discussing its properties and provenance. The unprecedented scale and diversity of MalNet offers exciting opportunities to advance the frontiers of graph representation learning---enabling new discoveries and research into imbalanced classification, explainability and the impact of class hardness. The database is publically available at www.mal-net.org.