 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Machine Learning via ADMM
May 01, 2019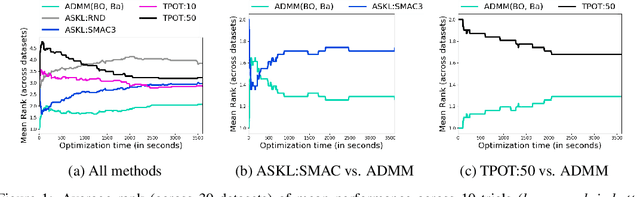
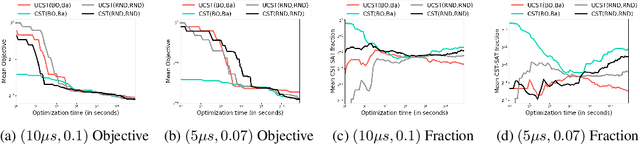
We study the automated machine learning (AutoML) problem of jointly selecting appropriate algorithms from an algorithm portfolio as well as optimizing their hyper-parameters for certain learning tasks. The main challenges include a) the coupling between algorithm selection and hyper-parameter optimization (HPO), and b) the black-box optimization nature of the problem where the optimizer cannot access the gradients of the loss function but may query function values. To circumvent these difficulties, we propose a new AutoML framework by leveraging the alternating direction method of multipliers (ADMM) scheme. Due to the splitting properties of ADMM, algorithm selection and HPO can be decomposed through the augmented Lagrangian function. As a result, HPO with mixed continuous and integer constraints are efficiently handled through a query-efficient Bayesian optimization approach and Euclidean projection operator that yields a closed-form solution. Algorithm selection in ADMM is naturally interpreted as a combinatorial bandit problem. The effectiveness of our proposed methodology is compared to state-of-the-art AutoML schemes such as TPOT and Auto-sklearn on numerous benchmark data sets.
A Survey on Practical Applications of Multi-Armed and Contextual Bandits
Apr 02, 2019
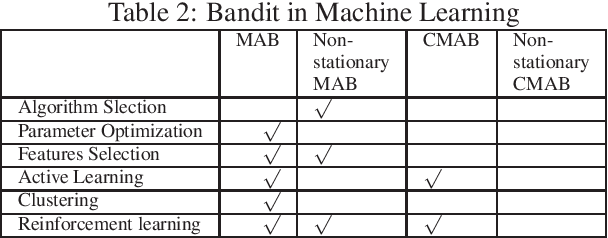
In recent years, multi-armed bandit (MAB) framework has attracted a lot of attention in various applications, from recommender systems and information retrieval to healthcare and finance, due to its stellar performance combined with certain attractive properties, such as learning from less feedback. The multi-armed bandit field is currently flourishing, as novel problem settings and algorithms motivated by various practical applications are being introduced, building on top of the classical bandit problem. This article aims to provide a comprehensive review of top recent developments in multiple real-life applications of the multi-armed bandit. Specifically, we introduce a taxonomy of common MAB-based applications and summarize state-of-art for each of those domains. Furthermore, we identify important current trends and provide new perspectives pertaining to the future of this exciting and fast-growing field.
Beyond Backprop: Online Alternating Minimization with Auxiliary Variables
Oct 24, 2018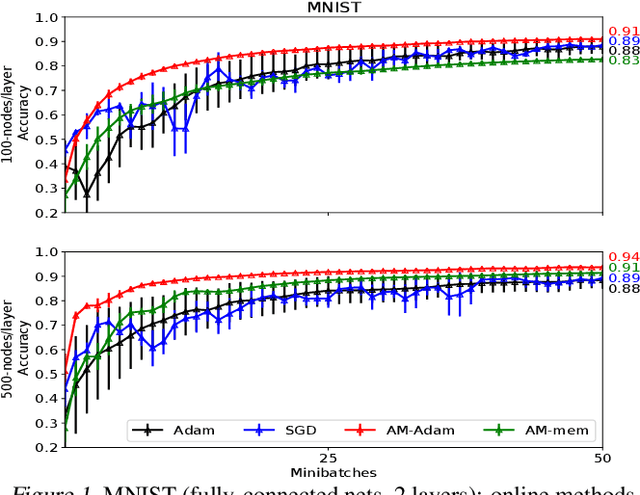
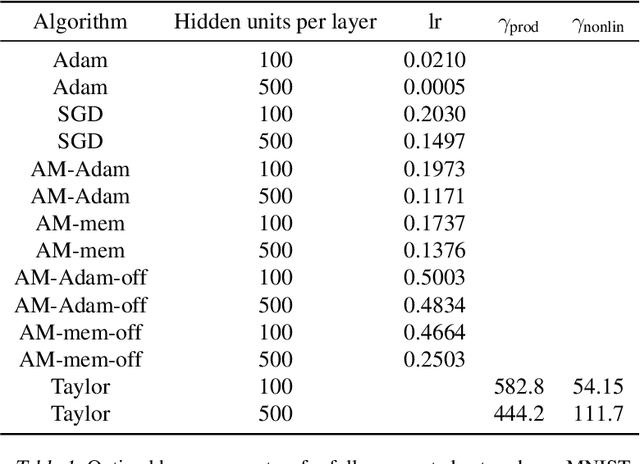
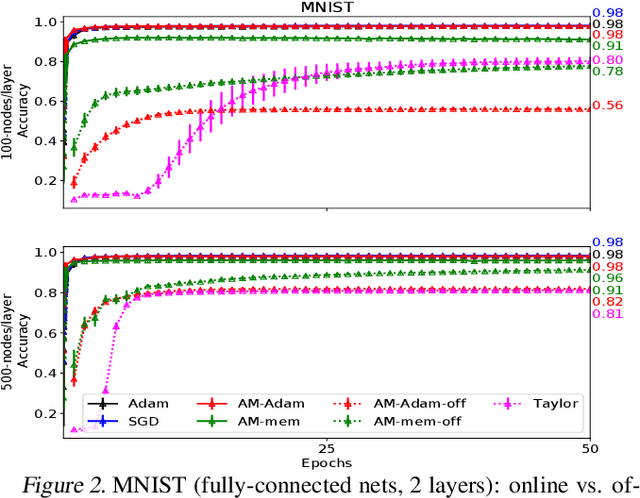
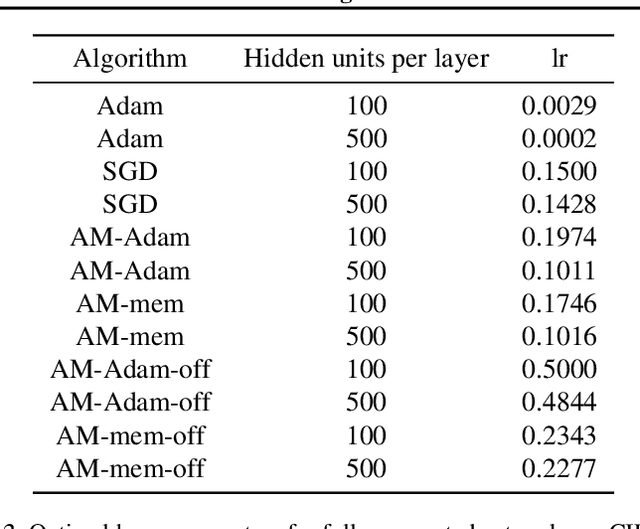
We propose a novel online alternating minimization (AltMin) algorithm for training deep neural networks, provide theoretical convergence guarantees and demonstrate its advantages on several classification tasks as compared both to standard backpropagation with stochastic gradient descent (backprop-SGD) and to offline alternating minimization. The key difference from backpropagation is an explicit optimization over hidden activations, which eliminates gradient chain computation in backprop, and breaks the weight training problem into independent, local optimization subproblems; this allows to avoid vanishing gradient issues, simplify handling non-differentiable nonlinearities, and perform parallel weight updates across the layers. Moreover, parallel local synaptic weight optimization with explicit activation propagation is a step closer to a more biologically plausible learning model than backpropagation, whose biological implausibility has been frequently criticized. Finally, the online nature of our approach allows to handle very large datasets, as well as continual, lifelong learning, which is our key contribution on top of recently proposed offline alternating minimization schemes (e.g., (Carreira-Perpinan andWang 2014), (Taylor et al. 2016)).
Interpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Sep 21, 2018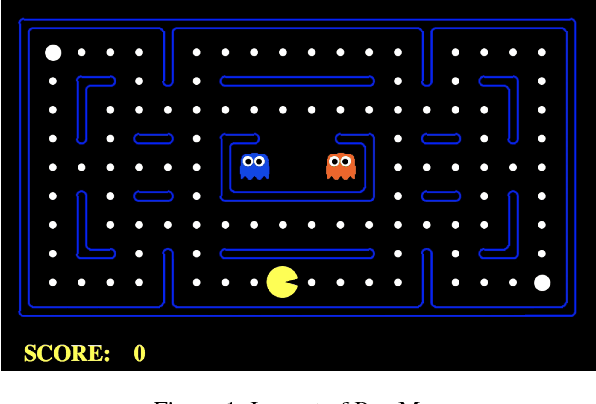
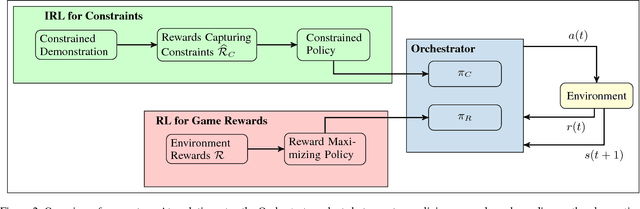
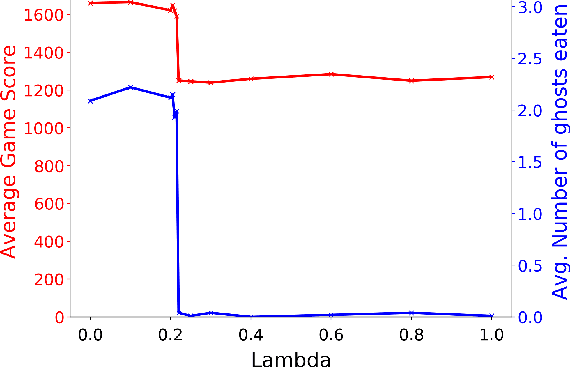
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.
Incorporating Behavioral Constraints in Online AI Systems
Sep 15, 2018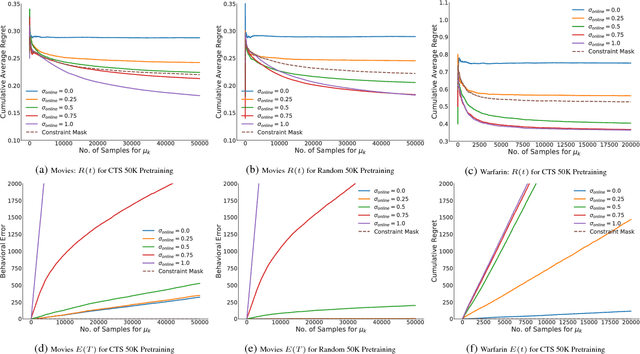
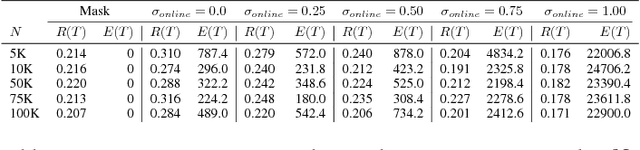
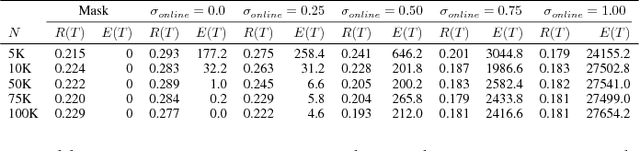
AI systems that learn through reward feedback about the actions they take are increasingly deployed in domains that have significant impact on our daily life. However, in many cases the online rewards should not be the only guiding criteria, as there are additional constraints and/or priorities imposed by regulations, values, preferences, or ethical principles. We detail a novel online agent that learns a set of behavioral constraints by observation and uses these learned constraints as a guide when making decisions in an online setting while still being reactive to reward feedback. To define this agent, we propose to adopt a novel extension to the classical contextual multi-armed bandit setting and we provide a new algorithm called Behavior Constrained Thompson Sampling (BCTS) that allows for online learning while obeying exogenous constraints. Our agent learns a constrained policy that implements the observed behavioral constraints demonstrated by a teacher agent, and then uses this constrained policy to guide the reward-based online exploration and exploitation. We characterize the upper bound on the expected regret of the contextual bandit algorithm that underlies our agent and provide a case study with real world data in two application domains. Our experiments show that the designed agent is able to act within the set of behavior constraints without significantly degrading its overall reward performance.
Adaptive Representation Selection in Contextual Bandit
May 15, 2018
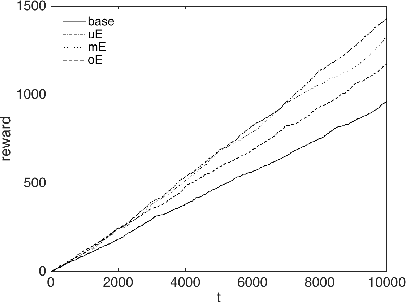
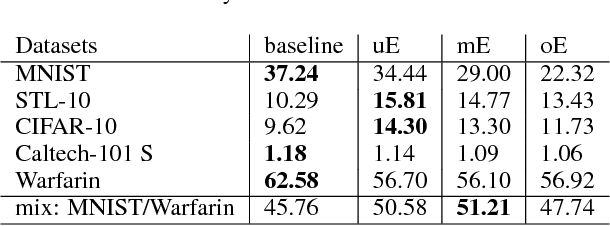
We consider an extension of the contextual bandit setting, motivated by several practical applications, where an unlabeled history of contexts can become available for pre-training before the online decision-making begins. We propose an approach for improving the performance of contextual bandit in such setting, via adaptive, dynamic representation learning, which combines offline pre-training on unlabeled history of contexts with online selection and modification of embedding functions. Our experiments on a variety of datasets and in different nonstationary environments demonstrate clear advantages of our approach over the standard contextual bandit.
Scalable Recollections for Continual Lifelong Learning
Feb 26, 2018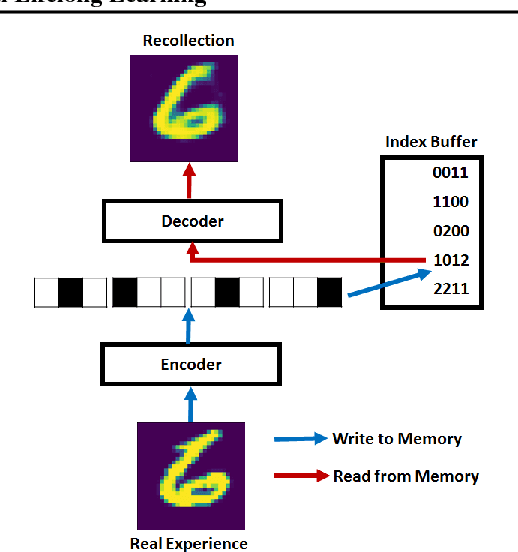

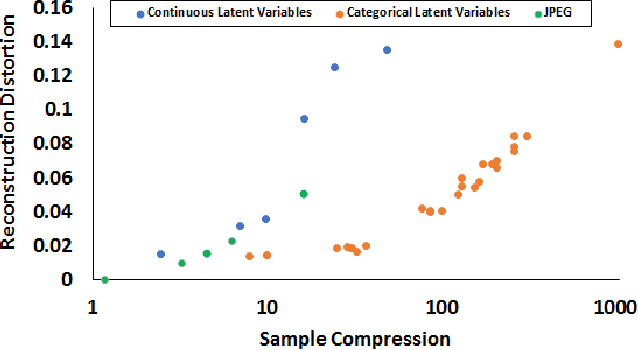
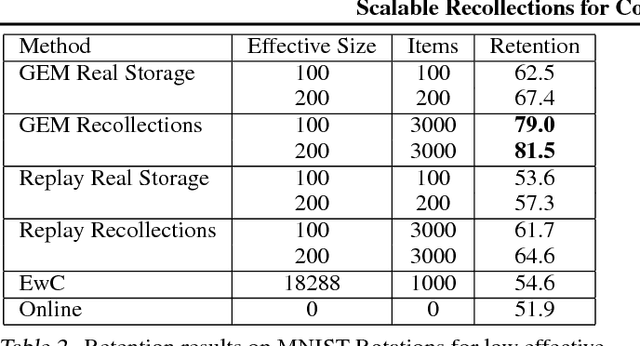
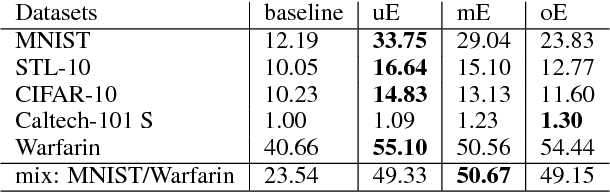
Given the recent success of Deep Learning applied to a variety of single tasks, it is natural to consider more human-realistic settings. Perhaps the most difficult of these settings is that of continual lifelong learning, where the model must learn online over a continuous stream of non-stationary data. A continual lifelong learning system must have three primary capabilities to succeed: it must learn and adapt over time, it must not forget what it has learned, and it must be efficient in both training time and memory. Recent techniques have focused their efforts largely on the first two capabilities while the third capability remains largely unexplored. In this paper, we consider the problem of efficient and effective storage of experiences over very large time-frames. In particular we consider the case where typical experiences are n bits and memories are limited to k bits for k << n. We present a novel scalable architecture and training algorithm in this challenging domain and provide an extensive evaluation of its performance. Our results show that we can achieve considerable gains on top of state-of-the-art methods such as GEM.
Context Attentive Bandits: Contextual Bandit with Restricted Context
Jun 07, 2017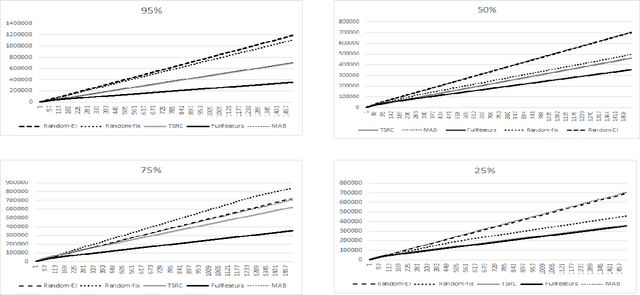

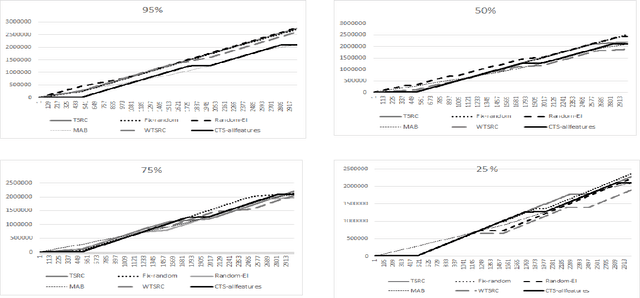
We consider a novel formulation of the multi-armed bandit model, which we call the contextual bandit with restricted context, where only a limited number of features can be accessed by the learner at every iteration. This novel formulation is motivated by different online problems arising in clinical trials, recommender systems and attention modeling. Herein, we adapt the standard multi-armed bandit algorithm known as Thompson Sampling to take advantage of our restricted context setting, and propose two novel algorithms, called the Thompson Sampling with Restricted Context(TSRC) and the Windows Thompson Sampling with Restricted Context(WTSRC), for handling stationary and nonstationary environments, respectively. Our empirical results demonstrate advantages of the proposed approaches on several real-life datasets
Bandit Models of Human Behavior: Reward Processing in Mental Disorders
Jun 07, 2017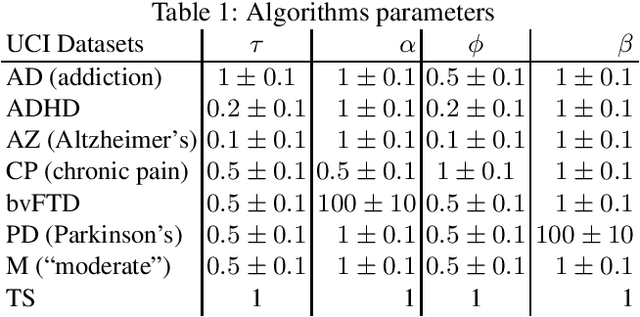
Drawing an inspiration from behavioral studies of human decision making, we propose here a general parametric framework for multi-armed bandit problem, which extends the standard Thompson Sampling approach to incorporate reward processing biases associated with several neurological and psychiatric conditions, including Parkinson's and Alzheimer's diseases, attention-deficit/hyperactivity disorder (ADHD), addiction, and chronic pain. We demonstrate empirically that the proposed parametric approach can often outperform the baseline Thompson Sampling on a variety of datasets. Moreover, from the behavioral modeling perspective, our parametric framework can be viewed as a first step towards a unifying computational model capturing reward processing abnormalities across multiple mental conditions.
Multi-armed Bandit Problem with Known Trend
May 10, 2017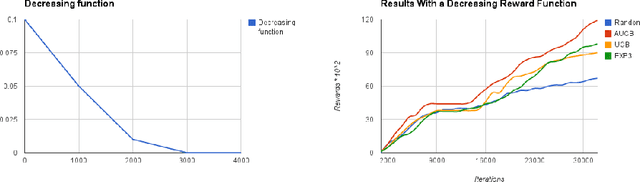
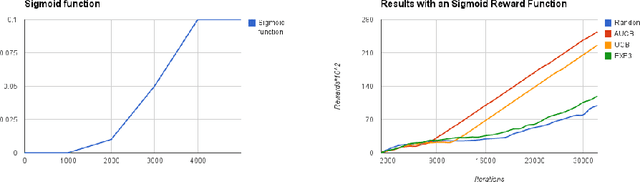
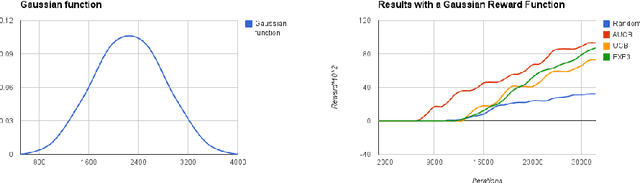
We consider a variant of the multi-armed bandit model, which we call multi-armed bandit problem with known trend, where the gambler knows the shape of the reward function of each arm but not its distribution. This new problem is motivated by different online problems like active learning, music and interface recommendation applications, where when an arm is sampled by the model the received reward change according to a known trend. By adapting the standard multi-armed bandit algorithm UCB1 to take advantage of this setting, we propose the new algorithm named A-UCB that assumes a stochastic model. We provide upper bounds of the regret which compare favourably with the ones of UCB1. We also confirm that experimentally with different simulations