 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concept is More Than a Word: Diversified Unlearning in Text-to-Image Diffusion Models
Mar 19, 2026Concept unlearning has emerged as a promising direction for reducing the risks of harmful content generation in text-to-image diffusion models by selectively erasing undesirable concepts from a model's parameters. Existing approaches typically rely on keywords to identify the target concept to be unlearned. However, we show that this keyword-based formulation is inherently limited: a visual concept is multi-dimensional, can be expressed in diverse textual forms, and often overlap with related concepts in the latent space, making keyword-only unlearning, which imprecisely indicate the target concept is brittle and prone to over-forgetting. This occurs because a single keyword represents only a narrow point estimate of the concept, failing to cover its full semantic distribution and entangled variations in the latent space. To address this limitation, we propose Diversified Unlearning, a distributional framework that represents a concept through a set of contextually diverse prompts rather than a single keyword. This richer representation enables more precise and robust unlearning. Through extensive experiments across multiple benchmarks and state-of-the-art baselines, we demonstrate that integrating Diversified Unlearning as an add-on component into existing unlearning pipelines consistently achieves stronger erasure, better retention of unrelated concepts, and improved robustness against adversarial recovery attacks.
Global-Local Regularization Via Distributional Robustness
Mar 01, 2022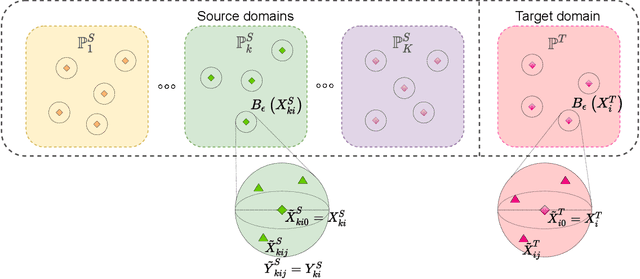
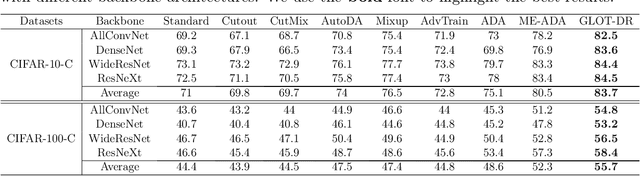

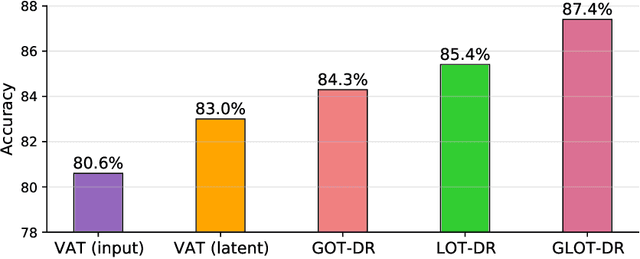
Despite superior performance in many situations, deep neural networks are often vulnerable to adversarial examples and distribution shifts, limiting model generalization ability in real-world applications. To alleviate these problems, recent approaches leverage distributional robustness optimization (DRO) to find the most challenging distribution, and then minimize loss function over this most challenging distribution. Regardless of achieving some improvements, these DRO approaches have some obvious limitations. First, they purely focus on local regularization to strengthen model robustness, missing a global regularization effect which is useful in many real-world applications (e.g., domain adaptation, domain generalization, and adversarial machine learning). Second, the loss functions in the existing DRO approaches operate in only the most challenging distribution, hence decouple with the original distribution, leading to a restrictive modeling capability. In this paper, we propose a novel regularization technique, following the veins of Wasserstein-based DRO framework. Specifically, we define a particular joint distribution and Wasserstein-based uncertainty, allowing us to couple the original and most challenging distributions for enhancing modeling capability and applying both local and global regularizations. Empirical studies on different learning problems demonstrate that our proposed approach significantly outperforms the existing regularization approaches in various domains: semi-supervised learning, domain adaptation, domain generalization, and adversarial machine learning.
A Unified Wasserstein Distributional Robustness Framework for Adversarial Training
Feb 27, 2022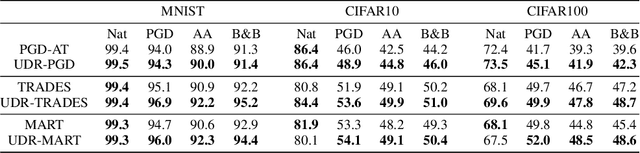
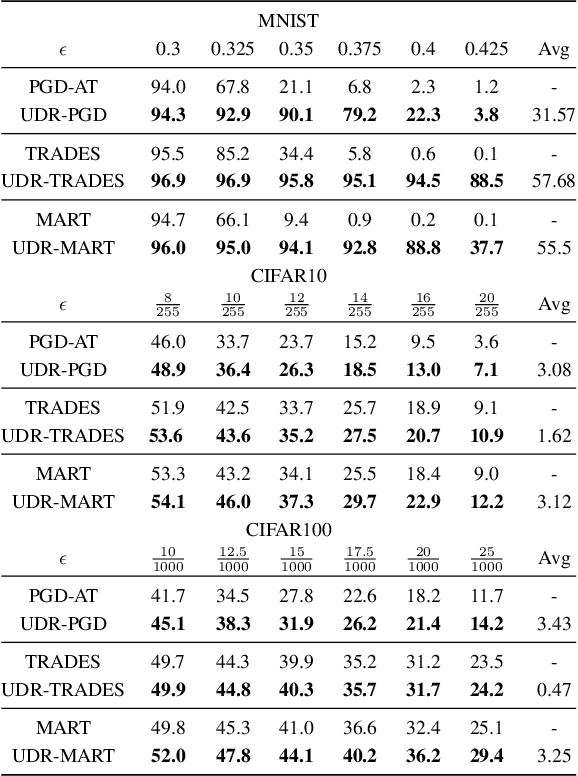
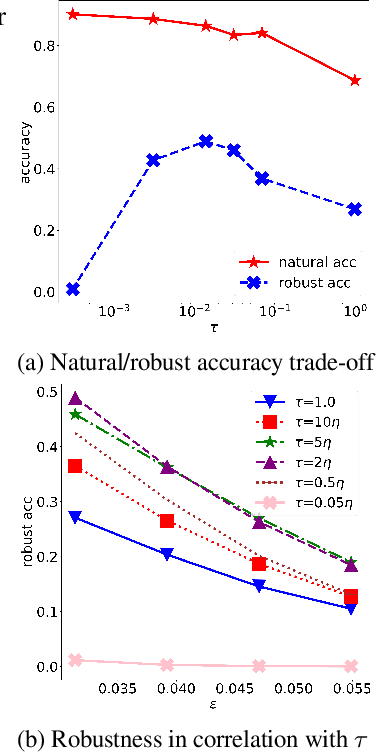
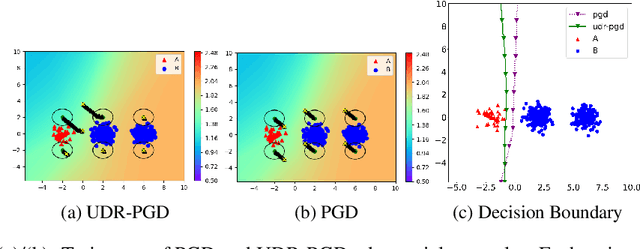
It is well-known that deep neural networks (DNNs) are susceptible to adversarial attacks, exposing a severe fragility of deep learning systems. As the result, adversarial training (AT) method, by incorporating adversarial examples during training, represents a natural and effective approach to strengthen the robustness of a DNN-based classifier. However, most AT-based methods, notably PGD-AT and TRADES, typically seek a pointwise adversary that generates the worst-case adversarial example by independently perturbing each data sample, as a way to "probe" the vulnerability of the classifier. Arguably, there are unexplored benefits in considering such adversarial effects from an entire distribution. To this end, this paper presents a unified framework that connects Wasserstein distributional robustness with current state-of-the-art AT methods. We introduce a new Wasserstein cost function and a new series of risk functions, with which we show that standard AT methods are special cases of their counterparts in our framework. This connection leads to an intuitive relaxation and generalization of existing AT methods and facilitates the development of a new family of distributional robustness AT-based algorithms. Extensive experiments show that our distributional robustness AT algorithms robustify further their standard AT counterparts in various settings.