 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Additive Instance-Wise Approach to Multi-class Model Interpretation
Jul 07, 2022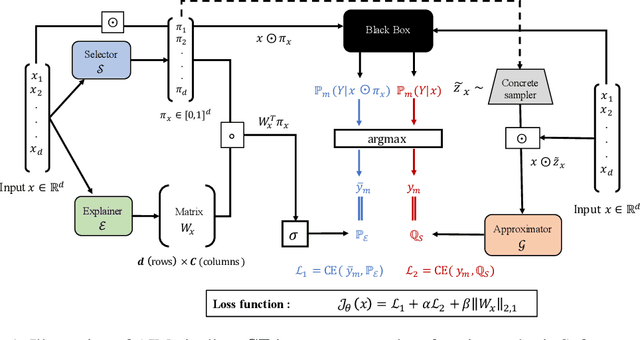
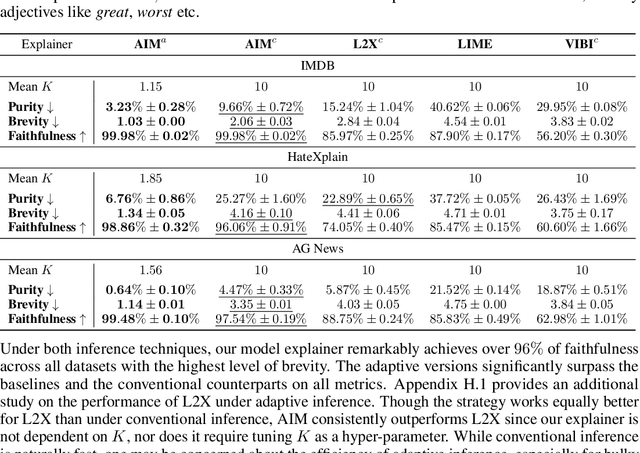
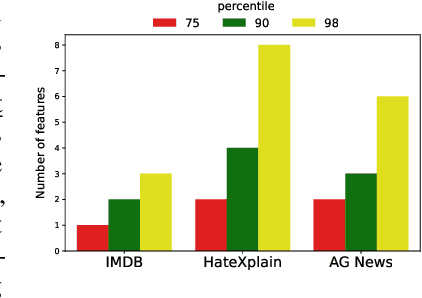

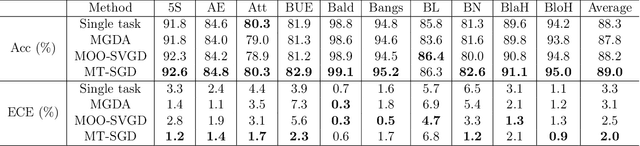
Interpretable machine learning offers insights into what factors drive a certain prediction of a black-box system and whether to trust it for high-stakes decisions or large-scale deployment. Existing methods mainly focus on selecting explanatory input features, which follow either locally additive or instance-wise approaches. Additive models use heuristically sampled perturbations to learn instance-specific explainers sequentially. The process is thus inefficient and susceptible to poorly-conditioned samples. Meanwhile, instance-wise techniques directly learn local sampling distributions and can leverage global information from other inputs. However, they can only interpret single-class predictions and suffer from inconsistency across different settings, due to a strict reliance on a pre-defined number of features selected. This work exploits the strengths of both methods and proposes a global framework for learning local explanations simultaneously for multiple target classes. We also propose an adaptive inference strategy to determine the optimal number of features for a specific instance. Our model explainer significantly outperforms additive and instance-wise counterparts on faithfulness while achieves high level of brevity on various data sets and black-box model architectures.
Stochastic Multiple Target Sampling Gradient Descent
Jun 04, 2022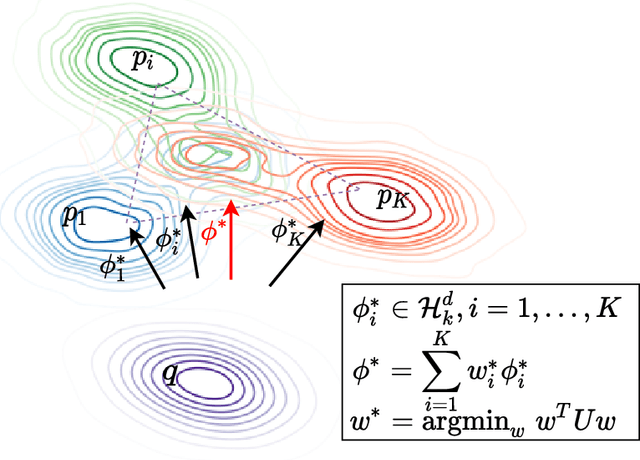

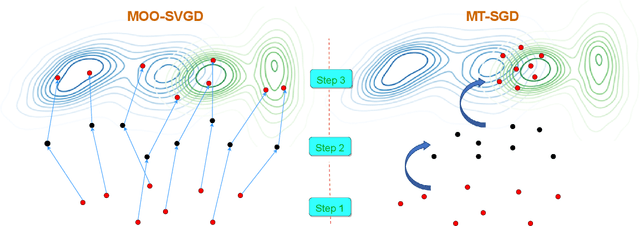
Sampling from an unnormalized target distribution is an essential problem with many applications in probabilistic inference. Stein Variational Gradient Descent (SVGD) has been shown to be a powerful method that iteratively updates a set of particles to approximate the distribution of interest. Furthermore, when analysing its asymptotic properties, SVGD reduces exactly to a single-objective optimization problem and can be viewed as a probabilistic version of this single-objective optimization problem. A natural question then arises: "Can we derive a probabilistic version of the multi-objective optimization?". To answer this question, we propose Stochastic Multiple Target Sampling Gradient Descent (MT-SGD), enabling us to sample from multiple unnormalized target distributions. Specifically, our MT-SGD conducts a flow of intermediate distributions gradually orienting to multiple target distributions, which allows the sampled particles to move to the joint high-likelihood region of the target distributions. Interestingly, the asymptotic analysis shows that our approach reduces exactly to the multiple-gradient descent algorithm for multi-objective optimization, as expected. Finally, we conduct comprehensive experiments to demonstrate the merit of our approach to multi-task learning.
High-Quality Pluralistic Image Completion via Code Shared VQGAN
Apr 05, 2022
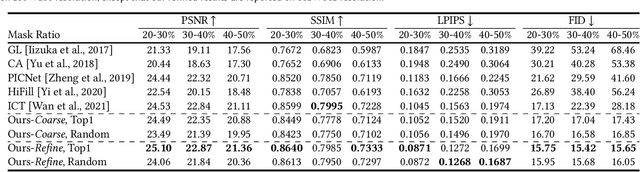


PICNet pioneered the generation of multiple and diverse results for image completion task, but it required a careful balance between $\mathcal{KL}$ loss (diversity) and reconstruction loss (quality), resulting in a limited diversity and quality . Separately, iGPT-based architecture has been employed to infer distributions in a discrete space derived from a pixel-level pre-clustered palette, which however cannot generate high-quality results directly. In this work, we present a novel framework for pluralistic image completion that can achieve both high quality and diversity at much faster inference speed. The core of our design lies in a simple yet effective code sharing mechanism that leads to a very compact yet expressive image representation in a discrete latent domain. The compactness and the richness of the representation further facilitate the subsequent deployment of a transformer to effectively learn how to composite and complete a masked image at the discrete code domain. Based on the global context well-captured by the transformer and the available visual regions, we are able to sample all tokens simultaneously, which is completely different from the prevailing autoregressive approach of iGPT-based works, and leads to more than 100$\times$ faster inference speed. Experiments show that our framework is able to learn semantically-rich discrete codes efficiently and robustly, resulting in much better image reconstruction quality. Our diverse image completion framework significantly outperforms the state-of-the-art both quantitatively and qualitatively on multiple benchmark datasets.
Global-Local Regularization Via Distributional Robustness
Mar 01, 2022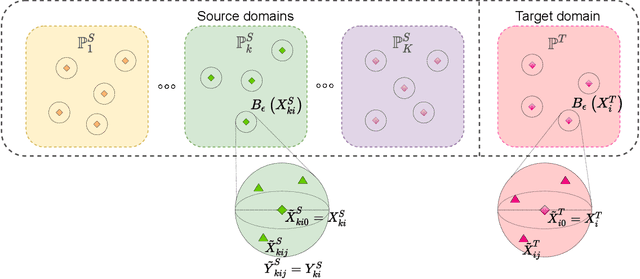
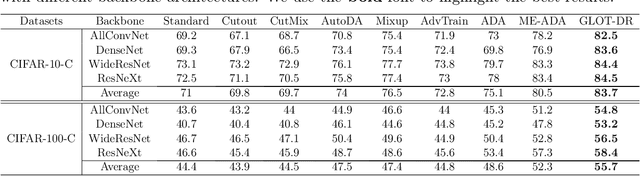

Despite superior performance in many situations, deep neural networks are often vulnerable to adversarial examples and distribution shifts, limiting model generalization ability in real-world applications. To alleviate these problems, recent approaches leverage distributional robustness optimization (DRO) to find the most challenging distribution, and then minimize loss function over this most challenging distribution. Regardless of achieving some improvements, these DRO approaches have some obvious limitations. First, they purely focus on local regularization to strengthen model robustness, missing a global regularization effect which is useful in many real-world applications (e.g., domain adaptation, domain generalization, and adversarial machine learning). Second, the loss functions in the existing DRO approaches operate in only the most challenging distribution, hence decouple with the original distribution, leading to a restrictive modeling capability. In this paper, we propose a novel regularization technique, following the veins of Wasserstein-based DRO framework. Specifically, we define a particular joint distribution and Wasserstein-based uncertainty, allowing us to couple the original and most challenging distributions for enhancing modeling capability and applying both local and global regularizations. Empirical studies on different learning problems demonstrate that our proposed approach significantly outperforms the existing regularization approaches in various domains: semi-supervised learning, domain adaptation, domain generalization, and adversarial machine learning.
A Unified Wasserstein Distributional Robustness Framework for Adversarial Training
Feb 27, 2022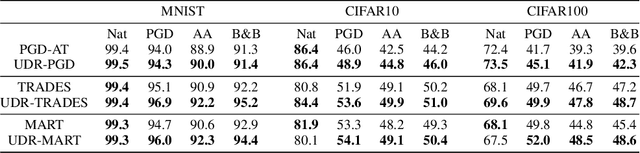
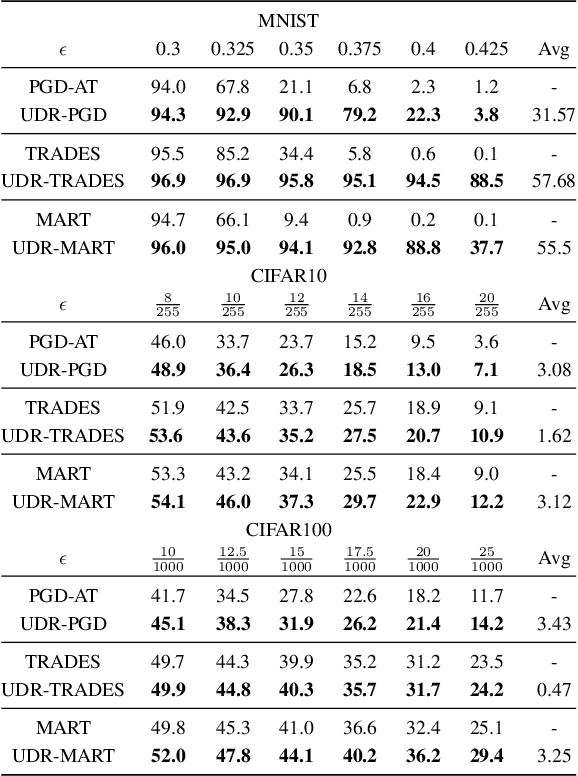
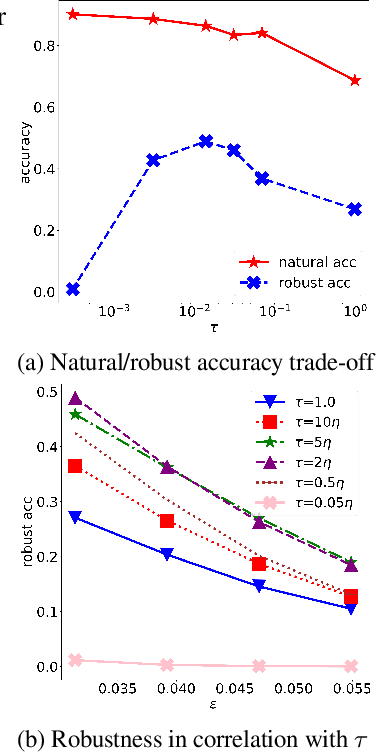
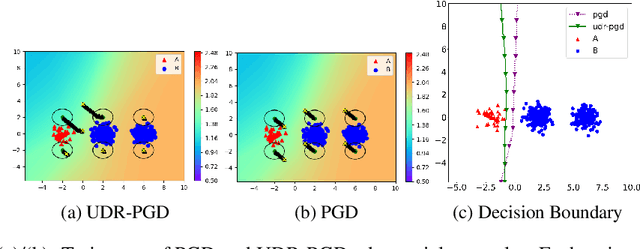
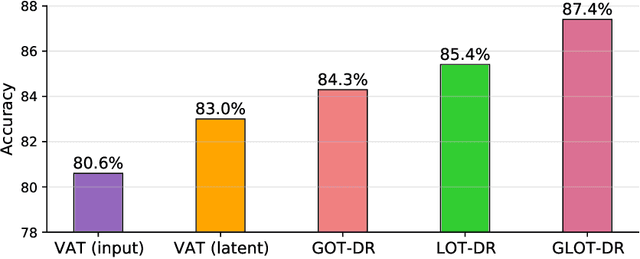
It is well-known that deep neural networks (DNNs) are susceptible to adversarial attacks, exposing a severe fragility of deep learning systems. As the result, adversarial training (AT) method, by incorporating adversarial examples during training, represents a natural and effective approach to strengthen the robustness of a DNN-based classifier. However, most AT-based methods, notably PGD-AT and TRADES, typically seek a pointwise adversary that generates the worst-case adversarial example by independently perturbing each data sample, as a way to "probe" the vulnerability of the classifier. Arguably, there are unexplored benefits in considering such adversarial effects from an entire distribution. To this end, this paper presents a unified framework that connects Wasserstein distributional robustness with current state-of-the-art AT methods. We introduce a new Wasserstein cost function and a new series of risk functions, with which we show that standard AT methods are special cases of their counterparts in our framework. This connection leads to an intuitive relaxation and generalization of existing AT methods and facilitates the development of a new family of distributional robustness AT-based algorithms. Extensive experiments show that our distributional robustness AT algorithms robustify further their standard AT counterparts in various settings.
Sobolev Transport: A Scalable Metric for Probability Measures with Graph Metrics
Feb 22, 2022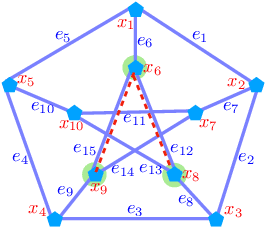
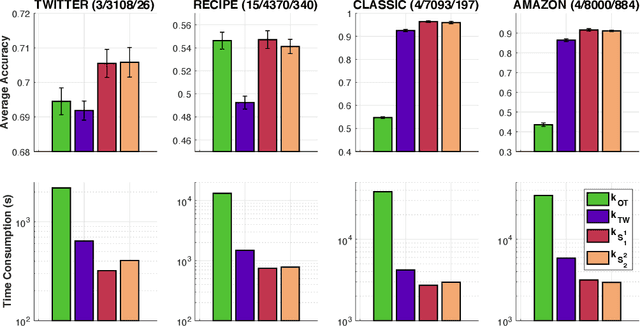
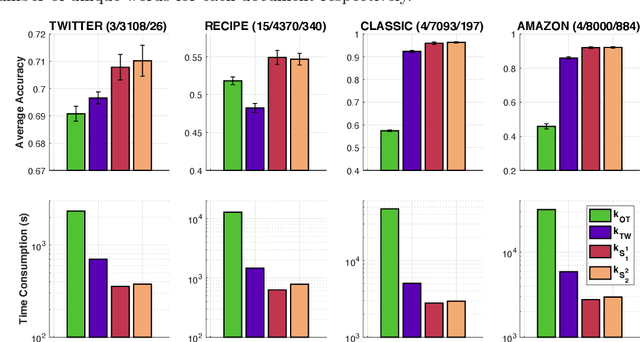
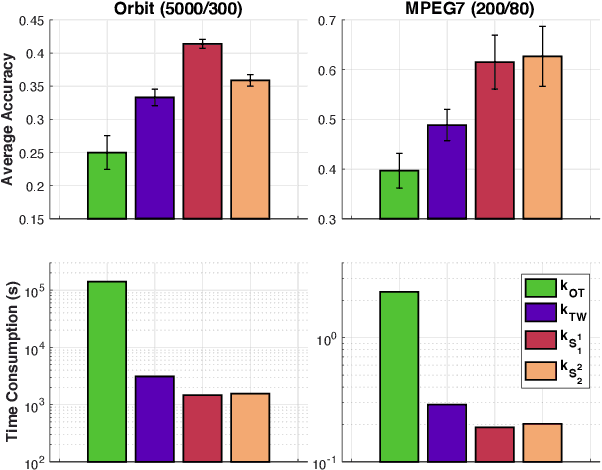
Optimal transport (OT) is a popular measure to compare probability distributions. However, OT suffers a few drawbacks such as (i) a high complexity for computation, (ii) indefiniteness which limits its applicability to kernel machines. In this work, we consider probability measures supported on a graph metric space and propose a novel Sobolev transport metric. We show that the Sobolev transport metric yields a closed-form formula for fast computation and it is negative definite. We show that the space of probability measures endowed with this transport distance is isometric to a bounded convex set in a Euclidean space with a weighted $\ell_p$ distance. We further exploit the negative definiteness of the Sobolev transport to design positive-definite kernels, and evaluate their performances against other baselines in document classification with word embeddings and in topological data analysis.
Two-view Graph Neural Networks for Knowledge Graph Completion
Dec 16, 2021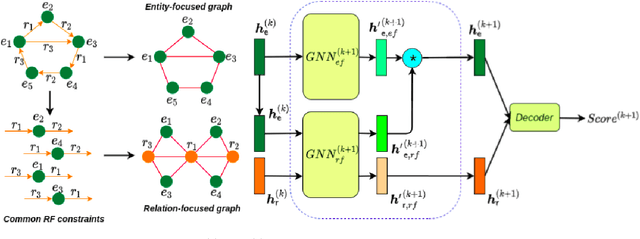
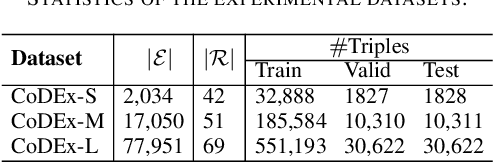
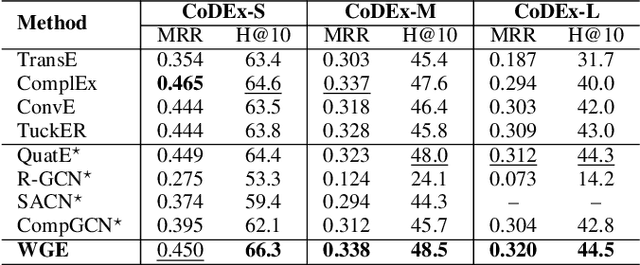
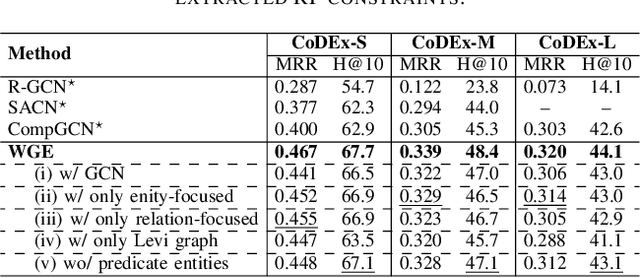
In this paper, we introduce a novel GNN-based knowledge graph embedding model, named WGE, to capture entity-focused graph structure and relation-focused graph structure. In particular, given the knowledge graph, WGE builds a single undirected entity-focused graph that views entities as nodes. In addition, WGE also constructs another single undirected graph from relation-focused constraints, which views entities and relations as nodes. WGE then proposes a new architecture of utilizing two vanilla GNNs directly on these two single graphs to better update vector representations of entities and relations, followed by a weighted score function to return the triple scores. Experimental results show that WGE obtains state-of-the-art performances on three new and challenging benchmark datasets CoDEx for knowledge graph completion.
On Learning Domain-Invariant Representations for Transfer Learning with Multiple Sources
Nov 27, 2021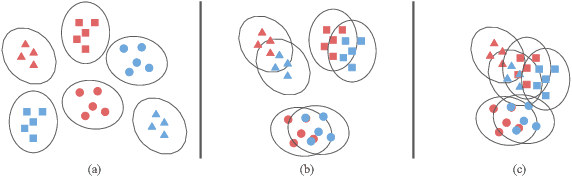
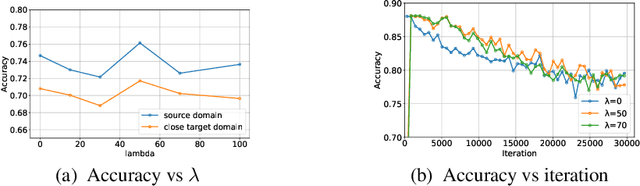
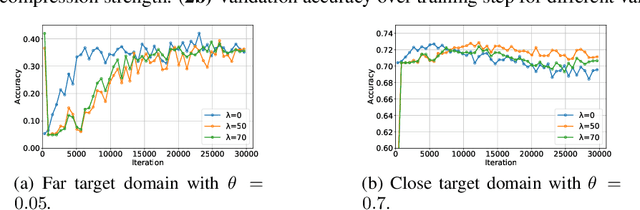
Domain adaptation (DA) benefits from the rigorous theoretical works that study its insightful characteristics and various aspects, e.g., learning domain-invariant representations and its trade-off. However, it seems not the case for the multiple source DA and domain generalization (DG) settings which are remarkably more complicated and sophisticated due to the involvement of multiple source domains and potential unavailability of target domain during training. In this paper, we develop novel upper-bounds for the target general loss which appeal to us to define two kinds of domain-invariant representations. We further study the pros and cons as well as the trade-offs of enforcing learning each domain-invariant representation. Finally, we conduct experiments to inspect the trade-off of these representations for offering practical hints regarding how to use them in practice and explore other interesting properties of our developed theory.
Model Fusion of Heterogeneous Neural Networks via Cross-Layer Alignment
Oct 29, 2021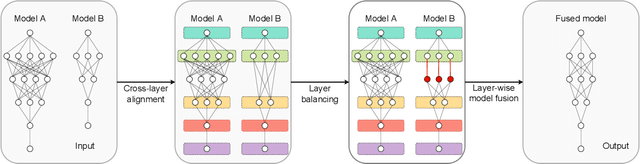

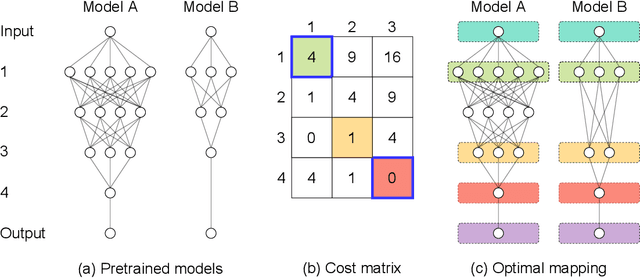

Layer-wise model fusion via optimal transport, named OTFusion, applies soft neuron association for unifying different pre-trained networks to save computational resources. While enjoying its success, OTFusion requires the input networks to have the same number of layers. To address this issue, we propose a novel model fusion framework, named CLAFusion, to fuse neural networks with a different number of layers, which we refer to as heterogeneous neural networks, via cross-layer alignment. The cross-layer alignment problem, which is an unbalanced assignment problem, can be solved efficiently using dynamic programming. Based on the cross-layer alignment, our framework balances the number of layers of neural networks before applying layer-wise model fusion. Our synthetic experiments indicate that the fused network from CLAFusion achieves a more favorable performance compared to the individual networks trained on heterogeneous data without the need for any retraining. With an extra fine-tuning process, it improves the accuracy of residual networks on the CIFAR10 dataset. Finally, we explore its application for model compression and knowledge distillation when applying to the teacher-student setting.
On Label Shift in Domain Adaptation via Wasserstein Distance
Oct 29, 2021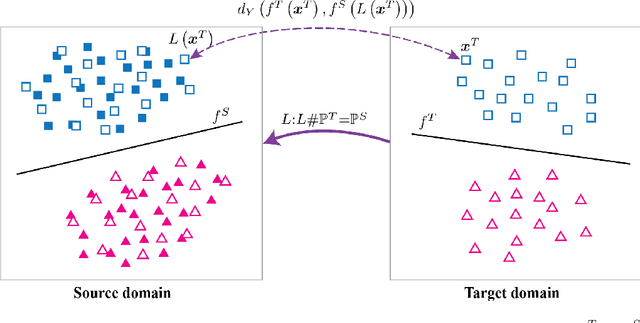
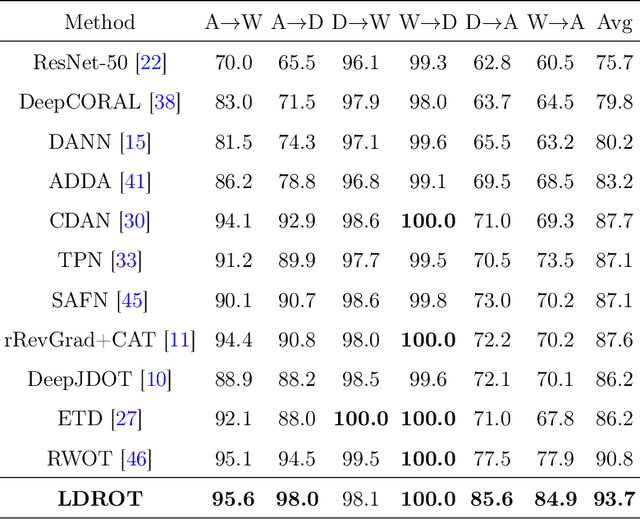
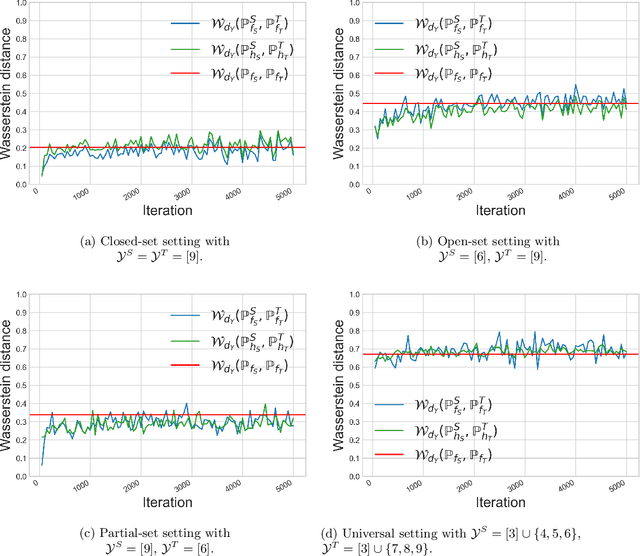
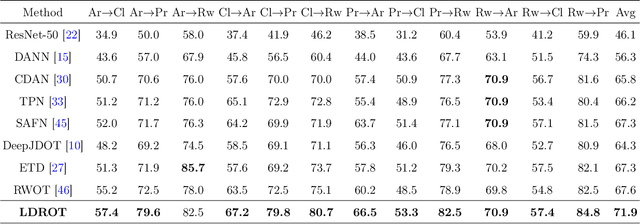
We study the label shift problem between the source and target domains in general domain adaptation (DA) settings. We consider transformations transporting the target to source domains, which enable us to align the source and target examples. Through those transformations, we define the label shift between two domains via optimal transport and develop theory to investigate the properties of DA under various DA settings (e.g., closed-set, partial-set, open-set, and universal settings). Inspired from the developed theory, we propose Label and Data Shift Reduction via Optimal Transport (LDROT) which can mitigate the data and label shifts simultaneously. Finally, we conduct comprehensive experiments to verify our theoretical findings and compare LDROT with state-of-the-art baselines.