 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video Captioning
Mar 05, 2026Weakly-Supervised Dense Video Captioning aims to localize and describe events in videos trained only on caption annotations, without temporal boundaries. Prior work introduced an implicit supervision paradigm based on Gaussian masking and complementary captioning. However, existing method focuses merely on generating non-overlapping masks without considering their semantic relationship to corresponding events, resulting in simplistic, uniformly distributed masks that fail to capture semantically meaningful regions. Moreover, relying solely on ground-truth captions leads to sub-optimal performance due to the inherent sparsity of existing datasets. In this work, we propose SAIL, which constructs semantically-aware masks through cross-modal alignment. Our similarity aware training objective guides masks to emphasize video regions with high similarity to their corresponding event captions. Furthermore, to guide more accurate mask generation under sparse annotation settings, we introduce an LLM-based augmentation strategy that generates synthetic captions to provide additional alignment signals. These synthetic captions are incorporated through an inter-mask mechanism, providing auxiliary guidance for precise temporal localization without degrading the main objective. Experiments on ActivityNet Captions and YouCook2 demonstrate state-of-the-art performance on both captioning and localization metrics.
Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning
Sep 04, 2025
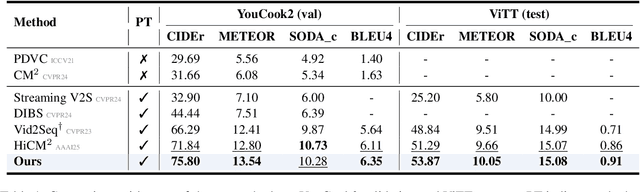
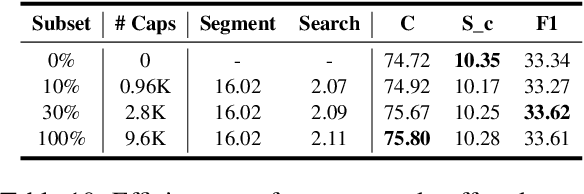
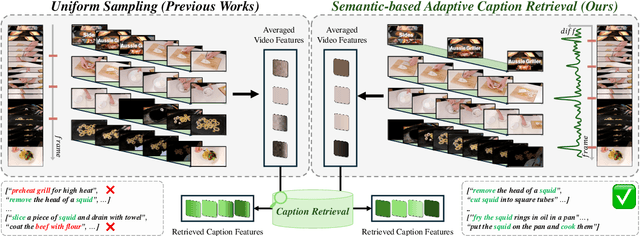
Dense video captioning aims to temporally localize events in video and generate captions for each event. While recent works propose end-to-end models, they suffer from two limitations: (1) applying timestamp supervision only to text while treating all video frames equally, and (2) retrieving captions from fixed-size video chunks, overlooking scene transitions. To address these, we propose Sali4Vid, a simple yet effective saliency-aware framework. We introduce Saliency-aware Video Reweighting, which converts timestamp annotations into sigmoid-based frame importance weights, and Semantic-based Adaptive Caption Retrieval, which segments videos by frame similarity to capture scene transitions and improve caption retrieval. Sali4Vid achieves state-of-the-art results on YouCook2 and ViTT, demonstrating the benefit of jointly improving video weighting and retrieval for dense video captioning
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning
Jul 24, 2025



Zero-shot Image Captioning (ZIC) increasingly utilizes synthetic datasets generated by text-to-image (T2I) models to mitigate the need for costly manual annotation. However, these T2I models often produce images that exhibit semantic misalignments with their corresponding input captions (e.g., missing objects, incorrect attributes), resulting in noisy synthetic image-caption pairs that can hinder model training. Existing dataset pruning techniques are largely designed for removing noisy text in web-crawled data. However, these methods are ill-suited for the distinct challenges of synthetic data, where captions are typically well-formed, but images may be inaccurate representations. To address this gap, we introduce SynC, a novel framework specifically designed to refine synthetic image-caption datasets for ZIC. Instead of conventional filtering or regeneration, SynC focuses on reassigning captions to the most semantically aligned images already present within the synthetic image pool. Our approach employs a one-to-many mapping strategy by initially retrieving multiple relevant candidate images for each caption. We then apply a cycle-consistency-inspired alignment scorer that selects the best image by verifying its ability to retrieve the original caption via image-to-text retrieval. Extensive evaluations demonstrate that SynC consistently and significantly improves performance across various ZIC models on standard benchmarks (MS-COCO, Flickr30k, NoCaps), achieving state-of-the-art results in several scenarios. SynC offers an effective strategy for curating refined synthetic data to enhance ZIC.
SIDA: Synthetic Image Driven Zero-shot Domain Adaptation
Jul 24, 2025



Zero-shot domain adaptation is a method for adapting a model to a target domain without utilizing target domain image data. To enable adaptation without target images, existing studies utilize CLIP's embedding space and text description to simulate target-like style features. Despite the previous achievements in zero-shot domain adaptation, we observe that these text-driven methods struggle to capture complex real-world variations and significantly increase adaptation time due to their alignment process. Instead of relying on text descriptions, we explore solutions leveraging image data, which provides diverse and more fine-grained style cues. In this work, we propose SIDA, a novel and efficient zero-shot domain adaptation method leveraging synthetic images. To generate synthetic images, we first create detailed, source-like images and apply image translation to reflect the style of the target domain. We then utilize the style features of these synthetic images as a proxy for the target domain. Based on these features, we introduce Domain Mix and Patch Style Transfer modules, which enable effective modeling of real-world variations. In particular, Domain Mix blends multiple styles to expand the intra-domain representations, and Patch Style Transfer assigns different styles to individual patches. We demonstrate the effectiveness of our method by showing state-of-the-art performance in diverse zero-shot adaptation scenarios, particularly in challenging domains. Moreover, our approach achieves high efficiency by significantly reducing the overall adaptation time.
ViPCap: Retrieval Text-Based Visual Prompts for Lightweight Image Captioning
Dec 26, 2024Recent lightweight image captioning models using retrieved data mainly focus on text prompts. However, previous works only utilize the retrieved text as text prompts, and the visual information relies only on the CLIP visual embedding. Because of this issue, there is a limitation that the image descriptions inherent in the prompt are not sufficiently reflected in the visual embedding space. To tackle this issue, we propose ViPCap, a novel retrieval text-based visual prompt for lightweight image captioning. ViPCap leverages the retrieved text with image information as visual prompts to enhance the ability of the model to capture relevant visual information. By mapping text prompts into the CLIP space and generating multiple randomized Gaussian distributions, our method leverages sampling to explore randomly augmented distributions and effectively retrieves the semantic features that contain image information. These retrieved features are integrated into the image and designated as the visual prompt, leading to performance improvements on the datasets such as COCO, Flickr30k, and NoCaps. Experimental results demonstrate that ViPCap significantly outperforms prior lightweight captioning models in efficiency and effectiveness, demonstrating the potential for a plug-and-play solution.
IFCap: Image-like Retrieval and Frequency-based Entity Filtering for Zero-shot Captioning
Sep 26, 2024



Recent advancements in image captioning have explored text-only training methods to overcome the limitations of paired image-text data. However, existing text-only training methods often overlook the modality gap between using text data during training and employing images during inference. To address this issue, we propose a novel approach called Image-like Retrieval, which aligns text features with visually relevant features to mitigate the modality gap. Our method further enhances the accuracy of generated captions by designing a Fusion Module that integrates retrieved captions with input features. Additionally, we introduce a Frequency-based Entity Filtering technique that significantly improves caption quality. We integrate these methods into a unified framework, which we refer to as IFCap ($\textbf{I}$mage-like Retrieval and $\textbf{F}$requency-based Entity Filtering for Zero-shot $\textbf{Cap}$tioning). Through extensive experimentation, our straightforward yet powerful approach has demonstrated its efficacy, outperforming the state-of-the-art methods by a significant margin in both image captioning and video captioning compared to zero-shot captioning based on text-only training.