 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExample-Driven Intent Prediction with Observers
Oct 17, 2020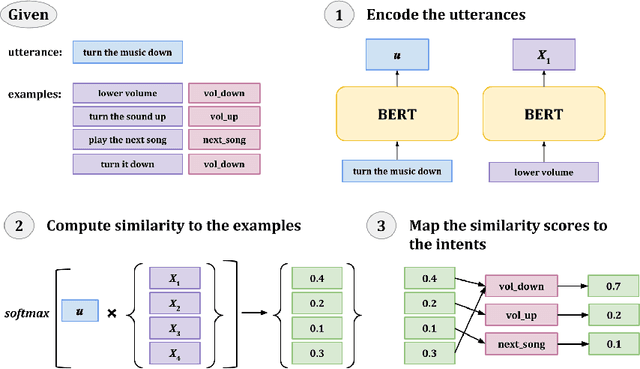
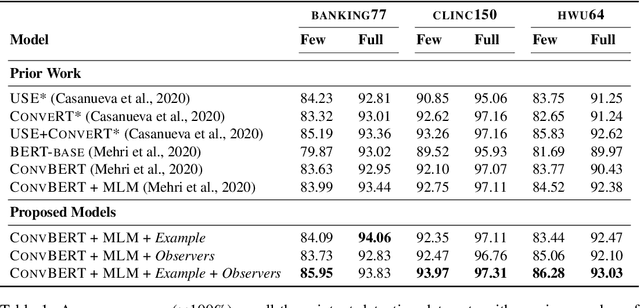
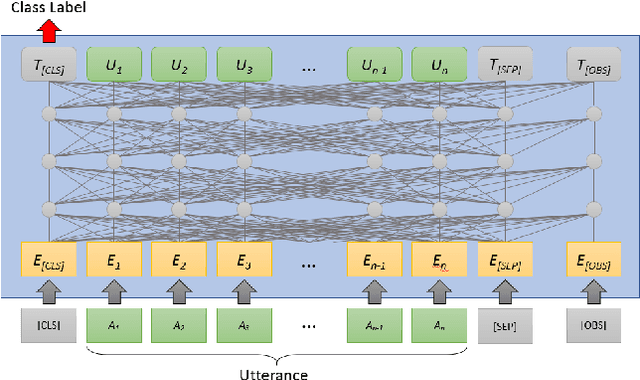

A key challenge of dialog systems research is to effectively and efficiently adapt to new domains. A scalable paradigm for adaptation necessitates the development of generalizable models that perform well in few-shot settings. In this paper, we focus on the intent classification problem which aims to identify user intents given utterances addressed to the dialog system. We propose two approaches for improving the generalizability of utterance classification models: (1) example-driven training and (2) observers. Example-driven training learns to classify utterances by comparing to examples, thereby using the underlying encoder as a sentence similarity model. Prior work has shown that BERT-like models tend to attribute a significant amount of attention to the [CLS] token, which we hypothesize results in diluted representations. Observers are tokens that are not attended to, and are an alternative to the [CLS] token. The proposed methods attain state-of-the-art results on three intent prediction datasets (Banking, Clinc}, and HWU) in both the full data and few-shot (10 examples per intent) settings. Furthermore, we demonstrate that the proposed approach can transfer to new intents and across datasets without any additional training.
DialoGLUE: A Natural Language Understanding Benchmark for Task-Oriented Dialogue
Oct 01, 2020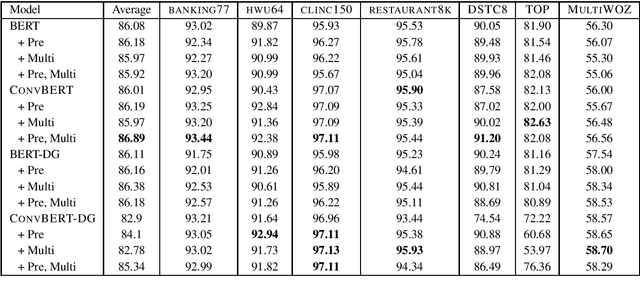
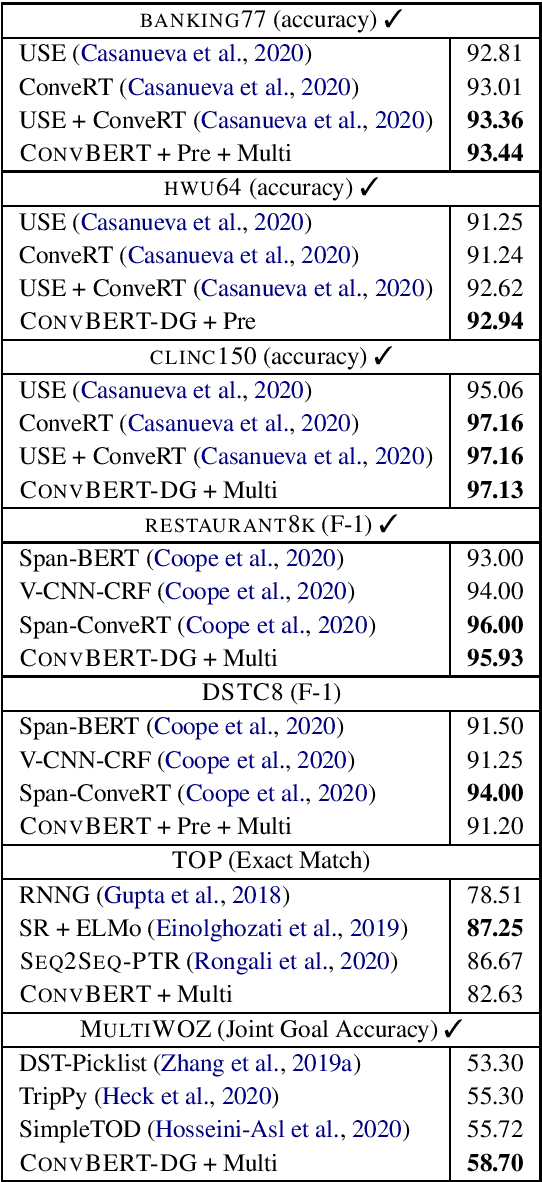
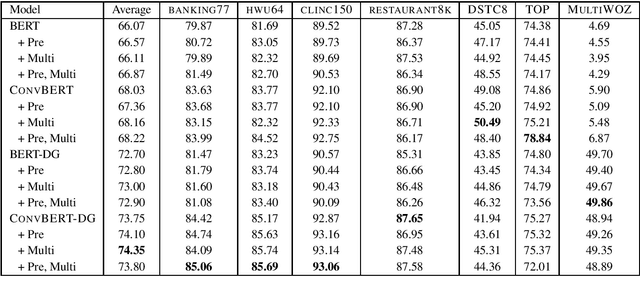
A long-standing goal of task-oriented dialogue research is the ability to flexibly adapt dialogue models to new domains. To progress research in this direction, we introduce DialoGLUE (Dialogue Language Understanding Evaluation), a public benchmark consisting of 7 task-oriented dialogue datasets covering 4 distinct natural language understanding tasks, designed to encourage dialogue research in representation-based transfer, domain adaptation, and sample-efficient task learning. We release several strong baseline models, demonstrating performance improvements over a vanilla BERT architecture and state-of-the-art results on 5 out of 7 tasks, by pre-training on a large open-domain dialogue corpus and task-adaptive self-supervised training. Through the DialoGLUE benchmark, the baseline methods, and our evaluation scripts, we hope to facilitate progress towards the goal of developing more general task-oriented dialogue models.
Learning from Mistakes: Combining Ontologies via Self-Training for Dialogue Generation
Sep 30, 2020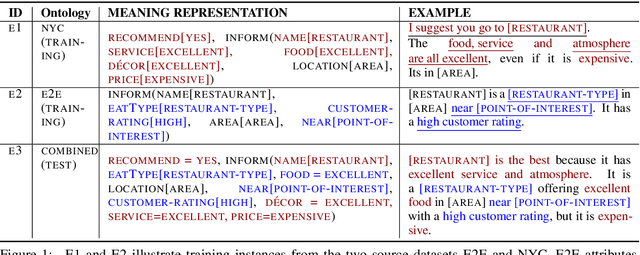
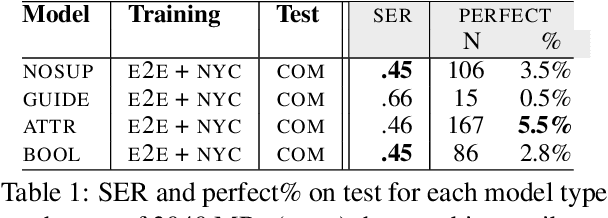
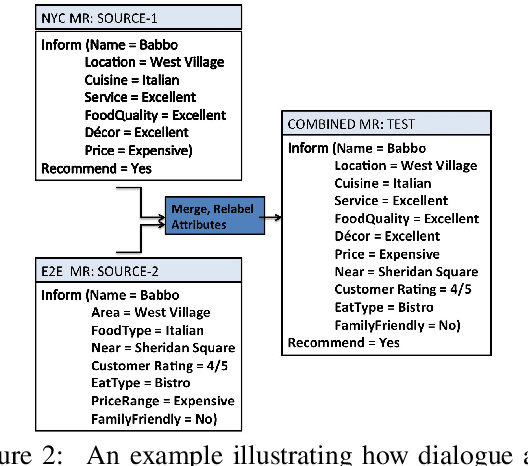
Natural language generators (NLGs) for task-oriented dialogue typically take a meaning representation (MR) as input. They are trained end-to-end with a corpus of MR/utterance pairs, where the MRs cover a specific set of dialogue acts and domain attributes. Creation of such datasets is labor-intensive and time-consuming. Therefore, dialogue systems for new domain ontologies would benefit from using data for pre-existing ontologies. Here we explore, for the first time, whether it is possible to train an NLG for a new larger ontology using existing training sets for the restaurant domain, where each set is based on a different ontology. We create a new, larger combined ontology, and then train an NLG to produce utterances covering it. For example, if one dataset has attributes for family-friendly and rating information, and the other has attributes for decor and service, our aim is an NLG for the combined ontology that can produce utterances that realize values for family-friendly, rating, decor and service. Initial experiments with a baseline neural sequence-to-sequence model show that this task is surprisingly challenging. We then develop a novel self-training method that identifies (errorful) model outputs, automatically constructs a corrected MR input to form a new (MR, utterance) training pair, and then repeatedly adds these new instances back into the training data. We then test the resulting model on a new test set. The result is a self-trained model whose performance is an absolute 75.4% improvement over the baseline model. We also report a human qualitative evaluation of the final model showing that it achieves high naturalness, semantic coherence and grammaticality
Are Neural Open-Domain Dialog Systems Robust to Speech Recognition Errors in the Dialog History? An Empirical Study
Aug 18, 2020
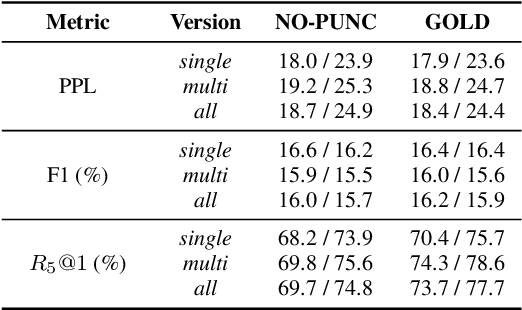

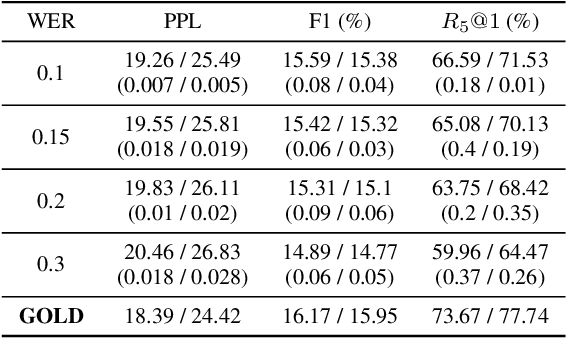
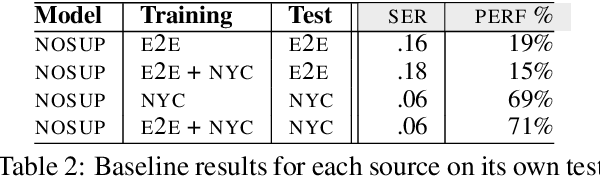
Large end-to-end neural open-domain chatbots are becoming increasingly popular. However, research on building such chatbots has typically assumed that the user input is written in nature and it is not clear whether these chatbots would seamlessly integrate with automatic speech recognition (ASR) models to serve the speech modality. We aim to bring attention to this important question by empirically studying the effects of various types of synthetic and actual ASR hypotheses in the dialog history on TransferTransfo, a state-of-the-art Generative Pre-trained Transformer (GPT) based neural open-domain dialog system from the NeurIPS ConvAI2 challenge. We observe that TransferTransfo trained on written data is very sensitive to such hypotheses introduced to the dialog history during inference time. As a baseline mitigation strategy, we introduce synthetic ASR hypotheses to the dialog history during training and observe marginal improvements, demonstrating the need for further research into techniques to make end-to-end open-domain chatbots fully speech-robust. To the best of our knowledge, this is the first study to evaluate the effects of synthetic and actual ASR hypotheses on a state-of-the-art neural open-domain dialog system and we hope it promotes speech-robustness as an evaluation criterion in open-domain dialog.
Policy-Driven Neural Response Generation for Knowledge-Grounded Dialogue Systems
Jun 09, 2020
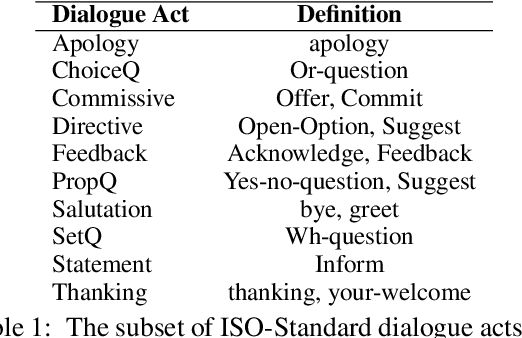
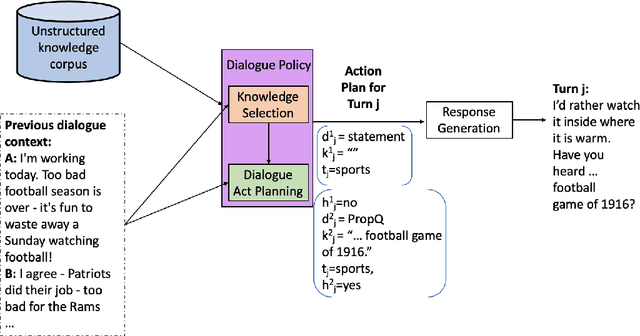
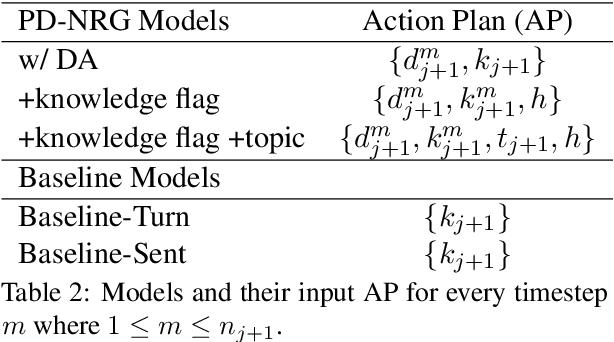
Open-domain dialogue systems aim to generate relevant, informative and engaging responses. Seq2seq neural response generation approaches do not have explicit mechanisms to control the content or style of the generated response, and frequently result in uninformative utterances. In this paper, we propose using a dialogue policy to plan the content and style of target responses in the form of an action plan, which includes knowledge sentences related to the dialogue context, targeted dialogue acts, topic information, etc. The attributes within the action plan are obtained by automatically annotating the publicly released Topical-Chat dataset. We condition neural response generators on the action plan which is then realized as target utterances at the turn and sentence levels. We also investigate different dialogue policy models to predict an action plan given the dialogue context. Through automated and human evaluation, we measure the appropriateness of the generated responses and check if the generation models indeed learn to realize the given action plans. We demonstrate that a basic dialogue policy that operates at the sentence level generates better responses in comparison to turn level generation as well as baseline models with no action plan. Additionally the basic dialogue policy has the added effect of controllability.
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access
Jun 05, 2020
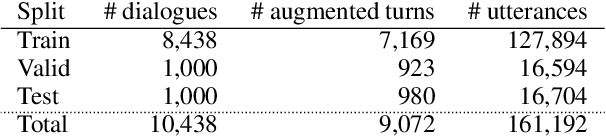
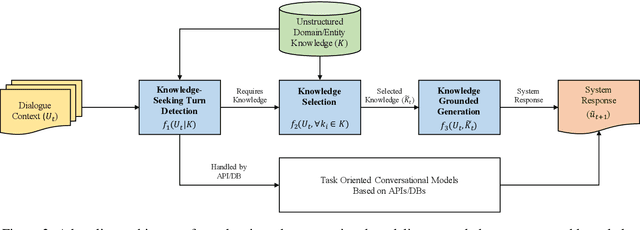

Most prior work on task-oriented dialogue systems are restricted to a limited coverage of domain APIs, while users oftentimes have domain related requests that are not covered by the APIs. In this paper, we propose to expand coverage of task-oriented dialogue systems by incorporating external unstructured knowledge sources. We define three sub-tasks: knowledge-seeking turn detection, knowledge selection, and knowledge-grounded response generation, which can be modeled individually or jointly. We introduce an augmented version of MultiWOZ 2.1, which includes new out-of-API-coverage turns and responses grounded on external knowledge sources. We present baselines for each sub-task using both conventional and neural approaches. Our experimental results demonstrate the need for further research in this direction to enable more informative conversational systems.
Schema-Guided Natural Language Generation
May 11, 2020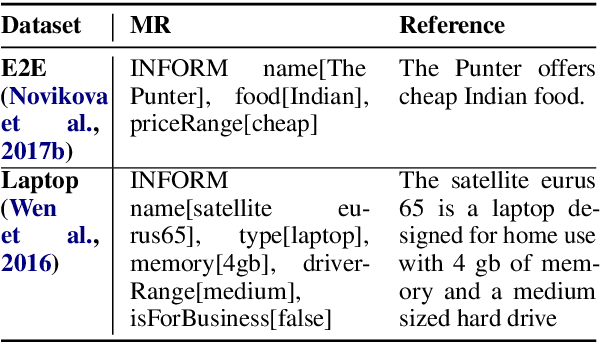


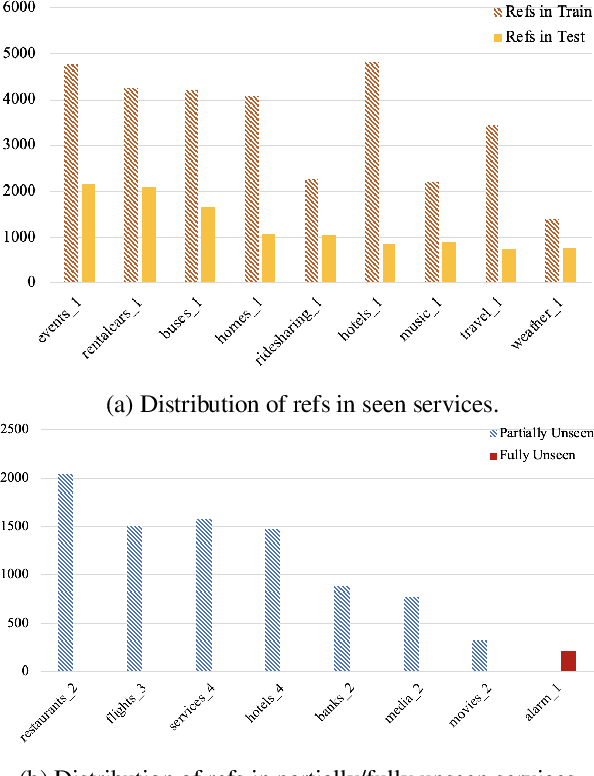
Neural network based approaches to natural language generation (NLG) have gained popularity in recent years. The goal of the task is to generate a natural language string to realize an input meaning representation, hence large datasets of paired utterances and their meaning representations are used for training the network. However, dataset creation for language generation is an arduous task, and popular datasets designed for training these generators mostly consist of simple meaning representations composed of slot and value tokens to be realized. These simple meaning representations do not include any contextual information that may be helpful for training an NLG system to generalize, such as domain information and descriptions of slots and values. In this paper, we present the novel task of Schema-Guided Natural Language Generation, in which we repurpose an existing dataset for another task: dialog state tracking. Dialog state tracking data includes a large and rich schema spanning multiple different attributes, including information about the domain, user intent, and slot descriptions. We train different state-of-the-art models for neural natural language generation on this data and show that inclusion of the rich schema allows our models to produce higher quality outputs both in terms of semantics and diversity. We also conduct experiments comparing model performance on seen versus unseen domains. Finally, we present human evaluation results and analysis demonstrating high ratings for overall output quality.
From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap
Apr 13, 2020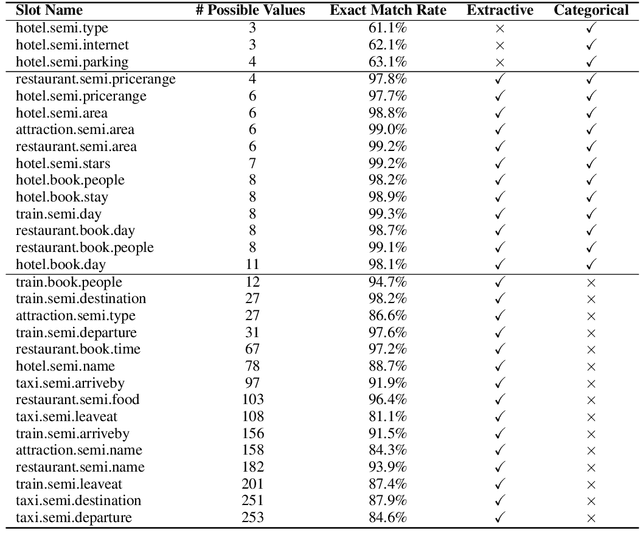
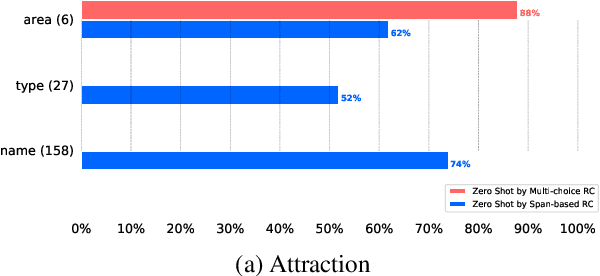

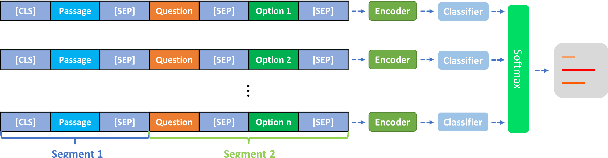
Dialogue state tracking (DST) is at the heart of task-oriented dialogue systems. However, the scarcity of labeled data is an obstacle to building accurate and robust state tracking systems that work across a variety of domains. Existing approaches generally require some dialogue data with state information and their ability to generalize to unknown domains is limited. In this paper, we propose using machine reading comprehension (RC) in state tracking from two perspectives: model architectures and datasets. We divide the slot types in dialogue state into categorical or extractive to borrow the advantages from both multiple-choice and span-based reading comprehension models. Our method achieves near the current state-of-the-art in joint goal accuracy on MultiWOZ 2.1 given full training data. More importantly, by leveraging machine reading comprehension datasets, our method outperforms the existing approaches by many a large margin in few-shot scenarios when the availability of in-domain data is limited. Lastly, even without any state tracking data, i.e., zero-shot scenario, our proposed approach achieves greater than 90% average slot accuracy in 12 out of 30 slots in MultiWOZ 2.1.
MA-DST: Multi-Attention Based Scalable Dialog State Tracking
Feb 07, 2020



Task oriented dialog agents provide a natural language interface for users to complete their goal. Dialog State Tracking (DST), which is often a core component of these systems, tracks the system's understanding of the user's goal throughout the conversation. To enable accurate multi-domain DST, the model needs to encode dependencies between past utterances and slot semantics and understand the dialog context, including long-range cross-domain references. We introduce a novel architecture for this task to encode the conversation history and slot semantics more robustly by using attention mechanisms at multiple granularities. In particular, we use cross-attention to model relationships between the context and slots at different semantic levels and self-attention to resolve cross-domain coreferences. In addition, our proposed architecture does not rely on knowing the domain ontologies beforehand and can also be used in a zero-shot setting for new domains or unseen slot values. Our model improves the joint goal accuracy by 5% (absolute) in the full-data setting and by up to 2% (absolute) in the zero-shot setting over the present state-of-the-art on the MultiWoZ 2.1 dataset.
DeepCopy: Grounded Response Generation with Hierarchical Pointer Networks
Aug 28, 2019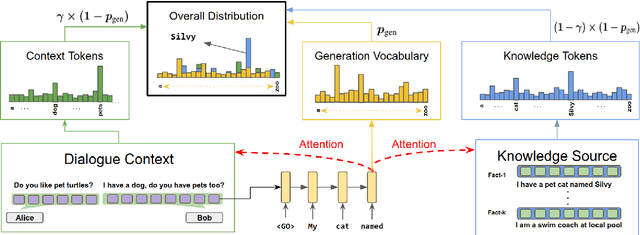
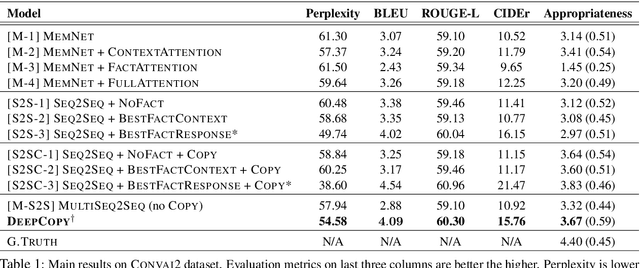
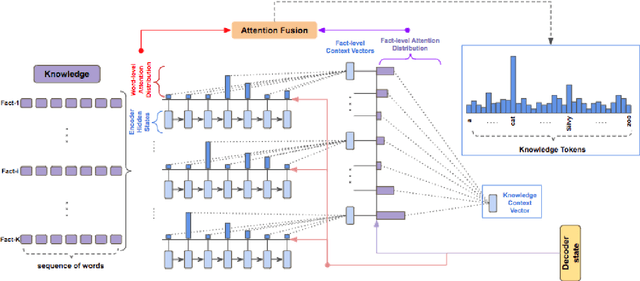
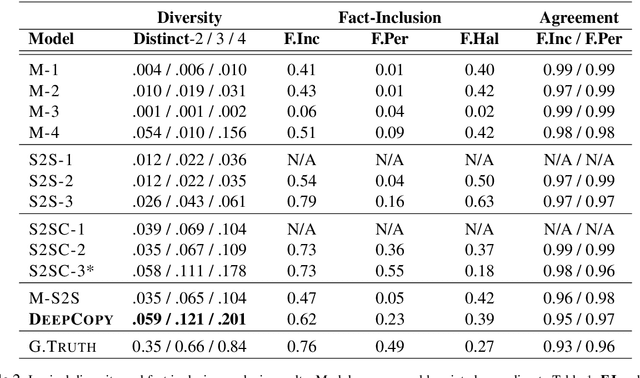
Recent advances in neural sequence-to-sequence models have led to promising results for several language generation-based tasks, including dialogue response generation, summarization, and machine translation. However, these models are known to have several problems, especially in the context of chit-chat based dialogue systems: they tend to generate short and dull responses that are often too generic. Furthermore, these models do not ground conversational responses on knowledge and facts, resulting in turns that are not accurate, informative and engaging for the users. In this paper, we propose and experiment with a series of response generation models that aim to serve in the general scenario where in addition to the dialogue context, relevant unstructured external knowledge in the form of text is also assumed to be available for models to harness. Our proposed approach extends pointer-generator networks (See et al., 2017) by allowing the decoder to hierarchically attend and copy from external knowledge in addition to the dialogue context. We empirically show the effectiveness of the proposed model compared to several baselines including (Ghazvininejad et al., 2018; Zhang et al., 2018) through both automatic evaluation metrics and human evaluation on CONVAI2 dataset.