 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing When to Ask: Self-Gated Clarification for Hierarchical Language Agents
Jun 09, 2026In hierarchical reasoning, failures often originate at intermediate decision points where the agent commits to a wrong branch without recognizing that it lacks critical information. Rather than treating clarification as an external uncertainty trigger, we propose ACTION-RATING, a formulation that places it inside the agent's action space on a shared ordinal scale with navigation, so that asking competes directly with acting at every decision point and help-seeking becomes observable at intermediate states. Two structurally distinct information-seeking modes emerge from the agent's own ratings: mandatory (no viable branch) and opportunistic (residual uncertainty despite a leading candidate). On Harmonized Tariff Schedule classification (30,000-node taxonomy, three benchmarks, 9~LLMs across 4 families), we observe a regime shift from mandatory to opportunistic clarification, with Information-Seeking Effectiveness (ISE), a local diagnostic defined as the fraction of help interactions followed by a correct next navigation step (not a final-task metric), rising from 50% to 74%. Three diagnostic contrasts fail to reproduce this structure. A separability test shows that the information-seeking pattern (mode split, ISE ranking) persists when answer quality is degraded (-18.8% accuracy), supporting an empirical separation between where an agent seeks help and the quality of the help it receives. Under the controlled answer channel, accuracy gains reach +16.2% at 10-digit; we read this as an upper bound on what better localization could unlock, not a deployment estimate.
From Debate to Decision: Conformal Social Choice for Safe Multi-Agent Deliberation
Apr 09, 2026Multi-agent debate improves LLM reasoning, yet agreement among agents is not evidence of correctness. When agents converge on a wrong answer through social reinforcement, consensus-based stopping commits that error to an automated action with no recourse. We introduce Conformal Social Choice, a post-hoc decision layer that converts debate outputs into calibrated act-versus-escalate decisions. Verbalized probability distributions from heterogeneous agents are aggregated via a linear opinion pool and calibrated with split conformal prediction, yielding prediction sets with a marginal coverage guarantee: the correct answer is included with probability ${\geq}\,1{-}α$, without assumptions on individual model calibration. A hierarchical action policy maps singleton sets to autonomous action and larger sets to human escalation. On eight MMLU-Pro domains with three agents (Claude Haiku, DeepSeek-R1, Qwen-3 32B), coverage stays within 1--2 points of the target. The key finding is not that debate becomes more accurate, but that the conformal layer makes its failures actionable: 81.9% of wrong-consensus cases are intercepted at $α{=}0.05$. Because the layer refuses to act on cases where debate is confidently wrong, the remaining conformal singletons reach 90.0--96.8% accuracy (up to 22.1pp above consensus stopping) -- a selection effect, not a reasoning improvement. This safety comes at the cost of automation, but the operating point is user-adjustable via $α$.
Automated Clinical Data Extraction with Knowledge Conditioned LLMs
Jun 26, 2024



The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
Hateful Memes Challenge: An Enhanced Multimodal Framework
Dec 20, 2021

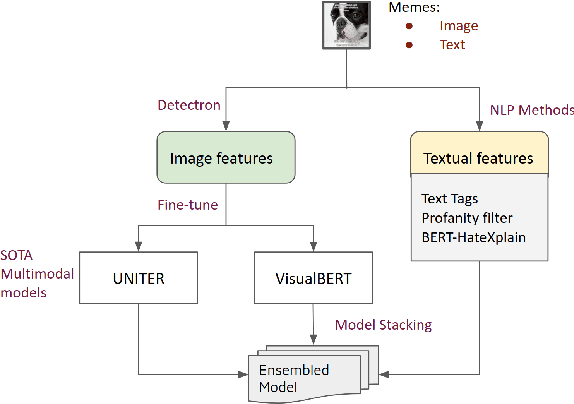
Hateful Meme Challenge proposed by Facebook AI has attracted contestants around the world. The challenge focuses on detecting hateful speech in multimodal memes. Various state-of-the-art deep learning models have been applied to this problem and the performance on challenge's leaderboard has also been constantly improved. In this paper, we enhance the hateful detection framework, including utilizing Detectron for feature extraction, exploring different setups of VisualBERT and UNITER models with different loss functions, researching the association between the hateful memes and the sensitive text features, and finally building ensemble method to boost model performance. The AUROC of our fine-tuned VisualBERT, UNITER, and ensemble method achieves 0.765, 0.790, and 0.803 on the challenge's test set, respectively, which beats the baseline models. Our code is available at https://github.com/yatingtian/hateful-meme