 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning
Paper and Code

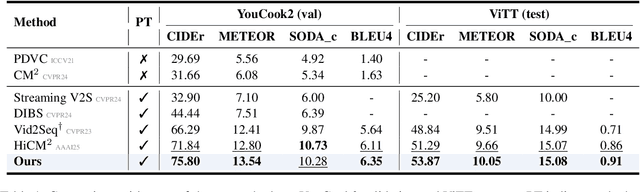
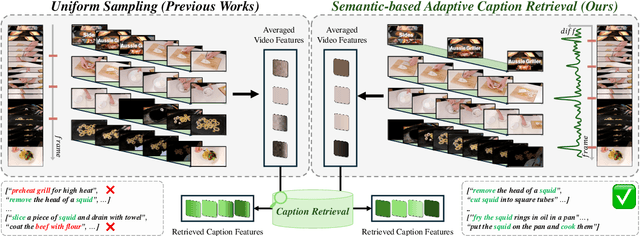
Dense video captioning aims to temporally localize events in video and generate captions for each event. While recent works propose end-to-end models, they suffer from two limitations: (1) applying timestamp supervision only to text while treating all video frames equally, and (2) retrieving captions from fixed-size video chunks, overlooking scene transitions. To address these, we propose Sali4Vid, a simple yet effective saliency-aware framework. We introduce Saliency-aware Video Reweighting, which converts timestamp annotations into sigmoid-based frame importance weights, and Semantic-based Adaptive Caption Retrieval, which segments videos by frame similarity to capture scene transitions and improve caption retrieval. Sali4Vid achieves state-of-the-art results on YouCook2 and ViTT, demonstrating the benefit of jointly improving video weighting and retrieval for dense video captioning