 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-MIL: Boosting Multi-Instance Learning Schemes via Task-specific Prompt Tuning
Mar 21, 2023Whole slide image (WSI) classification is a critical task in computational pathology, requiring the processing of gigapixel-sized images, which is challenging for current deep-learning methods. Current state of the art methods are based on multi-instance learning schemes (MIL), which usually rely on pretrained features to represent the instances. Due to the lack of task-specific annotated data, these features are either obtained from well-established backbones on natural images, or, more recently from self-supervised models pretrained on histopathology. However, both approaches yield task-agnostic features, resulting in performance loss compared to the appropriate task-related supervision, if available. In this paper, we show that when task-specific annotations are limited, we can inject such supervision into downstream task training, to reduce the gap between fully task-tuned and task agnostic features. We propose Prompt-MIL, an MIL framework that integrates prompts into WSI classification. Prompt-MIL adopts a prompt tuning mechanism, where only a small fraction of parameters calibrates the pretrained features to encode task-specific information, rather than the conventional full fine-tuning approaches. Extensive experiments on three WSI datasets, TCGA-BRCA, TCGA-CRC, and BRIGHT, demonstrate the superiority of Prompt-MIL over conventional MIL methods, achieving a relative improvement of 1.49%-4.03% in accuracy and 0.25%-8.97% in AUROC while using fewer than 0.3% additional parameters. Compared to conventional full fine-tuning approaches, we fine-tune less than 1.3% of the parameters, yet achieve a relative improvement of 1.29%-13.61% in accuracy and 3.22%-27.18% in AUROC and reduce GPU memory consumption by 38%-45% while training 21%-27% faster.
Token Sparsification for Faster Medical Image Segmentation
Mar 11, 2023



Can we use sparse tokens for dense prediction, e.g., segmentation? Although token sparsification has been applied to Vision Transformers (ViT) to accelerate classification, it is still unknown how to perform segmentation from sparse tokens. To this end, we reformulate segmentation as a sparse encoding -> token completion -> dense decoding (SCD) pipeline. We first empirically show that naively applying existing approaches from classification token pruning and masked image modeling (MIM) leads to failure and inefficient training caused by inappropriate sampling algorithms and the low quality of the restored dense features. In this paper, we propose Soft-topK Token Pruning (STP) and Multi-layer Token Assembly (MTA) to address these problems. In sparse encoding, STP predicts token importance scores with a lightweight sub-network and samples the topK tokens. The intractable topK gradients are approximated through a continuous perturbed score distribution. In token completion, MTA restores a full token sequence by assembling both sparse output tokens and pruned multi-layer intermediate ones. The last dense decoding stage is compatible with existing segmentation decoders, e.g., UNETR. Experiments show SCD pipelines equipped with STP and MTA are much faster than baselines without token pruning in both training (up to 120% higher throughput and inference up to 60.6% higher throughput) while maintaining segmentation quality.
Zero-shot Object Counting
Mar 03, 2023


Class-agnostic object counting aims to count object instances of an arbitrary class at test time. It is challenging but also enables many potential applications. Current methods require human-annotated exemplars as inputs which are often unavailable for novel categories, especially for autonomous systems. Thus, we propose zero-shot object counting (ZSC), a new setting where only the class name is available during test time. Such a counting system does not require human annotators in the loop and can operate automatically. Starting from a class name, we propose a method that can accurately identify the optimal patches which can then be used as counting exemplars. Specifically, we first construct a class prototype to select the patches that are likely to contain the objects of interest, namely class-relevant patches. Furthermore, we introduce a model that can quantitatively measure how suitable an arbitrary patch is as a counting exemplar. By applying this model to all the candidate patches, we can select the most suitable patches as exemplars for counting. Experimental results on a recent class-agnostic counting dataset, FSC-147, validate the effectiveness of our method. Code is available at https://github.com/cvlab-stonybrook/zero-shot-counting
Local Learning on Transformers via Feature Reconstruction
Dec 29, 2022Transformers are becoming increasingly popular due to their superior performance over conventional convolutional neural networks(CNNs). However, transformers usually require a much larger amount of memory to train than CNNs, which prevents their application in many low resource settings. Local learning, which divides the network into several distinct modules and trains them individually, is a promising alternative to the end-to-end (E2E) training approach to reduce the amount of memory for training and to increase parallelism. This paper is the first to apply Local Learning on transformers for this purpose. The standard CNN-based local learning method, InfoPro [32], reconstructs the input images for each module in a CNN. However, reconstructing the entire image does not generalize well. In this paper, we propose a new mechanism for each local module, where instead of reconstructing the entire image, we reconstruct its input features, generated from previous modules. We evaluate our approach on 4 commonly used datasets and 3 commonly used decoder structures on Swin-Tiny. The experiments show that our approach outperforms InfoPro-Transformer, the InfoPro with Transfomer backbone we introduced, by at up to 0.58% on CIFAR-10, CIFAR-100, STL-10 and SVHN datasets, while using up to 12% less memory. Compared to the E2E approach, we require 36% less GPU memory when the network is divided into 2 modules and 45% less GPU memory when the network is divided into 4 modules.
Precise Location Matching Improves Dense Contrastive Learning in Digital Pathology
Dec 23, 2022Dense prediction tasks such as segmentation and detection of pathological entities hold crucial clinical value in the digital pathology workflow. However, obtaining dense annotations on large cohorts is usually tedious and expensive. Contrastive learning (CL) is thus often employed to leverage large volumes of unlabeled data to pre-train the backbone network. To boost CL for dense prediction, some studies have proposed variations of dense matching objectives in pre-training. However, our analysis shows that employing existing dense matching strategies on histopathology images enforces invariance among incorrect pairs of dense features and, thus, is imprecise. To address this, we propose a precise location-based matching mechanism that utilizes the overlapping information between geometric transformations to precisely match regions in two augmentations. Extensive experiments on two pretraining datasets (TCGA-BRCA, NCT-CRC-HE) and three downstream datasets (GlaS, CRAG, BCSS) highlight the superiority of our method in semantic and instance segmentation tasks. Our method outperforms previous dense matching methods by up to 7.2 % in average precision for detection and 5.6 % in average precision for instance segmentation tasks. Additionally, by using our matching mechanism in the three popular contrastive learning frameworks, MoCo-v2, VICRegL and ConCL, the average precision in detection is improved by 0.7 % to 5.2 % and the average precision in segmentation is improved by 0.7 % to 4.0 %, demonstrating its generalizability.
Patch-level Gaze Distribution Prediction for Gaze Following
Nov 20, 2022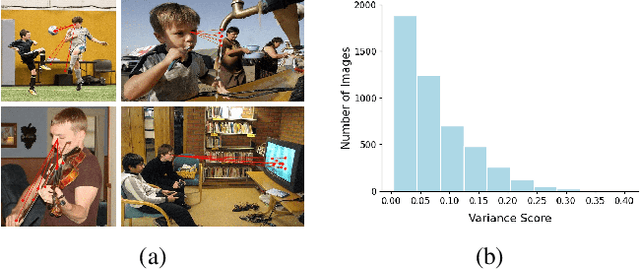
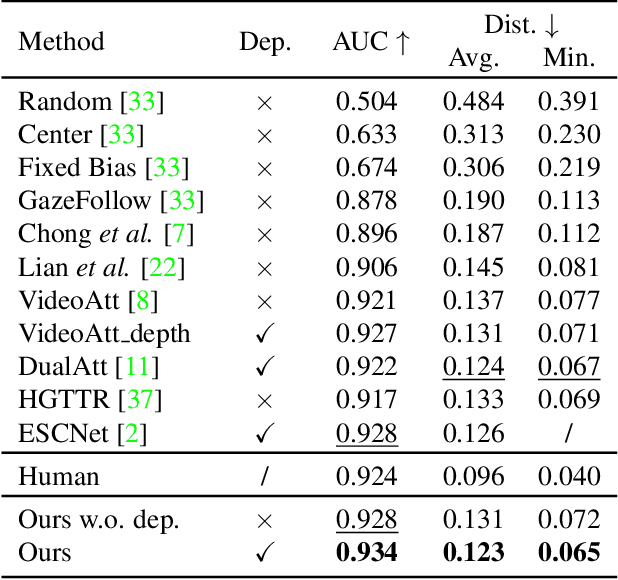
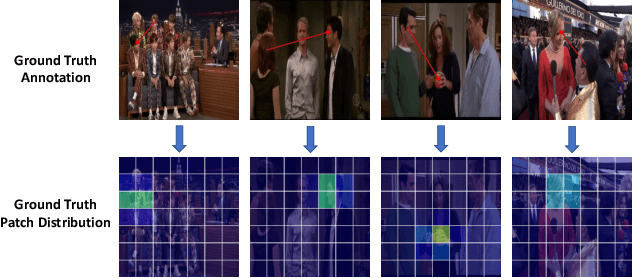
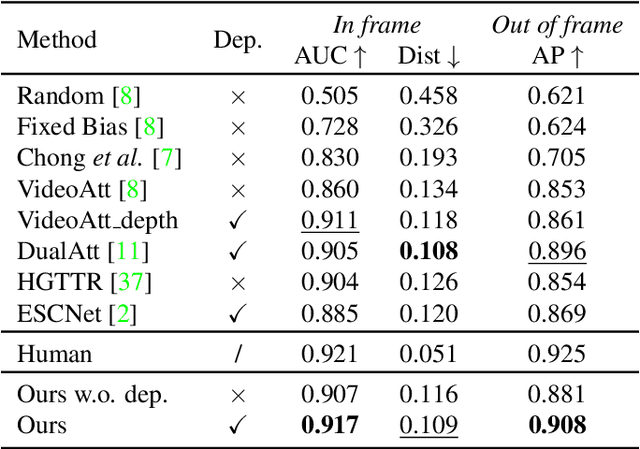
Gaze following aims to predict where a person is looking in a scene, by predicting the target location, or indicating that the target is located outside the image. Recent works detect the gaze target by training a heatmap regression task with a pixel-wise mean-square error (MSE) loss, while formulating the in/out prediction task as a binary classification task. This training formulation puts a strict, pixel-level constraint in higher resolution on the single annotation available in training, and does not consider annotation variance and the correlation between the two subtasks. To address these issues, we introduce the patch distribution prediction (PDP) method. We replace the in/out prediction branch in previous models with the PDP branch, by predicting a patch-level gaze distribution that also considers the outside cases. Experiments show that our model regularizes the MSE loss by predicting better heatmap distributions on images with larger annotation variances, meanwhile bridging the gap between the target prediction and in/out prediction subtasks, showing a significant improvement in performance on both subtasks on public gaze following datasets.
Taking a Respite from Representation Learning for Molecular Property Prediction
Oct 07, 2022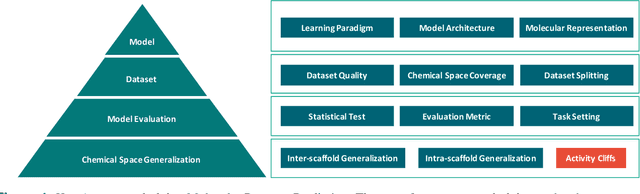
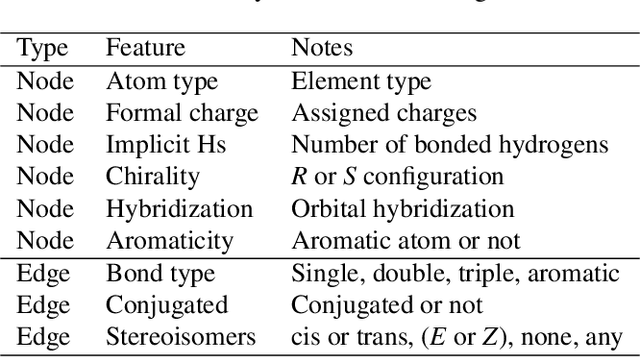
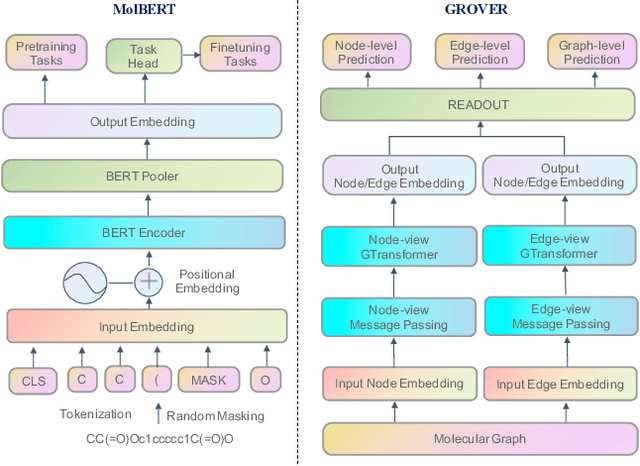
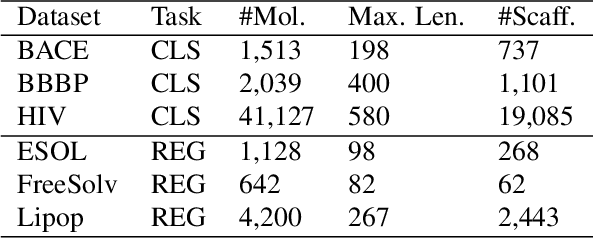
Artificial intelligence (AI) has been widely applied in drug discovery with a major task as molecular property prediction. Despite the boom of AI techniques in molecular representation learning, some key aspects underlying molecular property prediction haven't been carefully examined yet. In this study, we conducted a systematic comparison on three representative models, random forest, MolBERT and GROVER, which utilize three major molecular representations, extended-connectivity fingerprints, SMILES strings and molecular graphs, respectively. Notably, MolBERT and GROVER, are pretrained on large-scale unlabelled molecule corpuses in a self-supervised manner. In addition to the commonly used MoleculeNet benchmark datasets, we also assembled a suite of opioids-related datasets for downstream prediction evaluation. We first conducted dataset profiling on label distribution and structural analyses; we also examined the activity cliffs issue in the opioids-related datasets. Then, we trained 4,320 predictive models and evaluated the usefulness of the learned representations. Furthermore, we explored into the model evaluation by studying the effect of statistical tests, evaluation metrics and task settings. Finally, we dissected the chemical space generalization into inter-scaffold and intra-scaffold generalization and measured prediction performance to evaluate model generalizbility under both settings. By taking this respite, we reflected on the key aspects underlying molecular property prediction, the awareness of which can, hopefully, bring better AI techniques in this field.
Gigapixel Whole-Slide Images Classification using Locally Supervised Learning
Jul 17, 2022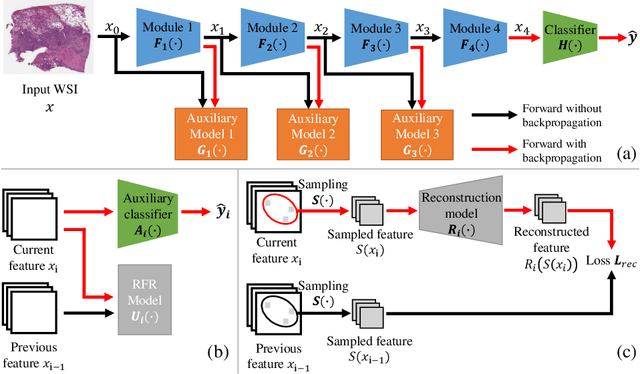
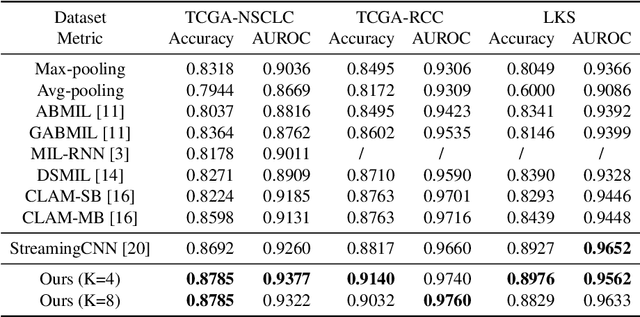


Histopathology whole slide images (WSIs) play a very important role in clinical studies and serve as the gold standard for many cancer diagnoses. However, generating automatic tools for processing WSIs is challenging due to their enormous sizes. Currently, to deal with this issue, conventional methods rely on a multiple instance learning (MIL) strategy to process a WSI at patch level. Although effective, such methods are computationally expensive, because tiling a WSI into patches takes time and does not explore the spatial relations between these tiles. To tackle these limitations, we propose a locally supervised learning framework which processes the entire slide by exploring the entire local and global information that it contains. This framework divides a pre-trained network into several modules and optimizes each module locally using an auxiliary model. We also introduce a random feature reconstruction unit (RFR) to preserve distinguishing features during training and improve the performance of our method by 1% to 3%. Extensive experiments on three publicly available WSI datasets: TCGA-NSCLC, TCGA-RCC and LKS, highlight the superiority of our method on different classification tasks. Our method outperforms the state-of-the-art MIL methods by 2% to 5% in accuracy, while being 7 to 10 times faster. Additionally, when dividing it into eight modules, our method requires as little as 20% of the total gpu memory required by end-to-end training. Our code is available at https://github.com/cvlab-stonybrook/local_learning_wsi.
Target-absent Human Attention
Jul 04, 2022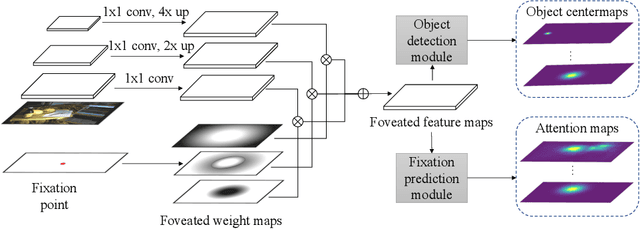
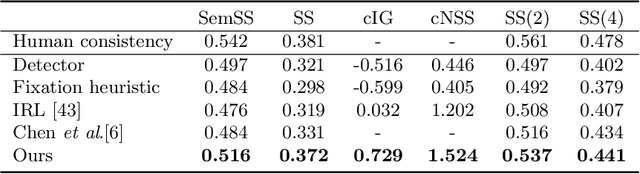


The prediction of human gaze behavior is important for building human-computer interactive systems that can anticipate a user's attention. Computer vision models have been developed to predict the fixations made by people as they search for target objects. But what about when the image has no target? Equally important is to know how people search when they cannot find a target, and when they would stop searching. In this paper, we propose the first data-driven computational model that addresses the search-termination problem and predicts the scanpath of search fixations made by people searching for targets that do not appear in images. We model visual search as an imitation learning problem and represent the internal knowledge that the viewer acquires through fixations using a novel state representation that we call Foveated Feature Maps (FFMs). FFMs integrate a simulated foveated retina into a pretrained ConvNet that produces an in-network feature pyramid, all with minimal computational overhead. Our method integrates FFMs as the state representation in inverse reinforcement learning. Experimentally, we improve the state of the art in predicting human target-absent search behavior on the COCO-Search18 dataset
Diffusion models as plug-and-play priors
Jun 17, 2022

We consider the problem of inferring high-dimensional data $\mathbf{x}$ in a model that consists of a prior $p(\mathbf{x})$ and an auxiliary constraint $c(\mathbf{x},\mathbf{y})$. In this paper, the prior is an independently trained denoising diffusion generative model. The auxiliary constraint is expected to have a differentiable form, but can come from diverse sources. The possibility of such inference turns diffusion models into plug-and-play modules, thereby allowing a range of potential applications in adapting models to new domains and tasks, such as conditional generation or image segmentation. The structure of diffusion models allows us to perform approximate inference by iterating differentiation through the fixed denoising network enriched with different amounts of noise at each step. Considering many noised versions of $\mathbf{x}$ in evaluation of its fitness is a novel search mechanism that may lead to new algorithms for solving combinatorial optimization problems.