 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning
Mar 12, 2026Existing retrieval-augmented approaches for Dense Video Captioning (DVC) often fail to achieve accurate temporal segmentation aligned with true event boundaries, as they rely on heuristic strategies that overlook ground truth event boundaries. The proposed framework, \textbf{STaRC}, overcomes this limitation by supervising frame-level saliency through a highlight detection module. Note that the highlight detection module is trained on binary labels derived directly from DVC ground truth annotations without the need for additional annotation. We also propose to utilize the saliency scores as a unified temporal signal that drives retrieval via saliency-guided segmentation and informs caption generation through explicit Saliency Prompts injected into the decoder. By enforcing saliency-constrained segmentation, our method produces temporally coherent segments that align closely with actual event transitions, leading to more accurate retrieval and contextually grounded caption generation. We conduct comprehensive evaluations on the YouCook2 and ViTT benchmarks, where STaRC achieves state-of-the-art performance across most of the metrics. Our code is available at https://github.com/ermitaju1/STaRC
Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning
Sep 04, 2025
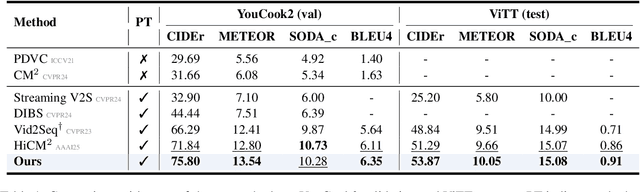
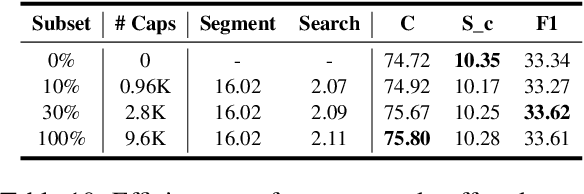
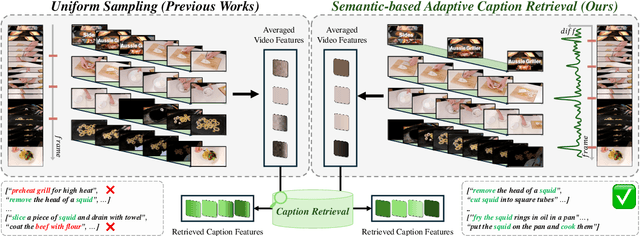
Dense video captioning aims to temporally localize events in video and generate captions for each event. While recent works propose end-to-end models, they suffer from two limitations: (1) applying timestamp supervision only to text while treating all video frames equally, and (2) retrieving captions from fixed-size video chunks, overlooking scene transitions. To address these, we propose Sali4Vid, a simple yet effective saliency-aware framework. We introduce Saliency-aware Video Reweighting, which converts timestamp annotations into sigmoid-based frame importance weights, and Semantic-based Adaptive Caption Retrieval, which segments videos by frame similarity to capture scene transitions and improve caption retrieval. Sali4Vid achieves state-of-the-art results on YouCook2 and ViTT, demonstrating the benefit of jointly improving video weighting and retrieval for dense video captioning
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning
Jul 24, 2025



Zero-shot Image Captioning (ZIC) increasingly utilizes synthetic datasets generated by text-to-image (T2I) models to mitigate the need for costly manual annotation. However, these T2I models often produce images that exhibit semantic misalignments with their corresponding input captions (e.g., missing objects, incorrect attributes), resulting in noisy synthetic image-caption pairs that can hinder model training. Existing dataset pruning techniques are largely designed for removing noisy text in web-crawled data. However, these methods are ill-suited for the distinct challenges of synthetic data, where captions are typically well-formed, but images may be inaccurate representations. To address this gap, we introduce SynC, a novel framework specifically designed to refine synthetic image-caption datasets for ZIC. Instead of conventional filtering or regeneration, SynC focuses on reassigning captions to the most semantically aligned images already present within the synthetic image pool. Our approach employs a one-to-many mapping strategy by initially retrieving multiple relevant candidate images for each caption. We then apply a cycle-consistency-inspired alignment scorer that selects the best image by verifying its ability to retrieve the original caption via image-to-text retrieval. Extensive evaluations demonstrate that SynC consistently and significantly improves performance across various ZIC models on standard benchmarks (MS-COCO, Flickr30k, NoCaps), achieving state-of-the-art results in several scenarios. SynC offers an effective strategy for curating refined synthetic data to enhance ZIC.