 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-WiViG: Interpretable Window Vision GNN
Mar 11, 2025Deep learning models based on graph neural networks have emerged as a popular approach for solving computer vision problems. They encode the image into a graph structure and can be beneficial for efficiently capturing the long-range dependencies typically present in remote sensing imagery. However, an important drawback of these methods is their black-box nature which may hamper their wider usage in critical applications. In this work, we tackle the self-interpretability of the graph-based vision models by proposing our Interpretable Window Vision GNN (i-WiViG) approach, which provides explanations by automatically identifying the relevant subgraphs for the model prediction. This is achieved with window-based image graph processing that constrains the node receptive field to a local image region and by using a self-interpretable graph bottleneck that ranks the importance of the long-range relations between the image regions. We evaluate our approach to remote sensing classification and regression tasks, showing it achieves competitive performance while providing inherent and faithful explanations through the identified relations. Further, the quantitative evaluation reveals that our model reduces the infidelity of post-hoc explanations compared to other Vision GNN models, without sacrificing explanation sparsity.
COMIX: Compositional Explanations using Prototypes
Jan 10, 2025



Aligning machine representations with human understanding is key to improving interpretability of machine learning (ML) models. When classifying a new image, humans often explain their decisions by decomposing the image into concepts and pointing to corresponding regions in familiar images. Current ML explanation techniques typically either trace decision-making processes to reference prototypes, generate attribution maps highlighting feature importance, or incorporate intermediate bottlenecks designed to align with human-interpretable concepts. The proposed method, named COMIX, classifies an image by decomposing it into regions based on learned concepts and tracing each region to corresponding ones in images from the training dataset, assuring that explanations fully represent the actual decision-making process. We dissect the test image into selected internal representations of a neural network to derive prototypical parts (primitives) and match them with the corresponding primitives derived from the training data. In a series of qualitative and quantitative experiments, we theoretically prove and demonstrate that our method, in contrast to post hoc analysis, provides fidelity of explanations and shows that the efficiency is competitive with other inherently interpretable architectures. Notably, it shows substantial improvements in fidelity and sparsity metrics, including 48.82% improvement in the C-insertion score on the ImageNet dataset over the best state-of-the-art baseline.
IMAFD: An Interpretable Multi-stage Approach to Flood Detection from time series Multispectral Data
May 13, 2024



In this paper, we address two critical challenges in the domain of flood detection: the computational expense of large-scale time series change detection and the lack of interpretable decision-making processes on explainable AI (XAI). To overcome these challenges, we proposed an interpretable multi-stage approach to flood detection, IMAFD has been proposed. It provides an automatic, efficient and interpretable solution suitable for large-scale remote sensing tasks and offers insight into the decision-making process. The proposed IMAFD approach combines the analysis of the dynamic time series image sequences to identify images with possible flooding with the static, within-image semantic segmentation. It combines anomaly detection (at both image and pixel level) with semantic segmentation. The flood detection problem is addressed through four stages: (1) at a sequence level: identifying the suspected images (2) at a multi-image level: detecting change within suspected images (3) at an image level: semantic segmentation of images into Land, Water or Cloud class (4) decision making. Our contributions are two folder. First, we efficiently reduced the number of frames to be processed for dense change detection by providing a multi-stage holistic approach to flood detection. Second, the proposed semantic change detection method (stage 3) provides human users with an interpretable decision-making process, while most of the explainable AI (XAI) methods provide post hoc explanations. The evaluation of the proposed IMAFD framework was performed on three datasets, WorldFloods, RavAEn and MediaEval. For all the above datasets, the proposed framework demonstrates a competitive performance compared to other methods offering also interpretability and insight.
Unsupervised Domain Adaptation within Deep Foundation Latent Spaces
Feb 22, 2024


The vision transformer-based foundation models, such as ViT or Dino-V2, are aimed at solving problems with little or no finetuning of features. Using a setting of prototypical networks, we analyse to what extent such foundation models can solve unsupervised domain adaptation without finetuning over the source or target domain. Through quantitative analysis, as well as qualitative interpretations of decision making, we demonstrate that the suggested method can improve upon existing baselines, as well as showcase the limitations of such approach yet to be solved.
Towards interpretable-by-design deep learning algorithms
Nov 19, 2023



The proposed framework named IDEAL (Interpretable-by-design DEep learning ALgorithms) recasts the standard supervised classification problem into a function of similarity to a set of prototypes derived from the training data, while taking advantage of existing latent spaces of large neural networks forming so-called Foundation Models (FM). This addresses the issue of explainability (stage B) while retaining the benefits from the tremendous achievements offered by DL models (e.g., visual transformers, ViT) pre-trained on huge data sets such as IG-3.6B + ImageNet-1K or LVD-142M (stage A). We show that one can turn such DL models into conceptually simpler, explainable-through-prototypes ones. The key findings can be summarized as follows: (1) the proposed models are interpretable through prototypes, mitigating the issue of confounded interpretations, (2) the proposed IDEAL framework circumvents the issue of catastrophic forgetting allowing efficient class-incremental learning, and (3) the proposed IDEAL approach demonstrates that ViT architectures narrow the gap between finetuned and non-finetuned models allowing for transfer learning in a fraction of time \textbf{without} finetuning of the feature space on a target dataset with iterative supervised methods.
Imbedding Deep Neural Networks
Feb 15, 2022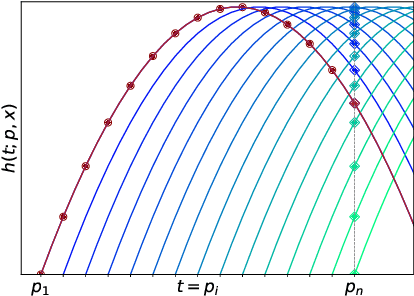
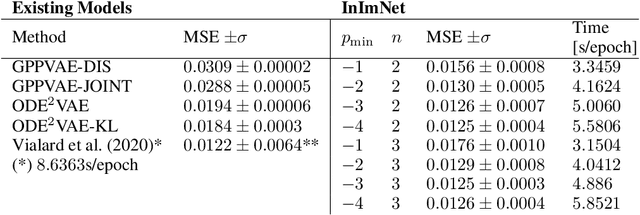
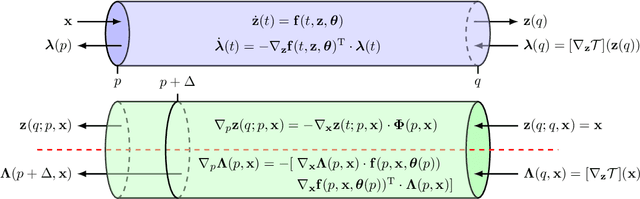
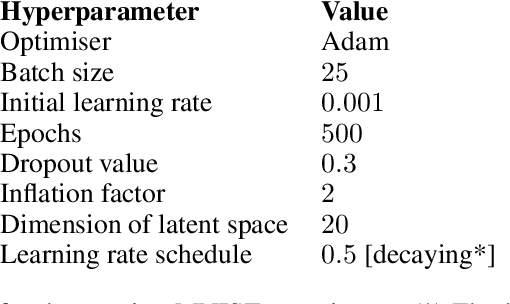
Continuous-depth neural networks, such as Neural ODEs, have refashioned the understanding of residual neural networks in terms of non-linear vector-valued optimal control problems. The common solution is to use the adjoint sensitivity method to replicate a forward-backward pass optimisation problem. We propose a new approach which explicates the network's `depth' as a fundamental variable, thus reducing the problem to a system of forward-facing initial value problems. This new method is based on the principle of `Invariant Imbedding' for which we prove a general solution, applicable to all non-linear, vector-valued optimal control problems with both running and terminal loss. Our new architectures provide a tangible tool for inspecting the theoretical--and to a great extent unexplained--properties of network depth. They also constitute a resource of discrete implementations of Neural ODEs comparable to classes of imbedded residual neural networks. Through a series of experiments, we show the competitive performance of the proposed architectures for supervised learning and time series prediction.
Skillful Precipitation Nowcasting using Deep Generative Models of Radar
Apr 02, 2021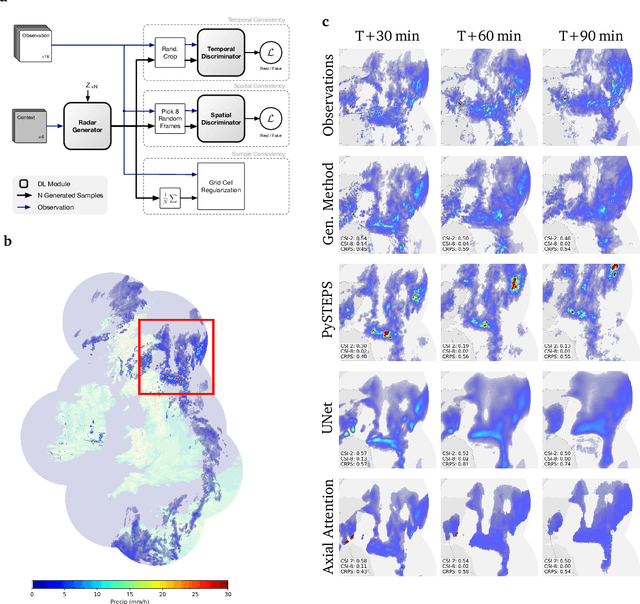
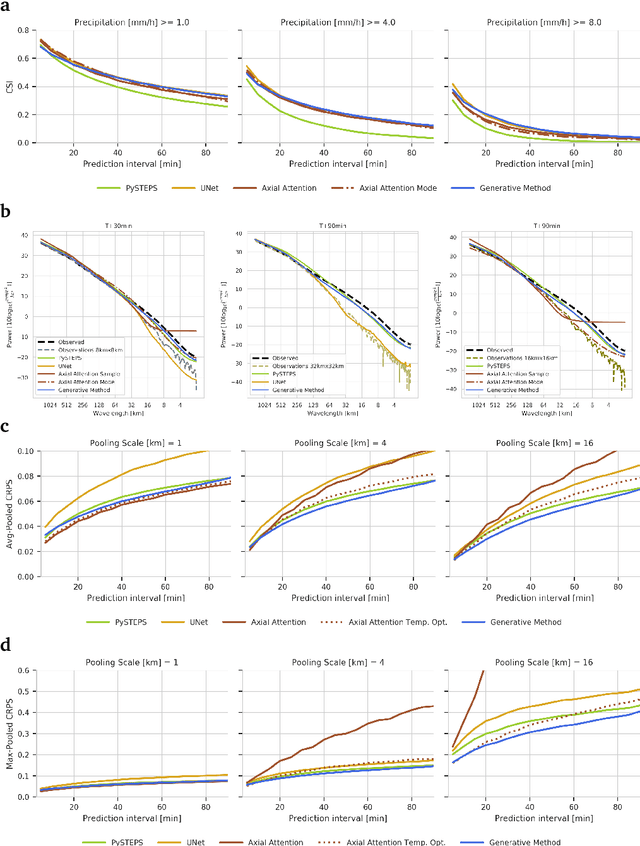
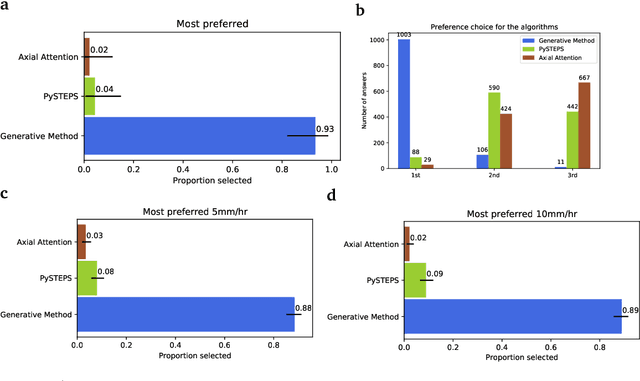
Precipitation nowcasting, the high-resolution forecasting of precipitation up to two hours ahead, supports the real-world socio-economic needs of many sectors reliant on weather-dependent decision-making. State-of-the-art operational nowcasting methods typically advect precipitation fields with radar-based wind estimates, and struggle to capture important non-linear events such as convective initiations. Recently introduced deep learning methods use radar to directly predict future rain rates, free of physical constraints. While they accurately predict low-intensity rainfall, their operational utility is limited because their lack of constraints produces blurry nowcasts at longer lead times, yielding poor performance on more rare medium-to-heavy rain events. To address these challenges, we present a Deep Generative Model for the probabilistic nowcasting of precipitation from radar. Our model produces realistic and spatio-temporally consistent predictions over regions up to 1536 km x 1280 km and with lead times from 5-90 min ahead. In a systematic evaluation by more than fifty expert forecasters from the Met Office, our generative model ranked first for its accuracy and usefulness in 88% of cases against two competitive methods, demonstrating its decision-making value and ability to provide physical insight to real-world experts. When verified quantitatively, these nowcasts are skillful without resorting to blurring. We show that generative nowcasting can provide probabilistic predictions that improve forecast value and support operational utility, and at resolutions and lead times where alternative methods struggle.
A review of radar-based nowcasting of precipitation and applicable machine learning techniques
May 11, 2020
A 'nowcast' is a type of weather forecast which makes predictions in the very short term, typically less than two hours - a period in which traditional numerical weather prediction can be limited. This type of weather prediction has important applications for commercial aviation; public and outdoor events; and the construction industry, power utilities, and ground transportation services that conduct much of their work outdoors. Importantly, one of the key needs for nowcasting systems is in the provision of accurate warnings of adverse weather events, such as heavy rain and flooding, for the protection of life and property in such situations. Typical nowcasting approaches are based on simple extrapolation models applied to observations, primarily rainfall radar. In this paper we review existing techniques to radar-based nowcasting from environmental sciences, as well as the statistical approaches that are applicable from the field of machine learning. Nowcasting continues to be an important component of operational systems and we believe new advances are possible with new partnerships between the environmental science and machine learning communities.
On-Policy Trust Region Policy Optimisation with Replay Buffers
Jan 18, 2019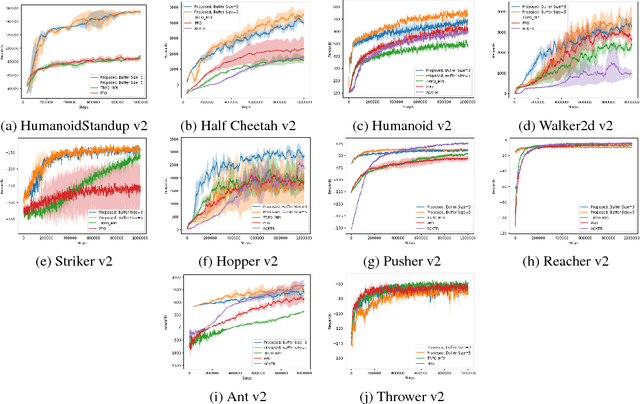
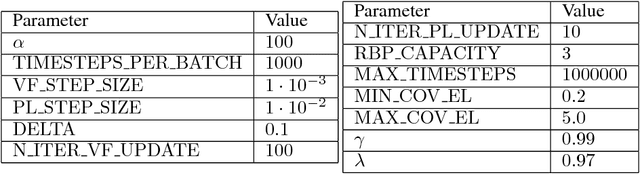
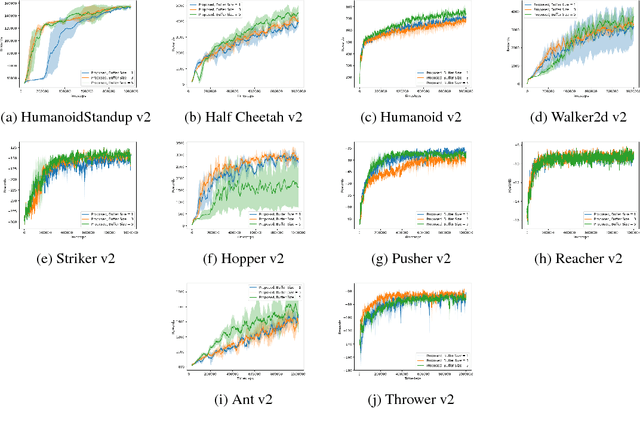
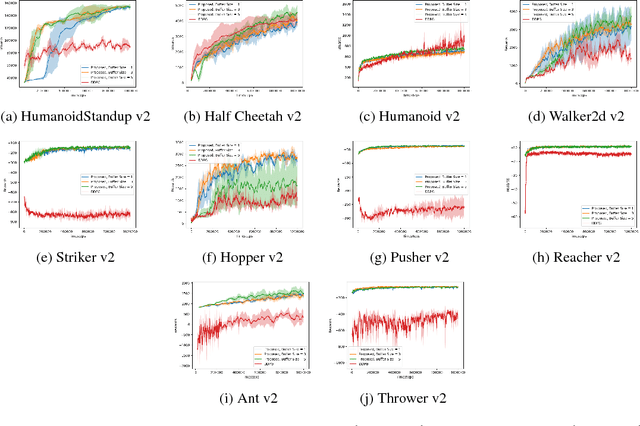
Building upon the recent success of deep reinforcement learning methods, we investigate the possibility of on-policy reinforcement learning improvement by reusing the data from several consecutive policies. On-policy methods bring many benefits, such as ability to evaluate each resulting policy. However, they usually discard all the information about the policies which existed before. In this work, we propose adaptation of the replay buffer concept, borrowed from the off-policy learning setting, to create the method, combining advantages of on- and off-policy learning. To achieve this, the proposed algorithm generalises the $Q$-, value and advantage functions for data from multiple policies. The method uses trust region optimisation, while avoiding some of the common problems of the algorithms such as TRPO or ACKTR: it uses hyperparameters to replace the trust region selection heuristics, as well as the trainable covariance matrix instead of the fixed one. In many cases, the method not only improves the results comparing to the state-of-the-art trust region on-policy learning algorithms such as PPO, ACKTR and TRPO, but also with respect to their off-policy counterpart DDPG.
Aggregated Sparse Attention for Steering Angle Prediction
Mar 15, 2018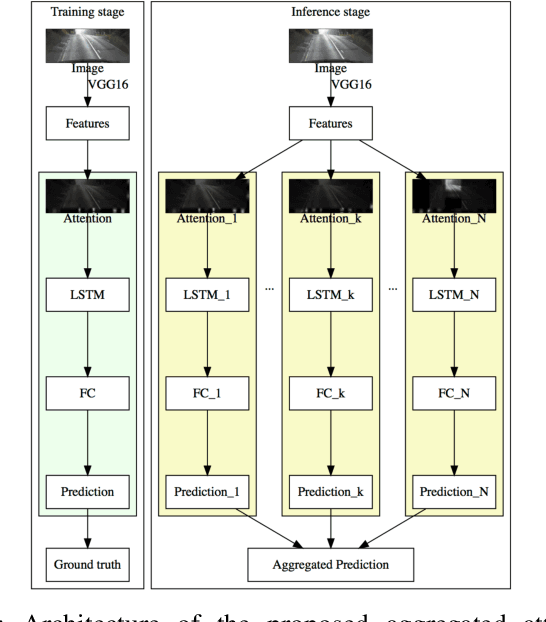

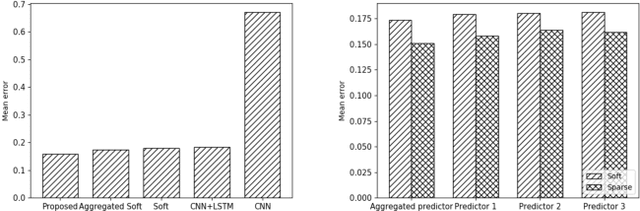
In this paper, we apply the attention mechanism to autonomous driving for steering angle prediction. We propose the first model, applying the recently introduced sparse attention mechanism to visual domain, as well as the aggregated extension for this model. We show the improvement of the proposed method, comparing to no attention as well as to different types of attention.